【LMS故障排除速查手册】:迅速定位与解决常见问题
发布时间: 2025-01-07 07:38:34 阅读量: 16 订阅数: 12 
# 摘要
随着在线学习的普及,学习管理系统(LMS)已成为教育和培训领域的关键组成部分。本文是一本LMS故障排除速查手册的概述,旨在为LMS管理员和维护人员提供故障诊断和解决的实用指南。文章首先介绍了LMS系统架构和故障诊断的基础理论,包括系统组件、数据流、故障分类及排除步骤。随后,通过常见故障案例分析,深入探讨了用户访问问题、系统功能故障和性能瓶颈问题的具体排查方法。接着,本文讨论了故障预防措施、系统性能优化和安全性加固,以减少未来故障发生的概率,并提升系统整体性能。最后,文章强调了故障排除实践操作的重要性,并探讨了持续学习和知识管理在LMS维护中的应用。本手册的目的是通过系统的故障排除流程、工具使用和团队协作来提高LMS的可靠性和用户体验。
# 关键字
学习管理系统;故障诊断;系统性能优化;安全性加固;知识管理;故障排除实践
参考资源链接:[LMSTest.Lab中文操作指南:比利时LMS系统全面解析](https://wenku.csdn.net/doc/86xrnbcco9?spm=1055.2635.3001.10343)
# 1. LMS故障排除速查手册概述
在当今数字化时代,学习管理系统(LMS)已成为教育和企业培训不可或缺的一部分。然而,LMS也并非完美无缺,系统故障时有发生。本手册旨在为IT专业人员提供一种快速、系统的方法来识别、诊断并解决LMS故障。
我们将从故障排除的基础理论开始,然后深入介绍LMS系统的内部工作原理、日志分析的技巧,以及故障案例的分析。之后,本手册还涵盖了故障预防、系统优化以及如何有效地撰写故障报告的实践操作。
接下来,我们会介绍如何通过构建故障处理案例库、知识共享和团队协作,以及专业成长路径的规划来持续学习和提升个人能力。
无论你是系统管理员还是技术支持人员,本手册都将为您提供解决LMS故障所需的知识和工具。让我们开始吧!
# 2. 故障诊断理论基础
## 2.1 LMS系统架构理解
### 2.1.1 LMS主要组件和功能
在进行故障诊断之前,理解LMS系统的架构至关重要。LMS(Learning Management System)是一个软件应用,用于规划、实施和评价学习过程。一个典型的LMS系统包括以下主要组件:
- **用户管理模块**:负责处理用户注册、登录、权限分配等功能。
- **课程管理模块**:提供课程创建、编辑、删除以及版本控制。
- **学习内容管理**:包括视频、文档、测验、讨论区等学习资源的管理。
- **学习跟踪与评估系统**:跟踪学生的学习进度并评估学习成果。
- **报告和分析模块**:收集数据,并生成学生学习报告以及课程有效性分析。
理解这些核心组件的功能是定位故障的第一步,因为很多问题往往和特定组件的操作有关联。
### 2.1.2 数据流和系统交互原理
在LMS系统中,数据流是按照特定的模式在各个组件间流动的。用户行为数据、课程内容、学习成果等信息在系统中流动,由后端数据库存储和处理。数据交互主要通过APIs、数据库查询和前后端服务来实现。确保数据流的顺畅和准确是保证LMS系统稳定运行的关键。
系统交互原理主要依赖于以下几个方面:
- **用户界面(UI)**:是用户和系统交互的前端界面。
- **应用层(Application Layer)**:处理逻辑操作和业务规则。
- **业务逻辑层(Business Logic Layer)**:提供应用和数据的中间通信。
- **数据访问层(Data Access Layer)**:实现数据的获取、存储和修改。
对数据流和系统交互原理的深入理解,能够帮助故障排除人员确定问题发生的位置,并实施有效的解决策略。
## 2.2 故障诊断的基本原则
### 2.2.1 故障分类和特点
故障分类和特点的理解有助于快速定位问题并提出有效的解决策略。故障可以被分类为软件故障、硬件故障、网络故障和配置问题。
- **软件故障**:通常涉及代码错误、程序崩溃或者功能异常。
- **硬件故障**:可能包括服务器故障、存储设备问题、内存泄漏等。
- **网络故障**:比如连接失败、超时、数据包丢失。
- **配置问题**:系统参数设置不当或更新错误导致的问题。
了解这些特点有助于区分不同类型的故障,并使用不同的诊断方法。
### 2.2.2 故障排除的步骤和方法论
故障排除的步骤和方法论是系统性地识别和解决问题的关键。一般而言,遵循以下步骤:
1. **问题确认和记录**:首先要确定问题是什么,记录下来。
2. **问题定位**:通过日志文件、系统报告等信息,确定问题发生的范围。
3. **诊断和测试**:利用各种测试工具和方法对问题进行更深入的了解。
4. **问题解决**:根据诊断结果,采取措施解决问题。
5. **验证和后续**:确保问题彻底解决,并监测系统是否稳定。
故障排除方法论中,经常提到的“5个为什么”法则,即通过对问题连续问“为什么”五次,可以逐步深入到问题的根本原因。
## 2.3 日志分析技巧
### 2.3.1 日志文件的作用和重要性
日志文件对于故障诊断至关重要,它记录了系统运行时发生的事件、错误信息、用户操作以及系统警告等。日志文件是问题发生时的主要参考,提供了时间线以及可能的问题起因。没有详细的日志信息,进行故障诊断就如同无头苍蝇一样盲目。
### 2.3.2 日志查看和分析工具
进行日志分析时,可以借助一些强大的工具,这里以Linux系统中的常用命令为例:
```bash
# 查看实时日志
tail -f /var/log/syslog
# 日志文件搜索
grep "ERROR" /var/log/messages
# 日志文件过滤
awk '/WARN/' /var/log/httpd/error_log
```
日志文件查看之后,往往需要进一步分析,比如排序、统计等操作,以挖掘更深层次的问题原因。一些高级的日志分析工具如ELK Stack(Elasticsearch、Logstash、Kibana)可以辅助进行大规模日志数据的搜索、分析和可视化。
通过分析日志文件,故障排除人员能够快速定位到故障发生的时间、类型、相关组件以及可能的原因,极大地提高故障排查效率。
# 3. 常见故障案例分析
## 3.1 用户访问问题
### 3.1.1 用户认证失败的排查
用户认证失败是用户访问LMS系统时常见的问题。这可能是由多种原因造成的,如网络问题、用户信息错误、权限设置不当或者系统故障等。解决这个问题需要从用户、网络和系统三个角度进行排查。
首先,验证用户信息的准确性,确保用户账号密码没有输入错误,并确认用户是否存在于系统数据库中。这一步骤可以通过查询用户的认证日志来完成,通常使用类似以下的SQL查询:
```sql
SELECT * FROM users WHERE username = '输入用户名' AND password = '输入密码';
```
其次,检查网络连接是否正常,一个简单的命令如 `ping` 可以用来检测网络连通性:
```bash
ping -c 4 [系统地址]
```
如果网络没有问题,则需要检查用户权限设置。确认用户是否有足够的权限来访问系统,并且检查用户组别配置是否正确。查看用户权限相关的日志信息可以使用:
```bash
tail -f /var/log/auth.log
```
最后,如果以上步骤都无法解决问题,可能需要检查LMS系统的配置文件和数据库,看是否存在配置错误或数据库损坏的情况。通常这需要数据库管理员的权限:
```sql
SELECT * FROM system_config WHERE config_name = '认证配置项';
```
### 3.1.2 用户界面加载缓慢的问题
用户界面加载缓慢,通常与网络延迟、系统资源消耗过大或者前端性能有关。解决该问题的关键在于定位瓶颈。
首先,可以利用浏览器的开发者工具查看前端资源加载的时间,确认是否是前端脚本或资源过大导致的问题:
```javascript
// 示例代码,用于记录加载时间
console.time('loadTime');
window.onload = function() {
console.timeEnd('loadTime');
};
```
其次,检查网络延迟,可用的工具包括 `traceroute` 或 `mtr`:
```bash
traceroute [系统地址]
```
如果网络不是问题,接下来应使用系统监控工具,比如 `top` 或 `htop`,来分析CPU和内存的使用情况:
```bash
htop
```
此外,可以利用性能分析工具如 `火焰图` 来可视化找出代码执行的瓶颈。Linux系统下,可以通过以下命令生成火焰图:
```bash
perf record -F 99 -a -g -- sleep 60
perf script | stackcollapse-perf.pl | flamegraph.pl > out.svg
```
如果前端性能没问题,则考虑后端服务是否受到了负载过高的影响。可以使用 `ApacheBench` 来模拟并发请求并分析性能:
```bash
ab -n 1000 -c 100 http://[系统地址]/login
```
## 3.2 系统功能故障
### 3.2.1 课程内容无法显示
课程内容无法显示可能是由于课程内容管理系统故障、用户权限问题或者内容数据丢失导致的。排查和解决此类问题需要一系列诊断步骤。
首先,验证课程内容是否存在于数据库中:
```sql
SELECT * FROM courses WHERE course_id = '输入课程ID';
```
如果课程数据存在,接下来需要检查用户权限,确认用户是否有权限查看该课程:
```sql
SELECT * FROM user_courses WHERE user_id = '输入用户ID' AND course_id = '输入课程ID';
```
如果用户权限没有问题,那么问题可能出在内容管理系统上。检查相关服务是否正常运行:
```bash
systemctl status course_content_service
```
如果服务运行正常,那么问题可能出在内容展示的前端模板上,需要对模板文件进行检查和修复。
### 3.2.2 评分和记录不更新问题
评分和记录不更新问题通常和后端数据处理逻辑、数据库性能或者并发处理能力有关。解决该问题需要对后端服务进行逐步诊断。
首先,检查相关日志文件来了解是否有错误信息:
```bash
tail -f /var/log/lms/grading.log
```
检查数据库中最后更新的记录时间,确认数据库连接和事务是否正常:
```sql
SELECT MAX(update_time) FROM grading_records;
```
如果是由于高并发导致的更新延迟,那么可能需要优化数据库索引或者调整数据库的写入性能:
```sql
ALTER TABLE grading_records ADD INDEX (user_id, course_id);
```
此外,需要检查系统是否正确处理并发操作,可以通过压力测试来模拟并发情况:
```bash
wrk -t12 -c400 -d30s http://[系统地址]/submit_grade
```
如果测试表明系统无法有效处理高并发,则需要考虑引入消息队列等技术来平滑负载。
## 3.3 性能瓶颈问题
### 3.3.1 负载过高的分析与解决
负载过高通常是指系统在高流量下无法正常处理请求,需要对系统负载进行分析,找出瓶颈并解决。
首先,使用系统监控工具,如 `iostat`, `netstat`, `vmstat` 来监测CPU、内存、磁盘和网络的使用情况:
```bash
iostat -xz 1
vmstat 1
netstat -s
```
其次,利用应用性能管理(APM)工具,如New Relic或Dynatrace,来分析应用层面的性能问题。
如果发现CPU使用率高,需要检查是否有长时间运行的查询或进程,可以使用 `top` 或 `htop`:
```bash
htop
```
如果发现磁盘I/O成为瓶颈,则需要优化磁盘使用,例如增加缓存或者使用更快的存储设备:
```bash
echo 3 > /proc/sys/vm/drop_caches
```
网络瓶颈则需要分析网络流量,查看是否有可能的网络攻击或异常流量:
```bash
tcpdump -i eth0
```
最后,通过优化应用代码,比如缓存优化、算法优化等方法,减少系统的计算和I/O操作,提升整体性能。
### 3.3.2 数据库性能优化案例
数据库是LMS系统中非常重要的组件,其性能直接影响整个系统的性能。优化数据库性能通常涉及索引优化、查询优化、表结构优化等。
首先,检查数据库查询的执行计划来找到潜在的瓶颈:
```sql
EXPLAIN SELECT * FROM courses WHERE name LIKE '%输入关键字%';
```
如果发现查询没有利用索引,应创建合适的索引来加快查询速度:
```sql
CREATE INDEX idx_course_name ON courses(name);
```
对表结构进行优化,比如将大表分解为多个小表,可以减少锁竞争并提升访问效率。
此外,考虑读写分离和数据库集群等方式来分摊负载和提升可用性。读写分离可以使用MySQL Proxy或类似的中间件来实现。
如果系统读取操作远多于写入操作,可以考虑引入缓存机制,如Redis或Memcached来缓存常用的查询结果,减轻数据库压力。
# 4. 故障预防与系统优化
## 4.1 故障预防措施
### 4.1.1 定期系统检查和维护
为了减少系统故障的发生概率,建立定期的系统检查和维护流程至关重要。这一流程通常包括以下几个方面:
- **硬件检查**:定期对服务器硬件进行检查,确保所有的组件如硬盘、内存条、电源供应器等运行正常。
- **系统更新**:保持操作系统和相关软件的更新,包括LMS系统的应用程序和插件。
- **备份验证**:确保定期备份数据的完整性和恢复过程的可行性。
- **性能监控**:利用监控工具持续监控系统的性能指标,如CPU、内存、磁盘I/O和网络流量等。
- **日志审查**:周期性地审查系统日志,寻找可能的异常行为或错误。
- **用户反馈**:及时响应用户反馈,提前识别潜在问题。
### 4.1.2 异常监控和预警机制
异常监控和预警机制的建立是实现故障预防的关键。以下是实现这一机制的步骤:
- **监控工具部署**:选择合适的监控工具,如Nagios、Zabbix或Prometheus,并根据需要配置监控参数。
- **预警阈值设定**:根据系统正常运行的性能数据,设定合理的预警阈值。
- **预警通知设置**:配置预警通知渠道,包括电子邮件、短信或者即时通讯工具。
- **定期演练**:定期模拟故障情景以测试预警机制的有效性。
- **数据日志分析**:利用数据日志分析工具(如ELK Stack)来分析历史数据,优化预警逻辑。
### 4.1.3 代码审查与测试
持续的代码审查和测试是预防故障的重要环节。这包括:
- **单元测试**:为每个组件编写单元测试,确保其功能正确。
- **集成测试**:在代码更改后执行集成测试,验证各组件之间的交互。
- **代码审查**:定期进行代码审查,确保代码质量符合团队标准。
- **自动化测试流程**:建立自动化测试流程,减少人为错误。
## 4.2 系统性能优化
### 4.2.1 硬件升级和调整
硬件升级是提升系统性能最直接的方法。在进行硬件升级前,需要进行性能分析以确定瓶颈所在:
- **内存升级**:如果系统存在大量内存交换,表明可能需要更多的内存。
- **存储优化**:对存储设备进行升级或调整,使用更快的SSD,或设置RAID保护。
- **CPU升级**:如果CPU使用率长期居高不下,可能需要更强的CPU处理能力。
- **网络提升**:升级网络设备或调整网络设置,以减少网络延迟和提高吞吐量。
### 4.2.2 软件配置和参数调整
除了硬件升级外,软件层面的优化也同样重要。这通常涉及:
- **数据库调优**:优化数据库查询,调整缓存大小,合理配置索引。
- **应用服务器调优**:调整应用服务器的配置参数,如Apache、Nginx的连接数和缓存设置。
- **LMS系统参数优化**:根据实际使用情况调整LMS系统的参数设置。
- **负载均衡器配置**:如果部署了负载均衡器,需要调整其参数以合理分配请求。
### 4.2.3 缓存策略的实施
缓存是提高系统响应速度和处理能力的有效手段。以下是一些关于缓存策略的实施建议:
- **内容分发网络(CDN)**:使用CDN可以减少服务器的负载,并提高内容加载速度。
- **服务器端缓存**:如Redis或Memcached可用于缓存数据库查询结果和频繁访问的动态内容。
- **客户端缓存**:为静态资源设置较长的缓存时间,减少重复请求。
## 4.3 安全性加固
### 4.3.1 常见安全威胁和预防
在系统安全性方面,了解常见的安全威胁及预防方法是至关重要的:
- **DDoS攻击**:使用抗DDoS服务和基础设施保护。
- **SQL注入**:在应用程序中使用参数化查询,避免直接将用户输入用作数据库查询。
- **跨站脚本攻击(XSS)**:对用户输入进行适当的编码和清理。
- **跨站请求伪造(CSRF)**:使用CSRF令牌确保请求的安全性。
### 4.3.2 安全审核和合规性检查
进行定期的安全审核和合规性检查,确保系统符合行业安全标准:
- **漏洞扫描**:定期使用漏洞扫描工具检测系统安全漏洞。
- **安全审核工具**:如OpenVAS或Nessus可以用来进行更深入的安全审核。
- **代码审计**:检查代码是否存在已知的安全漏洞。
- **合规性标准**:如GDPR、HIPAA等标准的符合性检查。
以上章节介绍了在LMS系统中,通过实施故障预防措施、系统性能优化和安全性加固来保持系统的稳定运行。每一项措施都是为了提前识别潜在问题,并通过优化手段减少系统故障的发生,提升整体的可用性和可靠性。
# 5. 故障排除实践操作
在本章节中,我们将通过实际操作流程演示、排查工具和技巧的讲解,以及故障报告编写的要领,为读者提供一系列的故障排除实践操作指导。这些内容将帮助IT从业者更高效地处理LMS系统中的各类故障。
## 5.1 实际操作流程演示
### 5.1.1 模拟故障场景和排查
模拟故障场景对于IT专业人士来说是一个重要的技能培养环节。它不仅能够测试和验证系统架构的健壮性,还能提高我们快速定位和解决问题的能力。以下是模拟故障场景的步骤:
1. **定义故障范围**:首先确定模拟故障的范围和类型,例如,网络延迟、数据库服务不可用或某个特定功能模块的异常。
2. **模拟故障**:按照既定的故障类型,利用相应的方法模拟故障。例如,可以通过网络限速工具模拟网络延迟,或使用特定脚本模拟数据库服务中断。
3. **观察影响**:记录故障发生后系统各组件和功能的表现,注意任何异常行为或性能下降。
4. **故障排查**:遵循故障排除的步骤和方法论,从收集日志开始,逐步使用各类诊断工具和命令进行问题定位。
5. **解决故障**:找到故障原因后,执行必要的操作以解决问题,如重启服务、修复配置文件或调整系统参数。
6. **验证修复**:最后,确认问题已彻底解决,验证系统功能恢复正常,并监控一段时间以确保问题不会复发。
### 5.1.2 实际案例的故障排除步骤
在实际工作中,故障排除步骤往往是定制化的。不过,我们可以总结一些通用的步骤来指导我们进行故障排查:
1. **问题描述和初步分析**:详细记录故障发生的环境、时间、用户描述的问题现象等信息,初步分析可能的原因。
2. **收集日志和数据**:从系统中收集相关日志文件,以及运行中的数据,如性能指标、错误代码等。
3. **使用诊断工具**:运行诊断工具进行系统检查,如网络诊断、性能监控工具等。
4. **构建假设并验证**:根据收集到的信息构建故障假设,并设计实验来验证假设的正确性。
5. **隔离问题和解决方案**:一旦找到问题源头,尝试临时措施隔离问题,然后制定并实施永久性解决方案。
6. **文档记录**:记录故障的原因、排查过程和解决问题的步骤,为将来可能出现的类似问题提供参考。
## 5.2 排查工具和技巧
### 5.2.1 使用工具进行故障定位
故障排除工具是IT人员手中的利器。这里介绍几款常用的故障排查工具:
- **Wireshark**:强大的网络协议分析工具,能够捕获和分析网络流量,帮助排查网络问题。
- **Nagios**:一个开源的系统和网络监控工具,能够监控主机、服务和网络。
- **Percona Toolkit**:一组用于MySQL服务器的高级命令行工具,能够进行备份、恢复、分析、诊断等操作。
- **top/htop**:Linux下的性能监测工具,可以实时显示系统中各个进程的资源占用情况。
### 5.2.2 实用脚本和命令
掌握一些实用的Linux命令和脚本可以帮助我们快速进行故障排查。这里列举一些常见的命令和场景:
- `ifconfig` 或 `ip addr`:查看和配置网络接口。
- `netstat` 或 `ss`:查看网络连接、路由表、接口统计等信息。
- `ps`:查看系统中运行的进程。
- `top` 或 `htop`:动态监控系统资源使用情况。
- `grep`:用于过滤文本信息,在日志分析中尤为有用。
- `curl` 或 `wget`:发送HTTP请求,测试服务响应。
- `crontab -e`:编辑或查看计划任务,排查计划任务相关问题。
这些命令和脚本需要结合实际的问题场景灵活使用,并且深入理解它们的参数和功能,以便更有效地定位和解决问题。
## 5.3 故障报告编写
### 5.3.1 故障报告的标准格式
一个结构化的故障报告可以帮助团队成员快速理解问题的本质,并为未来的故障排查提供有价值的信息。故障报告通常包含以下部分:
1. **标题**:简明扼要地描述故障,便于搜索和归档。
2. **故障描述**:详细描述故障发生的时间、影响范围、用户报告的问题现象。
3. **影响评估**:说明故障对业务运营的影响程度,如服务中断时间等。
4. **排查过程**:记录排查步骤、所用工具和发现的关键信息。
5. **根本原因分析**:分析故障的根本原因,包括故障发生的直接原因和深层次的根本原因。
6. **解决措施和预防策略**:提供解决故障所采取的措施,并给出预防类似故障发生的策略建议。
7. **附件**:包括日志文件、配置文件、屏幕截图等参考资料。
8. **总结和关闭**:故障处理后的总结评价和后续监控建议。
### 5.3.2 报告编写技巧和注意事项
在编写故障报告时,应该注意以下几点:
- **清晰性**:确保报告内容条理清晰,使用逻辑性强的语言,避免冗长的描述。
- **完整性**:确保包含所有必要的信息,让不熟悉此问题的同事也能理解。
- **客观性**:基于事实和证据撰写报告,避免主观臆断。
- **精确性**:使用具体数据和信息支撑描述,避免使用模糊不清的表述。
- **简洁性**:保持简洁明了,避免无关信息的干扰。
- **可读性**:使用清晰的格式,如分点、粗体或颜色高亮关键信息,便于阅读和理解。
通过遵循这些技巧,我们能够制作出高质量的故障报告,为团队的故障处理和知识积累做出贡献。
# 6. 持续学习和知识管理
在IT行业,持续学习和知识管理是保持专业竞争力和提升服务质量的关键因素。本章节将探讨如何构建故障处理案例库,加强知识共享和团队协作,以及规划个人的专业成长路径。
## 故障处理案例库构建
故障处理案例库是记录和存档故障排除经验的重要工具,它能够帮助技术人员快速查找以往的解决方案,并从中学习。
### 案例收集和整理
收集故障案例涉及到多个来源,包括但不限于:
- 客户反馈和请求记录
- 系统日志中的错误信息
- 故障排查和解决过程的详细记录
整理这些案例时,可以创建一个标准化的模板,包含以下字段:
- 故障描述:简洁明了地概述故障现象。
- 故障日期:故障发生的具体时间。
- 故障环境:故障发生的系统环境和配置。
- 故障处理:详细的故障处理步骤和过程。
- 解决方案:故障解决后的总结和教训。
- 标签:关键词或标签,用于快速索引和搜索。
### 案例库的持续更新
为了保证案例库的有效性,定期更新是必不可少的。技术人员应该:
- 定期回顾并更新案例库中的内容,确保信息的准确性。
- 新员工入职时,将他们的经验添加到案例库中。
- 鼓励团队成员分享非正式的故障处理技巧和心得。
## 知识共享和团队协作
一个有效的知识共享体系能够促进团队协作,提高问题解决的效率。
### 知识管理系统的选择与应用
选择一个适合团队的知识管理系统(KMS)至关重要。在选择时,考虑以下因素:
- 功能性:是否支持文档管理和分享、协作工具、搜索引擎优化等。
- 可扩展性:系统是否能够随着团队的成长而扩展。
- 用户体验:界面是否直观易用,是否支持多设备访问。
一旦确定了系统,确保团队成员:
- 定期上传和更新文档、教程和故障处理案例。
- 互相评论、提问和提供反馈,以形成知识共享的良性循环。
### 团队协作在故障处理中的作用
团队协作工具如Slack、Microsoft Teams可以帮助团队成员实时交流和协作。
- 利用即时通讯进行快速问题定位。
- 使用共享白板讨论复杂问题。
- 在线协作编辑文档和报告。
## 专业成长路径规划
专业成长不仅关乎个人技能的提升,也关乎如何将这些技能转化为团队和组织的成功。
### 个人技能提升策略
技术人员应制定个人技能提升计划:
- 参加线上课程和认证培训,获取最新的技术知识。
- 定期阅读行业报告和专业杂志。
- 主动参与内部和外部的技术交流会议。
### 参与专业社区和论坛
加入专业社区和论坛,可以让你:
- 跟踪行业动态和最新的技术趋势。
- 与其他技术人员交流心得,获取新的观点和解决方案。
- 参与开源项目,贡献代码或文档,提升个人影响力。
通过持续学习和积极参与知识管理,IT从业者不仅能够提高个人的故障处理能力,还能够推动团队和组织不断进步,进而提升整个企业的服务水平和竞争力。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《LMS测试系统操作指南》专栏是一份全面的指南,涵盖了LMS(学习管理系统)测试的各个方面。专栏提供了一系列文章,从入门指南到高级数据分析和系统集成,帮助用户快速掌握LMS测试操作和配置。此外,专栏还提供了故障排除速查手册、性能优化秘籍和用户体验优化指南,以解决常见问题并提升测试效率。专栏还深入探讨了数据管理、监控和日志分析,以及LMS的部署、配置和维护升级。最后,专栏还提供了最新的LMS动态、自定义模板制作和国际化测试策略,帮助用户充分利用LMS的功能并优化测试流程。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
GPS信号失步之谜:FPGA策略快速应对(原因分析及解决方案)
# 摘要
全球定位系统(GPS)信号失步问题影响着定位的准确性和可靠性。本文首先概述了GPS信号失步的现状和影响因素,然后分析了现场可编程门阵列(FPGA)技术在GPS系统中的应用及其优势。通过深入探讨环境因素、设备故障、软件缺陷对GPS信号失步的具体影响,本文提出了一系列基于FPGA的策略,包括实时监控诊断机制、硬件容错设计和软件算法优化,以应对GPS信号失步问题。最后,本文通过案例研究
G120变频器CU240BE快速精通:一步到位的安装与配置教程

# 摘要
本文对西门子G120变频器CU240BE进行详细的技术介绍,涵盖其硬件安装、参数配置、软件操作与维护,以及进阶应用等多个方面。首先概述了变频器的硬件组件及其功能,并详述了安装过程和检查方法。接着,本文深入讨论了基础与高级参数的设置,包括电机数据配
部署不再难:揭秘Preseed文件在传统BIOS中的5个应用案例

# 摘要
Preseed文件作为自动化安装Linux系统的一种有效工具,在现代数据中心部署中扮演着重要角色。本文全面概述了Preseed文件的基础理论、定制配置以及实践应用,并深入探讨了BIOS与UEFI环境下的差异、关键配置选项和高级配置技巧。文章还提供了
【Western Blot图像分析】:灰度分析的理论基础与实践指南
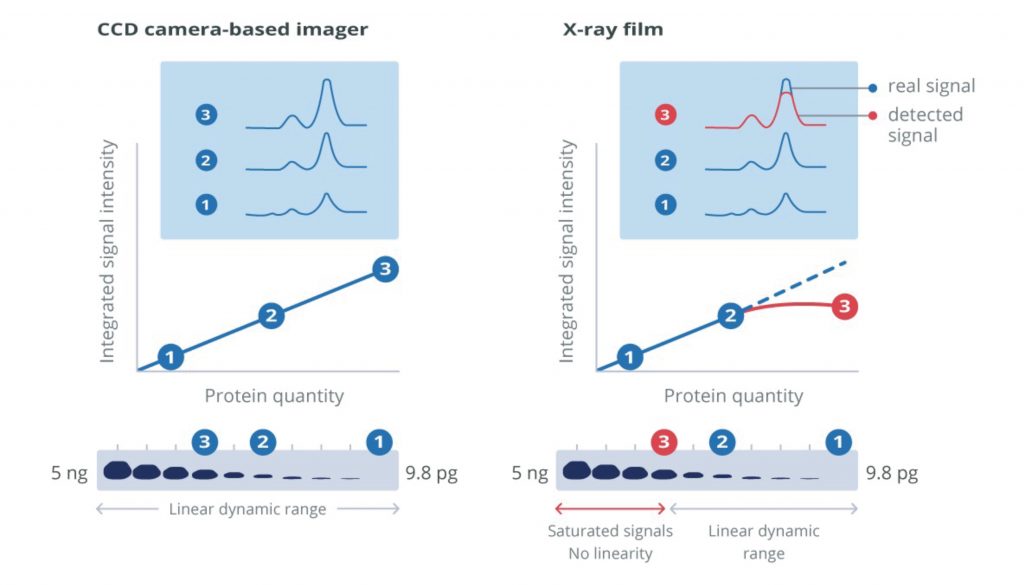
# 摘要
Western Blot技术是一种广泛应用于生物学和医学研究中的蛋白质分析方法。本文全面概述了Western Blot技术,包括图像的获取、预处理、灰度分析的理论基础及实践操作。文中详细介绍了实验室条件下图像采集技术和预处理技巧,探讨了灰度分析中的参数设置以及在蛋白质定量中的应用。同时,本文还阐述了在实验中
【698协议数据包结构深度解析】:解锁智能电表数据解读之道

# 摘要
本论文首先对698协议进行全面概述,紧接着深入分析其数据包结构,包括起始与结束标记、长度及校验机制,以及关键字段的作用和数据区域的构成。通过解码过程和实际应用案例,本论文展示了
揭秘电磁干扰:GJB_151B-2013标准实战解析与应用

# 摘要
本文深入探讨了电磁干扰(EMI)的基础理论、标准解读、实战测试技术、预防与控制实践以及系统级兼容性分析。通过对GJB_151B-2013标准的详细解读,本文分析了标准的起源、目的、测试项目和试验等级。实战测试技术章节提供了测试准备、实施测试及案例分析的系统性指导。预防与控制实践章节强调了硬件和软件设计阶段的EMI控制策略,并讨论了系统集成与维护阶段的管理。系统级兼容性分析章节则侧重于兼容性设计原则和
【MQTT客户端终极指南】:MQTTFX 1.7.1版本详解及实用技巧

# 摘要
本文详细介绍了MQTT协议的基础知识、客户端的使用方法、MQTTFX的特性以及实战技巧。首先概述了MQTT协议及其在MQTTFX环境下的应用,接着深入解析了MQTT客户端的连接流程、消息发布订阅机制和安全性设置。第三章分析了MQTTFX 1.7.1版本的新特性和高级配置,以及跨平台
【八路抢答器设计秘籍】:打造高效教学互动工具的10大策略

# 摘要
本文全面介绍了八路抢答器的设计概念、基础功能实现、高级功能开发、教学应用场景实践以及未来的展望与发展趋势。通过对硬件选择与布局、信号处理逻辑、用户交互设计的深入探讨,本文揭示了八路抢答器如何有效地实现基础互动功能,并通过并发管理、数据统计分析以及网络功能拓展来提升其高级应用性能。在教学应用场景中,文章探讨了八路抢答器如何创新课堂
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )