【大型Django项目中的simplejson应用】:案例分析,如何在大型项目中有效利用simplejson
发布时间: 2024-10-14 11:34:01 阅读量: 22 订阅数: 26 

Django 导出项目依赖库到 requirements.txt过程解析

# 1. simplejson概述及其在Django中的角色
## 简介
在Python的Web开发框架Django中,处理数据的序列化与反序列化是常见的需求。`simplejson`是一个性能优良的第三方库,它提供了对JSON数据格式的快速处理能力。本章节将介绍`simplejson`的基本概念,以及它在Django项目中扮演的角色。
## simplejson的优势
`simplejson`相比Python标准库中的`json`模块,提供了更快的序列化和反序列化性能,尤其在处理大型数据集时更为显著。此外,`simplejson`对JSON格式的支持更为全面,包括了一些额外的数据类型,使得开发者在处理复杂数据结构时更加得心应手。
## 在Django中的角色
在Django项目中,`simplejson`可以用于API开发中,将Django模型数据转换为JSON格式,以便前端应用能够方便地使用。同时,它也常用于优化数据传输过程,减少网络负载,提高用户体验。下面的章节将深入探讨`simplejson`在Django中的具体应用和实践。
# 2. simplejson与Django数据交互的理论基础
在本章节中,我们将深入探讨simplejson与Django之间数据交互的理论基础。这包括JSON数据格式的结构解析、Django的序列化与反序列化机制,以及simplejson在Django项目中的优势分析。
## 2.1 JSON数据格式与解析原理
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。它基于JavaScript的一个子集,但是JSON是独立于语言的文本格式。JSON常用于Web应用程序的数据交换。
### 2.1.1 JSON数据结构详解
JSON数据结构主要包括对象、数组、字符串、数字、布尔值和null。其中,对象和数组是最基本的数据结构。
- **对象**:是由键值对组成的集合,使用大括号 `{}` 包围。例如:
```json
{
"name": "John",
"age": 30,
"city": "New York"
}
```
在这个例子中,`"name"`, `"age"`, 和 `"city"` 是对象的键,而 `"John"`, `30`, 和 `"New York"` 是对应的值。
- **数组**:是值的有序列表,使用方括号 `[]` 包围。例如:
```json
[
"apple",
"banana",
"cherry"
]
```
这个数组包含三个字符串值。
### 2.1.2 解析JSON的算法和方法
解析JSON数据通常涉及将JSON字符串转换为JavaScript对象,这个过程称为“反序列化”。在Django中,我们可以使用Python内置的`json`库来实现这一过程。
- **解析算法**:JSON解析算法通常涉及两个步骤:词法分析和语法分析。词法分析将JSON字符串分解成一个个的词素(tokens),语法分析则根据JSON的语法规则构建出一个抽象语法树(AST)。
- **解析方法**:在Python中,我们可以使用`json.loads()`方法来解析JSON字符串。例如:
```python
import json
json_string = '{"name": "John", "age": 30}'
data = json.loads(json_string)
print(data['name']) # 输出: John
```
这段代码将JSON字符串解析为Python字典对象。
## 2.2 Django中序列化与反序列化机制
Django提供了一套内置的序列化工具,允许开发者将Django模型实例转换成JSON格式。这些工具主要用于Web API的开发,使得数据的传输更为方便。
### 2.2.1 Django REST framework序列化机制
Django REST framework(DRF)是一个强大的、灵活的工具,用于构建Web API。它提供了序列化器(Serializers),允许开发者定义如何将Django模型实例或其他复杂数据类型序列化成JSON。
- **序列化器的定义**:在DRF中,序列化器是用于将查询集(QuerySet)或模型实例转换成JSON格式的类。例如:
```python
from rest_framework import serializers
from .models import User
class UserSerializer(serializers.ModelSerializer):
class Meta:
model = User
fields = ('id', 'name', 'email')
```
这个序列化器将`User`模型的`id`、`name`和`email`字段序列化成JSON。
### 2.2.2 Django内置序列化工具的局限性
虽然Django内置了序列化功能,但它有一些局限性。例如,内置序列化不支持高级功能,如嵌套序列化、自定义字段处理等。
- **局限性的例子**:在内置序列化中,如果需要对字段进行复杂的自定义处理,可能需要重写序列化过程。这在DRF中则可以通过自定义字段和方法来轻松实现。
## 2.3 simplejson在Django中的优势分析
simplejson是Python的一个第三方库,它提供了比内置的`json`库更快、更强大的JSON处理能力。在Django项目中使用simplejson可以带来性能优势和灵活性。
### 2.3.1 性能优势
simplejson比Python内置的`json`库更快,特别是在处理大型数据集时。它还提供了更多优化选项,如更快的编解码器。
- **性能测试**:可以通过简单的基准测试来比较`json`库和`simplejson`的性能。例如:
```python
import json
import simplejson
data = {'key': 'value'} * 10000
json.dumps(data) # 使用内置json库
simplejson.dumps(data) # 使用simplejson
```
这段代码可以用来比较两者在序列化相同数据时的性能差异。
### 2.3.2 灵活性与可扩展性
simplejson提供了更多的编解码器和额外的功能,如支持`datetime`和`timedelta`对象的序列化,以及自定义编码器和解码器。
- **灵活性的例子**:在处理日期和时间数据时,simplejson可以使用内置的编解码器来处理`datetime`对象,而不需要额外的处理。例如:
```python
import simplejson
from datetime import datetime
now = datetime.now()
json_string = simplejson.dumps(now)
```
这段代码将当前日期和时间序列化为JSON字符串。
通过本章节的介绍,我们了解了JSON数据格式的结构、Django中的序列化与反序列化机制,以及simplejson在Django项目中的优势。这些理论知识为后续章节中的实践应用和优化策略奠定了基础。
# 3. simplejson在大型Django项目中的实践应用
## 3.1 构建高效的数据序列化框架
### 3.1.1 配置simplejson序列化选项
在大型Django项目中,数据序列化是构建高效API的关键环节。simplejson提供了丰富的配置选项,使得开发者可以根据具体需求调整序列化行为。在本章节中,我们将详细介绍如何在Django项目中配置simplejson,以及如何利用其高级选项来优化数据序列化。
首先,要使用simplejson进行数据序列化,需要在Django的设置文件中指定序列化器:
```python
# settings.py
REST_FRAMEWORK = {
'DEFAULT_RENDERER_CLASSES': (
'rest_framework.renderers.JSONRenderer',
),
'DEFAULT_PARSER_CLASSES': (
'rest_framework.parsers.JSONParser',
),
'DEFAULT_RENDERER_CLASSES': [
'rest_framework.renderers.JSONRenderer',
],
'DEFAULT_PERMISSION_CLASSES': [
'rest_framework.permissions.IsAuthenticated',
],
}
```
这里我们指定了JSONRenderer和JSONParser,它们都依赖于simplejson进行序列化和反序列化操作。如果你需要对simplejson的序列化行为进行更细致的控制,可以通过修改序列化器的配置来实现。
例如,你可能希望在序列化时忽略一些字段,或者改变默认的日期格式。这可以通过在Django设置中配置JSONRenderer来完成:
```python
# settings.py
REST_FRAMEWORK = {
'DEFAULT_RENDERER_CLASSES': (
'rest_framework.renderers.JSONRenderer',
),
'JSONRenderer': {
'ensure_ascii': False, # 使用Unicode编码处理非ASCII字符
'indent': 4, # 格式化输出,便于阅读
},
# 其他配置...
}
```
在这里,`ensure_ascii`设置为`False`允许输出Unicode字符,`indent`设置为4表示输出时每个层级缩进4

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到“Python库文件学习之django.utils.simplejson”专栏,我们将深入探索这个强大的JSON处理工具在Django项目中的应用。从入门指南到高级技巧,再到性能优化和安全措施,本专栏涵盖了所有你需要了解的内容。我们将探讨simplejson的编码原理、与原生json的性能对比、与数据库交互、文件操作、自定义编码器、信号处理和多进程编程中的应用。通过案例分析和实际技巧,我们将帮助你在Django项目中高效使用simplejson,提升开发效率和数据处理能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【松下PLC指令集详解】:输入输出到计时计数,一网打尽

# 摘要
本文深入探讨了松下PLC的指令集,涵盖了基础输入输出指令、计时指令、计数指令以及高级应用等多个方面。文章首先介绍
华为云架构设计:企业级云计算架构设计的10个黄金法则
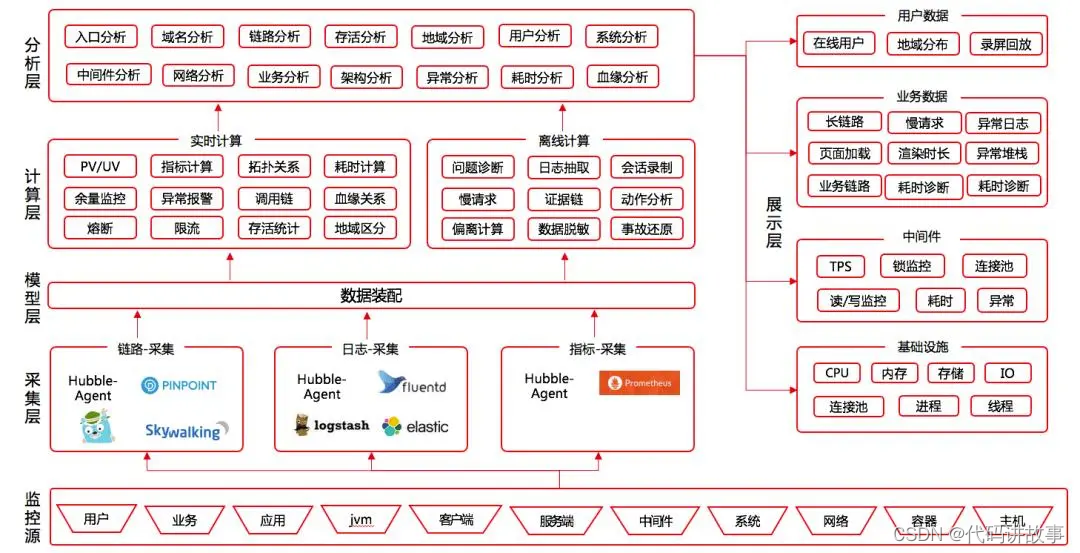
# 摘要
随着企业数字化转型的加速,云计算已成为支撑企业级服务的核心技术。本文首先概述了企业级云计算架构设计的重要性,继而以华为云架构设计为案例,探讨了其理论基础,包括云计算的概念、服务模型和架构关键组件。通过分析华为云架构设计的实践案例,本文突出了云数据中心构建、服务模型定制化以及安全性与合规性实施的重要性。进阶技巧与优化部分,进一步阐述了性能优化、自动化和智能化以及成本管理的方法。最后
TSPL入门到精通:一步一个脚印,系统学习TSPL的必经之路

# 摘要
TSPL语言是一种在编程领域中具有特定地位和作用的编程语言。本文首先介绍TSPL的定义、历史背景以及它与其他编程语言的对比分析。接着,本文深入探讨TSPL的基础知识,包括其语法基础、函数和模块系统、错误处理和调试。进阶技巧章节涵盖了TSPL中的高级数据结构、面向对象编程和并发及异步编程。实践
【安全攻防实战】:攻击者视角下的testCommandExecutor.jsp漏洞利用与防御
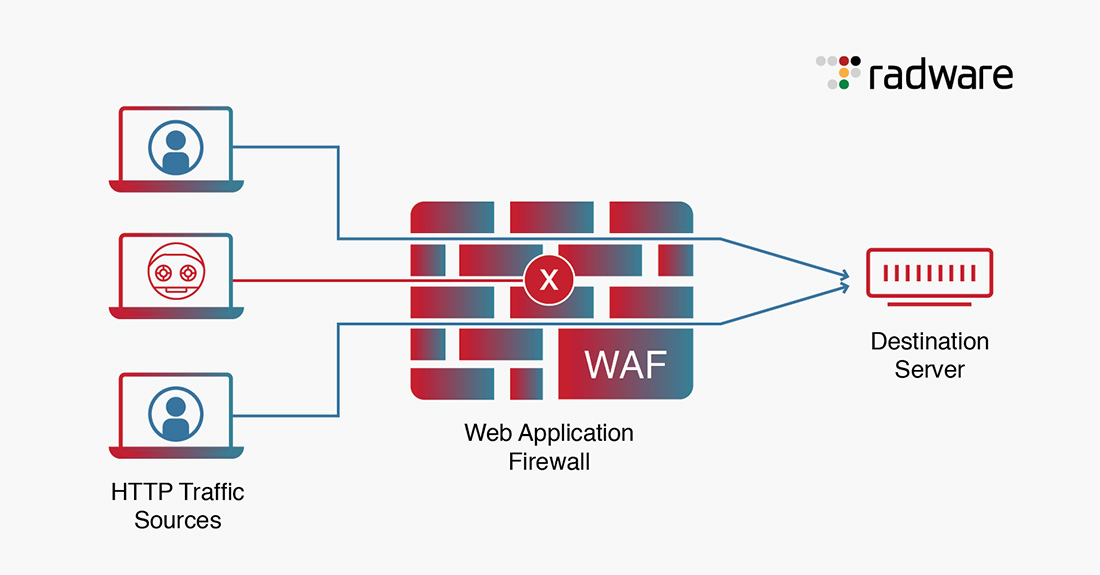
# 摘要
随着Web应用的普及,JSP漏洞成为攻击者青睐的突破口,本文从攻击者视角出发,深入分析了testCommandExecutor.jsp漏洞的成因、传播机制、利用技术以及防御策略。文章首先介绍JSP技术原理及存在的安全弱点,并详细探讨testCommandExecutor.jsp漏洞的具体背景。随后,从攻击者的角度详
AAO系统监控与维护秘籍:确保水处理工程长期稳定运行的5大策略

# 摘要
AAO系统作为一种先进技术应用于多个领域,其性能和稳定性对保障相关工作的正常运行至关重要。本文首先概述了AAO系统的基本架构和关键理论,随后详细介绍了监控策略的设计和实施,包括关键参数的解析、监控系统的建立、数据分析及异常处理方法。在维护策略部分,文章探讨了定期维护的理论基础,维护操作的标准流程以
【Oracle EBS财务模块实施全攻略】:最佳实践与挑战应对策略
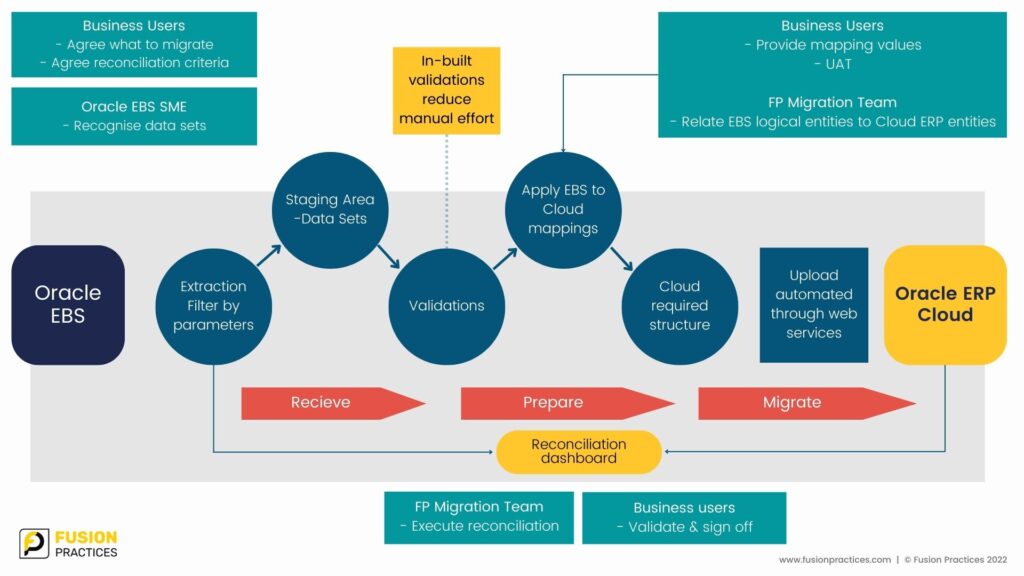
# 摘要
本文对Oracle EBS财务模块进行了全面的概述,深入分析了其核心功能、业务流程和技术实现基础。文章详细探讨了财务模块在实际实施过程中的最佳实践,包括项目规划、系统配置、数据迁移等关键步骤。针对实施过程中可能遇到的挑
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )