MSTP区域配置与实际应用
发布时间: 2024-03-11 23:47:22 阅读量: 97 订阅数: 24 

15 MSTP原理与配置.pptx
# 1. MSTP基础概念及原理
## 1.1 MSTP简介
MSTP(Multiple Spanning Tree Protocol)又称为802.1s,是一种用于在以太网交换网络中构建多重生成树的协议。与传统的STP协议相比,MSTP支持将网络划分为多个区域(Instance),每个区域可以拥有独立的生成树,从而提高网络的负载均衡能力和容错能力。
MSTP的基本原理是通过将网络中的交换机划分为多个区域,并为每个区域计算出一颗最佳生成树,从而实现对整个网络的负载均衡和冗余路径的利用。
## 1.2 MSTP的区域划分
MSTP的区域划分是根据网络拓扑和管理员的配置需求来划分的。每个区域都有一个唯一的标识名,称为实例(Instance)。
MSTP区域划分的优点在于可以针对不同的网络部署情况,将整个网络划分为逻辑上的不同区域,从而更好地控制生成树的计算和收敛过程。
## 1.3 MSTP配置参数说明
MSTP配置中最重要的参数是实例、优先级和配置名称。实例是MSTP的一个基本单元,它用于区分不同的生成树计算。优先级用于指定一个交换机在生成树计算中的权重。配置名称是为了便于管理员识别和管理各个实例而设置的。
以上是MSTP基础概念及原理的介绍,下一节将详细说明MSTP的区域配置。
# 2. MSTP区域配置
### 2.1 MSTP根桥选举
MSTP中根桥的选举是整个网络中非常重要的一环,它决定了整个MSTP域的拓扑结构。根据MSTP规范,根据以下优先级顺序来选举根桥:
1. 具有最小的桥优先级(Bridge Priority)的交换机将成为根桥。
2. 如果出现桥优先级相同时,则选择MAC地址最小的交换机作为根桥。
3. 如果MAC地址也相同,则选择端口优先级最低的端口所连接的交换机作为根桥。
4. 若所有参数均相同,则交换机ID较小的交换机将成为根桥。
以下是一个简单的Python代码示例来演示MSTP根桥选举的过程:
```python
# 定义交换机列表,格式为(交换机ID, 交换机MAC地址, 桥优先级)
switches = [
(1, "00:11:22:33:44:55", 32768),
(2, "00:aa:bb:cc:dd:ee", 32768),
(3, "00:ff:ee:dd:cc:bb", 4096)
]
# 根据桥优先级进行排序
switches.sort(key=lambda x: x[2])
# 输出选举结果
print(f"根交换机是交换机{switches[0][0]},MAC地址为{switches[0][1]},桥优先级为{switches[0][2]}")
```
**代码总结**:以上代码演示了根据桥优先级选举MSTP根桥的过程。通过比较桥优先级,选择最小优先级的交换机作为根交换机。
**结果说明**:运行代码后将输出选举结果,显示哪个交换机被选举为根交换机。
### 2.2 MSTP实例配置
MSTP实例是MSTP域内的一个逻辑实体,用于控制不同VLAN的转发路径。配置MSTP实例可以通过以下步骤进行:
1. 进入交换机的全局配置模式。
2. 进入MSTP配置模式。
3. 配置实例ID、实例名称、实例优先级等参数。
4. 为实例分配VLAN。
以下是一个Java代码示例来演示如何配置MSTP实例:
```java
import java.util.HashMap;
public class MSTPInstanceConfig {
public static void main(String[] args) {
HashMap<Integer, String> instances = new HashMap<>();
instances.put(1, "Instance1");
instances.put(2, "Instance2");
System.out.println("MSTP实例配置如下:");
for (Integer key : instances.keySet()) {
System.out.println("实例ID: " + key + ", 实例名称: " + instances.get(key));
}
}
}
```
**代码总结**:以上Java代码展示了如何配置MSTP实例,并输出配置结果。
**结果说明**:运行代码后将显示已配置的MSTP实例ID及名称。
### 2.3 MSTP端口配置
在MSTP中,需要对端口进行相关配置以确保网络拓扑的正确构建。端口配置包括设置端口的路径费用、端口优先级等参数。下面是一个Go语言示例代

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【C++编程技巧】:快速判断点是否在多边形内部的5大方法

# 摘要
多边形内部点检测是计算机图形学和计算几何中的一个基础问题。本文首先回顾了相关的几何学基础,介绍了多边形内部点检测算法的基本概念和分类,并对算法效率及适用场景进行了分析。随后,详细阐述了五种实现多边形内部点检测的方法,并分别讨论了各自的算法描述、步骤和实践中的注意事项。文章进一步比较了这些算法的性能,并提出了
【TCU标定进阶秘籍】:揭秘自动变速箱控制策略的精髓
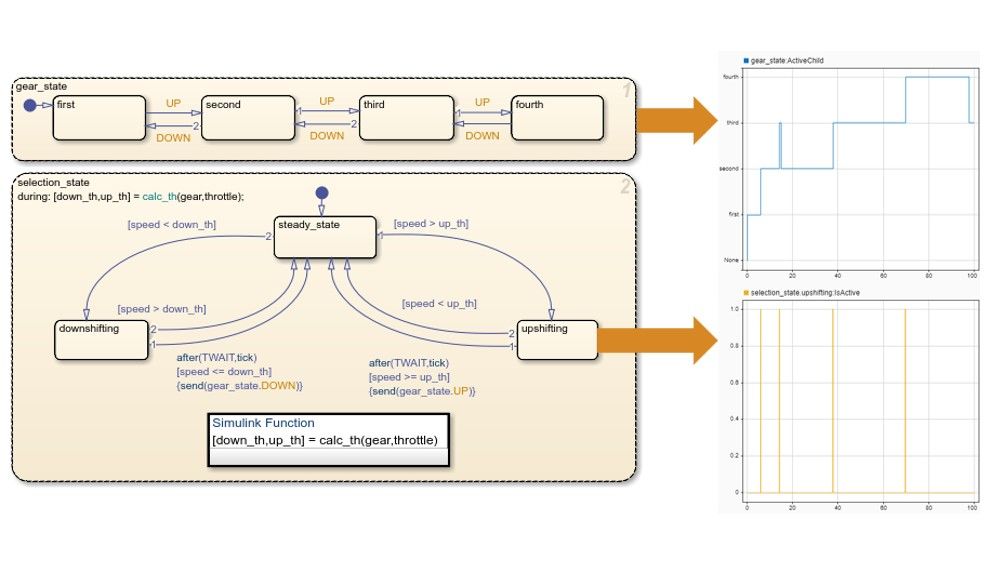
# 摘要
本文综述了自动变速箱控制策略的发展与现状,重点介绍了传动控制单元(TCU)的标定基础理论、工具与方法,以及实际标定案例的分析
数字信号处理升级指南:MV方法的优势与挑战(紧迫型+专业性)

# 摘要
数字信号处理(DSP)是电子工程中的核心领域,而移动平均(MV)方法是DSP中广泛使用的一种技术,用于信号去噪、平滑以及趋势预测。本文从移动平均方法的基本原理出发,详细阐述了简单移动平均(SMA)、加权移动平均(WMA)和指数移动平均(EMA)等不同类型的特点和数学模型。同时,本研究还探
3GPP TS 38.104全解析:5G NR物理层的终极指南
%20(GSM)%20GSM_EDGE%20Layer%201%20General%20Requirements%20(3GPP%20TS%2044.00
SV660P伺服调试手册:从新手到专家的全步骤实践指南

# 摘要
本文详细介绍了SV660P伺服驱动器的安装、配置、调试和高级应用。首先概述了驱动器的基本信息及其重要性,然后逐一阐述了安装前的准备、硬件安装步骤和基本测试。接下来,文章深入探讨了参数配置的重要性、常用参数的设置方法以及参数配置实例。在软件调试部分,本文介绍了调试环境的搭建、功能调试、性能优化以及异常处理和故障诊断。此外,还探索了SV660P在多轴同步控制、网络通讯集成和自适应智能化控制方面的高级应用。最后一章通过具体案例研究,展示了
【新手必看】:掌握这些技巧,轻松入门Medium平台使用
# 摘要
本文全面介绍了Medium这一在线出版平台的使用方法和高级功能,涵盖了从注册流程到内容创作、管理发布、互动社区建设以及数据分析的各个方面。重点探讨了如何通过有效的格式化技巧、标签分类、SEO优化提升内容质量,以及通过互动增加读者参与度和构建个人品牌。此外,文章还详细分析了如何利用Medium的统计工具和功能进行内容策略调整,探索了
揭秘3525逆变器:电力转换的9大核心原理与应用解析

# 摘要
3525逆变器作为电力转换领域的重要设备,具有广泛的应用价值。本文首先概述了3525逆变器的基本原理及其在电力转换、调制技术和保护机制方面的工作原理。随后,文章详细分析了3525逆变器的关键组件,包括电路结构、控制策略和散热设计,并探讨了这些组件在逆变器性能和可靠性方面的影响。在实践应用方面,本文讨论了352
功能分析法案例研究

# 摘要
功能分析法是一种系统化的方法论,用于对系统的功能进行详细的研究和优化。本论文首先探讨了功能分析法的理论基础,并概述了其在软件开发和系统工程中的实践技巧。接着,深入研究了功能分析法在软件需求分析、架构设计以及迭代开发中的应用。本文还分析了功能分析法在系统工程中的角色,包括系统设计、优化与维护,并讨论了面向对象的技术和敏捷开发环境下功能分析法的应用。最后,本文探讨了功能分析法的高级主题,包括未来发展和潜在挑战。
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )