HBase基础教程:CDH中的分布式NoSQL数据库
发布时间: 2023-12-14 17:48:16 阅读量: 44 订阅数: 26 

分布式数据库HBase
# 1. HBase简介
## 1.1 什么是HBase
HBase是一种开源的分布式列存储数据库,基于Hadoop的HDFS存储系统。它旨在提供可靠的、可扩展的、高性能的非关系型数据存储解决方案。
## 1.2 HBase的特点和优势
- **高可靠性**:HBase数据存储在Hadoop的分布式文件系统(HDFS)上,它通过HDFS的数据冗余和故障恢复机制实现高可靠性。
- **可扩展性**:HBase可以水平扩展,通过添加更多的节点来实现存储容量和吞吐量的扩展。
- **高性能**:HBase支持快速读写操作,并且能够处理大规模数据的并发访问。
- **灵活的数据模型**:HBase的数据模型类似于关系型数据库的表格,但支持动态列和宽表结构,可以灵活地适应不同数据类型和业务需求。
- **丰富的查询功能**:HBase支持多种查询方式,包括按行键范围、列簇、列和时间戳等条件进行检索。
- **强一致性**:HBase提供强一致性读写操作,保证数据的一致性和可靠性。
## 1.3 HBase与传统关系型数据库的区别
- **数据模型**:传统关系型数据库采用表格的方式组织数据,需要事先定义表结构和字段,而HBase则采用灵活的列族和列的方式组织数据。
- **存储方式**:传统关系型数据库使用行存储方式,而HBase使用列存储方式,更适合大规模数据的读写操作。
- **扩展性**:传统关系型数据库通常难以扩展到大规模集群,而HBase可以通过添加更多的节点实现数据的水平扩展。
- **事务支持**:传统关系型数据库支持ACID事务,可以保证数据的一致性和可靠性,而HBase在事务支持方面相对较弱,主要通过乐观锁机制来保证数据的一致性。
- **查询功能**:传统关系型数据库支持复杂的SQL查询,而HBase则提供了简单的键值查询和范围查询等基本功能,并且不支持复杂的SQL操作。
通过上述内容的介绍,读者可以初步了解HBase的基本概念、特点和与传统关系型数据库的区别。接下来的章节将进一步介绍CDH中的NoSQL数据库概述以及HBase的架构、部署和使用。
# 2. CDH介绍
CDH(Cloudera's Distribution Including Apache Hadoop)是由Cloudera开发的基于Apache Hadoop的分布式数据处理平台。CDH包含了很多组件和工具,其中包括各种大数据处理引擎、存储系统和开发工具等。其中一个重要的组件就是 NoSQL 数据库,它在 CDH 中扮演着重要的角色。
### 2.1 CDH是什么
CDH是一个企业级的大数据处理平台,它基于 Apache Hadoop 生态系统构建而成。CDH集成了多个 Apache 顶级项目,包括 Hadoop、HBase、Hive、Spark、Impala等等,以及一些 Cloudera 自家的产品。
CDH 提供了一个稳定可靠的大数据处理解决方案,使得企业能够利用大数据技术进行数据存储、分析和处理。
### 2.2 CDH中的NoSQL数据库概述
在 CDH 中,NoSQL 数据库是其中一个重要的组件。NoSQL 数据库是一种非关系型数据库,与传统的关系型数据库不同,NoSQL 数据库采用了不同的数据存储模型,通过水平扩展和分布式架构来实现高可用性和高性能。
CDH 中提供了多种 NoSQL 数据库的选择,包括 HBase、Cassandra、MongoDB等。本文重点介绍 HBase,它是 CDH 中的一种分布式列存储数据库。
### 2.3 分布式NoSQL数据库与传统数据库的区别
传统的关系型数据库是基于 ACID(原子性、一致性、隔离性和持久性)事务模型的,而分布式 NoSQL 数据库则更加注重可扩展性、高性能和高可用性。
在分布式 NoSQL 数据库中,数据被分布存储在多个节点上,通过分区和副本的方式实现数据的分布式存储和冗余备份。这种分布式存储方式使得 NoSQL 数据库能够处理大量的数据,并提供高可用性和容错能力。
另外,分布式 NoSQL 数据库往往采用键值对、文档、列族等不同的数据模型,比传统的关系型数据库更加灵活,可以适应不同类型的数据存储需求。
总结一下,CDH作为一个大数据处理平台,在其中集成了多种 NoSQL 数据库,提供了企业级的大数据存储和处理方案。与传统的关系型数据库相比,分布式 NoSQL 数据库更加注重可扩展性和高性能,适用于处理大规模数据的场景。
# 3. HBase的架构
#### 3.1 HBase的组成部分
HBase架构由以下几个重要组成部分组成:
1. HMaster:HBase集群中的主节点,负责管理RegionServer和数据表的元数据信息,包括Region的分配和负载均衡。
2. RegionServer:HBase集群中的工作节点,负责存储和管理数据。每个RegionServer可以负责多个Region,每个Region对应HBase表中的一个数据范围。
3. ZooKeeper:HBase使用ZooKeeper来实现分布式协调和锁服务,负责管理HBase集群的状态信息、配置信息以及集群的故障恢复。
4. HDFS:Hadoop分布式文件系统,作为HBase的底层存储,提供数据的高可靠性和分布式存储能力。
5. HFile:HBase的数据存储文件格式,在HDFS上存储数据,并按照指定的排序方式进行组织,提供高效的数据读写能力。
6. MemStore:HBase的内存存储容器,用于缓存写入的数据。当MemStore中的数据量达到一定阈值后,会被刷新到磁盘上的HFile中。
#### 3.2 HBase的工作原理
HBase的工作原理可以简单概括为以下几个步骤:
1. 创建表时,HBase会根据设定的分区策略将表分割成多个Region,并将这些Region分布在不同的RegionServer上。
2. 当客户端需要读取或写入数据时,首先会向ZooKeeper获取HBase集群的元数据信息,包括表的分区情况和RegionServer的位置。
3. 客户端根据元数据定位到存储目标的RegionServer,并发送查询或写入请求。
4. 对于读取请求,RegionServer根据查询条件在对应的Region中进行查找,并返回匹配的结果给客户端。
5. 对于写入请求,RegionServer将数据先写入内存中的MemStore,当MemStore的数据量达到一定阈值时,将数据刷新到磁盘上的HFile中。
6. 客户端可以通过HBase的API来进行数据的CRUD操作,同时也可以通过HBase的过滤器机制对数据进行进一步的处理和过滤。
#### 3.3 HBase在CDH中的角色和功能
在CDH(Cloudera's Distribution including Apache Hadoop)中,HBase作为大数据生态系统的一部分,扮演着重要的角色:
1. 数据存储:HBase作为NoSQL数据库,提供分布式、高可靠性的数据存储能力,能够承载海量数据的处理和存储需求。
2. 实时查询:HBase支持快速的随机读写,并能够在毫秒级别响应查询请求,适用于实时数据分析和查询场景。
3. 数据分析:HBase可以与其他大数据组件(如Hadoop、Spark等)无缝集成,提供高效的数据分析能力,支持批处理和实时流处理。
4. 数据一致性和容错性:HBase通过HDFS和ZooKeeper的支持,实现了数据的高可靠性和一致性,能够应对节点故障和数据丢失等情况。
总结:HBase的架构由HMaster、RegionServer、ZooKeeper、HDFS、HFile和MemStore等组成,在CDH中发挥着重要的角色,可以提供高可靠性的数据存储和实时查询能力,适用于大数据分析和存储场景。
# 4. HBase的部署和配置
HBase的部署和配置是使用HBase的重要环节,正确的部署和配置可以保证HBase集群的高性能和稳定运行。本章将介绍HBase的部署和配置步骤,包括准备工作、集群部署和HBase的配置。
### 4.1 准备工作
在部署HBase之前,需要完成以下准备工作:
- **环境准备**:确保每台服务器都具备HBase运行所需的环境,例如Java环境、必要的依赖包等。
- **系统配置**:调整操作系统的配置以满足HBase的要求,例如增加文件描述符的限制、修改内核参数等。
- **网络设置**:配置服务器之间的网络通信,确保HBase集群内各节点之间可以相互通信。
### 4.2 集群部署
HBase通常部署在由多台服务器组成的集群上,其典型的部署模式是主从架构。在集群部署过程中,需要注意以下几点:
- **Master节点**:选择一台或多台服务器作为HBase的Master节点,负责整个集群的协调和管理。
- **RegionServer节点**:其余的服务器作为HBase的RegionServer节点,负责存储和管理数据。
- **ZooKeeper集群**:HBase依赖ZooKeeper进行协调,在部署HBase之前需要先部署ZooKeeper集群。
### 4.3 配置HBase
完成集群部署后,需要对HBase进行相应的配置,主要包括以下内容:
- **HBase配置文件**:修改HBase的配置文件,例如hbase-site.xml、hdfs-site.xml等,配置HBase的核心参数和依赖组件的连接信息。
- **RegionServer配置**:根据实际情况配置RegionServer的个数和资源分配。
- **ZooKeeper配置**:配置HBase连接ZooKeeper的信息和参数。
在配置完成后,需要重启HBase集群以使配置生效。
通过完成以上部署和配置步骤,可以搭建一个稳定高效的HBase集群,为后续的数据存储和操作提供良好的基础。
# 5. HBase的数据模型和操作
#### 5.1 表和行键的概念
HBase是一个面向列的NoSQL数据库,数据以表的形式存储,每个表可以有多行,每行可以有多个列族,每个列族可以包含多个列。在HBase中,行键是唯一的,表的设计要根据业务需求精心选择行键,合理的行键设计可以提高检索效率。
```java
// 创建HBase表
HBaseAdmin admin = new HBaseAdmin(config);
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf("my_table"));
HColumnDescriptor columnFamily = new HColumnDescriptor("cf1");
tableDescriptor.addFamily(columnFamily);
admin.createTable(tableDescriptor);
// 插入数据
HTable table = new HTable(config, "my_table");
Put putData = new Put(Bytes.toBytes("row_key1"));
putData.add(Bytes.toBytes("cf1"), Bytes.toBytes("col1"), Bytes.toBytes("value1"));
table.put(putData);
// 查询数据
Get getData = new Get(Bytes.toBytes("row_key1"));
Result result = table.get(getData);
for (Cell cell : result.rawCells()) {
System.out.println("Cell: " + cell + " Value: " + Bytes.toString(CellUtil.cloneValue(cell)));
}
```
#### 5.2 列簇和列
HBase中的数据存储是以列簇的形式组织的,每个列簇包含多个列。列簇在表创建时需要预先定义,并且不能在后续的操作中动态添加或删除。列簇和列的设计要根据实际数据存储和查询需求进行规划。
```java
// 创建HBase表时定义列簇
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf("my_table"));
HColumnDescriptor columnFamily1 = new HColumnDescriptor("cf1");
HColumnDescriptor columnFamily2 = new HColumnDescriptor("cf2");
tableDescriptor.addFamily(columnFamily1);
tableDescriptor.addFamily(columnFamily2);
admin.createTable(tableDescriptor);
// 插入数据到不同列簇
Put putData1 = new Put(Bytes.toBytes("row_key1"));
putData1.add(Bytes.toBytes("cf1"), Bytes.toBytes("col1"), Bytes.toBytes("value1"));
Put putData2 = new Put(Bytes.toBytes("row_key1"));
putData2.add(Bytes.toBytes("cf2"), Bytes.toBytes("col2"), Bytes.toBytes("value2"));
table.put(putData1);
table.put(putData2);
```
#### 5.3 CRUD操作
HBase支持对数据的增加、查询、修改和删除操作,通过Put、Get、Scan和Delete等API可以实现对数据的CRUD操作。
```java
// 创建HBase表和插入数据已在前面代码示例中给出
// 查询数据
Get getData = new Get(Bytes.toBytes("row_key1"));
Result result = table.get(getData);
for (Cell cell : result.rawCells()) {
System.out.println("Cell: " + cell + " Value: " + Bytes.toString(CellUtil.cloneValue(cell)));
}
// 修改数据
Put newData = new Put(Bytes.toBytes("row_key1"));
newData.add(Bytes.toBytes("cf1"), Bytes.toBytes("col1"), Bytes.toBytes("new_value"));
table.put(newData);
// 删除数据
Delete deleteData = new Delete(Bytes.toBytes("row_key1"));
table.delete(deleteData);
```
#### 5.4 数据版本控制
HBase为每个单元格可保存不同版本的数据,默认为3个版本,可以配置为更多。通过版本控制,可以实现对历史数据的检索和回溯。
```java
// 增加数据版本
Put putData = new Put(Bytes.toBytes("row_key1"));
putData.add(Bytes.toBytes("cf1"), Bytes.toBytes("col1"), Bytes.toBytes("value1"));
table.put(putData);
// 再次修改数据
Put newData = new Put(Bytes.toBytes("row_key1"));
newData.add(Bytes.toBytes("cf1"), Bytes.toBytes("col1"), Bytes.toBytes("new_value"));
table.put(newData);
// 获取历史版本数据
Get getVersionedData = new Get(Bytes.toBytes("row_key1"));
getVersionedData.setMaxVersions(5); // 获取最多5个版本的数据
Result versionedResult = table.get(getVersionedData);
for (Cell cell : versionedResult.rawCells()) {
System.out.println("Cell: " + cell + " Value: " + Bytes.toString(CellUtil.cloneValue(cell)));
}
```
通过以上代码示例,可以了解HBase的数据模型和操作的基本原理和用法。
# 6. HBase的使用案例
HBase作为一种分布式、面向列的NoSQL数据库,可以在多种场景下发挥作用。接下来,我们将介绍HBase在实际使用案例中的应用场景和优势。
#### 6.1 实时数据分析
HBase适用于实时数据分析的场景,例如在互联网广告投放、用户行为分析等领域。由于HBase具有横向扩展能力和快速读写特性,可以快速存储大量实时产生的数据,并支持对这些数据进行实时查询和分析。下面我们以一个简单的用户行为分析场景为例,演示HBase在实时数据分析中的应用。
```python
# 代码示例
import happybase
# 连接HBase
connection = happybase.Connection('hbase-host')
table = connection.table('user_behavior')
# 存储用户点击行为数据
table.put(b'row-key1', {b'info:action': b'click', b'info:timestamp': b'20220101010101'})
table.put(b'row-key2', {b'info:action': b'view', b'info:timestamp': b'20220101010202'})
# 查询用户点击行为数据
data = table.row(b'row-key1', columns=[b'info:action', b'info:timestamp'])
print(data) # 输出查询结果
```
**代码总结:** 上述代码通过HappyBase库连接HBase,存储用户行为数据,并查询特定行键的数据。其中,`info:action`表示用户行为,`info:timestamp`表示时间戳。
**结果说明:** 通过HBase可以方便地存储和查询用户行为数据,支持实时数据分析应用场景。
#### 6.2 数据存储与检索
除了实时数据分析,HBase还可以作为数据存储与检索引擎,用于存储和查询海量数据。在电商行业、物联网领域等,通常需要存储大量的结构化数据,并能够快速检索,HBase正是适合这类场景的解决方案。下面我们以一个电商订单管理系统为例,演示HBase在数据存储与检索中的应用。
```java
// 代码示例
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
// 创建HBase配置
Configuration config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum", "hbase-zookeeper-host");
// 连接HBase
Connection connection = ConnectionFactory.createConnection(config);
Table table = connection.getTable(TableName.valueOf("orders"));
// 存储订单数据
Put put = new Put(Bytes.toBytes("order1"));
put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("product"), Bytes.toBytes("iphone"));
put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("quantity"), Bytes.toBytes("2"));
table.put(put);
// 查询订单数据
Get get = new Get(Bytes.toBytes("order1"));
Result result = table.get(get);
byte[] product = result.getValue(Bytes.toBytes("info"), Bytes.toBytes("product"));
System.out.println(Bytes.toString(product)); // 输出查询结果
```
**代码总结:** 以上Java代码示例中,通过HBase存储了订单数据,包括产品和数量信息,并进行了简单的查询操作。
**结果说明:** HBase可用于存储大量订单数据,并支持快速检索,适用于电商等场景。
#### 6.3 高并发访问
在需要支撑高并发访问的应用场景中,HBase也能够发挥作用。例如在社交网络、在线游戏等场景中,需要处理大量用户并发操作,HBase的分布式架构和快速读写特性可以很好地支持高并发访问需求。下面我们以一个简单的社交网络应用为例,演示HBase在高并发访问场景的应用。
```go
// 代码示例
package main
import (
"context"
"fmt"
"github.com/tsuna/gohbase"
"github.com/tsuna/gohbase/hrpc"
)
func main() {
client := gohbase.NewClient("hbase-host")
// 创建表
tableName := "social"
createTable := hrpc.NewCreateTable(context.Background(), []byte(tableName), []byte("info"))
client.CreateTable(createTable)
// 插入数据
putRequest, _ := hrpc.NewPutStr(context.Background(), tableName, "user1", map[string]map[string][]byte{"info": {"name": []byte("Alice")}})
client.Put(putRequest)
// 查询数据
getRequest, _ := hrpc.NewGetStr(context.Background(), tableName, "user1")
r, _ := client.Get(getRequest)
nameCell := r.Cells[0]
fmt.Printf("Name: %s\n", nameCell.Value)
}
```
**代码总结:** 以上Go语言代码示例中,使用gohbase库连接HBase,创建表并插入数据,然后进行查询操作。
**结果说明:** HBase可以很好地支持高并发访问,适用于需要处理大量用户并发操作的应用场景。
通过以上使用案例的介绍,读者可以进一步了解HBase在实际应用中的场景和优势。 HBase作为一种高可靠、高扩展、面向列的分布式数据库,在众多大数据应用中发挥着重要作用。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏《CDH》致力于为读者提供CDH(Cloudera's Distribution Including Apache Hadoop)大数据平台相关的内容。从HBase基础教程到Sqoop数据传输工具,再到Flume实时日志收集指南和Oozie定时任务调度,专栏涵盖了CDH中的各种关键功能和工具的详尽解析。此外,Sentry权限管理的详细介绍,以及CDH性能调优与优化指南和监控与诊断工具的解密揭秘,也为读者提供了实用的技巧与经验。专栏还介绍了CDH集群备份与恢复指南以及版本升级与迁移指南,旨在为用户提供保障数据可靠性和稳定性的解决方案。如果您想了解如何在CDH环境下优化大数据处理效率、确保系统稳定性以及实现无缝升级与数据迁移,本专栏将为您提供宝贵的经验和指导。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【调试与诊断】:cl.exe高级调试技巧,让代码问题无所遁形
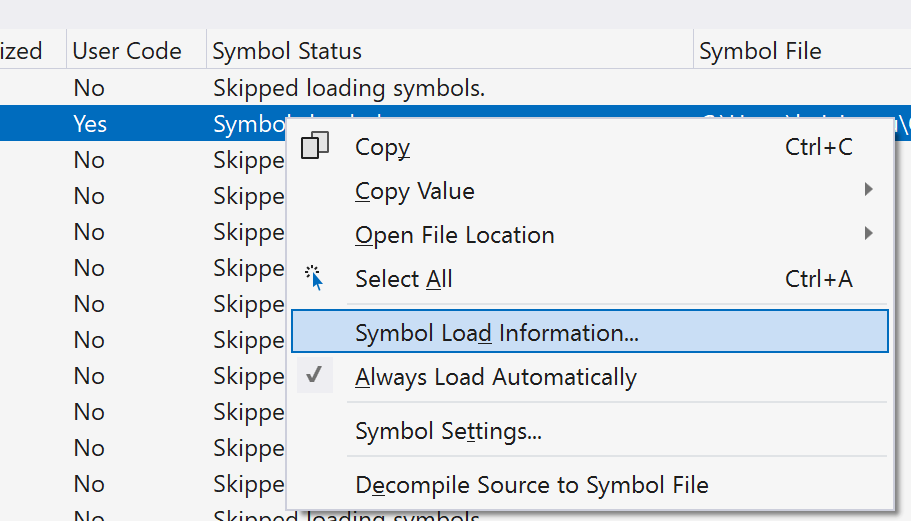
# 摘要
本文围绕软件开发的调试与诊断技术进行了深入探讨,特别是聚焦于Microsoft Visual Studio环境中的cl.exe编译器。文章首先介绍了调试与诊断的基础知识,随后详细解析了cl.exe编译器的使用、优化及调试符号管理。高级
【多核系统中Xilinx Tri-Mode MAC的高效应用】:架构设计与通信机制

# 摘要
本文深入探讨了多核系统环境下网络通信的优化与维护问题,特别关注了Xilinx Tri-Mode MAC架构的关键特性和高效应用。通过对核心硬件设计、网络通信协议、多核处理器集成以及理论模型的分析,文章阐述了如何在多核环境中实现高速数据传输与任务调度。本文还提供了故障诊断技术、系统维护与升级策略,并通过案例研究,探讨了Tri-Mode MAC在高性能计算与数据中心的应用
【APQC五级设计框架深度解析】:企业流程框架入门到精通

# 摘要
APQC五级设计框架是一个综合性的企业流程管理工具,旨在通过结构化的方法提升企业的流程管理能力和效率。本文首先概述了APQC框架的核心原则和结构,强调了企业流程框架的重要性,并详细描述了框架的五大级别和流程分类方法。接着,文章深入探讨了设计和实施APQC框架的方法论,包括如何识别关键流程、确定流程的输入输出、进行现状评估、制定和执行实施计划。此外,本文还讨论了APQC
ARINC653标准深度解析:航空电子实时操作系统的设计与应用(权威教程)

# 摘要
ARINC653作为一种航空航天领域内应用广泛的标准化接口,为实时操作系统提供了一套全面的架构规范。本文首先概述了ARINC653标准,然后详细分析了其操作系统架构及实时内核的关键特性,包括任务管理和时间管理调度、实时系统的理论基础与性能评估,以及内核级通信机制。接着,文章探讨了ARINC653的应用接口(
【软件仿真工具】:MATLAB_Simulink在倒立摆设计中的应用技巧
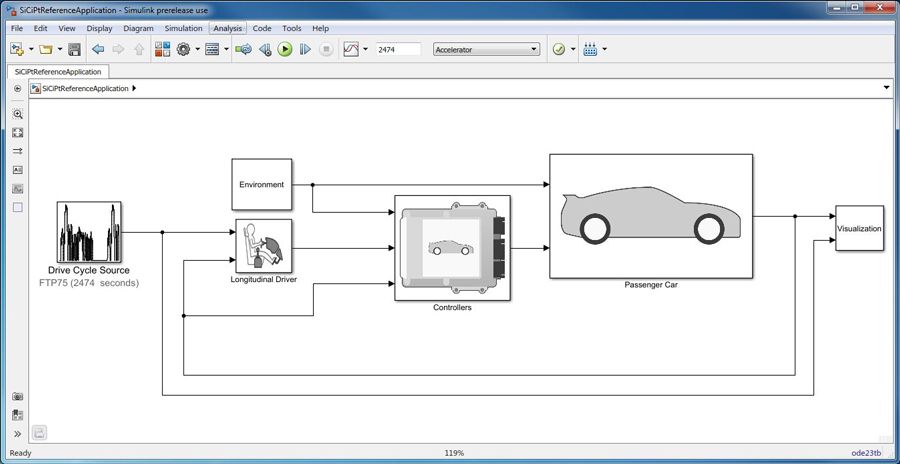
# 摘要
本文系统地介绍了MATLAB与Simulink在倒立摆系统设计与控制中的应用。文章首先概述
自动化测试与验证指南:高通QXDM工具提高研发效率策略

# 摘要
随着移动通信技术的快速发展,高通QXDM工具已成为自动化测试和验证领域不可或缺的组件。本文首先概述了自动化测试与验证的基本概念,随后对高通QXDM工具的功能、特点、安装和配置进行了详细介绍。文章重点探讨了QXDM工具在自动化测试与验证中的实际应用,包括脚本编写、测试执行、结果分析、验证流程设计及优化策略。此外,本文还分析了QXDM工具如何提高研发效率,并探讨了其技术发展趋势以及
C语言内存管理:C Primer Plus第六版指针习题解析与技巧

# 摘要
本论文深入探讨了C语言内存管理和指针应用的理论与实践。第一章为C语言内存管理的基础介绍,第二章系统阐述了指针与内存分配的基本概念,包括动态与静态内存、堆栈管理,以及指针类型与内存地址的关系。第三章对《C Primer Plus》第六版中的指针习题进行了详细解析,涵盖基础、函数传递和复杂数据结构的应用。第四章则集中于指针的高级技巧和最佳实践,重点讨论了内存操作、防止内存泄漏及指针错
【PDF元数据管理艺术】:轻松读取与编辑PDF属性的秘诀

# 摘要
本文详细介绍了PDF元数据的概念、理论基础、读取工具与方法、编辑技巧以及在实际应用中的案例研究。PDF元数据作为电子文档的重要组成部分,不仅对文件管理与检索具有关键作用,还能增强文档的信息结构和互操作性。文章首先解析了PDF文件结构,阐述了元数据的位置和作用,并探讨了不同标准和规范下元数据的特点。随后,本文评述了多种读取PDF元数据的工具和方法,包括命令行和图形用户
中兴交换机QoS配置教程:网络性能与用户体验双优化指南
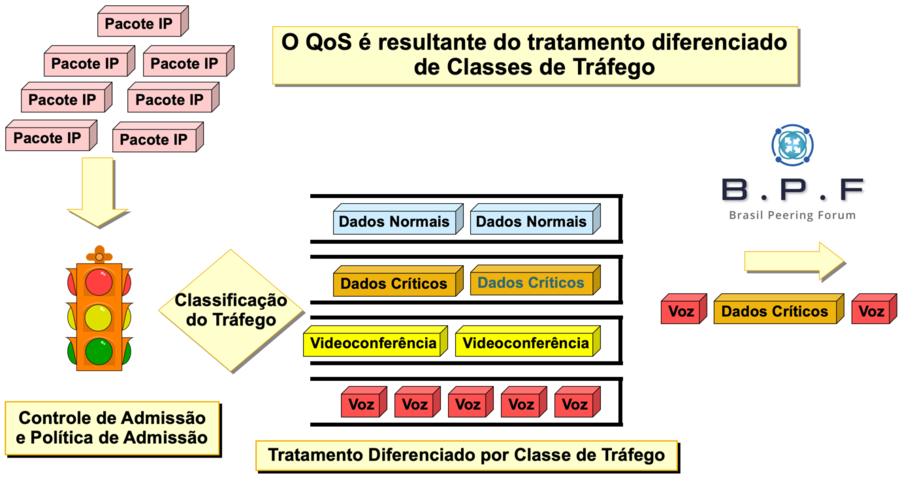
# 摘要
随着网络技术的快速发展,服务质量(QoS)成为交换机配置中的关键考量因素,直接影响用户体验和网络资源的有效管理。本文详细阐述了QoS的基础概念、核心原则及其在交换机中的重要性,并深入探讨了流量分类、标记、队列调度、拥塞控制和流量整形等关键技术。通过中兴交换机的配置实践和案例研究,本文展示了如何在不同网络环境中有效地应用QoS策略,以及故障排查
工程方法概览:使用MICROSAR进行E2E集成的详细流程
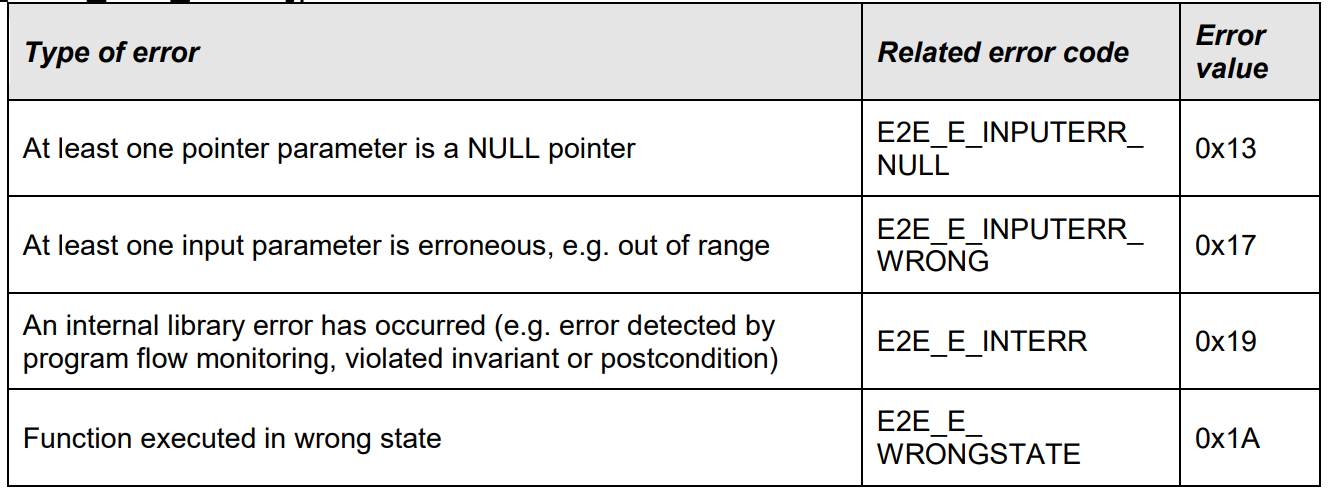
# 摘要
本文全面阐述了MICROSAR基础和其端到端(E2E)集成概念,详细介绍了MICROSAR E2E集成环境的建立过程,包括软件组件的安装配置和集成开发工具的使用。通过实践应用章节,分析了E2E集成在通信机制和诊断机制的实现方法。此外,文章还探讨了E2E集成的安全机制和性能优化策略,以及通过项目案例分析展示了E2E集成在实际项目中的应用,讨论了遇到的问题和解决方案,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )