前端路由原理与单页应用(SPA)开发
发布时间: 2023-12-08 14:13:25 阅读量: 30 订阅数: 41 

详解vue 单页应用(spa)前端路由实现原理
# 1. 前端路由原理
## 1.1 什么是前端路由
前端路由是指通过在前端页面中动态改变URL,实现页面之间的切换和展示内容的变化的一种技术。传统的后端路由是在服务器端根据URL的不同返回不同的页面内容,而前端路由则是直接在前端页面中根据URL的变化进行页面展示。
## 1.2 前端路由与传统路由的区别
传统的路由是基于URL的,通过不同的URL地址来区分不同的页面和资源。前端路由则是用来处理URL和页面之间的映射关系,通过监听URL的变化,实现页面的切换和加载不同的内容。
## 1.3 前端路由的优势与应用场景
前端路由的优势在于减少了服务器的负载和网络请求,提高了用户的体验。同时,前端路由可以实现单页应用(SPA),在页面间切换时只需要局部更新,而不用重新加载整个页面。
适用于以下场景:
- 页面间切换频繁,需要实现无刷新加载
- 需要提高用户体验,减少页面的加载时间
- 需要实现页面之间的参数传递和状态管理
以上是第一章节的内容,接下来将继续编写后续的章节。
# 2. 单页应用(SPA)简介
### 2.1 什么是单页应用
### 2.2 SPA与多页应用的对比
### 2.3 SPA的优缺点分析
单页应用(SPA)简介
### 2.1 什么是单页应用
单页应用(SPA)是一种Web应用程序的实现方式,它通过动态地更新页面的一部分,而不是整页刷新的方式来提供更快的用户体验。在传统的多页应用中,每次用户进行导航时都需要服务器重新加载整个页面。而在单页应用中,页面只在初始化时加载一次,之后的导航都是通过前端路由来控制页面的内容变化。
### 2.2 SPA与多页应用的对比
在多页应用中,每个URL对应一个独立的HTML文件。用户在不同页面之间的切换会触发整个页面的重新加载,这种方式会消耗较多的带宽和服务器资源。而在单页应用中,所有的页面都是在一个HTML文件中进行渲染和切换,只需要加载和渲染所需的数据和模板,减少了网络传输和服务器的压力。
另外,在多页应用中,页面之间的切换通常需要重新加载整个页面,导致用户的等待时间较长。而在单页应用中,只需要通过前端路由进行页面切换,不需要重新加载整个页面,所以用户切换页面的体验更加流畅。
### 2.3 SPA的优缺点分析
#### 2.3.1 优点:
- 用户体验好:由于单页应用只需要加载和渲染部分内容,所以页面切换更加流畅,用户体验更好。
- 前后端分离:前端负责页面渲染和交互逻辑,后端负责提供数据接口,前后端可以并行开发。
- 数据与视图分离:通过前端路由控制页面切换,视图与数据分离,可以根据需要进行灵活的组合和展示。
#### 2.3.2 缺点:
- 首屏加载时间较长:由于单页应用需要一次性加载所有需要的资源,所以首屏加载时间较长,对于移动端用户可能会有一定的影响。
- SEO不友好:由于单页应用的内容都是动态生成的,搜索引擎爬虫可能无法正确抓取页面内容,对于SEO可能会有一定的影响。需要通过特殊处理和预渲染来解决这个问题。
总结:单页应用通过前端路由的方式实现页面切换,提供了更好的用户体验和前后端分离的开发模式。但是也存在首屏加载时间较长和SEO不友好的问题,开发者需要根据具体应用场景进行权衡和选择。
# 3. 前端路由实现方法
## 3.1 基于Hash的前端路由实现
### 3.1.1 什么是Hash路由
Hash路由是前端路由的一种实现方式,在URL中以#字符为分隔符,后面部分称为Hash。使用Hash路由实现前端页面的跳转,不会触发浏览器的页面刷新,同时也可以通过修改Hash值实现页面的状态切换。
### 3.1.2 Hash路由的实现原理
基于Hash的前端路由实现原理很简单,通过监听`window`对象的`hashchange`事件,当URL的Hash值发生变化时,执行相应的处理函数,进而实现页面的跳转和状态切换。
下面是一个使用原生JavaScript实现的简单Hash路由示例:
```javascript
function Router() {
this.routes = {}; // 存储路由对应的处理函数
this.currentHash = ''; // 记录当前的Hash值
}
Router.prototype.route = function (path, callback) {
this.routes[path] = callback || function () {};
};
Router.prototype.refresh = function () {
this.currentHash = window.location.hash.slice(1) || '/'; // 获取当前的Hash值
this.routes[this.currentHash](); // 根据Hash值执行对应的处理函数
};
Router.prototype.init = function () {
window.addEventListener('load', this.refresh.bind(this));
window.addEventListener('hashchange', this.refresh.bind(this));
};
var router = new Router();
// 定义路由对应的处理函数
function home() {
console.log('Welcome to Home Page!');
}
function about() {
console.log('This is About Page!');
}
// 注册路由和对应的处理函数
router.route('/', home);
router.route('/about', about);
// 初始化路由
router.init();
```
上述代码中,我们定义了一个`Router`类,它具有`route()`、`refresh()`和`init()`三个方法。通过`route()`方法可以注册路由和对应的处理函数,`refresh()`方法用于根据当前的Hash值执行相应的处理函数,`init()`方法则是初始化路由,监听`load`和`hashchange`事件。
代码示例中,我们注册了两个路由`/`和`/about`,并分别对应了处理函数`home()`和`about()`。当页面的Hash值发生变化时,会根据Hash值执行对应的处理函数。
这种基于Hash的前端路由实现方法简单易懂,兼容性较好,适用于一些简单的单页应用场景。但是在URL上会带有`#`符号,不够美观。因此,在现代前端开发中,更常用的是基于History API的前端路由实现方式。
## 3.2 基于History API的前端路由实现
### 3.2.1 什么是History API
History API是HTML5中新增的API,可以通过`history`对象来操作浏览器的历史记录。它提供了一种更加友好和灵活的方式来管理浏览器的历史记录,从而实现前端路由。
### 3.2.2 History API的实现原理
基于History API的前端路由实现原理相对复杂一些。它通过`pushState()`和`replaceState()`方法向浏览器的历史记录中添加新的状态,并且通过`popstate`事件监听浏览器的前进、后退操作。当发生前进、后退操作时,执行相应的处理函数,实现页面的跳转和状态切换。
下面是一个使用原生JavaScript实现的简单History API路由示例:
```javascript
function Router() {
this.routes = {}; // 存储路由对应的处理函数
this.currentUrl
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
这篇专栏《前端面试题》涵盖了广泛的前端技术知识和实践经验,内容包括HTML、CSS、JavaScript、ES6、前端框架(如Vue.js和React.js)、Webpack构建工具、TypeScript静态类型检查、HTTP协议、Web性能优化、CSS预处理器、前端工程化、前端路由、数据可视化、前端安全、移动端开发、Service Worker以及WebAssembly等方面。每个主题均提供了深入的解析和实践技巧,旨在帮助前端开发者建立扎实的技术基础,掌握最新的前端技术趋势,并为面试提供全面的准备。无论您是正在学习前端技术,准备面试,或者想深入了解前端领域的最新动态,这个专栏都将是您不可多得的学习资料。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【3D建模新手入门】:5个步骤带你快速掌握实况脸型制作

# 摘要
随着计算机图形学的飞速发展,3D建模在游戏、电影、工业设计等多个领域中扮演着至关重要的角色。本文系统介绍了3D建模的基础知识,对比分析了市面上常见的建模软件功能与特点,并提供了安装与界面配置的详细指导。通过对模型构建、草图到3D模型的转换、贴图与材质应用的深入讲解,本文为初学者提供了从零开始的实操演示。此外,文章还探讨了3D建模中的灯光与渲染技巧,以及在实践案例中如何解决常见问题和
PL4KGV-30KC新手入门终极指南:一文精通基础操作
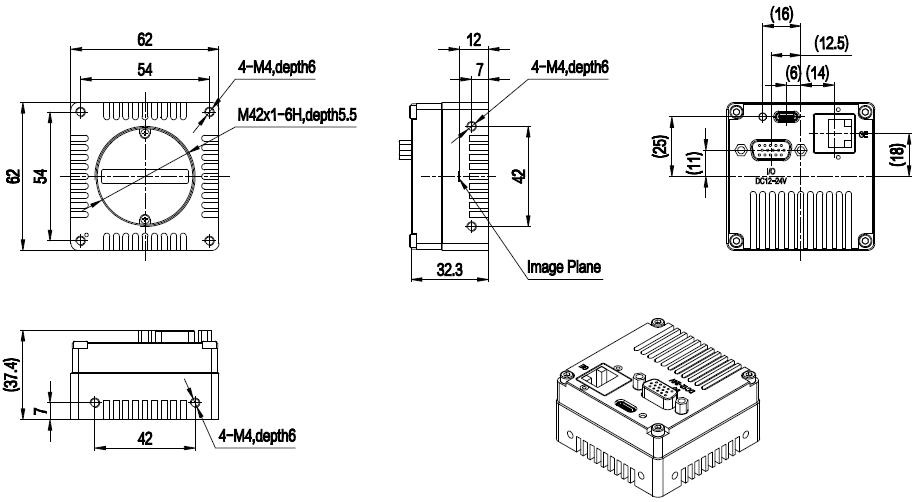
# 摘要
本文全面介绍PL4KGV-30KC设备,包括其基础知识、操作界面、功能、实践操作案例以及高级应用与优化。首先概述了PL4KGV-30KC的基础知识和操作界面布局,随后深入分析其菜单设置、连接通讯以及测量、数据分析等实践操作。文中还探讨了该设备的高级应用,如自定义程序开发、扩展模块集成以及性能调优策略。最后,本文讨论了社区资源的
【海思3798MV100刷机终极指南】:创维E900-S系统刷新秘籍,一次成功!

# 摘要
本文系统介绍了海思3798MV100的刷机全过程,涵盖预备知识、工具与固件准备、实践步骤、进阶技巧与问题解决,以及刷机后的安全与维护措施。文章首先讲解了刷机的基础知识和必备工具的获取与安装,然后详细描述了固件选择、备份数据、以及降低刷机风险的方法。在实践步骤中,作者指导读者如何进入刷机模式、操作刷机流程以及完成刷机后的系统初始化和设置。进阶技巧部分涵盖了刷机中
IP5306 I2C与SPI性能对决:深度分析与对比
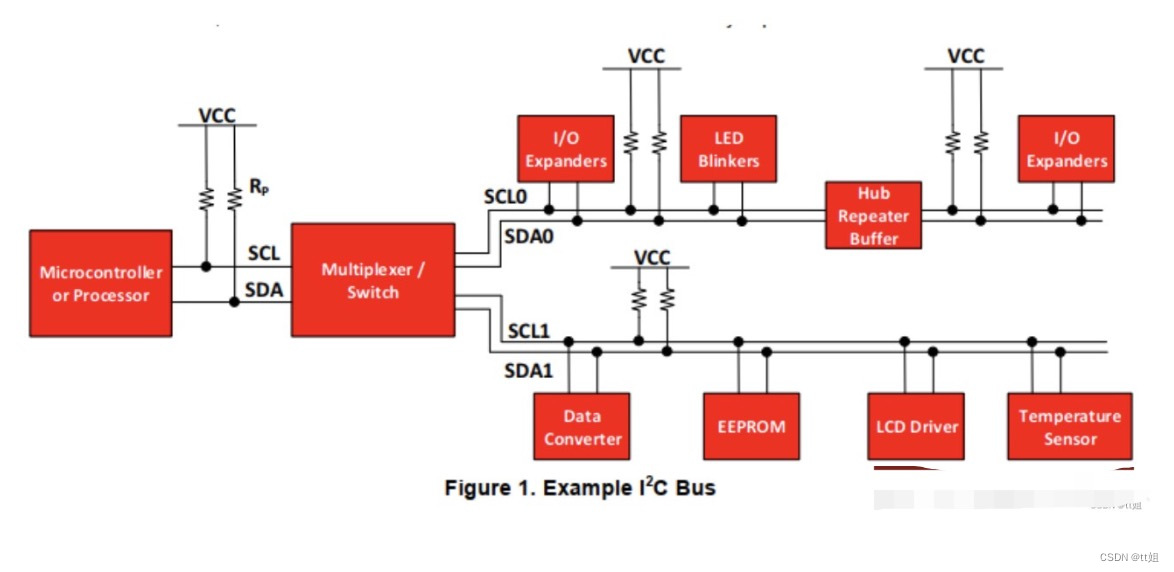
# 摘要
随着电子设备与嵌入式系统的发展,高效的数据通信协议变得至关重要。本文首先介绍了I2C和SPI这两种广泛应用于嵌入式设备的通信协议的基本原理及其在IP5306芯片中的具体实现。通过性能分析,比较了两种协议在数据传输速率、带宽、延迟、兼容性和扩展性方面的差异,并探讨了IP5306在电源管理和嵌入式系统中的应用案例。最后,提出针对I2C与SPI协议性能优化的策略和实践建议,并对未来技术发展趋势进行了
性能优化秘籍:提升除法器设计的高效技巧
# 摘要
本文综合探讨了除法器设计中的性能瓶颈及其优化策略。通过分析理论基础与优化方法论,深入理解除法器的工作原理和性能优化理论框架。文章详细介绍了硬件设计的性能优化实践,包括算法、电路设计和物理设计方面的优化技术。同时,本文也探讨了软件辅助设计与模拟优化的方法,并通过案例研究验证了优化策略的有效性。文章最后总结了研究成果,并指出了进一步研究的方向,包括新兴技术在除法器设计中的应用及未来发展趋势。
# 关键字
除法器设计;性能瓶颈;优化策略;算法优化;电路设计;软件模拟;协同优化
参考资源链接:[4除4加减交替法阵列除法器的设计实验报告](https://wenku.csdn.net/do
FSIM分布式处理:提升大规模图像处理效率

# 摘要
FSIM分布式处理是将图像处理任务分散到多个处理单元中进行,以提升处理能力和效率的一种技术。本文首先概述了FSIM分布式处理的基本概念,并详细介绍了分布式计算的理论基础,包括其原理、图像处理算法、以及架构设计。随后,本文通过FSIM分布式框架的搭建和图像处理任务的实现,进一步阐述了分布式处理的实际操作过程。此外,本文还探讨了FSIM分布式处理在性能评估、优化策略以及高级应用方面的
IEC 60068-2-31冲击试验的行业应用:案例研究与实践

# 摘要
IEC 60068-2-31标准为冲击试验提供了详细规范,是评估产品可靠性的重要依据。本文首先概述了IEC 60068-2-31标准,然后
【高维数据的概率学习】:面对挑战的应对策略及实践案例
# 摘要
高维数据的概率学习是处理复杂数据结构和推断的重要方法,本文概述了其基本概念、理论基础与实践技术。通过深入探讨高维数据的特征、概率模型的应用、维度缩减及特征选择技术,本文阐述了高维数据概率学习的理论框架。实践技术部分着重介绍了概率估计、推断、机器学习算法及案例分析,着重讲解了概率图模型、高斯过程和高维稀疏学习等先进算法。最后一章展望了高维数据概率学习的未来趋势与挑战,包括新兴技术的应用潜力、计算复杂性问题以及可解释性研究。本文为高维数据的概率学习提供了一套全面的理论与实践指南,对当前及未来的研究方向提供了深刻见解。
# 关键字
高维数据;概率学习;维度缩减;特征选择;稀疏学习;深度学
【RTL8812BU模块调试全攻略】:故障排除与性能评估秘籍
# 摘要
本文详细介绍了RTL8812BU无线模块的基础环境搭建、故障诊断、性能评估以及深入应用实例。首先,概述了RTL8812BU模块的基本信息,接着深入探讨了其故障诊断与排除的方法,包括硬件和软件的故障分析及解决策略。第三章重点分析了模块性能评估的关键指标与测试方法,并提出了相应的性能优化策略。第四章则分享了定制化驱动开发的经验、网络安全的增强方法以及多模块协同工作的实践。最后,探讨了新兴技术对RTL8812BU模块未来的影响,并讨论了模块的可持续发展趋势。本文为技术人员提供了全面的RTL8812BU模块应用知识,对于提高无线通信系统的效率和稳定性具有重要的参考价值。
# 关键字
RTL
VC709开发板原理图挑战:信号完整性与电源设计的全面解析(硬件工程师必读)
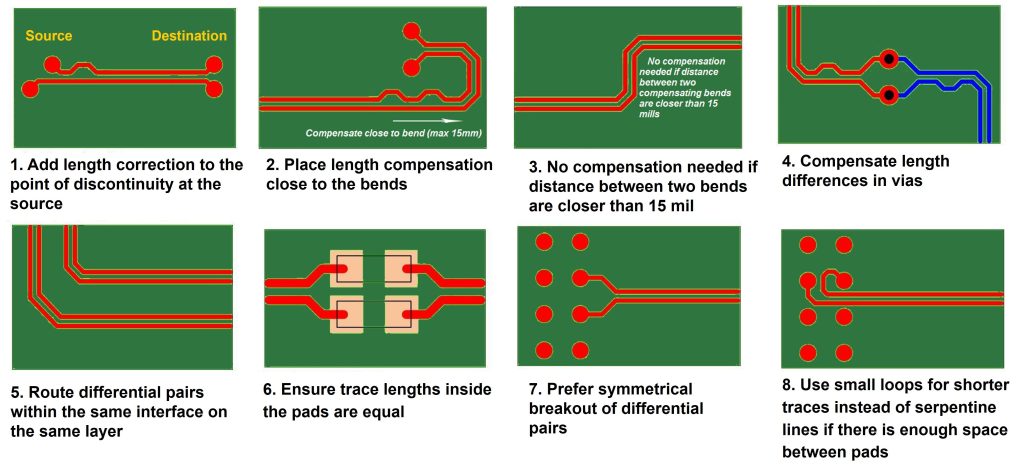
# 摘要
本文旨在详细探讨VC709开发板的信号和电源完整性设计,以及这些设计在实践中面临的挑战和解决方案。首先概述了VC709开发板的基本情况,随后深入研究了信号完整性与电源完整性基础理论,并结合实际案例分析了设计中的关键问题和对策。文章进一步介绍了高级设计技巧和最新技术的应用,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )