【LSTM在NLP中的影响】:探索自然语言处理的未来,深度学习的最新进展
发布时间: 2024-12-13 23:57:29 阅读量: 12 订阅数: 16 

自然语言处理之AI深度学习实战视频教程

参考资源链接:[LSTM长短期记忆网络详解及正弦图像预测](https://wenku.csdn.net/doc/6412b548be7fbd1778d42973?spm=1055.2635.3001.10343)
# 1. LSTM基本原理及在NLP中的重要性
## 1.1 LSTM的历史与基本原理
长短期记忆网络(LSTM)是一种特殊的循环神经网络(RNN),由Hochreiter和Schmidhuber于1997年提出。LSTM的引入是为了克服传统RNN在长序列学习中遇到的梯度消失或梯度爆炸问题。它通过引入三个门控结构—遗忘门(forget gate)、输入门(input gate)以及输出门(output gate),有效地调节信息的流动,决定哪些信息应该被保留或遗忘。
## 1.2 LSTM在自然语言处理(NLP)中的重要性
在NLP领域,LSTM扮演了至关重要的角色,它能够处理和记忆长距离依赖关系,这对于理解语言的上下文非常重要。例如,在文本生成、机器翻译、情感分析和语言模型构建等任务中,LSTM通过保持长期的状态记忆,极大地提升了模型的性能和准确性。其能够捕捉到复杂语言结构中的细微差别,这使得LSTM成为NLP发展的关键推动力。
# 2. LSTM网络的结构与训练技术
### LSTM单元的工作原理
循环神经网络(Recurrent Neural Networks, RNNs)在处理序列数据时因其能够维持历史信息而受到青睐,但随着序列的增加,传统RNNs容易出现梯度消失或梯度爆炸的问题。长短期记忆网络(Long Short-Term Memory, LSTM)是为了解决这类问题而被提出的一种特殊类型的RNN。
#### LSTM的门控机制解析
LSTM的核心是其独特的门控结构,它允许网络学习长期依赖性。LSTM由三个主要的门控组成:遗忘门(forget gate)、输入门(input gate)和输出门(output gate)。每个门控都由一个sigmoid神经网络层和一个点乘操作组成。
- **遗忘门(Forget Gate)**:决定哪些信息从细胞状态中被丢弃。它通过查看上一个隐藏状态和当前输入来决定保留还是遗忘信息。
```python
import numpy as np
# 假设h_t-1是前一个隐藏状态,x_t是当前输入,W_f是权重矩阵
# b_f是偏置项,f是遗忘门的输出
W_f = np.random.uniform(size=(hidden_state_size, input_state_size))
b_f = np.random.uniform(size=(hidden_state_size, 1))
f = sigmoid(np.dot(W_f, x_t) + np.dot(U_f, h_t-1) + b_f)
```
- **输入门(Input Gate)**:决定哪些新信息被存储在细胞状态中。输入门有两个部分,一个决定新信息的价值,另一个决定输入值的权重。
```python
# W_i和U_i分别对应输入门权重和更新权重
W_i = np.random.uniform(size=(input_state_size, input_state_size))
U_i = np.random.uniform(size=(input_state_size, hidden_state_size))
b_i = np.random.uniform(size=(input_state_size, 1))
# i是输入门输出,g是新候选值
i = sigmoid(np.dot(W_i, x_t) + np.dot(U_i, h_t-1) + b_i)
g = np.tanh(np.dot(W_g, x_t) + np.dot(U_g, h_t-1) + b_g)
```
- **输出门(Output Gate)**:决定下一个隐藏状态的值。输出基于细胞状态经过一个tanh层后被缩放,与输出门相乘。
```python
# W_o和U_o分别对应输出门权重和输出权重
W_o = np.random.uniform(size=(output_state_size, input_state_size))
U_o = np.random.uniform(size=(output_state_size, hidden_state_size))
b_o = np.random.uniform(size=(output_state_size, 1))
o = sigmoid(np.dot(W_o, x_t) + np.dot(U_o, h_t-1) + b_o)
h_t = o * np.tanh(c_t)
```
细胞状态(cell state)是LSTM的关键组件,通过门控机制更新其值。通过这些门,LSTM能够保护和控制细胞状态,从而避免了RNN中的梯度消失问题。
| 门控类型 | 功能描述 |
| --- | --- |
| 遗忘门 | 决定丢弃或保留历史信息 |
| 输入门 | 决定新信息如何影响细胞状态 |
| 输出门 | 决定下一个隐藏状态的内容 |
通过门控机制的综合作用,LSTM可以长期维持信息而不会受到梯度消失或梯度爆炸的影响。这使得LSTM在处理长序列数据时具有独特的优势。
#### LSTM与传统RNN的比较
LSTM与传统RNN的主要区别在于其内部的门控机制。传统RNNs简单地通过一个权重矩阵来传递信息,这导致了在长序列上难以捕捉长期依赖关系。而LSTM则通过复杂的门控结构来控制信息的流入和流出,能够有效地捕获长距离的依赖关系。
| 比较项 | 传统RNN | LSTM |
| --- | --- | --- |
| 结构复杂性 | 相对简单,信息通过单一权重矩阵传递 | 结构复杂,包括三个门控和细胞状态 |
| 梯度问题 | 梯度消失或梯度爆炸 | 通过门控机制避免了梯度问题 |
| 长期依赖 | 难以处理 | 能够有效地处理 |
综上所述,LSTM凭借其独特的门控机制克服了传统RNN在长期依赖任务上的不足,使其在处理诸如语言模型、时间序列预测等复杂任务时表现更佳。在下一节中,我们将深入探讨LSTM的训练策略,包括数据预处理、向量化以及解决梯度消失和梯度爆炸问题的方法。
# 3. LSTM在NLP中的应用实例
在深度学习的众多分支中,自然语言处理(NLP)是一个研究和应用都非常活跃的领域。LSTM作为一种特殊的循环神经网络,因其能有效解决长期依赖问题而被广泛应用于NLP中。本章节将探讨LSTM在NLP中的具体应用实例,包括文本分类、序列生成任务以及语言模型构建。
## 3.1 LSTM在文本分类中的应用
文本分类是NLP中的一个基础任务,涉及将文本数据归入一个或多个类别。LSTM模型在此类任务中以其强大的序列建模能力而脱颖而出。
### 3.1.1 情感分析的案例研究
情感分析是文本分类的一个典型例子,目的是判断文本表达的情绪倾向,如积极或消极。LSTM在情感分析中的优势在于其能够捕捉长距离的依赖关系,这对于理解句子中的复杂情感至关重要。
下面是一个使用LSTM进行情感分析的基本代码示例:
```python
from keras.models import Sequential
from keras.layers import Embedding, LSTM, Dense
# 假设已经预处理好的数据集为X_train和y_train
model = Sequential()
model.add(Embedding(input_dim=vocab_size, output_dim=embedding_dim, input_length=max_length))
model.add(LSTM(units=128, dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X_train, y_train, batch_size=32, epochs=10)
```
在这个模型中,首先使用`Embedding`层将输入的单词转换为密集的向量表示,然后通过`LSTM`层进行序列的处理,最后通过`Dense`层输出情感分类的结果。这里的`dropout`和`recurrent_dropout`参数是为了防止过拟合而设置的正则化技术。
### 3.1.2 文章主题分类的实现方法
文章主题分类的目标是将文本数据分配到预定义的类别中,例如将新闻报道分类到政治、体育、经济等类别。LSTM模型可以有效地学习到文本数据中的主题

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了LSTM(长短时记忆)神经网络,从基础原理到高级应用。它涵盖了LSTM在时间序列预测、自然语言处理、图像描述和医疗诊断中的广泛应用。专栏还提供了LSTM的选型秘籍、实战指南、训练加速术、变体解析、模型优化技术和多模态学习融合方法。此外,它还比较了TensorFlow和PyTorch框架中LSTM的实现,并提供了推荐系统和医疗诊断中LSTM的革新性应用案例。通过本专栏,读者可以全面掌握LSTM神经网络,提升AI模型的性能,并探索其在各种领域的创新应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
HALCON基础教程:轻松掌握23.05版本HDevelop操作符(专家级指南)

# 摘要
本文全面介绍HALCON 23.05版本HDevelop环境及其图像处理、分析和识别技术。首先概述HDevelop开发环境的特点,然后深入探讨HALCON在图像处理领域的基础操作,如图像读取、显示、基本操作、形态学处理等。第三章聚焦于图像分析与识别技术,包括边缘和轮廓检测、图像分割与区域分析、特征提取与匹配。在第四章中,本文转向三维视觉处理,介绍三维
【浪潮英信NF5460M4安装完全指南】:新手也能轻松搞定
# 摘要
本文详细介绍了浪潮英信NF5460M4服务器的安装、配置、管理和性能优化过程。首先概述了服务器的基本信息和硬件安装步骤,包括准备工作、物理安装以及初步硬件设置。接着深入讨论了操作系统的选择、安装流程以及基础系统配置和优化。此外,本文还包含了服务器管理与维护的最佳实践,如硬件监控、软件更新与补丁管理以及故障排除支持。最后,通过性能测试与优化建议章节,本文提供了测试工具介绍、性能调优实践和长期维护升级规划,旨在帮助用户最大化服务器性能并确保稳定运行。
# 关键字
服务器安装;操作系统配置;硬件监控;软件更新;性能测试;故障排除
参考资源链接:[浪潮英信NF5460M4服务器全面技术手
ACM动态规划专题:掌握5大策略与50道实战演练题
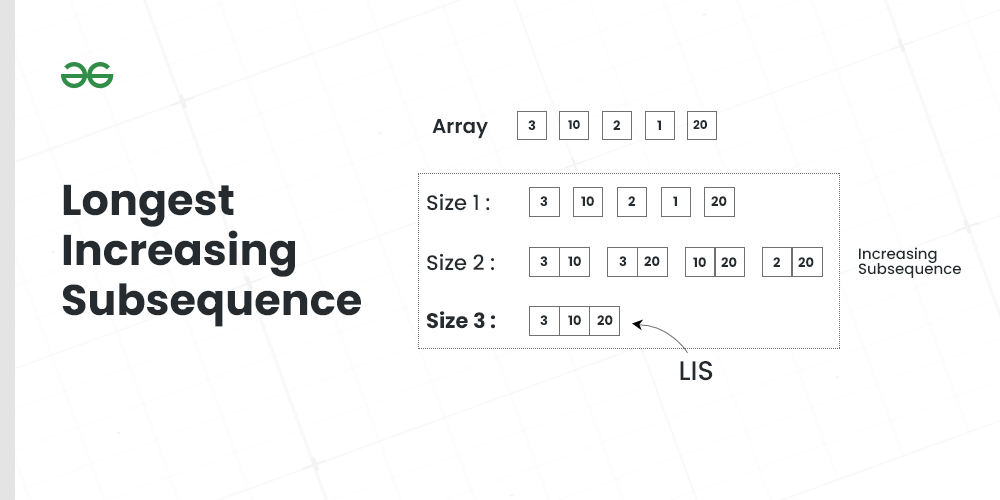
# 摘要
动态规划是解决复杂优化问题的一种重要算法思想,涵盖了基础理论、核心策略以及应用拓展的全面分析。本文首先介绍了ACM中动态规划的基础理论,并详细解读了动态规划的核心策略,包括状态定义、状态转移方程、初始条件和边界处理、优化策略以及复杂度分析。接着,通过实战演练的方式,对不同难度等级的动态规划题目进行了深入的分析与解答,涵盖了背包问题、数字三角形、石子合并、最长公共子序列等经典问题
Broyden方法与牛顿法对决:非线性方程组求解的终极选择

# 摘要
本文旨在全面探讨非线性方程组求解的多种方法及其应用。首先介绍了非线性方程组求解的基础知识和牛顿法的理论与实践,接着
【深度剖析】:掌握WindLX:完整用户界面与功能解读,打造个性化工作空间
# 摘要
本文全面介绍了WindLX用户界面的掌握方法、核心与高级功能详解、个性化工作空间的打造技巧以及深入的应用案例研究。通过对界面定制能力、应用管理、个性化设置等核心功能的详细解读,以及窗口管理、集成开发环境支持和多显示器设置等高级功能的探索,文章为用户提供了全面的WindLX使用指导。同时,本文还提供了实际工作
【数学建模竞赛速成攻略】:6个必备技巧助你一臂之力
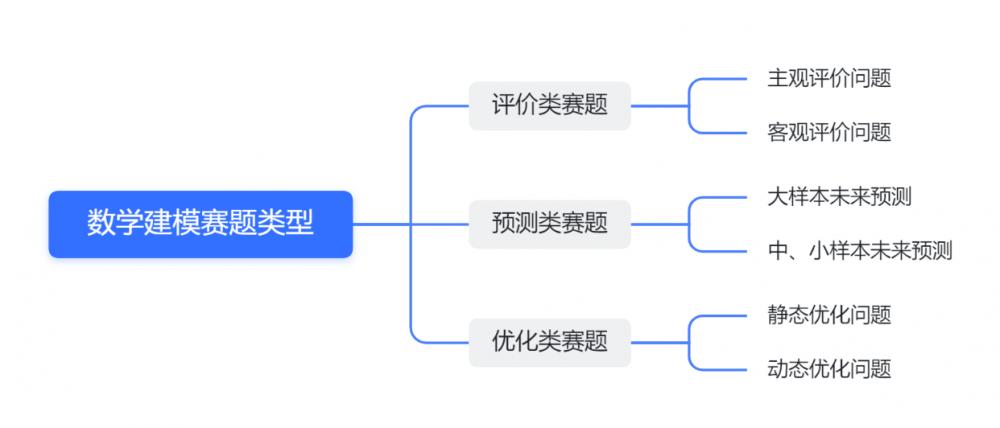
# 摘要
数学建模竞赛是一项综合性强、应用广泛的学术活动,旨在解决实际问题。本文旨在全面介绍数学建模竞赛的全过程,包括赛前准备、基本理论和方法的学习、实战演练、策略和技巧的掌握以及赛后分析与反思。文章详细阐述了竞赛规则、团队组建、文献收集、模型构建、论文撰写等关键环节,并对历届竞赛题目进行了深入分析。此外,本文还强调了时间管理、团队协作、压力管理等关键策略,以及对个人和团队成长的反思,以及对
【SEED-XDS200仿真器使用手册】:嵌入式开发新手的7日速成指南
# 摘要
SEED-XDS200仿真器作为一款专业的嵌入式开发工具,其概述、理论基础、使用技巧、实践应用以及进阶应用构成了本文的核心内容。文章首先介绍了SEED-XDS200仿真器的硬件组成及其在嵌入式系统开发中的重要性。接着,详细阐述了如何搭建开发环境,掌握基础操作以及探索高级功能。本文还通过具体项目实战,探讨了如何利用仿真器进行入门级应用开发、系统性能调优及故障排除。最后,文章深入分析了仿真器与目标系统的交互,如何扩展第三方工具支持,以及推荐了学习资源,为嵌入式开发者提供了一条持续学习与成长的职业发展路径。整体而言,本文旨在为嵌入式开发者提供一份全面的SEED-XDS200仿真器使用指南。
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )