大数据管理与优化策略
发布时间: 2024-02-25 07:57:50 阅读量: 87 订阅数: 28 
# 1. 理解大数据管理
大数据管理作为信息技术领域中的重要概念,已经成为许多企业和组织必须面对和解决的挑战。从根本上看,大数据管理涉及对大规模数据的收集、存储、清洗、分析和应用,旨在提高数据的可用性和可信度,为决策提供支持。本章将深入探讨大数据管理的基本概念、重要性,以及面临的主要挑战。
## 1.1 什么是大数据
在信息时代,随着互联网、物联网和传感器技术的快速发展,人类社会创造的数据呈现出爆炸式增长的趋势。大数据(Big Data)通常被定义为具有海量、高速生成、多样化和价值密度低等特点的数据集合。这些数据往往需要利用先进的技术和工具来进行有效的管理和分析。
## 1.2 大数据管理的重要性
随着企业经营和决策的数字化转型,大数据管理的重要性日益凸显。有效的大数据管理可以帮助企业更好地了解市场、产品和客户,并能够提高决策的准确性和效率,促进企业的创新和发展。
## 1.3 大数据管理的目标和挑战
大数据管理的主要目标是确保数据的安全性、一致性和易用性,以及提高数据的可靠性和实时性。然而,实现这些目标面临诸多挑战,包括数据采集的复杂性、数据存储与处理的成本、数据隐私与安全的保护,以及数据分析与应用的技术难度。
以上是本章的部分内容,后续章节将继续深入探讨大数据管理的各个方面。
# 2. 大数据采集与存储
大数据的采集和存储是大数据管理中至关重要的一环,它涉及到数据来源的多样性和海量数据的高效存储管理。在这一章节中,我们将探讨大数据的采集方式、工具以及大数据的存储技术,同时也需要考虑数据的安全性和隐私保护。
### 2.1 数据采集的方式与工具
在大数据管理中,数据的采集方式有多种多样,常见的方式包括:
- **批量采集:** 通过定时任务、日志分析等方式批量获取数据。
- **流式采集:** 通过实时流处理技术(如Apache Kafka、Apache Flink等)进行数据的实时采集和处理。
- **日志采集:** 通过日志收集工具(比如Fluentd、Logstash等)收集服务器和应用产生的日志数据。
- **Web 数据采集:** 通过网络爬虫技术采集网页上的结构化数据。
针对不同的数据来源和采集需求,可以选用合适的工具来进行数据采集。比如,在Python中,可以使用BeautifulSoup库进行网页数据的抓取,使用Requests库进行API数据的获取,使用Pandas库进行结构化数据的处理等。
### 2.2 大数据存储技术
大数据的存储技术需要能够应对海量数据的高效存储和快速检索,常见的大数据存储技术包括:
- **分布式文件系统(DFS):** 如Hadoop HDFS、Amazon S3等,能够存储大规模数据,并提供高可靠性和高吞吐量的数据访问。
- **列式存储数据库:** 如Apache HBase、Cassandra等,适合于需要快速随机访问少量字段的数据存储。
- **NoSQL 数据库:** 如MongoDB、Couchbase等,适合于非结构化数据的存储和检索。
在实际应用中,需要根据数据的特点和访问模式选择合适的存储技术。同时,还需要考虑数据的安全性和隐私保护,采取加密、权限控制等措施保护数据的安全。
### 2.3 数据安全与隐私保护
大数据管理中,数据安全和隐私保护是不容忽视的重要环节。针对大数据存储过程中可能存在的数据泄露、数据被篡改等安全问题,需要采取一系列的安全措施,比如:
- **数据加密:** 对数据进行加密存储,保障数据在存储过程中不易被窃取。
- **访问权限控制:** 设定严格的访问权限,确保只有授权人员可以访问特定的数据。
- **数据备份与恢复:** 定期进行数据备份,并建立完善的灾难恢复机制,以应对数据意外丢失或损坏的情况。
- **隐私保护:** 在数据采集

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏将系统性地介绍大数据工程师集训所需的知识和技能,着重于华为HCIA认证的入门教程。通过深入探讨数据仓库与数据湖的概念和应用,读者将理解数据存储技术的演进与比较,为构建高效的大数据存储系统打下基础。此外,我们将深入探讨大数据管理与优化策略,帮助读者学习如何有效地管理和优化大数据系统,以应对不断增长的数据规模和复杂性。无论是对于正在准备华为HCIA认证考试的学习者,还是对于希望系统地了解大数据工程领域知识与技能的专业人士,本专栏都将提供全面而深入的指导和学习资源。
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
揭秘ILI9488性能调优:提升显示效率的终极指南

参考资源链接:[ILI9488驱动芯片详解:320x480 RGB TFT LCD单芯片](https://wenku.csdn.net/doc/6412b766be7fbd1778d4a2b4?spm=1055.2635.3001.10343)
# 1. ILI9488显示屏技术概览
## ILI9488技术简介
ILI9
【USB3 Vision协议调试技巧】:提升系统稳定性的专家级策略

参考资源链接:[USB3 Vision协议详解:工业相机的USB3.0标准指南](https://wenku.csdn.net/doc/6vpdqfiyj3?spm=1055.2635.3001.10343)
# 1. USB3 Vision协议基础
## 1.1 协议概述
USB3 Vision协议是
【U8运行时错误缓存与数据一致性】:缓存失效与数据同步问题的应对策略

参考资源链接:[U8 运行时错误 440,运行时错误‘6’溢出解决办法.pdf](https://wenku.csdn.net/doc/644bc130ea0840391e55a560?spm=1055.2635.3001.10343)
# 1. U8运行时错误缓存概述
在现代IT架构中,缓存的使用越来越普遍,它能够显著提升数据检索的效率,缓解后端服务的压力。U8运行时错误缓存是企业级应用中常见的一种缓存机制,它在出现运行时错误时
ABAQUS中网格删除的技术挑战与应对策略:专家指南

参考资源链接:[ABAQUS教程:删除网格与重新化分操作](https://wenku.csdn.net/doc/3nmrhvsu7n?spm=1055.2635.3001.10343)
# 1. ABAQUS网格处理概述
## 1.1 网格处理的重要性
在有限元分析中,网格处理是至关重要的一步,它直接影响到模拟的准确性和计算的效率。正确的网格划分可以确保模型在
【LPDDR5 vs LPDDR4】:关键性能对比揭示未来升级路径
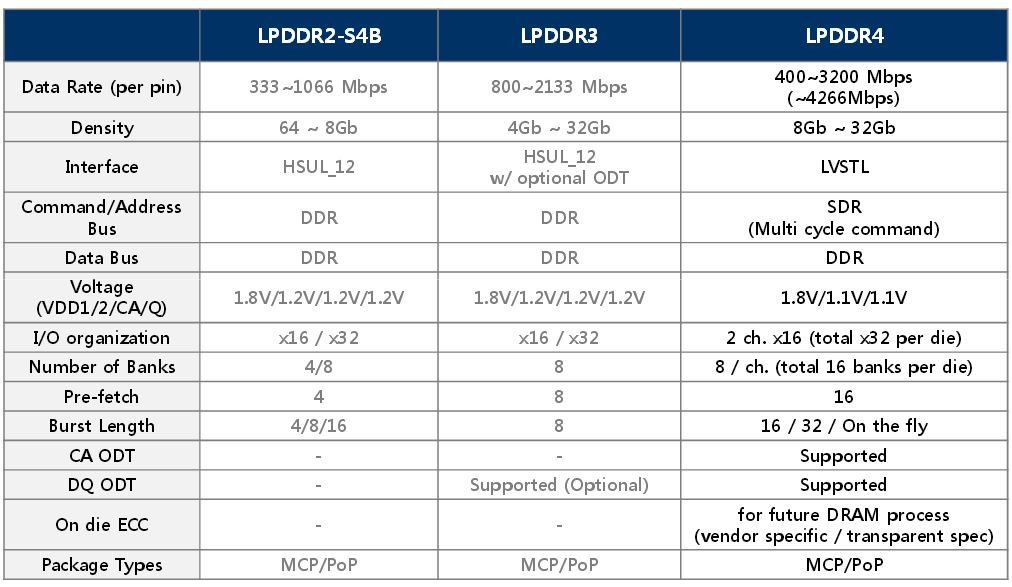
参考资源链接:[LPDDR5详解:架构、比较与关键特性](https://wenku.csdn.net/doc/7spq8iipvh?spm=1055.2635.3001.10343)
# 1. LPDDR内存技术概述
## 1.1 LPDDR内存的发展背景
LPDDR(Low Power Double Data Rate)内存是一种专为
DS3231在汽车电子中的应用:技术创新与案例分享

参考资源链接:[DS3231:中文手册详解高性能I2C时钟芯片](https://wenku.csdn.net/doc/6412b6efbe7fbd1778d48808?spm=1055.2635.3001.10343)
# 1. DS3231实时时钟模块概述
DS3231实时时钟模块是一款常用于微控制器项目的高精度时间记录设备。
安川YRC1000高级参数调整:性能优化与故障预防实战攻略

参考资源链接:[安川YRC1000 使用说明书.pdf](https://wenku.csdn.net/doc/6401abfecce7214c316ea3fd?spm=1055.2635.3001.10343)
# 1. 安川YRC1000控制器概述
## 1.1 YRC1000的定位与应用领域
安川YRC1000控制器是专为机器人技术与自动化产业设计的先进设备。其设计兼顾了操作简便与性能强大的特点,广泛应用
【IT8786工控主板COM芯片集成优势】:简化设计与成本控制

参考资源链接:[IT8786E-I工控主板Super I/O芯片详解](https://wenku.csdn.net/doc/6412b756be7fbd1778d49f0c?spm=1055.2635.3001.10343)
# 1. IT8786工控主板概述
## 1.1 工控主板的行业重要性
工控主板作为工业计算机的核心部件,其设计和性能直接影响到整个系统的稳定运行。随着工业4.0
【PMF5.0移动应用适配】:随时随地工作的3大关键设置

参考资源链接:[PMF5.0操作指南:VOCs源解析实用手册](https://wenku.csdn.net/doc/6412b4eabe7fbd1778d4148a?spm=1055.2635.3001.10343)
# 1. PMF5.0移动应用适配概述
随着智能手机用户数量的激增和移动网络技术的飞速发展,移动应用的用户体验和性能成为竞争的关键点。PMF5.0作为行业内的领先解决
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )