Python print()函数的进阶技巧:解锁格式化输出和字符串操作的奥秘
发布时间: 2024-06-22 20:43:34 阅读量: 7 订阅数: 12 

# 1. Python print()函数基础**
print()函数是Python中用于在控制台中输出信息的内置函数。其基本语法为:
```python
print(*objects, sep=' ', end='\n', file=sys.stdout, flush=False)
```
其中:
* objects:要输出的对象,可以是字符串、数字、列表等任意数据类型。
* sep:对象之间的分隔符,默认为空格。
* end:输出后的换行符,默认为换行符。
* file:输出的目标文件,默认为标准输出(sys.stdout)。
* flush:是否立即刷新输出缓冲区,默认为False。
# 2. Python print()函数格式化输出
### 2.1 字符串格式化语法
Python 的 print() 函数支持字符串格式化,允许我们使用占位符来动态地插入变量或表达式。字符串格式化语法如下:
```python
print(f"格式化字符串", 变量1, 变量2, ..., 关键字参数=值)
```
其中:
* `f` 前缀表示使用 f-string 格式化语法。
* `格式化字符串` 是一个包含占位符的字符串。
* `变量1`、`变量2` 等是需要插入的变量或表达式。
* `关键字参数=值` 是可选的,用于指定占位符的格式化选项。
### 2.1.1 位置参数
位置参数使用 `{}` 占位符,占位符中指定变量或表达式的索引。索引从 0 开始,依次对应于要插入的变量或表达式。例如:
```python
name = "John Doe"
age = 30
print(f"姓名:{name}, 年龄:{age}")
```
输出:
```
姓名:John Doe, 年龄:30
```
### 2.1.2 关键字参数
关键字参数使用 `{关键字}` 占位符,占位符中指定变量或表达式的名称。关键字参数允许我们指定占位符的格式化选项,例如对齐方式、小数位数等。例如:
```python
name = "John Doe"
age = 30
print(f"姓名:{name:<20}, 年龄:{age:>5}")
```
输出:
```
姓名:John Doe , 年龄: 30
```
其中:
* `:<20` 指定 `name` 变量左对齐,并填充 20 个空格。
* `:>5` 指定 `age` 变量右对齐,并填充 5 个空格。
### 2.2 格式化字符串类型
Python 的 print() 函数支持多种字符串类型的格式化:
### 2.2.1 数字格式化
数字格式化使用 `:` 后跟格式化说明符。常见的格式化说明符包括:
* `d`:十进制整数
* `f`:浮点数
* `e`:科学计数法
* `%`:百分比
例如:
```python
number = 1234.5678
print(f"十进制整数:{number:d}")
print(f"浮点数:{number:f}")
print(f"科学计数法:{number:e}")
print(f"百分比:{number:%}")
```
输出:
```
十进制整数:1235
浮点数:1234.567800
科学计数法:1.234568e+03
百分比:1234.5678%
```
### 2.2.2 字符串格式化
字符串格式化使用 `:` 后跟格式化说明符。常见的格式化说明符包括:
* `s`:字符串
* `r`:原始字符串(不转义特殊字符)
* `a`:对齐(左对齐、居中、右对齐)
例如:
```python
name = "John Doe"
print(f"字符串:{name:s}")
print(f"原始字符串:{name:r}")
print(f"左对齐:{name:<20}")
print(f"居中:{name:^20}")
print(f"右对齐:{name:>20}")
```
输出:
```
字符串:John Doe
原始字符串:John Doe
左对齐:John Doe
居中: John Doe
右对齐: John Doe
```
### 2.2.3 日期和时间格式化
日期和时间格式化使用 `:` 后跟格式化说明符。常见的格式化说明符包括:
* `%Y`:年
* `%m`:月
* `%d`:日
* `%H`:小时
* `%M`:分钟
* `%S`:秒
例如:
```python
from datetime import datetime
now = datetime.now()
print(f"当前日期:{now:%Y-%m-%d}")
print(f"当前时间:{now:%H:%M:%S}")
```
输出:
```
当前日期:2023-03-08
当前时间:14:30:15
```
# 3.1 字符串拼接和连接
字符串拼接和连接是 Python 中常见的操作,用于将多个字符串组合成一个新的字符串。有几种方法可以实现字符串拼接和连接:
**+ 运算符**
+ 运算符用于字符串拼接,它将两个字符串连接在一起。例如:
```python
>>> str1 = "Hello"
>>> str2 = "World"
>>> str3 = str1 + str2
>>> print(str3)
HelloWorld
```
**join() 方法**
join() 方法用于将一个列表或元组中的所有字符串连接在一起,并使用指定的连接符。例如:
```python
>>> my_list = ["Hello", "World", "Python"]
>>> str3 = " ".join(my_list)
>>> print(str3)
Hello World Python
```
**format() 方法**
format() 方法可以用于字符串拼接,它允许使用占位符和格式化字符串来创建新的字符串。例如:
```python
>>> name = "John"
>>> age = 30
>>> str3 = "My name is {} and I am {} years old.".format(name, age)
>>> print(str3)
My name is John and I am 30 years old.
```
### 3.2 字符串切片和索引
字符串切片和索引允许我们访问字符串中的特定字符或子字符串。有几种方法可以实现字符串切片和索引:
**[] 运算符**
[] 运算符用于索引字符串中的字符或子字符串。索引从 0 开始,正索引表示从字符串开头开始,负索引表示从字符串末尾开始。例如:
```python
>>> str = "Hello World"
>>> print(str[0]) # 输出 'H'
>>> print(str[6]) # 输出 'W'
>>> print(str[-1]) # 输出 'd'
```
**切片操作**
切片操作允许我们从字符串中提取一个子字符串。语法为 `str[start:end:step]`, 其中:
* start:开始索引(包含)
* end:结束索引(不包含)
* step:步长(可选,默认值为 1)
例如:
```python
>>> str = "Hello World"
>>> print(str[0:5]) # 输出 'Hello'
>>> print(str[6:11]) # 输出 'World'
>>> print(str[0:11:2]) # 输出 'HloWrd'
```
### 3.3 字符串查找和替换
字符串查找和替换允许我们在字符串中搜索和替换子字符串。有几种方法可以实现字符串查找和替换:
**find() 和 rfind() 方法**
find() 方法用于在字符串中查找子字符串的第一个匹配项,rfind() 方法用于查找最后一个匹配项。如果找不到匹配项,则返回 -1。例如:
```python
>>> str = "Hello World"
>>> print(str.find("World")) # 输出 6
>>> print(str.rfind("World")) # 输出 6
```
**replace() 方法**
replace() 方法用于在字符串中替换子字符串。语法为 `str.replace(old, new, count)`, 其中:
* old:要替换的子字符串
* new:替换后的子字符串
* count:替换次数(可选,默认值为全部替换)
例如:
```python
>>> str = "Hello World"
>>> print(str.replace("World", "Python")) # 输出 'Hello Python'
```
# 4. Python print()函数进阶应用
### 4.1 输出控制和重定向
#### 4.1.1 输出缓冲区
默认情况下,Python 的 print() 函数会立即将输出发送到标准输出流(通常是控制台窗口)。但是,我们可以使用缓冲区来控制输出的时机。
```python
import sys
# 设置缓冲区为行缓冲
sys.stdout = open(sys.stdout.fileno(), mode='w', buffering=1)
print('Hello')
print('World')
```
执行以上代码时,输出不会立即显示,直到缓冲区已满(即达到缓冲区大小或换行符)。
#### 4.1.2 文件输出
我们可以使用 `file` 参数将输出重定向到文件。
```python
with open('output.txt', 'w') as f:
print('Hello', 'World', file=f)
```
执行以上代码后,输出将写入 `output.txt` 文件。
#### 4.1.3 错误输出
Python 提供了 `sys.stderr` 流用于错误输出。我们可以使用 `file` 参数将错误信息重定向到 `sys.stderr`。
```python
print('Error message', file=sys.stderr)
```
### 4.2 调试和日志记录
#### 4.2.1 print()函数作为调试工具
print() 函数可以作为一种方便的调试工具。通过在代码中添加 print() 语句,我们可以输出变量值或中间结果,以帮助我们了解程序的执行流程。
```python
def sum_numbers(a, b):
print(f'a: {a}, b: {b}')
return a + b
result = sum_numbers(10, 20)
print(f'Result: {result}')
```
#### 4.2.2 print()函数在日志记录中的应用
print() 函数也可以用于日志记录。通过将输出重定向到日志文件,我们可以记录程序的执行信息、错误消息和调试信息。
```python
import logging
# 设置日志级别
logging.basicConfig(level=logging.INFO)
# 创建一个日志器
logger = logging.getLogger(__name__)
# 记录一条信息日志
logger.info('Program started')
# 记录一条错误日志
logger.error('An error occurred')
```
# 5.1 prettytable库
### 5.1.1 表格输出美化
prettytable库是一个Python库,用于美化表格输出。它提供了一个`PrettyTable`类,可以轻松创建和格式化表格数据。
```python
from prettytable import PrettyTable
# 创建一个表格
table = PrettyTable(["姓名", "年龄", "城市"])
# 添加行
table.add_row(["John", 30, "New York"])
table.add_row(["Jane", 25, "London"])
table.add_row(["Peter", 40, "Paris"])
# 打印表格
print(table)
```
输出:
```
+---------+-------+--------+
| 姓名 | 年龄 | 城市 |
+---------+-------+--------+
| John | 30 | New York |
| Jane | 25 | London |
| Peter | 40 | Paris |
+---------+-------+--------+
```
### 5.1.2 表格对齐和排序
prettytable库还允许对表格进行对齐和排序。
**对齐**
```python
# 设置对齐方式
table.align = "l" # 左对齐
table.align = "c" # 居中对齐
table.align = "r" # 右对齐
```
**排序**
```python
# 按特定列排序
table.sortby = "年龄"
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
Python print()函数是Python中用于输出信息的强大工具。本专栏深入探讨了print()函数的方方面面,从初学者到高级用户都可以从中受益。专栏涵盖了print()函数的用法、进阶技巧、常见陷阱、调试利器、性能优化、替代方案以及在各种应用场景中的使用,包括数据分析、Web开发、机器学习、自动化脚本、多线程和多进程、分布式系统、云计算、测试和调试、代码重构、敏捷开发、DevOps、持续集成和持续交付、微服务架构等。通过深入理解print()函数,您可以有效地输出信息,调试问题,优化代码,并提高应用程序的整体质量。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【实战演练】虚拟宠物:开发一个虚拟宠物游戏,重点在于状态管理和交互设计。

# 2.1 虚拟宠物的状态模型
### 2.1.1 宠物的基本属性
虚拟宠物的状态由一系列基本属性决定,这些属性描述了宠物的当前状态,包括:
- **生命值 (HP)**:宠物的健康状况,当 HP 为 0 时,宠物死亡。
- **饥饿值 (Hunger)**:宠物的饥饿程度,当 Hunger 为 0 时,宠物会饿死。
- **口渴
【实战演练】前沿技术应用:AutoML实战与应用

# 1. AutoML概述与原理**
AutoML(Automated Machine Learning),即自动化机器学习,是一种通过自动化机器学习生命周期
【实战演练】时间序列预测项目:天气预测-数据预处理、LSTM构建、模型训练与评估

# 1. 时间序列预测概述**
时间序列预测是指根据历史数据预测未来值。它广泛应用于金融、天气、交通等领域,具有重要的实际意义。时间序列数据通常具有时序性、趋势性和季节性等特点,对其进行预测需要考虑这些特性。
# 2. 数据预处理
### 2.1 数据收集和清洗
#### 2.1.1 数据源介绍
时间序列预测模型的构建需要可靠且高质量的数据作为基础。数据源的选择至关重要,它将影响模型的准确性和可靠性。常见的时序数据源包括:
【实战演练】构建简单的负载测试工具

# 1. 负载测试基础**
负载测试是一种性能测试,旨在模拟实际用户负载,评估系统在高并发下的表现。它通过向系统施加压力,识别瓶颈并验证系统是否能够满足预期性能需求。负载测试对于确保系统可靠性、可扩展性和用户满意度至关重要。
# 2. 构建负载测试工具
### 2.1 确定测试目标和指标
在构建负载测试工具之前,至关重要的是确定测试目标和指标。这将指导工具的设计和实现。以下是一些需要考虑的关键因素:
【进阶】入侵检测系统简介
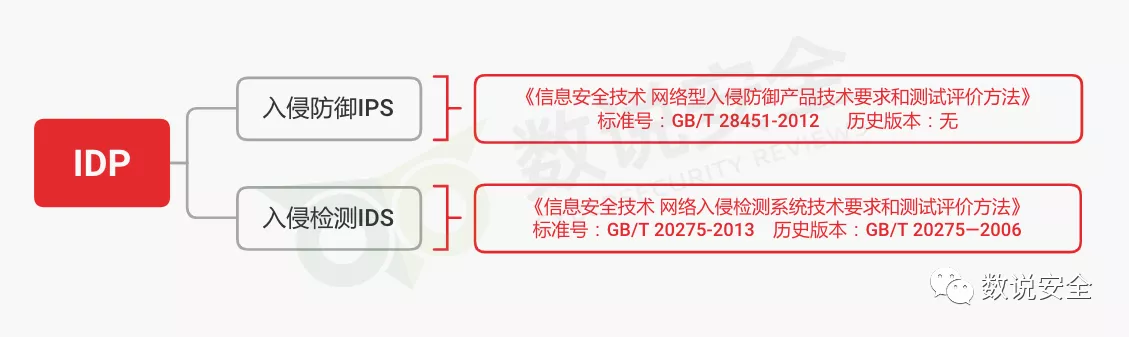
# 1. 入侵检测系统概述**
入侵检测系统(IDS)是一种网络安全工具,用于检测和预防未经授权的访问、滥用、异常或违反安全策略的行为。IDS通过监控网络流量、系统日志和系统活动来识别潜在的威胁,并向管理员发出警报。
IDS可以分为两大类:基于网络的IDS(NIDS)和基于主机的IDS(HIDS)。NIDS监控网络流量,而HIDS监控单个主机的活动。IDS通常使用签名检测、异常检测和行
【实战演练】综合案例:数据科学项目中的高等数学应用

# 1. 数据科学项目中的高等数学基础**
高等数学在数据科学中扮演着至关重要的角色,为数据分析、建模和优化提供了坚实的理论基础。本节将概述数据科学
【实战演练】通过强化学习优化能源管理系统实战
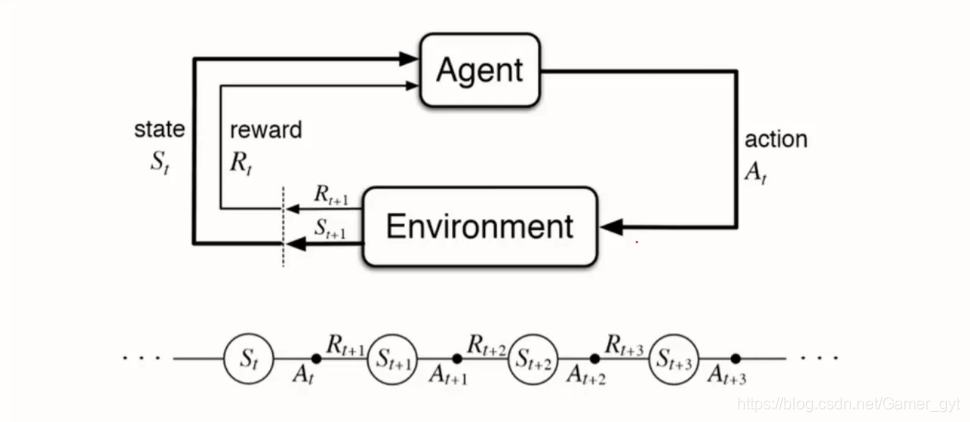
# 2.1 强化学习的基本原理
强化学习是一种机器学习方法,它允许智能体通过与环境的交互来学习最佳行为。在强化学习中,智能体通过执行动作与环境交互,并根据其行为的
【实战演练】深度学习在计算机视觉中的综合应用项目

# 1. 计算机视觉概述**
计算机视觉(CV)是人工智能(AI)的一个分支,它使计算机能够“看到”和理解图像和视频。CV 旨在赋予计算机人类视觉系统的能力,包括图像识别、对象检测、场景理解和视频分析。
CV 在广泛的应用中发挥着至关重要的作用,包括医疗诊断、自动驾驶、安防监控和工业自动化。它通过从视觉数据中提取有意义的信息,为计算机提供环境感知能力,从而实现这些应用。
# 2.1 卷积
【实战演练】使用Docker与Kubernetes进行容器化管理
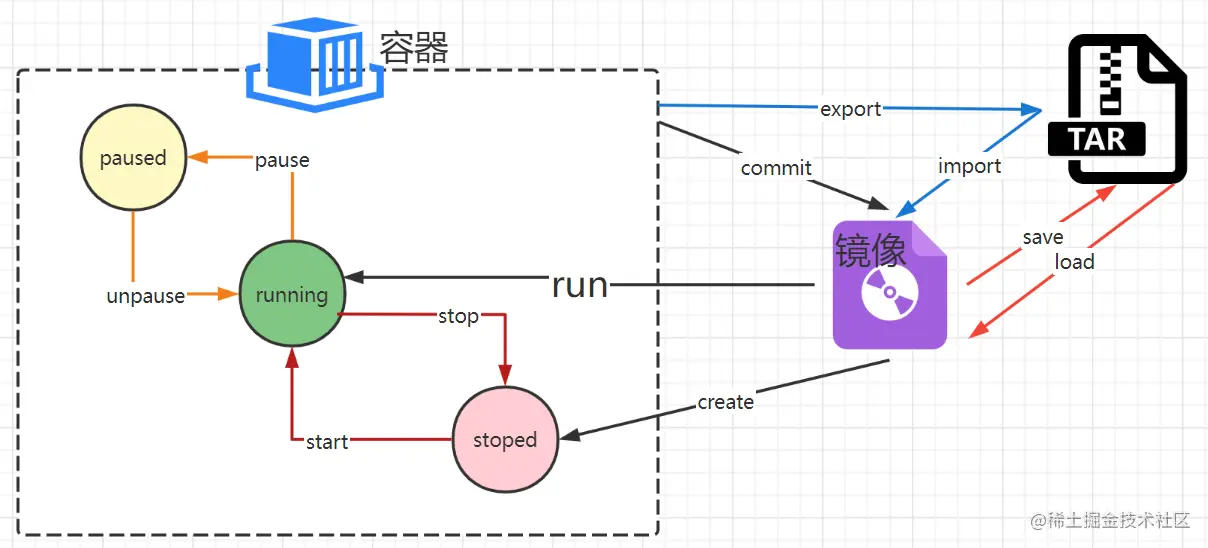
# 2.1 Docker容器的基本概念和架构
Docker容器是一种轻量级的虚拟化技术,它允许在隔离的环境中运行应用程序。与传统虚拟机不同,Docker容器共享主机内核,从而减少了资源开销并提高了性能。
Docker容器基于镜像构建。镜像是包含应用程序及
【实战演练】python云数据库部署:从选择到实施
# 2.1 云数据库类型及优劣对比
**关系型数据库(RDBMS)**
* **优点:**
* 结构化数据存储,支持复杂查询和事务
* 广泛使用,成熟且稳定
* **缺点:**
* 扩展性受限,垂直扩展成本高
* 不适合处理非结构化或半结构化数据
**非关系型数据库(NoSQL)**
* **优点:**
* 可扩展性强,水平扩展成本低
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )