【Anaconda新手必备】:掌握这5个API文档技巧,让你的编程效率翻倍!
发布时间: 2024-12-09 16:49:43 阅读量: 9 订阅数: 17 

2024年Anaconda安装教程:超详细版,让你轻松成为“圈内人”!
# 1. Anaconda入门与配置
Anaconda是一个开源的Python发行版本,它为科学计算和数据处理提供了便利,尤其适合数据科学家、分析师、工程师使用。该章节旨在帮助新手用户快速入门Anaconda,并对其环境进行配置。
## 1.1 下载与安装Anaconda
首先,访问Anaconda官方网站下载适合个人操作系统(Windows、Mac OS X、Linux)的安装包。下载完成后,根据安装向导的提示完成安装过程。建议在安装过程中选中“Add Anaconda to my PATH environment variable”(将Anaconda添加到环境变量路径中)以方便后续操作。
## 1.2 验证安装
安装完成后,在命令行界面(终端)输入`conda --version`或`python --version`。如果系统正确返回版本信息,则表示Anaconda已成功安装。
## 1.3 配置conda初始化
执行`conda init`命令初始化conda环境。根据系统提示,如果提示是否立即激活conda环境,建议选择“yes”。这样,conda将自动激活base环境。
以上是Anaconda的基础入门内容。配置完成后,您就可以开始使用Anaconda进行包管理和环境管理了。接下来的章节将详细介绍如何高效地使用Anaconda环境,包括创建、管理以及如何通过conda和pip进行包管理等。
# 2. 深入理解Anaconda环境管理
## 2.1 环境创建与管理
### 2.1.1 创建环境的命令和参数
Anaconda环境的创建是将不同的软件包和依赖隔离开来,以保证项目之间的依赖不会相互冲突。通过使用`conda`命令,我们可以创建一个新的环境并指定环境名称以及需要安装的包。
例如,创建一个名为`py37`的环境,并指定使用Python 3.7版本:
```bash
conda create -n py37 python=3.7
```
此命令中的参数含义如下:
- `-n`:指定环境名称。
- `python=3.7`:指定环境中安装的Python版本。
在创建环境时,还可以通过添加更多的包名和版本号来同时安装这些包,例如:
```bash
conda create -n myenv numpy=1.18 pandas=0.25
```
这将创建一个名为`myenv`的环境,其中同时安装了`numpy`和`pandas`的指定版本。
### 2.1.2 环境激活与切换
创建了环境后,需要激活它才能使用。在不同的操作系统上,激活命令会有所不同:
在Windows系统中,使用以下命令:
```cmd
conda activate py37
```
在Linux或macOS系统中,使用:
```bash
source activate py37
```
激活后,你的命令提示符前会显示当前的环境名称,表明你正在使用该环境。
如果需要切换到另一个环境,只需在激活命令中指定新的环境名称即可:
```bash
conda activate myenv
```
你还可以通过`deactivate`命令退出当前环境,返回到默认的root环境。
```bash
conda deactivate
```
## 2.2 包的安装与更新
### 2.2.1 常用包管理命令
在Anaconda环境内,我们可以使用`conda`命令来管理包,包括安装、更新、列出已安装的包等。
安装包的命令格式为:
```bash
conda install package_name=version
```
如果省略版本号,则会安装最新版本的包。
更新包的命令与安装类似,但需要使用`update`关键字:
```bash
conda update package_name
```
列出当前环境中所有已安装的包:
```bash
conda list
```
### 2.2.2 解决依赖问题的方法
在安装或更新包时,可能会遇到依赖冲突问题。Anaconda通过其内部的依赖解决器来处理这些问题。
例如,当你尝试安装一个包,但它的版本与环境中其他包不兼容时,`conda`会尝试寻找满足所有依赖关系的解决方案。
如果遇到无法解决的依赖冲突,可以使用`conda install -c conda-forge`命令指定从conda-forge频道安装,该频道常包含最新或不同版本的包。
## 2.3 环境备份与迁移
### 2.3.1 导出和导入环境配置
为了在不同的机器或项目间迁移环境,可以导出当前环境的配置信息。使用以下命令可以导出名为`myenv`的环境:
```bash
conda env export -n myenv > environment.yml
```
这会生成一个名为`environment.yml`的文件,其中包含了环境的所有详细信息。
如果需要在其他地方创建相同配置的环境,只需使用以下命令:
```bash
conda env create -f environment.yml
```
此命令会根据`environment.yml`文件中的描述,创建一个与原环境完全一致的新环境。
### 2.3.2 环境迁移的最佳实践
在进行环境迁移时,遵循以下最佳实践可以帮助确保过程的顺利进行:
1. **记录环境配置**:在迁移之前,总是导出环境配置文件并验证环境配置的正确性。
2. **测试新环境**:在新的机器或新的开发周期开始前,确保所有依赖和包都正确安装且无冲突。
3. **使用虚拟环境**:对于Python项目,建议使用`virtualenv`来隔离项目环境,因为`conda`环境主要是用于安装包含二进制扩展的包。
4. **备份数据**:在迁移过程中,备份重要数据和配置文件总是明智的,以防万一需要恢复原始状态。
5. **环境版本控制**:使用如`pip freeze > requirements.txt`命令配合版本控制系统跟踪依赖,这样可以在不依赖`conda`环境的情况下,复制和重建环境。
通过遵循这些实践,即使在复杂的项目中,也能有效地管理和迁移Anaconda环境。
# 3. 掌握Anaconda中的Jupyter Notebook
## 3.1 Notebook基础操作
### 3.1.1 创建和编辑Notebook
Jupyter Notebook是数据分析领域广泛使用的交互式笔记本。在创建一个新的Notebook时,可以利用Anaconda Navigator图形界面,或直接在命令行中使用`jupyter notebook`命令。以下是创建和编辑Notebook的基本步骤:
1. 打开Anaconda Navigator,找到Jupyter Notebook图标并启动。
2. 在浏览器中打开Jupyter Notebook界面,通过点击`New`按钮选择`Python [Conda root]`来创建一个新的Notebook。
3. 在新的Notebook中,你可以输入代码单元格,按下`Shift + Enter`来执行。
创建Notebook后,你可以通过单元格的`Insert`菜单来添加新的单元格,并选择是代码单元格还是Markdown单元格来进行编辑。
### 3.1.2 熟悉Notebook界面
Jupyter Notebook的界面由一系列的单元格组成,支持Markdown文本格式。你可以通过点击工具栏上的`Help` > `User Interface Tour`来快速了解各个界面元素。
1. **工具栏**:提供了创建、复制、粘贴、删除等单元格操作,以及保存、重启内核等选项。
2. **文件菜单**:提供了文件操作选项,如新建、打开、保存、下载等。
3. **运行按钮**:允许执行选中单元格的代码或Markdown文本。
4. **内核选项**:在`Kernel`菜单中,可以重启内核、中断运行等。
代码单元格支持多种编程语言,但最常见的是Python。Markdown单元格则用于编写说明文本,可以设置标题、列表、链接等格式。
### 3.1.3 编码实践
在编写代码时,Notebook提供实时代码补全的功能,能够提高开发效率。使用Tab键可以触发补全提示,结合Shift+Tab可以查看函数的文档说明。
```python
# 示例代码:计算圆周率π的近似值
import math
pi_approx = sum([(-1)**(i/2) / math.factorial(i) for i in range(1000000)])
pi_approx # 显示结果
```
以上代码利用了Python的`math`库来计算π的近似值。每个单元格执行后,结果会直接显示在单元格下方。
## 3.2 高效使用Notebook
### 3.2.1 插件的安装与使用
Jupyter Notebook通过插件系统可以扩展其功能。插件可以通过`nbextension`安装,例如安装`jupyter_contrib_nbextensions`包。
1. 安装插件包:`!conda install -c conda-forge jupyter_contrib_nbextensions`
2. 启用扩展:`%load_ext jupyter_contrib_nbextensions`
3. 配置和查看扩展列表:在Notebook中点击`Nbextensions`按钮。
### 3.2.2 调试和性能优化技巧
为了提高Notebook的运行效率,可以进行以下操作:
- **使用魔法命令**:例如`%timeit`用于测试代码执行时间。
- **局部变量重置**:使用`%reset -f`可以重置局部变量,防止内核内存过大。
- **代码优化**:利用代码分析工具,例如`line_profiler`,来识别性能瓶颈。
## 3.3 Notebook扩展应用
### 3.3.1 集成开发工具(IDE)功能
Jupyter Notebook的交互性和灵活性使其成为开发环境的一部分,但在某些情况下,可能需要集成开发工具(IDE)的功能。例如,JupyterLab提供了一个更强大的开发环境,它支持插件扩展,允许更复杂的项目管理。
### 3.3.2 数据可视化与展示
Notebook提供多种方式用于数据可视化,可以集成不同的可视化工具:
- **使用Matplotlib和Seaborn**:这些库可以集成到Notebook中用于生成静态图表。
- **使用Plotly和Bokeh**:这些库可以创建交互式的图表,使得数据展示更为直观。
```python
import matplotlib.pyplot as plt
import seaborn as sns
# 生成静态图表
plt.plot([1, 2, 3, 4])
plt.title('Simple Plot')
plt.show()
# 使用Seaborn进行高级可视化
sns.set()
plt.figure(figsize=(10, 6))
sns.regplot(x="total_bill", y="tip", data=tips)
plt.show()
```
以上示例代码展示了如何使用Matplotlib和Seaborn库在Notebook中进行数据可视化。
通过Jupyter Notebook与数据分析和可视化库的结合,可以创建出丰富多彩的数据分析报告和展示。这种集成不仅提高了分析的效率,也使得数据分析的分享和展示变得更为便捷。
# 4. ```
# 第四章:利用Anaconda进行科学计算
科学计算是数据科学的核心,而Anaconda通过其庞大的包库,为科学计算提供了强大的支持。本章节将深入探讨如何利用Anaconda中的关键库进行高效的数据分析、机器学习、深度学习以及数据可视化。
## 4.1 数据分析基础
在数据分析领域,Pandas和NumPy是不可或缺的两个库。Pandas提供了快速、灵活和表达式丰富的数据结构,使“关系”或“标签”数据的处理变得简单直观。NumPy是Python科学计算的基础包,它增加了对多维数组的支持,并对数组运算进行了优化。
### 4.1.1 Pandas库的使用
Pandas库的使用可以从数据的导入开始,支持多种格式的数据源,如CSV、Excel、JSON等。数据分析中常用的函数、数据透视表以及分组聚合等操作,都可以通过Pandas轻松实现。
```python
import pandas as pd
# 加载数据集
data = pd.read_csv('data.csv')
# 查看数据集前五行
print(data.head())
# 数据清洗
data.dropna(inplace=True) # 删除空值
data.drop_duplicates(inplace=True) # 删除重复行
# 数据分组聚合
grouped_data = data.groupby('category').mean() # 按照某个类别进行平均值计算
print(grouped_data)
```
### 4.1.2 NumPy库在数据处理中的应用
NumPy库的核心是N维数组对象ndarray,该对象是一个快速而灵活的大数据容器。在数据分析的预处理和模型的特征构建阶段,NumPy的数组运算为大规模数值计算提供了支持。
```python
import numpy as np
# 创建NumPy数组
arr = np.array([[1, 2, 3], [4, 5, 6]])
# 数组形状调整
reshaped_arr = arr.reshape(3, 2)
print(reshaped_arr)
# 数组的基本运算
sum_arr = np.sum(arr, axis=1)
print(sum_arr)
```
## 4.2 机器学习与深度学习
随着机器学习和深度学习的发展,它们在各个领域中的应用变得越来越广泛。Anaconda通过提供丰富的机器学习和深度学习库,极大地降低了入门门槛。
### 4.2.1 Scikit-learn入门实践
Scikit-learn是一个开源的机器学习库,它提供了许多常用的机器学习算法,如分类、回归、聚类等。它简单易用,并且与Pandas、NumPy等库配合良好。
```python
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 加载数据集
iris = load_iris()
X, y = iris.data, iris.target
# 数据集拆分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 构建模型
clf = RandomForestClassifier()
clf.fit(X_train, y_train)
# 预测结果
predictions = clf.predict(X_test)
# 计算准确率
print("Accuracy:", accuracy_score(y_test, predictions))
```
### 4.2.2 TensorFlow和PyTorch框架介绍
TensorFlow和PyTorch是目前最为流行的深度学习框架,它们都是基于图的计算,但提供不同的用户接口和使用方式。TensorFlow使用静态计算图,而PyTorch使用动态计算图,这让PyTorch在研究和开发中更加灵活。
```python
import torch
import torch.nn as nn
import torch.optim as optim
# 定义一个简单的神经网络模型
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc = nn.Linear(4, 3) # 输入4维,输出3维
def forward(self, x):
x = torch.relu(self.fc(x))
return x
# 实例化模型
net = SimpleNN()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001)
# 假设的输入数据和标签
input = torch.randn(1, 4)
target = torch.randint(0, 3, (1,))
# 训练网络
output = net(input)
loss = criterion(output, target)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
```
## 4.3 可视化工具与技巧
可视化是数据分析中非常重要的环节,它可以将复杂的数据分析结果以图形的方式直观展现出来,有助于我们更好地理解数据。
### 4.3.1 Matplotlib和Seaborn的图形绘制
Matplotlib是Python中最基础的绘图库,提供了一个面向对象的API来绘制各种静态、动态、交互式的图表。Seaborn是建立在Matplotlib基础上的一个高级绘图库,它为绘制统计图形提供了高级接口。
```python
import matplotlib.pyplot as plt
import seaborn as sns
# 使用Matplotlib绘制简单散点图
x = np.random.randn(100)
y = np.random.randn(100)
plt.scatter(x, y)
plt.title("Matplotlib Scatter Plot")
plt.show()
# 使用Seaborn绘制更高级的分布图
tips = sns.load_dataset('tips')
sns.displot(tips, x="total_bill", y="tip", hue="day", kind="reg")
```
### 4.3.2 交互式可视化的实现方式
交互式可视化使用户可以通过与图表的交互来获取更多信息。Plotly是一个支持创建交互式图表的库,它允许我们创建具有复杂动画和交互功能的图形。
```python
import plotly.express as px
# 创建一个交互式散点图
df = px.data.iris() # 加载iris数据集
fig = px.scatter(df, x="sepal_width", y="sepal_length", color="species")
fig.show()
```
以上章节内容介绍了如何使用Anaconda进行基础和高级科学计算操作,通过代码和逻辑分析详细解读了Pandas、NumPy、Scikit-learn、TensorFlow/PyTorch、Matplotlib、Seaborn以及Plotly的具体使用场景与方法。这些知识点能够帮助IT从业者在数据分析、机器学习和深度学习等领域中有效地执行任务。
```
# 5. 优化Anaconda项目工作流
## 5.1 环境管理的最佳实践
### 5.1.1 环境文件的使用
在使用Anaconda进行项目开发时,环境文件是定义和管理依赖的关键。它们可以确保环境的一致性,便于在不同机器或团队成员之间共享和重现相同的开发环境。
环境文件主要分为两类:`environment.yml` 和 `condarc`。`environment.yml` 文件描述了一个Anaconda环境的全部包和版本,可以通过 `conda env create -f environment.yml` 命令来创建相同的环境。而 `condarc` 文件则用于设置conda的全局配置,如代理、镜像源等。
对于 `environment.yml` 文件,其基本结构包含以下几个部分:
- `name`: 定义环境名称。
- `channels`: 列出用于查找包的Anaconda通道。
- `dependencies`: 列出构成环境所需的所有包及其版本。
```yaml
name: myenv
channels:
- conda-forge
- defaults
dependencies:
- numpy=1.19
- pandas
- python=3.7
```
使用 `conda env export > environment.yml` 可以导出现有环境的依赖到文件。在环境重建时,执行 `conda env create -f environment.yml` 即可。
### 5.1.2 环境版本控制策略
环境的版本控制是确保项目可重复性和可移植性的重要组成部分。有几种策略可以帮助我们管理环境的版本变化:
- **使用环境文件快照**:通过定期导出 `environment.yml` 文件,确保环境的每一次重要变动都有记录。
- **使用环境文件的版本控制**:利用Git等版本控制系统来管理环境文件,可以跟踪和管理不同版本之间的差异。
- **编写环境构建脚本**:创建脚本自动化环境的安装和配置过程,避免人工操作的失误,方便环境的快速部署。
```shell
# 创建环境的构建脚本示例
conda create -n myenv python=3.7
conda activate myenv
pip install numpy pandas
# 可以将上述命令保存为一个shell脚本文件,如create_env.sh
```
使用版本控制策略,我们能够更加精确地追踪环境变化,快速回滚到旧版本或者推进到新版本,进一步提高工作效率。
## 5.2 持续集成与自动化部署
### 5.2.1 利用Conda-Forge简化流程
在科学计算领域,Conda-Forge是一个流行且功能强大的渠道,它提供了大量的预编译二进制包,这些包通过社区贡献而得。利用Conda-Forge可以极大地简化安装和依赖管理的流程。
首先,需要将Conda-Forge添加到你的Anaconda渠道列表中:
```shell
conda config --add channels conda-forge
```
安装包时,Conda-Forge会自动被考虑进去。为了优化工作流,可以在`environment.yml`中显式指定需要的包:
```yaml
name: myenv
channels:
- conda-forge
dependencies:
- matplotlib
- scipy
```
利用Conda-Forge,可以在环境配置文件中直接安装最新版本的科学计算包,省去了从源代码编译的麻烦。
### 5.2.2 自动化测试和部署工具的使用
在项目开发过程中,自动化测试是确保代码质量和可靠性的重要环节。Anaconda可以与如Tox、pytest这样的自动化测试工具结合使用。
部署工作流可以使用如Ansible、Docker等工具,这些工具可以自动化打包和分发应用程序及其依赖项。通过编写YAML格式的Dockerfile或者Ansible剧本,可以描述应用程序的环境和运行条件,实现环境的一致性和可重用性。
```yaml
# Dockerfile 示例
FROM continuumio/miniconda3
# 复制环境文件到镜像
COPY environment.yml /tmp/environment.yml
# 创建并激活环境
RUN conda env create -f /tmp/environment.yml && conda clean --all
# 将应用程序复制到镜像中
COPY . /app
# 激活环境并运行应用程序
CMD [ "conda", "activate", "myenv" , "python", "app.py"]
```
自动化工具可以帮助开发团队减少重复性工作,提高开发效率,同时减少因人为操作导致的错误。
## 5.3 安全与维护
### 5.3.1 隔离开发环境的重要性
在多项目并行开发的环境中,隔离开发环境能够避免依赖冲突和版本混乱的问题。对于每个项目,都应当使用独立的环境进行开发和测试。
隔离环境除了可以减少开发风险外,还有助于提升开发效率。开发者可以使用不同的工具和库版本,针对特定项目进行优化,而不用担心影响到其他项目。对于团队协作来说,使用独立的环境也能够确保大家在同样的条件下工作,提高协作的流畅度。
在Anaconda中,可以使用 `conda create` 命令来创建和管理多个独立环境:
```shell
# 创建一个新的环境
conda create -n myproject python=3.7
# 激活环境
conda activate myproject
# 进行项目开发和测试
```
### 5.3.2 更新和清理策略
在项目开发的过程中,随着依赖库的更新,环境也需要定期进行清理和优化。这不仅能够释放磁盘空间,也能够提升项目的运行效率。
使用 `conda update` 命令可以更新环境中的包到最新版本:
```shell
conda activate myenv
conda update --all
```
对于清理无用的包和缓存文件,Anaconda提供了一系列的工具:
```shell
# 清理conda缓存中的包
conda clean --packages
# 删除无用的包缓存和tar文件
conda clean --tarballs
# 删除无用的包和索引缓存
conda clean --index-cache
# 删除整个环境
conda remove --name myenv --all
```
在清理过程中,需要注意不要删除正在使用的包,以免影响开发环境的稳定性。定期的更新和清理可以保持环境的健康状态,对于长期维护项目至关重要。
以上章节内容已经展示了优化Anaconda项目工作流的重要环节和方法,从环境管理最佳实践到持续集成和自动化部署,再到环境的安全与维护策略,每一步都至关重要。通过实施这些策略,项目管理者和开发人员可以显著提升工作效率,并确保项目开发的顺利进行。
# 6. Anaconda在生产环境中的应用
在了解了Anaconda的基础知识,掌握了其在个人和团队项目中的应用之后,我们将深入探讨Anaconda在生产环境中的应用。在生产环境中,确保软件运行的稳定性和高效性是至关重要的。Anaconda作为一个全面的科学计算平台,其在生产环境中的表现也同样出色。本章节将带您探索Anaconda在生产环境中的部署策略、性能优化以及安全性保障。
## 6.1 部署策略的制定与应用
部署策略的制定是在生产环境中成功应用Anaconda的关键。一个良好的部署策略不仅能够确保应用的可靠性和稳定性,还能够提高开发和运维的效率。
### 6.1.1 容器化部署
容器化技术是当前软件部署的趋势之一,Docker容器因其轻量级和隔离性,特别适合用于部署Anaconda环境。
- **Dockerfile配置**:编写一个适合项目的Dockerfile,用于定义Anaconda环境的容器镜像。
- **构建镜像**:通过Docker命令或者CI/CD流水线构建Anaconda环境的镜像。
- **运行容器**:使用`docker run`命令启动容器实例,并确保容器配置中包含了足够的资源分配以及必要的网络配置。
```Dockerfile
# 示例Dockerfile
FROM continuumio/miniconda3
# 安装依赖
RUN conda install numpy pandas scikit-learn -y
# 设置工作目录
WORKDIR /app
# 将当前目录下的文件复制到容器中
COPY . /app
# 设置环境变量
ENV PATH /opt/conda/bin:$PATH
```
### 6.1.2 Kubernetes管理
在生产环境中,一个复杂的应用通常需要一个复杂的部署策略。Kubernetes作为一个开源的容器编排平台,能够帮助管理多容器的应用部署。
- **Pod配置**:创建一个Pod定义文件,指定容器镜像和所需的资源限制。
- **服务与部署**:定义服务以实现负载均衡,并设置部署以确保应用的高可用性。
- **滚动更新**:通过定义部署的更新策略来实施无中断的服务更新。
```yaml
# 示例Pod配置文件
apiVersion: v1
kind: Pod
metadata:
name: anaconda-pod
spec:
containers:
- name: anaconda-container
image: your-anaconda-image:latest
resources:
requests:
memory: "128Mi"
cpu: "500m"
limits:
memory: "256Mi"
cpu: "1000m"
```
## 6.2 性能优化技巧
在生产环境中,性能优化是保证用户满意度的重要因素。对于运行在Anaconda上的应用程序,通过一些策略可以显著提高性能。
### 6.2.1 内存和资源管理
在运行数据密集型应用时,合理的内存和CPU资源管理能够避免资源竞争,保持应用的稳定运行。
- **内存限制**:在Docker容器中设置内存限制,防止应用占用过多内存导致系统不稳定。
- **并行计算**:利用Anaconda中的并行处理库(如Dask)来提升计算效率,同时保证资源的有效利用。
### 6.2.2 模块化和优化包版本
模块化部署和管理项目依赖的包版本可以减少不必要的复杂性,提高应用的可维护性。
- **环境文件**:使用`environment.yml`文件来记录并共享项目依赖,确保每个环境中的包版本一致。
- **依赖分离**:对于通用功能,可以打包为独立的包或服务,减少重复代码和依赖。
## 6.3 安全性与维护最佳实践
在生产环境中,安全性与维护是不可忽视的方面,Anaconda通过一系列措施提供支持。
### 6.3.1 安全性保障
安全性保障包括对敏感数据的处理、隔离开发和生产环境、以及定期更新和打补丁。
- **敏感数据加密**:在配置文件中使用加密存储敏感信息,如API密钥和数据库密码。
- **隔离环境**:确保开发环境与生产环境分离,防止未测试代码直接影响生产系统。
- **安全补丁**:定期更新Anaconda及其包到最新版本,修补已知的安全漏洞。
### 6.3.2 定期维护和监控
通过定期维护和实施监控策略,能够及时发现和解决问题,保证系统的稳定运行。
- **备份与恢复**:定期备份关键数据和环境配置,确保数据安全。
- **系统监控**:使用监控工具如Prometheus或Grafana监控系统资源使用情况和应用性能。
- **日志分析**:实施日志管理策略,方便快速定位问题并进行分析。
以上内容展示了如何在生产环境中应用Anaconda,涵盖了部署策略、性能优化以及安全性与维护的最佳实践。通过这些策略和方法,可以最大限度地提高Anaconda在生产环境中的表现,确保业务的高效和稳定运行。在下一章节中,我们将继续深入探讨Anaconda的企业级应用以及如何利用其进行数据科学项目管理。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到关于 Anaconda API 文档的深入专栏!本专栏将带你踏上数据分析、脚本编写、第三方库集成、DevOps 实践和版本历史探究的旅程。通过一系列引人入胜的文章,我们将揭示 Anaconda API 文档在数据科学工作流中的强大功能。从探索其在数据分析中的应用,到掌握编写高效脚本的技巧,再到了解它在集成 Python 库和持续集成/持续部署中的关键作用,本专栏将为你提供全面的指南,帮助你充分利用 Anaconda API 文档。此外,我们还将深入探讨 Jupyter Notebook 中的互动功能,展示 API 文档如何增强你的数据科学工作流。准备好踏上发现之旅,解锁 Anaconda API 文档的无限潜力!
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
台达PLC DVP32ES2-C终极指南:从安装到高级编程的全面教程
参考资源链接:[台达DVP32ES2-C PLC安装手册:256点I/O扩展与应用指南](https://wenku.csdn.net/doc/64634ae0543f8444889c0bcf?spm=1055.2635.3001.10343)
# 1. 台达PLC DVP32ES2-C基础介绍
台达电子作为全球知名的自动化与电子组件制造商,其PLC(可编程逻辑控制器)产品广泛应用于工业自动化领域。DVP32ES2-C作为台达PL
【九齐8位单片机基础教程】:NYIDE中文手册入门指南
参考资源链接:[NYIDE 8位单片机开发软件中文手册(V3.1):全面教程](https://wenku.csdn.net/doc/1p9i8oxa9g?spm=1055.2635.3001.10343)
# 1. 九齐8位单片机概述
九齐8位单片机是一种广泛应用于嵌入式系统和微控制器领域的设备,以其高性能、低功耗、丰富的外设接口以及简单易用的编程环境而著称。本章将概览九齐8位单片机的基础知识
【西门子840 CNC报警速查秘籍】:快速诊断故障,精确锁定PLC变量

参考资源链接:[标准西门子840CNC报警号对应的PLC变量地址](https://wenku.csdn.net/doc/6412b61dbe7fbd1778d45910?spm=1055.2635.3001.10343)
# 1. 西门子840 CNC报警系统概述
## 1.1 CNC报警系统的作用
CNC(Computer Numerical Contro
数据结构基础精讲:算法与数据结构的7大关键关系深度揭秘
参考资源链接:[《数据结构1800题》带目录PDF,方便学习](https://wenku.csdn.net/doc/5sfqk6scag?spm=1055.2635.3001.10343)
# 1. 数据结构与算法的关系概述
数据结构与算法是计算机科学的两大支柱,它们相辅相成,共同为复杂问题的高效解决提供方法论。在这一章中,我们将探讨数据结构与算法的紧密联系,以及为什么理解它
QSGMII性能稳定性测试:掌握核心测试技巧

参考资源链接:[QSGMII接口规范:连接PHY与MAC的高速解决方案](https://wenku.csdn.net/doc/82hgqw0h96?spm=1055.2635.3001.10343)
Nginx HTTPS转HTTP:24个安全设置确保兼容性与性能

参考资源链接:[Nginx https配置错误:https请求重定向至http问题解决](https://wenku.csdn.net/doc/6412b6b5be7fbd1778d47b10?spm=1055.2635.3001.10343)
# 1. Nginx HTTPS转HTTP基础
在这一章中,我们将探索Nginx如何从HTTPS过渡
JVPX连接器设计精要:结构、尺寸与装配的终极指南
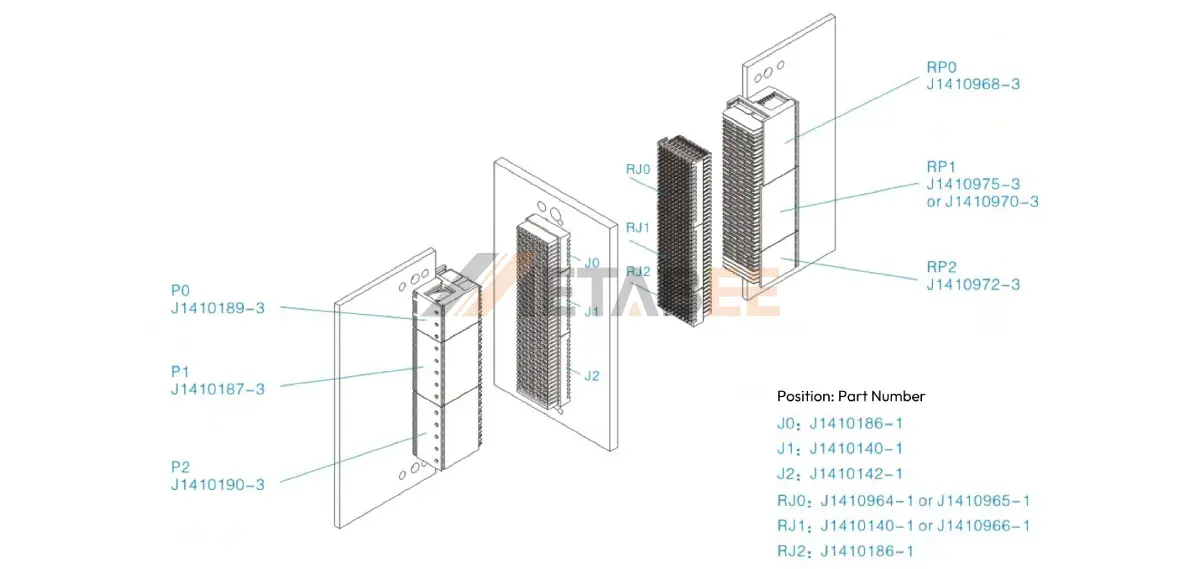
参考资源链接:[航天JVPX加固混装连接器技术规格与优势解析](https://wenku.csdn.net/doc/6459ba7afcc5391368237d7a?spm=1055.2635.3001.10343)
# 1. JVPX连接器概述与市场应用
JVPX连接器作为军事和航天领域广泛使用的一种精密连接器,其设计与应用展现了电子设备连接技术的先进性。本章节将首先探讨JVPX连接
STM32F405RGT6性能全解析:如何优化核心架构与资源管理
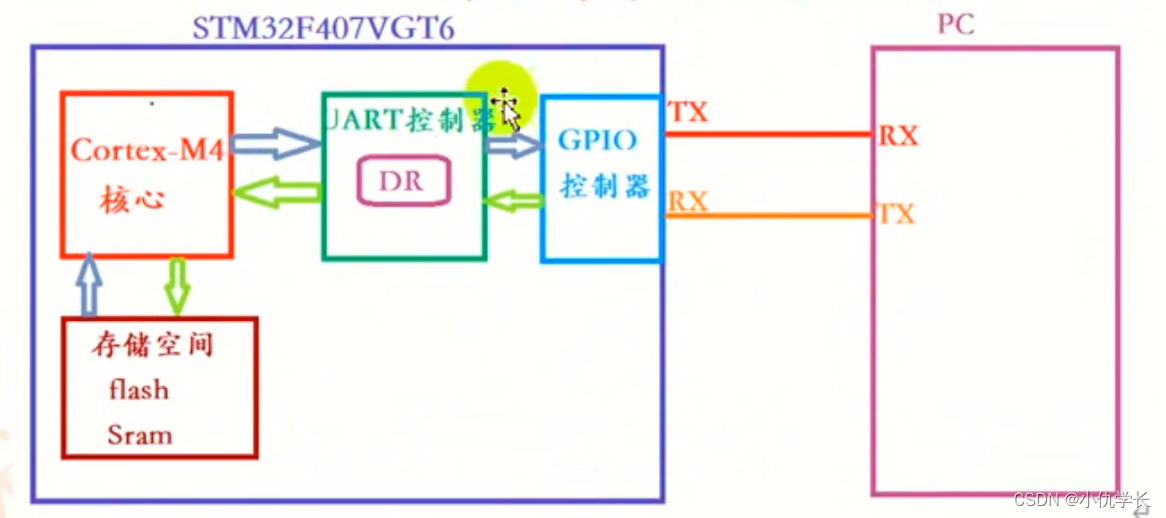
参考资源链接:[STM32F405RGT6中文参考手册:Cortex-M4 MCU详解](https://wenku.csdn.net/doc/6401ad30cce7214c316ee9da?spm=1055.2635.3001.10343)
# 1. STM32F405RGT6核心架构概览
STM32F405RGT6作为ST公司的一款高性能ARM Cortex-M4微控制器,其核心架构的设计是提升整体性能和效
数字集成电路设计实用宝典:第五章应用技巧大公开
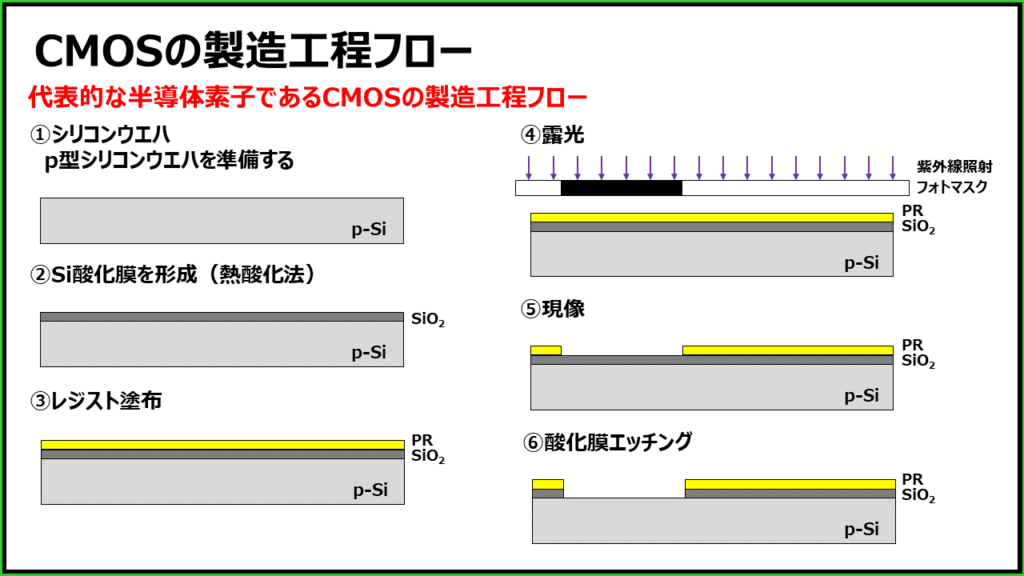
参考资源链接:[数字集成电路设计 第五章答案 chapter5_ex_sol.pdf](https://wenku.csdn.net/doc/64a21b7d7ad1c22e798be8ea?spm=1055.2635.3001.10343)
# 1. 数字集成电路设计基础
## 1.1 概述
数字集成电路是现代电子技术中的核心组件,它利用晶体管的开关特性来
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )