Oracle数据库索引失效案例分析与解决方案:索引失效大揭秘
发布时间: 2024-07-26 02:44:49 阅读量: 103 订阅数: 34 

oracle数据库索引失效
# 1. 索引失效概述**
索引失效是指索引无法有效地加速查询,导致查询性能下降。索引失效的原因有很多,包括索引结构不合理、数据更新频繁和统计信息不准确。
索引结构不合理是指索引列选择不当或索引类型选择不当。索引列选择不当会导致索引无法覆盖查询所需的数据,从而导致全表扫描。索引类型选择不当会导致索引无法有效地加速查询,例如使用哈希索引来加速范围查询。
# 2. 索引失效的常见原因**
索引失效是指索引不再有效地加速查询,导致查询性能下降。索引失效的原因多种多样,主要可归因于以下几个方面:
**2.1 索引结构不合理**
索引结构不合理会导致索引无法有效地用于查询优化。常见的索引结构不合理问题包括:
**2.1.1 索引列选择不当**
索引列选择不当是指为不适合创建索引的列创建索引。例如,对于经常更新的列或包含大量重复值的列,创建索引可能弊大于利。
**代码块:**
```sql
CREATE INDEX idx_name ON table_name (column_name);
```
**逻辑分析:**
此代码创建了一个名为 `idx_name` 的索引,使用列 `column_name` 作为索引列。如果 `column_name` 经常更新或包含大量重复值,则此索引可能不会有效地提高查询性能。
**2.1.2 索引类型选择不当**
索引类型选择不当是指为不适合查询模式的列选择不合适的索引类型。例如,对于范围查询,使用哈希索引可能比使用 B 树索引更有效。
**代码块:**
```sql
CREATE INDEX idx_name ON table_name (column_name) USING HASH;
```
**逻辑分析:**
此代码使用哈希索引创建了一个名为 `idx_name` 的索引,使用列 `column_name` 作为索引列。如果查询模式主要涉及范围查询,则哈希索引可能不如 B 树索引有效。
**2.2 数据更新频繁**
频繁的数据更新会导致索引失效。当数据更新时,索引需要更新以反映更改。如果更新频繁,索引可能会变得碎片化和无效。
**2.2.1 大量数据插入或删除**
大量数据插入或删除会导致索引碎片化。当插入或删除大量数据时,索引的叶子节点可能变得不连续,导致查询性能下降。
**2.2.2 数据更新导致索引失效**
数据更新也可能导致索引失效。例如,如果更新索引列的值,则索引可能不再有效地加速查询。
**代码块:**
```sql
UPDATE table_name SET column_name = new_value WHERE condition;
```
**逻辑分析:**
此代码更新了 `table_name` 表中 `column_name` 列的值,其中 `condition` 指定了要更新的行。如果 `column_name` 是索引列,则此更新可能导致索引失效。
**2.3 统计信息不准确**
统计信息不准确会导致优化器做出错误的决策,从而导致索引失效。统计信息用于估计表中数据的分布,优化器根据这些估计来选择最有效的执行计划。
**2.3.1 统计信息过时**
统计信息过时是指统计信息不再反映表中数据的当前分布。当数据发生重大更改时,统计信息可能会过时。
**2.3.2 统计信息不准确**
统计信息不准确是指统计信息不准确地反映表中数据的分布。这可能是由于数据收集过程中的错误或数据分布异常造成的。
# 3. 索引失效的诊断与修复
### 3.1 诊断索引失效
#### 3.1.1 查询执行计划
查询执行计划可以显示查询在执行过程中使用的索引。如果查询没有使用索引,或者使用的是不合适的索引,则可能是索引失效的迹象。
**示例代码:**
```sql
EXPLAIN PLAN FOR SELECT * FROM table_name WHERE column_name = 'value';
```
**逻辑分析:**
该查询将生成一个执行计划,其中包含查询使用的索引信息。如果查询未使用索引,则执行计划中将不会出现索引信息。
#### 3.1.2 索引使用情况分析
索引使用情况分析可以显示特定索引的使用频率。如果某个索引的使用频率很低,则可能是索引失效的迹象。
**示例代码:**
```sql
SELECT index_name, index_usage_count
FROM v$object_usage
WHERE object_type = 'INDEX';
```
**逻辑分析:**
该查询将返回一个表,其中包含每个索引的名称和使用次数。如果某个索引的使用次数很低,则可能需要考虑重建或删除该索引。
### 3.2 修复索引失效
#### 3.2.1 重建索引
重建索引可以修复索引结构中的错误,并确保索引是最新的。
**示例代码:**
```sql
ALTER INDEX index_name REBUILD;
```
**逻辑分析:**
该命令将重建指定的索引。重建索引是一个耗时的操作,因此在执行该操作之前应仔细考虑。
#### 3.2.2 重新收集统计信息
重新收集统计信息可以更新 Oracle 数据库中存储的有关表和索引的统计信息。这可以帮助 Oracle 数据库选择最合适的索引。
**示例代码:**
```sql
ANALYZE TABLE table_name COMPUTE STATISTICS;
```
**逻辑分析:**
该命令将重新收集指定表的统计信息。重新收集统计信息是一个耗时的操作,因此在执行该操作之前应仔细考虑。
### 3.3 索引失效的修复流程
索引失效的修复流程通常包括以下步骤:
1. **诊断索引失效:**使用查询执行计划和索引使用情况分析来诊断索引失效。
2. **修复索引失效:**使用重建索引或重新收集统计信息来修复索引失效。
3. **验证修复结果:**使用查询执行计划和索引使用情况分析来验证修复结果。
### 3.4 索引失效的预防措施
为了防止索引失效,可以采取以下措施:
* **合理设计索引:**选择合适的索引列和索引类型。
* **优化数据更新操作:**批量更新数据并使用分区表。
* **定期收集统计信息:**定期重新收集统计信息以确保其是最新的。
# 4. 防止索引失效的最佳实践
### 4.1 合理设计索引
#### 4.1.1 选择合适的索引列
- **选择唯一或主键列:**对于唯一或主键列,索引可以快速定位到唯一行,提高查询效率。
- **选择经常用于查询的列:**索引列应该经常用于查询条件中,这样才能有效减少表扫描的次数。
- **避免选择过宽的列:**索引列的宽度会影响索引的大小和维护成本,过宽的列会降低索引的效率。
#### 4.1.2 选择合适的索引类型
- **B-Tree 索引:**B-Tree 索引是Oracle中默认的索引类型,适用于范围查询和等值查询。
- **Hash 索引:**Hash 索引适用于等值查询,比 B-Tree 索引更快,但不能用于范围查询。
- **Bitmap 索引:**Bitmap 索引适用于对大量数据进行快速过滤,但不能用于排序或范围查询。
### 4.2 优化数据更新操作
#### 4.2.1 批量更新数据
- **使用批量更新语句:**批量更新语句可以一次更新多行数据,减少对索引的更新次数,提高效率。
- **使用分区表:**分区表可以将数据分成多个分区,对单个分区进行更新操作可以减少对其他分区的索引更新。
#### 4.2.2 使用分区表
- **分区表:**分区表将表分成多个分区,每个分区包含特定范围的数据。
- **好处:**分区表可以优化数据更新操作,因为只更新受影响的分区,减少对索引的更新。
- **示例:**
```sql
CREATE TABLE orders (
order_id NUMBER(10) NOT NULL,
order_date DATE,
customer_id NUMBER(10) NOT NULL,
total_amount NUMBER(10,2)
)
PARTITION BY RANGE (order_date) (
PARTITION p202301 VALUES LESS THAN (TO_DATE('2023-01-01', 'YYYY-MM-DD')),
PARTITION p202302 VALUES LESS THAN (TO_DATE('2023-02-01', 'YYYY-MM-DD')),
PARTITION p202303 VALUES LESS THAN (TO_DATE('2023-03-01', 'YYYY-MM-DD'))
);
```
### 4.3 定期收集统计信息
- **定期收集统计信息:**Oracle 使用统计信息来优化查询计划。过时的或不准确的统计信息会导致索引失效。
- **收集统计信息的命令:**
```sql
ANALYZE TABLE table_name COMPUTE STATISTICS;
```
- **自动收集统计信息:**Oracle 可以通过自动任务定期收集统计信息。
# 5. 索引失效案例分析
### 5.1 案例一:索引失效导致查询性能下降
**场景描述:**
一家电子商务网站的订单查询页面响应时间突然变慢。经过调查发现,索引失效导致查询执行计划发生了变化,导致查询效率降低。
**问题分析:**
* 查询执行计划显示,原本应该使用的索引没有被使用。
* 索引使用情况分析显示,索引的命中率很低。
**解决方案:**
* 重建索引以修复索引结构。
* 重新收集统计信息以更新索引的统计信息。
**代码示例:**
```sql
-- 重建索引
ALTER INDEX idx_order_date ON orders REBUILD;
-- 重新收集统计信息
ANALYZE TABLE orders COMPUTE STATISTICS;
```
### 5.2 案例二:索引失效导致数据完整性问题
**场景描述:**
一个银行系统的转账交易表中,存在一个唯一索引来保证转账交易的唯一性。由于索引失效,导致重复的转账交易被插入到数据库中,造成了数据完整性问题。
**问题分析:**
* 唯一索引失效,导致重复的转账交易被插入。
* 索引使用情况分析显示,索引的命中率为 0。
**解决方案:**
* 重建索引以修复索引结构。
* 检查数据源,找出导致索引失效的数据更新操作。
* 优化数据更新操作以防止索引失效。
**代码示例:**
```sql
-- 重建索引
ALTER INDEX idx_transfer_id ON transfers REBUILD;
-- 检查数据源
SELECT * FROM transfers
WHERE transfer_id IN (
SELECT transfer_id
FROM transfers
GROUP BY transfer_id
HAVING COUNT(*) > 1
);
```
# 6. 索引失效的未来趋势
随着数据库技术的发展,索引失效的未来趋势主要体现在以下两个方面:
### 6.1 自适应索引
自适应索引是一种自动调整和维护索引的机制。它通过监控查询模式和数据更新模式,动态地调整索引结构和统计信息。自适应索引可以有效地解决索引失效问题,因为它可以根据实际使用情况自动优化索引。
### 6.2 基于机器学习的索引优化
机器学习技术可以用于分析查询模式和数据更新模式,并根据分析结果优化索引结构和统计信息。基于机器学习的索引优化可以进一步提高索引的效率,并降低索引失效的风险。
**案例分析:**
**问题:**某数据库系统中存在大量索引失效问题,导致查询性能下降。
**解决方案:**采用自适应索引机制,自动调整索引结构和统计信息。经过一段时间后,索引失效问题得到有效解决,查询性能显著提升。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面深入地探讨了 Oracle 数据库的各个方面,从性能优化到数据建模,再到 DevOps 实践和人工智能应用。专栏文章涵盖了各种主题,包括:
* 揭示性能下降的根源和解决策略
* 分析和解决索引失效问题
* 诊断和解决死锁问题
* 深入了解表锁问题及其解决方案
* 探索数据一致性保障机制和事务管理
* 提供 Oracle 数据库备份和恢复的实战指南
* 介绍高可用性架构设计,包括 RAC、Data Guard 和 GoldenGate
* 分享 Oracle 数据库监控和诊断技巧
* 提供查询优化技巧,涉及索引、SQL 调优和执行计划分析
* 阐述数据建模和设计原则,包括实体关系模型、范式化和反范式化
* 介绍 PL_SQL 编程,涵盖存储过程、函数和触发器
* 探讨 XML 和 JSON 处理技术,包括 XMLType、XQuery、Web 服务、JSON 数据类型、JSON 解析和 JSON 存储
* 讨论 Oracle 数据库 DevOps 实践,包括自动化、持续集成和持续交付
* 探索 Oracle 数据库人工智能应用,涉及机器学习、自然语言处理和预测分析
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【组织转型的终极攻略】:EFQM模型在IT卓越服务中的10大应用策略
# 摘要
随着信息技术的迅速发展,IT服务的卓越管理成为了提升组织竞争力的关键。本文系统介绍了EFQM模型的核心原则及其与IT卓越服务的紧密联系。通过分析EFQM模型的基本构成和核心理念,文章阐述了该模型在促进IT组织转型、提升领导力、增强员工能力和优化服务流程中的价值和作用。接着,本文提出了一系列实用的策略实践,包括领导力提升、员工参与度提高、流程优化与创新,以及顾客关系管理和策略制定与实施。文章还通过案例分析,揭示了EFQM模型在具体实践中的应用效果及其带来的启示。最后,本文对EFQM模型在面临新兴技术挑战和市场发展趋势中的未来展望进行了探讨,强调了持续改进和长期规划的重要性。
# 关键
微信群聊管理高效法:AutoJs中的消息过滤与优化策略

# 摘要
AutoJs平台为微信群聊管理提供了强大的消息过滤技术,本文首先介绍了AutoJs的基本概念和群聊管理的概述,然后深入探讨了消息过滤技术的理论基础,包括脚本语言、过滤机制与方法、优化策略等。第三章展示了AutoJs消息过滤技术的实践应用,涵盖脚本编写、调试测试及部署
先农熵与信息熵深度对比:揭秘不同领域的应用奥秘
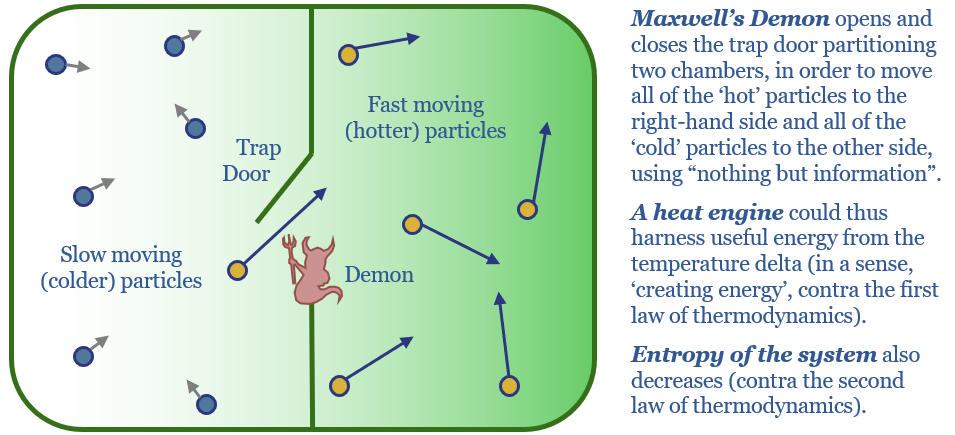
# 摘要
本文系统地探讨了熵理论的起源、发展以及在不同领域的应用。首先,我们追溯了熵理论的历史,概述了先农熵的基本概念、数学描述以及它与其他熵理论的比较。随后,文章
SRIO Gen2与PCIe Gen3性能大对决:专家指南助你选择最佳硬件接口

# 摘要
随着技术的快速发展,硬件接口技术在计算机系统中扮演着越来越重要的角色。本文旨在为读者提供对SRIO Gen2和PCIe Gen3硬件接口技术的深入理解,通过比较两者的技术特点、架构
瓦斯灾害防治:地质保障技术的国内外对比与分析
# 摘要
本文围绕地质保障技术在瓦斯灾害防治中的作用进行了全面分析。第一章介绍了瓦斯灾害的形成机理及其特点,第二章则从理论基础出发,探讨了地质保障技术的发展历程及其在瓦斯防治中的应用。第三章对比了国内外地质保障技术的发展现状和趋势,第四章通过案例分析展示了地质保障技术在实际中的应用及其对提高矿山安全的贡献。最后,第五章展望了地质保障技术的发展前景,并探讨了面临的挑战及应对策略。本文通过深入分析,强调了地质保障技术在
【推荐系统架构设计】:从保险行业案例中提炼架构设计实践

# 摘要
推荐系统作为保险行业满足个性化需求的关键技术,近年来得到了快速发展。本文首先概述了推荐系统在保险领域的应用背景和需求。随后,本文探讨了推荐系统的基本理论和评价指标,包括协同过滤、基于内容的推荐技术,以及推荐系统的架构设计、算法集成和技术选型。文中还提供了保险行业的推荐系统实践案例,并分析了数据安全、隐私保护的挑战与策略。最后,本文讨论了推荐系统在伦理与社会责任方面的考量,关注其可能带来的偏见
【Win10_Win11系统下SOEM调试全攻略】:故障诊断与优化解决方案

# 摘要
SOEM(System of Everything Management)技术在现代操作系统中扮演着至关重要的角色,尤其是在Windows 10和Windows 11系统中。本文详细介绍了SOEM的基础概念、故障诊断理论基础、实践应用以及系统优化和维护策略。通
KST_WorkVisual_40_zh与PLC通信实战:机器人与工业控制系统的无缝整合

# 摘要
本文对KST_WorkVisual_40_zh软件与PLC通信的基础进行了系统阐述,同时详述了软件的配置、使用以及变量与数据映射。进一步,文中探讨了机器人与PLC通信的实战应用,包括通信协议的选择、机器人控制指令的编写与发送,以及状态数据的读取与处理。此外,分析了KST_WorkVisual_40
【AVR编程故障诊断手册】:使用avrdude 6.3快速定位与解决常见问题

# 摘要
AVR微控制器作为嵌入式系统领域的核心技术,其编程和开发离不开工具如avrdude的支持。本文首先介绍了AVR编程基础及avrdude入门知识,然后深入探讨了avrdude命令行工具的使用方法、通信协议以及高级特性。随后,本文提供了AVR编程故障诊断的技巧和案例分析,旨
教育界的新宠:Overleaf在LaTeX教学中的创新应用

# 摘要
本文介绍了LaTeX及其在教育领域的重要性,详细阐述了Overleaf平台的入门使用方法,包括基本功能、用户界面、协作特性及版本控制。随后,文章探讨了Overleaf在制作教学材料、学生作业和学术写作中的应用实践,并分析了其高级功能和定制化方法。最后,本文评估了Overleaf在教育创新中的潜力与面临的挑战,并对其未来的发展趋势进行了展望。
# 关键字
LaTeX;Ov
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )