OpenCV轮廓凸度计算:图像分割与目标识别,深入分析图像轮廓形状
发布时间: 2024-08-08 15:29:18 阅读量: 41 订阅数: 44 
# 1. OpenCV图像分割概述
图像分割是计算机视觉中一项基本任务,旨在将图像分解为具有不同特征的子区域。OpenCV(Open Source Computer Vision Library)是一个强大的计算机视觉库,提供了丰富的图像分割算法。
OpenCV中的图像分割方法主要分为两类:基于阈值的分割和基于区域的分割。基于阈值的分割根据像素强度或颜色将图像分成不同的区域,而基于区域的分割则将具有相似特征的像素分组在一起。
OpenCV提供了多种图像分割算法,包括阈值分割、颜色空间分割、形态学分割和聚类分割等。这些算法可以根据不同的图像特征和应用场景选择使用。
# 2. OpenCV轮廓提取与分析
### 2.1 轮廓的概念与提取方法
#### 2.1.1 轮廓的定义和提取步骤
**轮廓定义:**
轮廓是一幅图像中对象的边界或边缘,它是一组连续的点,描述了对象的形状。
**轮廓提取步骤:**
1. **图像二值化:**将图像转换为二值图像,其中对象为白色,背景为黑色。
2. **边缘检测:**使用边缘检测算法(如Canny或Sobel)检测图像中的边缘。
3. **轮廓查找:**使用轮廓查找算法(如cv2.findContours())在边缘图像中找到轮廓。
#### 2.1.2 常用的轮廓提取算法
**Canny边缘检测:**
```python
import cv2
# 读取图像
image = cv2.imread('image.jpg')
# 灰度转换
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Canny边缘检测
edges = cv2.Canny(gray, 100, 200)
# 显示边缘图像
cv2.imshow('Edges', edges)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
**Sobel边缘检测:**
```python
import cv2
# 读取图像
image = cv2.imread('image.jpg')
# 灰度转换
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Sobel边缘检测
sobelx = cv2.Sobel(gray, cv2.CV_64F, 1, 0, ksize=5)
sobely = cv2.Sobel(gray, cv2.CV_64F, 0, 1, ksize=5)
# 计算梯度幅值
gradient = cv2.addWeighted(np.abs(sobelx), 0.5, np.abs(sobely), 0.5, 0)
# 显示梯度幅值图像
cv2.imshow('Gradient', gradient)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
### 2.2 轮廓属性分析
#### 2.2.1 轮廓周长和面积
**周长:**轮廓所有点的长度之和。
**面积:**轮廓内部区域的面积。
**代码示例:**
```python
import cv2
# 读取图像并提取轮廓
image = cv2.imread('image.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(gray, 100, 200)
contours, hierarchy = cv2.findContours(edges, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 计算轮廓周长和面积
for contour in contours:
perimeter = cv2.arcLength(contour, True)
area = cv2.contourArea(contour)
print("Perimeter:", perimeter)
print("Area:", area)
```
#### 2.2.2 轮廓中心和质心
**中心:**轮廓所有点的平均值。
**质心:**轮廓所有点的加权平均值,权重为每个点的面积。
**代码示例:**
```python
import cv2
# 读取图像并提取轮廓
image = cv2.imread('image.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(gray, 100, 200)
contours, hierarchy = cv2.findContours(edges, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 计算轮廓中心和质心
for contour in contours:
moments = cv2.moments(contour)
cx = int(moments['m10'] / moments['m00'])
cy = int(moments['m01'] / moments['m00'])
print("Center:", (cx, cy))
# 计算质心
M = cv2.moments(contour)
cX = int(M["m10"] / M["m00"])
cY = int(M["m01"] / M["m00"])
print("Centroid:", (cX, cY))
```
#### 2.2.3 轮廓的凸包和凸度
**凸包:**

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0

专栏简介
该专栏深入探讨了 OpenCV 中与轮廓相关的函数,涵盖了从轮廓提取到缺陷检测的各个方面。通过一系列循序渐进的教程,它揭示了轮廓提取、匹配、表示和缺陷检测的原理和实践。专栏还介绍了 OpenCV 中用于轮廓逼近、凸包和凹包、矩、分层、形态学操作、距离变换、霍夫变换、多边形拟合、骨架提取、面积计算、周长计算、凸度计算、方向计算和惯性矩计算等各种技术。通过这些教程,读者可以深入理解图像轮廓,并掌握使用 OpenCV 进行图像分割、目标识别、形状分析和缺陷检测的实用技巧。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【ES7210-TDM级联深入剖析】:掌握技术原理与工作流程,轻松设置与故障排除

# 摘要
本文旨在系统介绍TDM级联技术,并以ES7210设备为例,详细分析其在TDM级联中的应用。文章首先概述了TDM级联技术的基本概念和ES7210设备的相关信息,进而深入探讨了TDM级联的原理、配置、工作流程以及高级管理技巧。通过深入配置与管理章节,本文提供了多项高级配置技巧和安全策略,确保级联链路的稳定性和安全性。最后,文章结合实际案例,总结了故障排除和性能优化的实用
社区与互动:快看漫画、腾讯动漫与哔哩哔哩漫画的社区建设与用户参与度深度对比
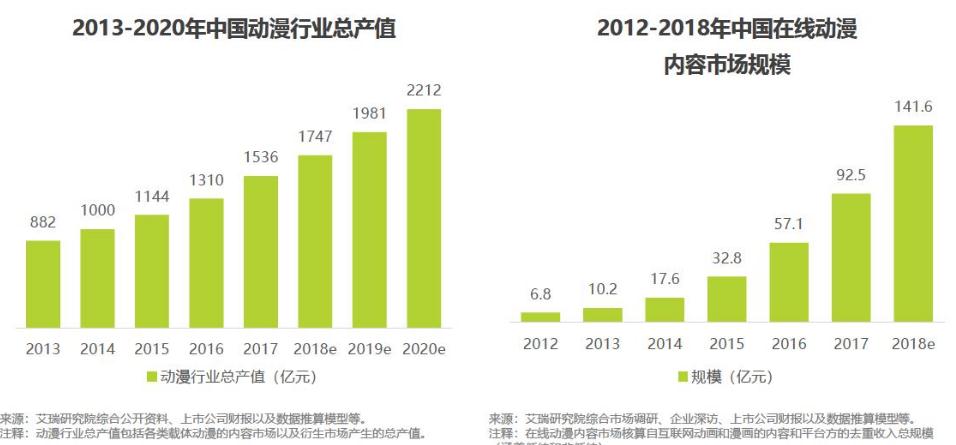
# 摘要
本文围绕现代漫画平台社区建设及其对用户参与度影响展开研究,分别对快看漫画、腾讯动漫和哔哩哔哩漫画三个平台的社区构建策略、用户互动机制以及社区文化进行了深入分析。通过评估各自社区功能设计理念、用户活跃度、社区运营实践、社区特点和社区互动文化等因素,揭示了不同平台在促进用户参与度和社区互动方面的策略与成效。此外,综合对比三平台的社区建设模式和用户参与度影响因素,本文提出了关于漫画平
平衡成本与激励:报酬要素等级点数公式在财务管理中的角色

# 摘要
本文探讨了成本与激励平衡的艺术,着重分析了报酬要素等级点数公式的理论基础及其实践应用。通过财务管理的激励理论,解析了激励模型与组织行为的关系,继而深入阐述了等级点数公式的定义、历史发展、组成要素及其数学原理。实践应用章节讨论了薪酬体系的设计与实施、薪酬结构的评估与优化,以及等级点数公式的具体案例应用。面对当前应用中出现的挑战,文章提出了未来趋势预测,并在案例研究与实证分析章节中进行了国内外企业薪酬
【R语言数据可视化进阶】:Muma包与ggplot2的高效结合秘籍
# 摘要
随着大数据时代的到来,数据可视化变得越来越重要。本文首先介绍了R语言数据可视化的理论基础,并详细阐述了Muma包的核心功能及其在数据可视化中的应用,包括数据处理和高级图表绘制。接着,本文探讨了ggplot2包的绘图机制,性能优化技巧,并分析了如何通过个性化定制来提升图形的美学效果。为了展示实际应用,本文进一步讨论了Muma与g
【云计算中的同花顺公式】:部署与管理,迈向自动化交易
# 摘要
本文全面探讨了云计算与自动化交易系统之间的关系,重点分析了同花顺公式的理论基础、部署实践、以及在自动化交易系统管理中的应用。文章首先介绍了云计算和自动化交易的基础概念,随后深入研究了同花顺公式的定义、语言特点、语法结构,并探讨了它在云端的部署优势及其性能优化。接着,本文详细描述了同花顺公式的部署过程、监控和维护策略,以及如何在自动化交易系统中构建和实现交易策略。此外,文章还分析了数据分析与决策支持、风险控制与合规性管理。在高级应用方面,
【Origin自动化操作】:一键批量导入ASCII文件数据,提高工作效率
# 摘要
本文旨在介绍Origin软件在自动化数据处理方面的应用,通过详细解析ASCII文件格式以及Origin软件的功能,阐述了自动化操作的实现步骤和高级技巧。文中首先概述了Origin的自动化操作,紧接着探讨了自动化实现的理论基础和准备工作,包括环境配置和数据集准备。第三章详细介绍了Origin的基本操作流程、脚本编写、调试和测试方法
【存储系统深度对比】:内存与硬盘技术革新,优化策略全解析

# 摘要
随着信息技术的快速发展,存储系统在现代计算机架构中扮演着至关重要的角色。本文对存储系统的关键指标进行了概述,并详细探讨了内存技术的演变及其优化策略。本文回顾了内存技术的发展历程,重点分析了内存性能的提升方法,包括架构优化、访问速度增强和虚拟内存管理。同时,本文对硬盘存储技术进行了革新与挑战的探讨,从历史演进到当前的技术突破,再到性能与耐用性的提升策略。此外,文章还对存储系统的性能进行了深
【广和通4G模块多连接管理】:AT指令在处理多会话中的应用
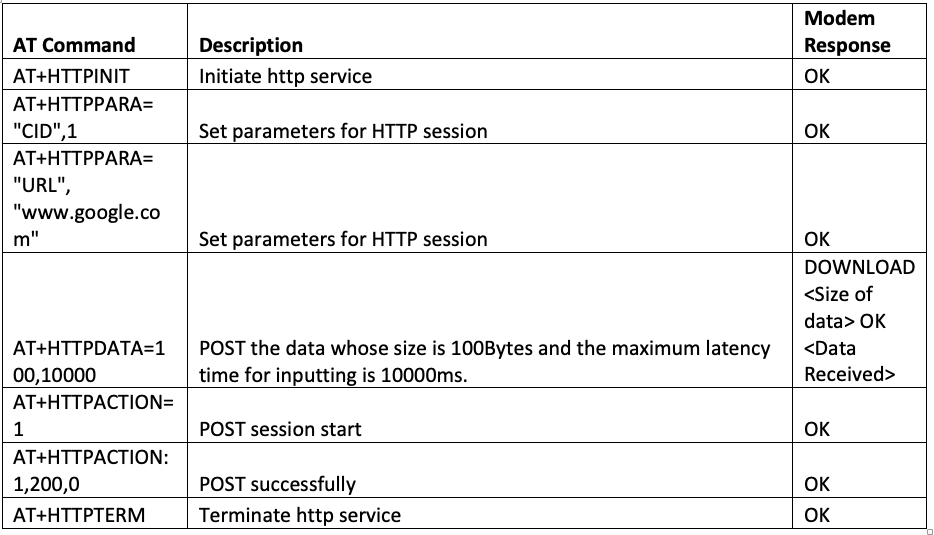
# 摘要
本文深入探讨了AT指令在广和通4G模块中的应用,以及在多连接管理环境下的性能优化。首先,介绍了AT指令的基础知识,包括基础指令的使用方法和高级指令的管理功能,并详细解析了错误诊断与调试技巧。其次,阐述了多连接管理的理论基础,以及AT指令在多连接建立和维护中的应用。接着,介绍了性能优化的基本原理,包括系统资源分配、连接效
【移动打印系统CPCL编程攻略】:打造高效稳定打印环境的20大策略

# 摘要
本文首先概述了移动打印系统CPCL的概念及其语言基础,详细介绍了CPCL的标签、元素、数据处理和打印逻辑控制等关键技术点。其次,文章深入探讨了CPCL在实践应用中的模板设计、打印任务管理以及移动设备与打印机的交互方式。此外,本文还提出了构建高效稳定打印环境的策略,包括系统优化、打印安全机制和高级打印功能的实现。最后,通过行业应用案例分析,本文总结了
AP6521固件升级中的备份与恢复:如何防止意外和数据丢失
# 摘要
本文全面探讨了固件升级过程中的数据安全问题,强调了数据备份的重要性。首先,从理论上分析了备份的定义、目的和分类,并讨论了备份策略的选择和最佳实践。接着,通过具体的固件升级场景,提出了一套详细的备份计划制定方法以及各种备份
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )