引入Apollo Client优化React应用中GraphQL数据管理
发布时间: 2024-02-22 14:57:16 阅读量: 32 订阅数: 17 
# 1. 理解GraphQL和Apollo Client
## 1.1 介绍GraphQL的基本概念
GraphQL是一种由Facebook开发的查询语言和运行时。它旨在提供一种更高效、强大和灵活的方式来与API进行交互。与传统的RESTful API相比,GraphQL允许客户端精确地指定其需要的数据结构,从而减少了不必要的数据传输和提高了数据请求的灵活性。
GraphQL的基本概念包括:
- **类型系统**: 定义数据的结构和操作
- **查询语言**: 定义客户端请求的数据
- **解析器**: 处理客户端查询,并从数据源中取出所需数据
- **单一端点**: 所有的数据查询都通过单一的HTTP端点进行
## 1.2 Apollo Client的作用和优势
Apollo Client是一个强大的状态管理库,专门用于与GraphQL API通信。它可以轻松地集成到React、Vue等流行的框架中,并提供了许多有用的功能,如数据缓存、本地状态管理、执行查询、订阅和优化网络请求。
Apollo Client的优势包括:
- **跨平台支持**: 可以与任何JavaScript框架一起使用
- **数据缓存**: 自动管理数据缓存,减少不必要的网络请求
- **本地状态管理**: 可以集成到React应用中,统一管理远程和本地数据状态
## 1.3 为什么在React应用中选择Apollo Client管理GraphQL数据
在React应用中选择Apollo Client管理GraphQL数据的优势包括:
- **集成性**: 可以直接集成到React应用中,并与现有的数据管理方案共存
- **数据缓存**: 自动管理数据缓存,减少对服务器的频繁请求
- **实时更新**: 支持GraphQL的实时数据更新和订阅功能
- **开发便利**: 提供了丰富的开发工具和开发者体验
在接下来的章节中,我们将会详细介绍如何安装、配置和使用Apollo Client来优化React应用中的GraphQL数据管理。
# 2. 安装和配置Apollo Client
在本章中,我们将详细介绍如何安装和配置Apollo Client,以便在React应用中管理GraphQL数据。我们将学习如何设置Apollo Client并集成到React应用中,以及如何配置GraphQL服务器端链接和数据源。
#### 2.1 安装和设置Apollo Client
首先,我们需要通过npm或yarn安装Apollo Client库。在项目目录中打开终端,并执行以下命令:
```bash
npm install @apollo/client graphql
```
或者使用yarn:
```bash
yarn add @apollo/client graphql
```
安装完成后,我们就可以开始配置Apollo Client了。
#### 2.2 配置Apollo Client和React应用的集成
我们需要在应用的顶层组件中配置Apollo Client。首先,在项目中创建一个Apollo Client实例,然后使用`ApolloProvider`组件将其提供给整个应用。
```jsx
// apollo.js
import { ApolloClient, InMemoryCache } from '@apollo/client';
const client = new ApolloClient({
uri: 'http://your-graphql-server.com/graphql',
cache: new InMemoryCache(),
});
export default client;
```
然后,在应用的入口文件中将Apollo Client与React应用集成:
```jsx
// index.js
import React from 'react';
import ReactDOM from 'react-dom';
import { ApolloProvider } from '@apollo/react-hooks';
import client from './apollo';
import App from './App';
ReactDOM.render(
<ApolloProvider client={client}>
<App />
</ApolloProvider>,
document.getElementById('root')
);
```
#### 2.3 设置GraphQL服务器端链接和数据源
在配置Apollo Client时,我们需要提供GraphQL服务器端的链接地址。这个链接通常指向一个GraphQL HTTP服务端点。同时,我们也可以配置其他数据源,比如WebSocket等,以实现实时数据订阅和推送。
```jsx
// apollo.js
import { ApolloClient, InMemoryCache, HttpLink, split } from '@apollo/client';
import { WebSocketLink } from '@apollo/client/link/ws';
import { getMainDefinition } from '@apollo/client/utilities';
const httpLink = new HttpLink({
uri: 'http://your-graphql-server.com/graphql',
});
const wsLink = new WebSocketLink({
uri: 'ws://your-graphql-server.com/graphql',
options: {
reconnect: true,
},
});
const link = split(
({ query }) => {
const defin
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏将带领读者深入探索在React中如何利用GraphQL实现实时聊天室。从初步了解GraphQL及其应用开始,到在React应用中集成GraphQL客户端,使用GraphQL Schema定义数据结构,再利用Queries与Mutations实现数据交互,探索Subscriptions实现实时通信功能,以及组件渐进式加载GraphQL数据等方面展开讨论。通过引入Apollo Client优化数据管理,构建消息发送与接收组件,引入分布式查询加速数据查询,实现消息提示功能,以及消息撤回与编辑功能,最终展示GraphQL与React的强大交互能力。这一系列文章将帮助读者全面理解并运用GraphQL与React开发出高效的实时聊天应用。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
NVIDIA ORIN NX性能基准测试:超越前代的关键技术突破
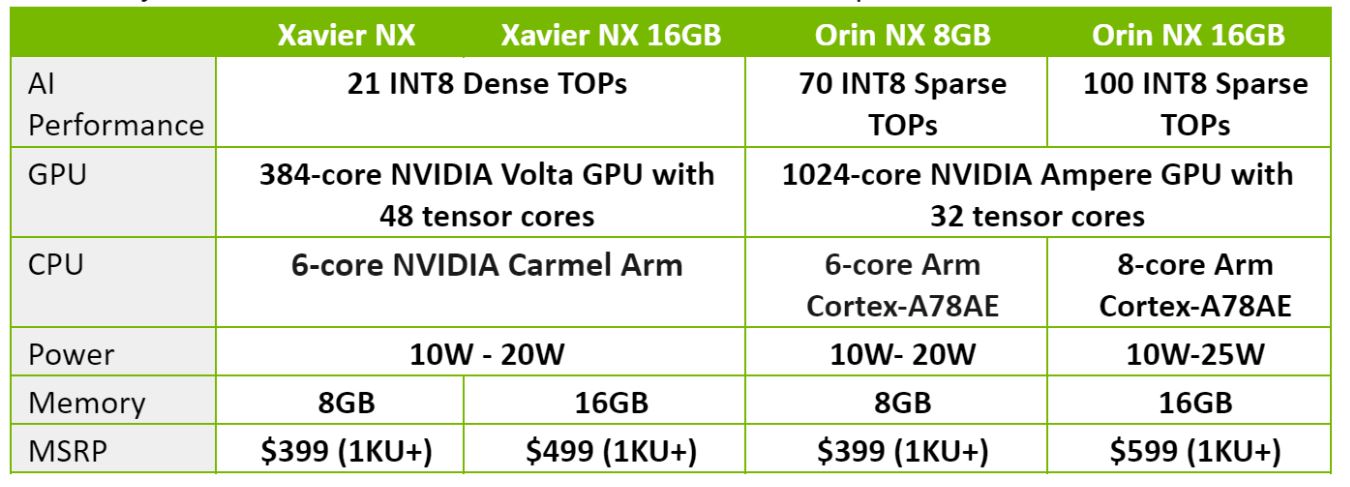
# 摘要
本文全面介绍了NVIDIA ORIN NX处理器的性能基准测试理论基础,包括性能测试的重要性、测试类型与指标,并对其硬件架构进行了深入分析,探讨了处理器核心、计算单元、内存及存储的性能特点。此外,文章还对深度学习加速器及软件栈优化如何影响AI计算性能进行了重点阐述。在实践方面,本文设计了多个实验,测试了NVI
图论期末考试必备:掌握核心概念与问题解答的6个步骤

# 摘要
图论作为数学的一个分支,广泛应用于计算机科学、网络分析、电路设计等领域。本文系统地介绍图论的基础概念、图的表示方法以及基本算法,为图论的进一步学习与研究打下坚实基础。在图论的定理与证明部分,重点阐述了最短路径、树与森林、网络流问题的经典定理和算法原理,包括Dijkstra和Floyd-Warshall算法的详细证明过程。通过分析图论在社交网络、电路网络和交通网络中的实际应用,本文探讨了图论问题解决策略和技巧,包括策略规划、数学建模与软件
【无线电波传播影响因素详解】:信号质量分析与优化指南
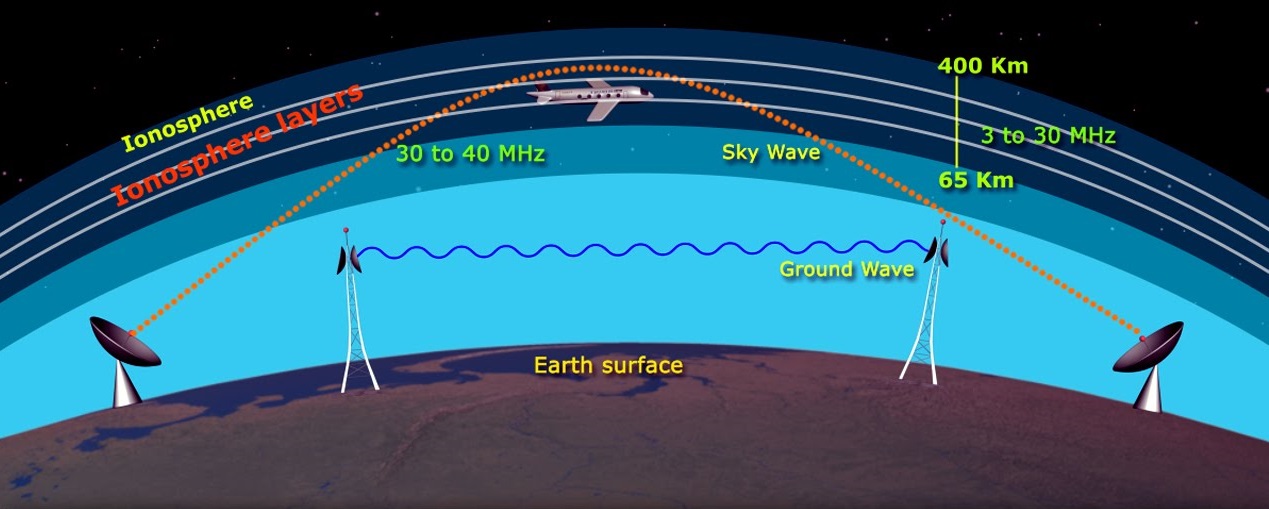
# 摘要
本文综合探讨了无线电波传播的基础理论、环境影响因素以及信号质量的评估和优化策略。首先,阐述了大气层、地形、建筑物、植被和天气条件对无线电波传播的影响。随后,分析了信号衰减、干扰识别和信号质量测量技术。进一步,提出了包括天线技术选择、传输系统调整和网络规划在内的优化策略。最后,通过城市、农村与偏远地区以及特殊环境下无线电波传播的实践案例分析,为实际应用提供了理论指导和解决方案。
# 关键字
无线电波传播;信号衰减;信号干扰;信号
FANUC SRVO-062报警:揭秘故障诊断的5大实战技巧

# 摘要
FANUC SRVO-062报警是工业自动化领域中伺服系统故障的常见表现,本文对该报警进行了全面的综述,分析了其成因和故障排除技巧。通过深入了解FANUC伺服系统架构和SRVO-062报警的理论基础,本文提供了详细的故障诊断流程,并通过伺服驱动器和电机的检测方法,以及参数设定和调整的具体操作
【单片微机接口技术速成】:快速掌握数据总线、地址总线与控制总线
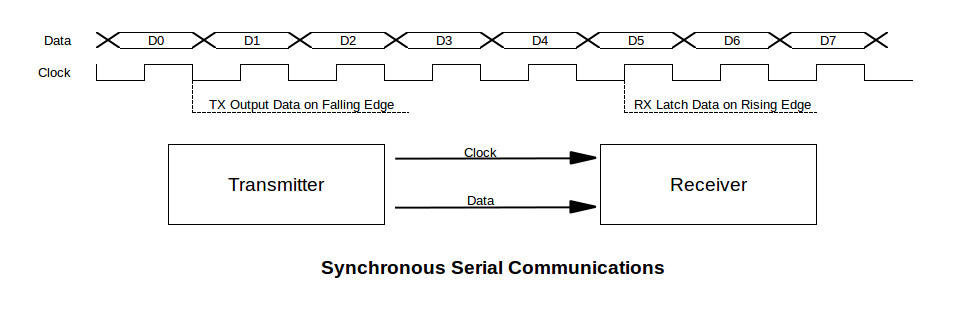
# 摘要
本文深入探讨了单片微机接口技术,重点分析了数据总线、地址总线和控制总线的基本概念、工作原理及其在单片机系统中的应用和优化策略。数据总线的同步与异步机制,以及其宽度对传输效率和系统性能的影响是本文研究的核心之一。地址总线的作用、原理及其高级应用,如地址映射和总线扩展,对提升寻址能力和系统扩展性具有重要意义。同时,控制总线的时序控制和故障处理也是确保系统稳定运行的关键技术。最后
【Java基础精进指南】:掌握这7个核心概念,让你成为Java开发高手

# 摘要
本文全面介绍了Java语言的开发环境搭建、核心概念、高级特性、并发编程、网络编程及数据库交互以及企业级应用框架。从基础的数据类型和面向对象编程,到集合框架和异常处理,再到并发编程和内存管理,本文详细阐述了Java语言的多方面知识。特别地,对于Java的高级特性如泛型和I/O流的使用,以及网络编程和数据库连接技
电能表ESAM芯片安全升级:掌握最新安全标准的必读指南
# 摘要
ESAM芯片作为电能表中重要的安全组件,对于确保电能计量的准确性和数据的安全性发挥着关键作用。本文首先概述了ESAM芯片及其在电能表中的应用,随后探讨了电能表安全标准的演变历史及其对ESAM芯片的影响。在此基础上,深入分析了ESAM芯片的工作原理和安全功能,包括硬件架构、软件特性以及加密技术的应用。接着,本文提供了一份关于ESAM芯片安全升级的实践指南,涵盖了从前期准备到升级实施以及后
快速傅里叶变换(FFT)实用指南:精通理论与MATLAB实现的10大技巧
# 摘要
快速傅里叶变换(FFT)是信号处理和数据分析的核心技术,它能够将时域信号高效地转换为频域信号,以进行频谱分析和滤波器设计等。本文首先回顾FFT的基础理论,并详细介绍了MATLAB环境下FFT的使用,包括参数解析及IFFT的应用。其次,深入探讨了多维FFT、离散余弦变换(DCT)以及窗函数在FFT中的高级应用和优化技巧。此外,本文通过不同领域的应用案例
【高速ADC设计必知】:噪声分析与解决方案的全面解读

# 摘要
高速模拟-数字转换器(ADC)是现代电子系统中的关键组件,其性能受到噪声的显著影响。本文系统地探讨了高速ADC中的噪声基础、噪声对性能的影响、噪声评估与测量技术以及降低噪声的实际解决方案。通过对噪声的分类、特性、传播机制以及噪声分析方法的研究,我们能
【Python3 Serial数据完整性保障】:实施高效校验和验证机制
# 摘要
本论文首先介绍了Serial数据通信的基础知识,随后详细探讨了Python3在Serial通信中的应用,包括Serial库的安装、配置和数据流的处理。本文进一步深入分析了数据完整性的理论基础、校验和验证机制以及常见问题。第四章重点介绍了使用Python3实现Serial数据校验的方法,涵盖了基本的校验和算法和高级校验技
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )