【Python函数运行机制大揭秘】:揭开函数调用背后的神秘面纱
发布时间: 2024-06-17 19:28:52 阅读量: 93 订阅数: 37 

无需编写任何代码即可创建应用程序:Deepseek-R1 和 RooCode AI 编码代理.pdf
# 1. Python函数基础
Python函数是代码块,用于执行特定的任务。它们可以接收输入(称为参数),并返回输出(称为返回值)。函数允许代码重用,提高可读性和可维护性。
函数使用`def`关键字定义,后跟函数名和参数列表。参数是函数接收的输入,可以是任意数据类型。函数体包含要执行的代码,它以冒号结尾。
函数可以通过调用函数名来执行,并提供实际参数。实际参数与形式参数(函数定义中的参数)相匹配,并传递给函数体中的变量。
# 2. 函数调用机制
### 2.1 函数的定义和调用
函数定义使用 `def` 关键字,后跟函数名称和参数列表。参数列表中的每个参数都是一个变量,用于存储传递给函数的数据。函数体由冒号分隔,包含要执行的代码。
```python
def greet(name):
print(f"Hello, {name}!")
```
要调用函数,只需使用其名称并传递所需的参数。
```python
greet("John") # 输出:Hello, John!
```
### 2.2 参数传递和返回值
参数传递有两种方式:
- **位置参数:**按顺序传递,与函数定义中参数的顺序相对应。
- **关键字参数:**通过名称传递,允许以任意顺序传递参数。
函数可以返回一个值,使用 `return` 关键字。返回的值可以是任何数据类型,包括另一个函数。
```python
def sum_numbers(a, b):
return a + b
result = sum_numbers(10, 20) # result 为 30
```
### 2.3 函数作用域和闭包
**作用域**定义了变量的可见性。函数内部定义的变量仅在该函数内可见。
**闭包**是一个函数,它可以访问定义它的函数中的变量,即使该函数已经执行完毕。闭包通常用于创建状态或共享数据。
```python
def outer_function():
x = 10
def inner_function():
print(x) # 访问 outer_function 中的 x
inner_function() # 输出:10
```
# 3. 函数优化技巧
### 3.1 性能优化方法
#### 3.1.1 避免不必要的函数调用
在函数内部反复调用另一个函数会增加执行时间。如果可能,应将函数调用移动到函数外部,或使用局部变量存储函数调用的结果。
```python
def calculate_average(nums):
# 避免重复调用 len(nums)
length = len(nums)
total = 0
for num in nums:
total += num
return total / length
```
#### 3.1.2 使用内置函数和库函数
内置函数和库函数通常比自定义函数执行得更快,因为它们经过高度优化。例如,使用 `sum()` 函数比手动求和更快。
```python
# 使用内置 sum() 函数
total = sum(nums)
# 手动求和
total = 0
for num in nums:
total += num
```
#### 3.1.3 减少循环次数
减少循环次数可以提高性能。例如,可以使用 `enumerate()` 函数同时遍历索引和值,避免额外的循环。
```python
# 使用 enumerate() 同时遍历索引和值
for index, value in enumerate(nums):
# ...
# 分别遍历索引和值
for index in range(len(nums)):
value = nums[index]
# ...
```
#### 3.1.4 使用缓存
缓存可以存储函数调用的结果,避免重复计算。这在函数调用成本很高的情况下特别有用。
```python
# 使用缓存存储计算结果
cache = {}
def expensive_calculation(arg):
if arg in cache:
return cache[arg]
else:
result = ... # 计算结果
cache[arg] = result
return result
```
### 3.2 代码可读性和可维护性
#### 3.2.1 使用有意义的函数名称
函数名称应清晰简洁地描述函数的功能。避免使用模糊或通用的名称。
```python
# 清晰的函数名称
def calculate_total_sales(orders):
# 模糊的函数名称
def process_data(data):
```
#### 3.2.2 添加注释
注释可以解释函数的用途、参数和返回值。这有助于其他开发人员理解和维护代码。
```python
def calculate_total_sales(orders):
"""计算一组订单的总销售额。
参数:
orders: 订单列表
返回值:
总销售额
"""
```
#### 3.2.3 使用适当的缩进和格式
适当的缩进和格式使代码更易于阅读和理解。遵循一致的编码风格,例如 PEP 8。
```python
# 正确的缩进和格式
def calculate_total_sales(orders):
total = 0
for order in orders:
total += order.total
# 不正确的缩进和格式
def calculate_totalsales(orders):total=0for order in orders:total+=order.total
```
#### 3.2.4 分解复杂函数
复杂函数应分解为更小的、更易于管理的函数。这提高了代码的可读性和可维护性。
```python
# 分解复杂函数
def process_data(data):
# 分解为更小的函数
cleaned_data = clean_data(data)
transformed_data = transform_data(cleaned_data)
return transformed_data
```
# 4. 函数高级应用
### 4.1 函数式编程
#### 函数式编程简介
函数式编程是一种编程范式,它强调使用不可变数据和纯函数来编写代码。纯函数是那些不修改其输入或产生副作用的函数。函数式编程的优点包括:
- **代码可预测性:** 由于纯函数不会修改其输入,因此更容易推理和预测代码的行为。
- **并行性:** 函数式代码通常可以很容易地并行化,因为函数之间没有共享状态。
- **可测试性:** 函数式代码更容易测试,因为输入和输出是明确定义的,并且没有副作用。
#### 函数式编程语言
函数式编程语言专门设计用于支持函数式编程范式。一些流行的函数式编程语言包括:
- Haskell
- Lisp
- Scala
- F#
#### Python中的函数式编程
尽管 Python 并不是专门的函数式编程语言,但它支持一些函数式编程特性,例如:
- 匿名函数(lambda 表达式)
- 高阶函数(接受函数作为参数或返回函数的函数)
- 惰性求值(仅在需要时才计算值)
### 4.2 装饰器和元类
#### 装饰器
装饰器是一种设计模式,允许在不修改函数源代码的情况下修改函数的行为。装饰器通过将另一个函数包装在要装饰的函数周围来实现。包装函数可以执行各种任务,例如:
- 添加日志记录
- 计时函数执行
- 验证函数参数
#### 元类
元类是创建类的类。它们允许您自定义类的行为,例如:
- 控制类的创建方式
- 添加自定义属性或方法
- 拦截对类属性或方法的访问
#### 装饰器和元类的用法
装饰器和元类通常一起使用来创建高级功能。例如,您可以使用元类创建具有特定属性或方法的类,然后使用装饰器来修改这些属性或方法的行为。
#### 示例
以下是一个使用装饰器和元类的示例:
```python
# 创建一个元类,它将向类添加一个名为 "name" 的属性
class NameMeta(type):
def __new__(cls, name, bases, dct):
dct['name'] = name
return super().__new__(cls, name, bases, dct)
# 使用元类创建类
class Person(metaclass=NameMeta):
def __init__(self, name):
self.name = name
# 创建一个装饰器,它将向函数添加日志记录功能
def log_function(func):
def wrapper(*args, **kwargs):
print(f"Calling {func.__name__} with args {args} and kwargs {kwargs}")
result = func(*args, **kwargs)
print(f"Function {func.__name__} returned {result}")
return result
return wrapper
# 使用装饰器装饰方法
@log_function
def greet(name):
return f"Hello, {name}!"
# 创建一个 Person 对象并调用 greet() 方法
person = Person("John")
greet(person.name)
```
输出:
```
Calling greet with args (('John',)) and kwargs {}
Function greet returned Hello, John!
```
# 5.1 常见错误和解决方法
在使用Python函数时,可能会遇到各种错误。了解常见的错误类型及其解决方法对于快速解决问题至关重要。
**1. NameError:名称错误**
* **错误原因:**引用了未定义的变量或函数。
* **解决方法:**确保变量或函数已正确定义,或者使用适当的导入语句引入外部模块。
**2. TypeError:类型错误**
* **错误原因:**传递了与函数预期类型不匹配的参数。
* **解决方法:**检查函数签名并确保传递的参数类型正确。
**3. IndexError:索引错误**
* **错误原因:**尝试访问列表或元组超出其范围的索引。
* **解决方法:**确保索引在列表或元组的有效范围内。
**4. ValueError:值错误**
* **错误原因:**传递了无效或不适当的值。
* **解决方法:**检查函数文档以了解接受的值范围,并确保传递的值符合这些限制。
**5. AttributeError:属性错误**
* **错误原因:**尝试访问不存在的属性。
* **解决方法:**确保对象具有该属性,或者使用适当的条件语句检查属性是否存在。
**6. KeyError:键错误**
* **错误原因:**尝试访问字典中不存在的键。
* **解决方法:**确保键存在于字典中,或者使用适当的条件语句检查键是否存在。
**7. ZeroDivisionError:零除错误**
* **错误原因:**尝试将数字除以零。
* **解决方法:**在除法操作之前检查除数是否为零,并在必要时处理这种情况。
**8. MemoryError:内存错误**
* **错误原因:**程序分配的内存超过了可用内存。
* **解决方法:**优化代码以减少内存使用,或者增加可用内存。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨 Python 函数的方方面面,从运行机制、参数传递、返回值到函数嵌套、装饰器、异常处理、性能优化、测试、并发编程和设计模式。通过深入浅出的讲解和实战指南,专栏旨在帮助读者全面掌握 Python 函数的奥秘,提升代码的可读性、可维护性、可扩展性和性能。涵盖从基础概念到高级技巧,本专栏为 Python 开发人员提供了全面的指南,助力他们编写高效、健壮且可维护的代码。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【VS2022升级全攻略】:全面破解.NET 4.0包依赖难题
# 摘要
本文对.NET 4.0包依赖问题进行了全面概述,并探讨了.NET框架升级的核心要素,包括框架的历史发展和包依赖问题的影响。文章详细分析了升级到VS2022的必要性,并提供了详细的升级步骤和注意事项。在升级后,本文着重讨论了VS2022中的包依赖管理新工具和方法,以及如何解决升级中遇到的问题,并对升级效果进行了评估。最后,本文展望了.NET框架的未来发
【ALU设计实战】:32位算术逻辑单元构建与优化技巧

# 摘要
算术逻辑单元(ALU)作为中央处理单元(CPU)的核心组成部分,在数字电路设计中起着至关重要的作用。本文首先概述了ALU的基本原理与功能,接着详细介绍32位ALU的设计基础,包括逻辑运算与算术运算单元的设计考量及其实现。文中还深入探讨了32位ALU的设计实践,如硬件描述语言(HDL)的实现、仿真验证、综合与优化等关
【网络效率提升实战】:TST性能优化实用指南

# 摘要
本文全面综述了TST性能优化的理论与实践,首先介绍了性能优化的重要性及基础理论,随后深入探讨了TST技术的工作原理和核心性能影响因素,包括数据传输速率、网络延迟、带宽限制和数据包处理流程。接着,文章重点讲解了TST性能优化的实际技巧,如流量管理、编码与压缩技术应用,以及TST配置与调优指南。通过案例分析,本文展示了TST在企业级网络效率优化中的实际应用和性能提升措施,并针对实战
【智能电网中的秘密武器】:揭秘输电线路模型的高级应用

# 摘要
本文详细介绍了智能电网中输电线路模型的重要性和基础理论,以及如何通过高级计算和实战演练来提升输电线路的性能和可靠性。文章首先概述了智能电网的基本概念,并强调了输电线路模型的重要性。接着,深入探讨了输电线路的物理构成、电气特性、数学表达和模拟仿真技术。文章进一步阐述了稳态和动态分析的计算方法,以及优化算法在输电线路模型中的应用。在实际应用方面,本文分析了实时监控、预测模型构建和维护管理策略。此外,探讨了当前技术面临的挑战和未来发展趋势,包括人
【扩展开发实战】:无名杀Windows版素材压缩包分析
# 摘要
本论文对无名杀Windows版素材压缩包进行了全面的概述和分析,涵盖了素材压缩包的结构、格式、数据提取技术、资源管理优化、安全性版权问题以及拓展开发与应用实例。研究指出,素材压缩包是游戏运行不可或缺的组件,其结构和格式的合理性直接影响到游戏性能和用户体验。文中详细分析了压缩算法的类型、标准规范以及文件编码的兼容性。此外,本文还探讨了高效的数据提取技
【软件测试终极指南】:10个上机练习题揭秘测试技术精髓
# 摘要
软件测试作为确保软件质量和性能的重要环节,在现代软件工程中占有核心地位。本文旨在探讨软件测试的基础知识、不同类型和方法论,以及测试用例的设计、执行和管理策略。文章从静态测试、动态测试、黑盒测试、白盒测试、自动化测试和手动测试等多个维度深入分析,强调了测试用例设计原则和测试数据准备的重要性。同时,本文也关注了软件测试的高级技术,如性能测试、安全测试以及移动
【NModbus库快速入门】:掌握基础通信与数据交换
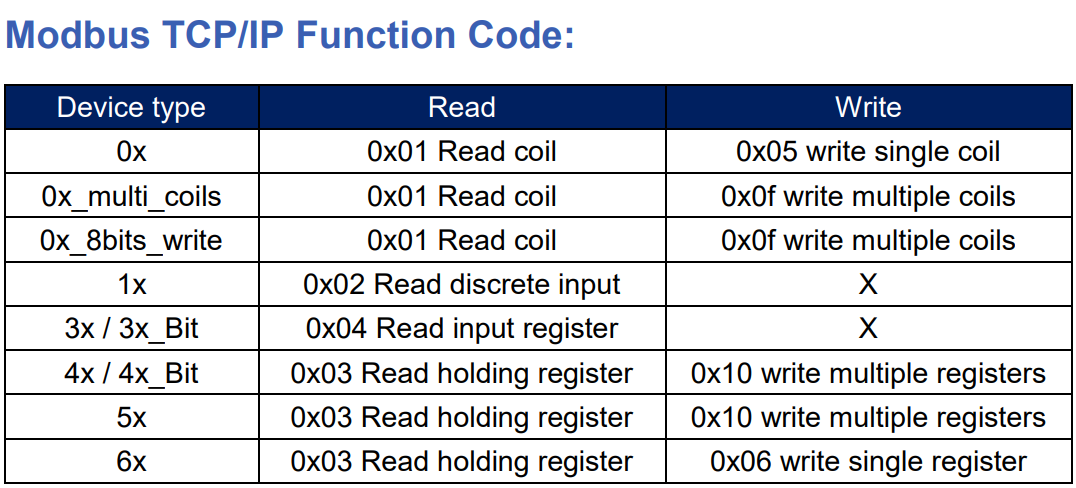
# 摘要
本文全面介绍了NModbus库的特性和应用,旨在为开发者提供一个功能强大且易于使用的Modbus通信解决方案。首先,概述了NModbus库的基本概念及安装配置方法,接着详细解释了Modbus协议的基础知识以及如何利用NModbus库进行基础的读写操作。文章还深入探讨了在多设备环境中的通信管理,特殊数据类型处理以及如何定
单片机C51深度解读:10个案例深入理解程序设计
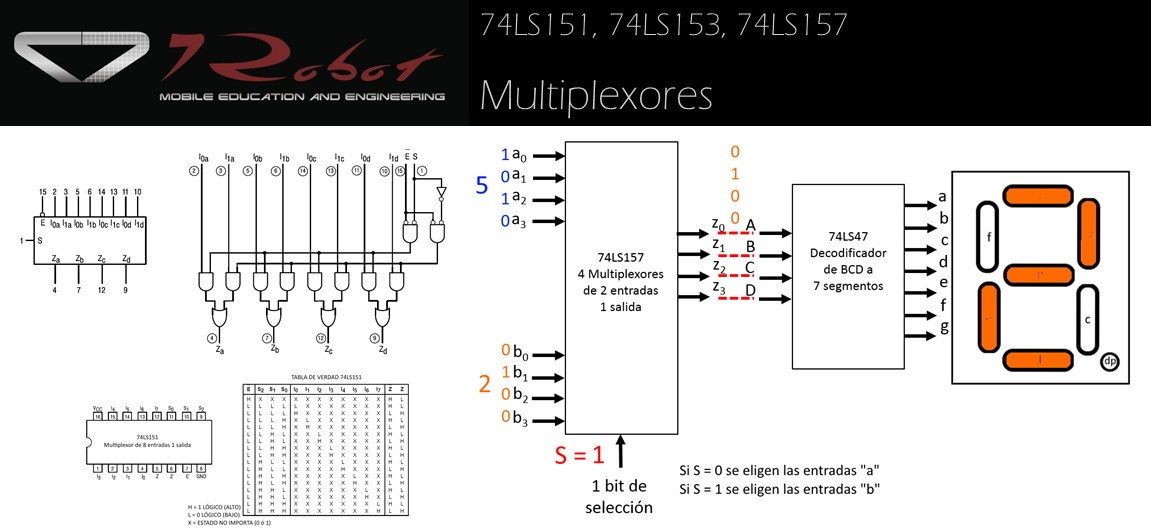
# 摘要
本文系统地介绍了基于C51单片机的编程及外围设备控制技术。首先概述了C51单片机的基础知识,然后详细阐述了C51编程的基础理论,包括语言基础、高级编程特性和内存管理。随后,文章深入探讨了单片机硬件接口操作,涵盖输入/输出端口编程、定时器/计数器编程和中断系统设计。在单片机外围设备控制方面,本文讲解了串行通信、ADC/DAC接口控制及显示设备与键盘接口的实现。最后,通过综合案例分
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )