JSON数据库模型在微服务架构中的实践:提升灵活性与可扩展性
发布时间: 2024-07-28 18:49:48 阅读量: 32 订阅数: 26 
# 1. JSON数据库模型概述**
JSON(JavaScript Object Notation)数据库模型是一种非关系型数据库模型,它使用JSON格式存储和管理数据。与关系型数据库不同,JSON数据库不使用表和列,而是使用文档和集合来组织数据。文档是一组键值对,而集合是文档的集合。
JSON数据库模型的优点包括:
* **灵活的数据模型:**JSON数据库模型支持灵活的数据结构,允许数据以任何方式组织和存储。
* **轻量级和高性能:**JSON是一种轻量级的格式,可以快速解析和处理,从而提高了数据库的性能。
# 2. JSON数据库模型在微服务架构中的优势
### 2.1 灵活的数据模型
JSON数据库模型采用灵活的模式,允许数据以文档的形式存储,其中每个文档包含一组键值对。这种模式使JSON数据库能够轻松适应不断变化的数据结构,而无需修改数据库架构。在微服务架构中,服务通常是独立部署和管理的,数据模型可能会随着时间的推移而演变。JSON数据库的灵活性使微服务能够轻松适应这些变化,而无需进行繁琐的数据库迁移或架构重构。
### 2.2 轻量级和高性能
JSON数据库模型是轻量级的,这意味着它具有较低的内存和CPU开销。这使其非常适合微服务架构,其中资源通常受到限制。此外,JSON数据库通常利用NoSQL数据存储技术,这些技术针对高性能和可扩展性进行了优化。NoSQL数据库通常使用分布式架构,可以轻松扩展以处理不断增加的数据负载。
### 2.3 可扩展性和弹性
JSON数据库模型的可扩展性和弹性使其非常适合微服务架构。微服务架构通常涉及多个独立的服务,这些服务可能部署在不同的服务器或云环境中。JSON数据库可以轻松地跨多个服务器或云环境进行扩展,以满足不断增长的数据需求。此外,JSON数据库通常具有内置的复制和故障转移机制,可以确保数据的冗余和可用性,即使在发生硬件故障或网络中断的情况下。
#### 代码示例:
```python
import json
# 创建一个JSON文档
document = {
"name": "John Doe",
"age": 30,
"occupation": "Software Engineer"
}
# 将JSON文档插入数据库
db.insert(document)
# 查询数据库以获取所有文档
results = db.find({})
# 遍历查询结果
for result in results:
print(result)
```
#### 逻辑分析:
此代码示例演示了如何在JSON数据库中插入和查询文档。首先,它创建一个JSON文档,其中包含有关人员的信息。然后,它将文档插入数据库。接下来,它查询数据库以获取所有文档。最后,它遍历查询结果并打印每个文档。
#### 参数说明:
* `db`:JSON数据库的实例。
* `document`:要插入数据库的JSON文档。
* `results`:查询结果。
#### 表格:JSON数据库模型与关系数据库模型的比较
| 特性 | JSON数据库模型 | 关系数据库模型 |
|---|---|---|
| 数据模型 | 灵活,基于文档 | 严格,基于表 |
| 可扩展性 | 高可扩展性 | 可扩展性有限 |
| 性能 | 高性能 | 性能受限于表连接和索引 |
| 复杂查询 | 复杂查询可能很慢 | 复杂查询通常很有效率 |
| 数据完整性 | 数据完整性较弱 | 数据完整性较强 |
#### Mermaid格式流程图:JSON数据库模型在微服务架构中的优势
```mermaid
graph LR
subgraph JSON数据库模型
灵活的数据模型
轻量级和高性能
可扩展性和弹性
end
subgraph 微服务架构
独立部
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 JSON 数据库模型,从入门基础到精通原理,提供了全面的指南。专栏涵盖了性能优化秘籍,提升查询效率和数据存储优化。此外,还比较了 JSON 数据库模型与关系型数据库,分析了优缺点和应用场景。专栏还介绍了 JSON 数据库模型在 NoSQL 中的应用,探索了其优势和局限。在微服务架构中的实践部分,阐述了如何提升灵活性与可扩展性。专栏还提供了最佳实践大全,涵盖了从设计到部署的各个方面,确保高效运行。最后,专栏深入探讨了常见挑战与解决方案,应对数据一致性和性能问题。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
质量控制中的Rsolnp应用:流程分析与改进的策略

# 1. 质量控制的基本概念
## 1.1 质量控制的定义与重要性
质量控制(Quality Control, QC)是确保产品或服务质量
【nlminb项目应用实战】:案例研究与最佳实践分享
# 1. nlminb项目概述
## 项目背景与目的
在当今高速发展的IT行业,如何优化性能、减少资源消耗并提高系统稳定性是每个项目都需要考虑的问题。nlminb项目应运而生,旨在开发一个高效的优化工具,以解决大规模非线性优化问题。项目的核心目的包括:
- 提供一个通用的非线性优化平台,支持多种算法以适应不同的应用场景。
- 为开发者提供一个易于扩展
【R语言跨语言交互指南】:在R中融合Python等语言的强大功能

# 1. R语言简介与跨语言交互的需求
## R语言简介
R语言是一种广泛使用的开源统计编程语言,它在统计分析、数据挖掘以及图形表示等领域有着显著的应用。由于其强健的社区支持和丰富的包资源,R语言在全球数据分析和科研社区中享有盛誉。
## 跨语言交互的必要性
在数据科学领域,不
模型验证的艺术:使用R语言SolveLP包进行模型评估
# 1. 线性规划与模型验证简介
## 1.1 线性规划的定义和重要性
线性规划是一种数学方法,用于在一系列线性不等式约束条件下,找到线性目标函数的最大值或最小值。它在资源分配、生产调度、物流和投资组合优化等众多领域中发挥着关键作用。
```mermaid
flowchart LR
A[问题定义] --> B[建立目标函数]
B --> C[确定约束条件]
C --> D[
constrOptim在生物统计学中的应用:R语言中的实践案例,深入分析

# 1. constrOptim在生物统计学中的基础概念
在生物统计学领域中,优化问题无处不在,从基因数据分析到药物剂量设计,从疾病风险评估到治疗方案制定。这些问题往往需要在满足一定条件的前提下,寻找最优解。constrOptim函数作为R语言中用于解决约束优化问题的一个重要工具,它的作用和重
R语言与SQL数据库交互秘籍:数据查询与分析的高级技巧
# 1. R语言与SQL数据库交互概述
在数据分析和数据科学领域,R语言与SQL数据库的交互是获取、处理和分析数据的重要环节。R语言擅长于统计分析、图形表示和数据处理,而SQL数据库则擅长存储和快速检索大量结构化数据。本章将概览R语言与SQL数据库交互的基础知识和应用场景,为读者搭建理解后续章节的框架。
## 1.
R语言数据包安全使用指南:规避潜在风险的策略
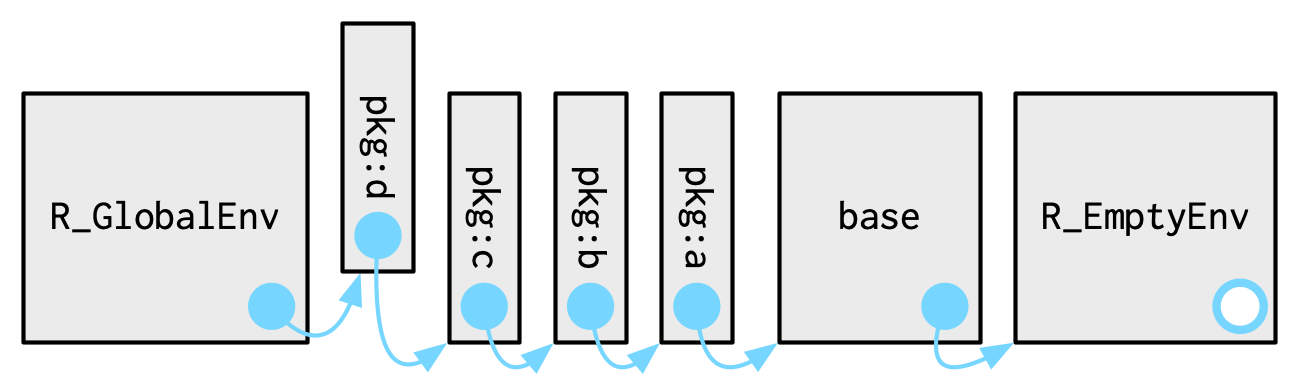
# 1. R语言数据包基础知识
在R语言的世界里,数据包是构成整个生态系统的基本单元。它们为用户提供了一系列功能强大的工具和函数,用以执行统计分析、数据可视化、机器学习等复杂任务。理解数据包的基础知识是每个数据科学家和分析师的重要起点。本章旨在简明扼要地介绍R语言数据包的核心概念和基础知识,为
动态规划的R语言实现:solnp包的实用指南
# 1. 动态规划简介
## 1.1 动态规划的历史和概念
动态规划(Dynamic Programming,简称DP)是一种数学规划方法,由美国数学家理查德·贝尔曼(Richard Bellman)于20世纪50年代初提出。它用于求解多阶段决策过程问题,将复杂问题分解为一系列简单的子问题,通过解决子问题并存储其结果来避免重复计算,从而显著提高算法效率。DP适用于具有重叠子问题和最优子
【数据挖掘应用案例】:alabama包在挖掘中的关键角色

# 1. 数据挖掘简介与alabama包概述
## 1.1 数据挖掘的定义和重要性
数据挖掘是一个从大量数据中提取或“挖掘”知识的过程。它使用统计、模式识别、机器学习和逻辑编程等技术,以发现数据中的有意义的信息和模式。在当今信息丰富的世界中,数据挖掘已成为各种业务决策的关键支撑技术。有效地挖掘数据可以帮助企业发现未知的关系,预测未来趋势,优化
R语言数据包多语言集成指南:与其他编程语言的数据交互(语言桥)

# 1. R语言数据包的基本概念与集成需求
## R语言数据包简介
R语言作为统计分析领域的佼佼者,其数据包(也称作包或库)是其强大功能的核心所在。每个数据包包含特定的函数集合、数据集、编译代码等,专门用于解决特定问题。在进行数据分析工作之前,了解如何选择合适的数据包,并集成到R的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )