【Scilab异常处理】:打造健壮程序的终极指南
发布时间: 2024-12-15 19:54:24 阅读量: 3 订阅数: 7 

反归一化matlab代码-scilab_sptb:scilab_sptb
参考资源链接:[Scilab中文教程:全面指南(0.04版) - 程序设计、矩阵运算与数据分析](https://wenku.csdn.net/doc/61jmx47tht?spm=1055.2635.3001.10343)
# 1. Scilab异常处理概述
在编程的世界里,异常处理是确保软件稳定性和健壮性的重要机制。Scilab作为一款强大的数值计算软件,同样提供了异常处理功能,帮助开发人员在遇到非预期事件时,能够优雅地处理错误,保证程序的继续运行或安全退出。
异常处理不仅能够提升程序的用户体验,还能增强程序的可维护性和可扩展性。在本章中,我们将概述Scilab异常处理的基本概念、它的重要性,以及如何在Scilab环境中有效地应用异常处理来优化代码。我们将逐步深入,首先从错误类型和警告机制的了解开始,为后续章节奠定基础。
## 第一节:异常处理的重要性
异常处理机制能够捕捉那些在正常执行过程中出现的非正常情况,通过预设的代码路径对这些情况进行处理,避免程序因意外错误而崩溃。无论是在开发阶段还是在生产环境中,异常处理都是保障程序稳定运行的关键。
以下是异常处理带来的几个关键优势:
- **容错性:** 当程序中发生错误时,异常处理机制能够捕获这些错误,并允许程序继续执行或进行安全退出。
- **调试与日志记录:** 通过异常处理,可以记录错误信息和上下文,便于后续的错误分析和调试。
- **用户体验:** 妥善处理异常可以避免程序异常崩溃,减少对用户造成的困扰。
通过本章的学习,您将掌握Scilab中如何实现异常处理,并理解其在日常开发中的实践意义。让我们开始深入了解Scilab异常处理的细节。
# 2. Scilab的错误类型和警告机制
## 2.1 识别Scilab中的错误类型
### 2.1.1 语法错误
在Scilab中,语法错误是开发过程中最常见的问题之一。这类错误发生在代码不符合Scilab语法规则时,比如拼写函数名错误、缺少分号、括号不匹配等。Scilab编译器会在遇到这类错误时立即报错并阻止代码的执行。
为了识别和修正语法错误,Scilab提供了一套完整的错误信息提示系统。当出现语法错误时,Scilab会指出出错的行号,这为开发者快速定位问题提供了便利。此外,Scilab在错误提示信息中还包含了对错误类型的描述,如“expecting a ',' or a ';'”(期待一个逗号或者分号)。
```scilab
// 示例:语法错误代码段
A = [1 2 3
4 5 6]; // 缺少闭合的分号
disp(A)
```
上述代码片段会引发一个语法错误,因为矩阵`A`的定义缺少了闭合分号。Scilab会在第一行末尾的方括号后给出错误提示。
为了防止此类错误,开发者可以采取以下策略:
- 使用文本编辑器编写代码,这些编辑器通常有语法高亮和错误检查功能。
- 经常性地执行代码,小步快跑(Baby Steps)以确保每次更改后代码仍然可以正常运行。
- 仔细阅读错误提示,并且修正第一处出现的错误,再继续其他错误的修正。
### 2.1.2 运行时错误
运行时错误指的是在代码执行阶段,程序因为某些条件不满足或者资源无法访问等问题而中断。Scilab中常见的运行时错误包括但不限于数组维度不匹配、文件路径错误、除以零等。
这些错误可能不会在编译阶段被发现,但在程序执行阶段会立即显现。Scilab同样会提供错误信息和位置,帮助开发者诊断问题所在。
```scilab
// 示例:运行时错误代码段
A = [1 2; 3 4];
B = A^(-1); // 这里尝试对矩阵求逆,但如果矩阵不可逆,则引发运行时错误
disp(B)
```
在这个例子中,`A`矩阵是奇异矩阵,不能求逆,所以会出现运行时错误。Scilab会在运行到该行代码时报告错误信息。
处理运行时错误,开发者可以:
- 在代码中增加适当的检查和异常处理逻辑,比如使用`try-catch`语句来捕获运行时错误。
- 使用Scilab的调试工具,如`dbstop`来设置断点,观察错误发生时的程序状态。
- 对代码的每个关键部分进行单元测试,确保输入参数的正确性和边界条件的处理。
### 2.1.3 逻辑错误
逻辑错误是最难以发现和修正的错误类型之一。这类错误通常不会引起程序的立即崩溃,但会导致程序结果出错或者行为异常。逻辑错误源于开发者的错误假设或者错误的算法实现,比如算法实现的逻辑分支错误、迭代条件设置不当等。
Scilab没有直接的方式来识别和报告逻辑错误,开发者需要通过代码审查、逻辑分析或者对比期望输出和实际输出来识别问题。
```scilab
// 示例:逻辑错误代码段
function result = increment(value)
if (value < 0)
result = value - 1; // 逻辑错误:意图是增加数值,却执行了减法操作
else
result = value + 1;
end
endfunction
```
函数`increment`意图是给输入值加一,但由于条件判断和运算符使用错误,变成了减一操作。这个逻辑错误可能不会引发Scilab错误信息,但会得到错误的结果。
为了减少逻辑错误的发生,开发者可以:
- 编写清晰明确的需求文档,详尽描述函数或程序应该完成的任务。
- 使用版本控制系统,可以追溯修改历史,理解错误引入的具体时刻。
- 应用测试驱动开发(TDD)方法,先编写测试再编写代码,有助于明确功能实现的目标。
- 增加代码的可读性和注释,有助于其他开发者或者未来的自己理解代码逻辑。
## 2.2 Scilab中的警告处理
### 2.2.1 警告的识别和分类
Scilab在执行代码时,除了错误信息外,还会提供警告信息。警告信息通常用来提示开发者代码中潜在的问题或者不推荐的做法,但不会阻止程序的继续执行。警告的识别和分类有助于开发者理解代码的潜在问题,并且对代码进行改进。
Scilab警告信息包括但不限于:
- 变量名使用了已经弃用的函数或功能。
- 执行了不安全的类型转换操作。
- 在循环中使用了非向量操作。
```scilab
// 示例:Scilab警告代码段
A = [1, 2, 3]; // 使用逗号分隔元素,而非空格或分号
B = A * 2; // Scilab自动将A转换为列向量,但产生警告
disp(B)
```
上述代码片段会引发一个警告,因为Scilab默认是按列操作来处理不规则向量的乘法。编译器会提示:
```
Warning: The last line of this code could produce unexpected results.
```
开发者需要理解这个警告,并在必要时调整代码逻辑。
### 2.2.2 警告处理策略
处理Scilab中的警告可以采取以下策略:
- 遵守Scilab的编程最佳实践,并且确保代码风格一致性。
- 避免使用非标准的或已经弃用的Scilab功能和特性。
- 开启Scilab的编译器警告级别到最高,以便获取更详细的警告信息。
- 仔细阅读和理解每一个警告信息,评估是否需要对代码进行改进。
```scilab
// 使用Scilab的编译器警告级别指令
exec("set warning", 3); // 设置警告级别到最高
```
通过上述策略,开发者可以减少警告的产生,并提升代码质量。
## 2.3 交互式错误处理
### 2.3.1 Scilab的调试器使用
Scilab内置了一个强大的调试器,允许开发者在代码执行时中断程序,检查程序的状态。这允许开发者在特定位置查看变量的值、执行流程、堆栈信息等。交互式错误处理利用调试器来诊断和修正程序问题。
Scilab调试器提供了如下功能:
- `dbstop`:在指定行设置断点。
- `dbcont`:从当前位置继续执行。
- `dbstep`:单步执行代码。
- `dbstack`:显示当前堆栈信息。
```scilab
// 示例:使用Scilab调试器
dbstop("in myfunction at 3") // 在函数myfunction的第3行设置断点
myfunction() // 调用函数以触发断点
```
开发者可以通过逐步执行和变量检查,更好地理解程序的执行流程和变量状态。
### 2.3.2 代码分析和改进策略
交互式错误处理除了使用调试器之外,还包括对代码的持续分析和改进。这要求开发者经常性地审视和重构代码,以确保代码的健壮性和可维护性。
代码分析和改进的策略包括:
- 定期运行静态代码分析工具,如`lint`,来检测潜在的编码问题。
- 遵循代码审查制度,定期邀请同事对代码进行审查。
- 使用Scilab的性能分析工具,如`profiler`,来发现代码中的性能瓶颈。
- 编写单元测试覆盖各种边界条件,以验证代码的功能。
```scilab
// 示例:Scilab性能分析工具使用
profiler on // 开启性能分析器
// 执行一段代码
profiler off // 关闭性能分析
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
AES算法深度解码:MixColumn变换的内部机制大公开

参考资源链接:[AES加密算法:MixColumn列混合详解](https://wenku.csdn.net/doc/2rcwh8h7ph
【SolidWorks建模速成】:零基础到复杂零件构建,只需5步!

参考资源链接:[SolidWorks初学者教程:从基础到草图绘制](https://wenku.csdn.net/doc/1zpbmv5282?spm=1055.2635.3001.10343)
# 1. SolidWorks建模入门基础
SolidWorks 是一款广受欢迎的3D CAD设计软件,适用于各种工程领域,包括机械设计、汽车、航空和其他工业设计。对于刚刚接触SolidWo
【HFSS栅球建模问题全攻略】:快速识别与解决建模难题

参考资源链接:[2015年ANSYS HFSS BGA封装建模教程:3D仿真与分析](https://wenku.csdn.net/doc/840stuyum7?spm=1055.2635.3001.10343)
# 1. HFSS栅球建模基础
在现代电磁工程领域,高频结构仿真软件(HFSS)已成为不可或缺的工具之一。本章将介绍HFSS栅球建模的基础知识,旨在为初学
Sonic Visualiser插件开发入门:打造个性化音频分析工具
参考资源链接:[Sonic Visualiser新手指南:详尽功能解析与实用技巧](https://wenku.csdn.net/doc/r1addgbr7h?spm=1055.2635.3001.10343)
# 1. Sonic Visualiser插件开发入门
## 简介
Sonic Visualiser 是一个功能强大的音频分析软件,它不仅提供了一个用户友好的界面用于查看和处理音频文件,还允许开发者通过插件机制扩展其功能。本章旨在为初学者介绍Sonic Visualiser插件开发的基本概念和入门步骤。
## 开发环境准备
在开始之前,你需要准备开发环境。推荐使用Python语言进
最优化案例研究
参考资源链接:[《最优化导论》习题答案](https://wenku.csdn.net/doc/6412b73fbe7fbd1778d499de?spm=1055.2635.3001.10343)
# 1. 最优化理论基础
最优化是数学和计算机科学中的一个重要分支,旨在找到问题中的最优解,即在
【机器学习优化高频CTA策略入门】:掌握数据预处理、回测与风险管理
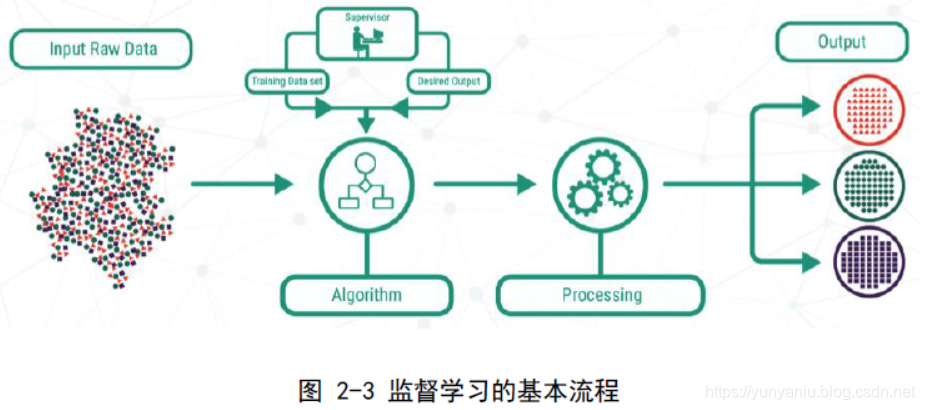
参考资源链接:[基于机器学习的高频CTA策略研究:模型构建与策略回测](https://wenku.csdn.net/doc/4ej0nwiyra?spm=1055.2635.3001.10343)
# 1. 机器学习与高频CTA策略概述
## 机器学习与高频交易的交叉
在金融领域,尤其是高频交易(CTA)策略中,机器学习技术已成为一种创新力量,它使交易者能够从历史数据中发现复杂的模
【监控与优化】实时监控Wonderware Historian性能,提升效率

参考资源链接:[Wonderware Historian与DAServer配置详解:数据采集与存储教程](https://wenk
【TIA博途V16新用户必读】:5个快速上手项目的小技巧
参考资源链接:[TIA博途V16仿真问题全解:启动故障与解决策略](https://wenku.csdn.net/doc/4x9dw4jntf?spm=1055.2635.3001.10343)
# 1. TIA博途V16界面概览
## 1.1 用户界面的初识
初识TIA博途V16,用
RK3588原理图设计深度解析:基础到高级优化技巧

参考资源链接:[RK3588硬件设计全套资料,原理图与PCB文件下载](https://wenku.csdn.net/doc/89nop3h5no?spm=1055.2635.3001.10343)
# 1. RK3588芯片架构概述
RK3588是Rockchip推出的一款高性能多核处理器,主要面向AI计算、高清视频处理和高端多媒体应用。本章将介绍RK3588的硬件架构,包括其内部构成、核心性能参数以
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )