探索MATLAB数据结构与算法:数据处理与算法实现的艺术
发布时间: 2024-06-09 15:31:48 阅读量: 65 订阅数: 32 

# 1. MATLAB数据结构基础**
MATLAB数据结构是存储和组织数据的基本方式。它们提供了一种高效且灵活的方法来处理各种类型的数据,从标量到复杂的多维数组。
MATLAB数据结构的基本类型包括:
- 标量:单个数值、字符或逻辑值。
- 数组:一组相同类型元素的集合,排列成行和列。
- 矩阵:一种特殊的数组,其元素排列成行和列,形成一个矩形网格。
- 单元格数组:一个数组,其中每个元素可以包含任何类型的数据,包括其他数据结构。
- 结构体:一种数据结构,它将相关数据组织成具有命名字段的记录。
# 2. MATLAB算法基础
### 2.1 数值算法
**2.1.1 数值计算和误差分析**
数值算法是MATLAB中用于执行数值计算的算法。这些算法涉及使用有限精度表示的数字,因此可能会产生误差。误差分析是数值算法中一个重要的方面,它涉及研究和量化这些误差。
**2.1.2 线性方程组求解**
线性方程组求解是数值算法中另一个重要的领域。MATLAB提供了一系列函数来求解线性方程组,包括:
- `linsolve`:使用LU分解法求解线性方程组。
- `inv`:求解方程组系数矩阵的逆矩阵,然后用逆矩阵乘以右端常数项得到解。
- `mldivide`:使用高斯消去法求解线性方程组。
```
% 求解线性方程组 A * x = b
A = [2 1; 3 4];
b = [5; 7];
% 使用 linsolve 求解
x1 = linsolve(A, b);
% 使用 inv 求解
x2 = A \ b;
% 使用 mldivide 求解
x3 = mldivide(A, b);
% 打印解
disp(x1);
disp(x2);
disp(x3);
```
**逻辑分析:**
上述代码中,`linsolve`、`inv`和`mldivide`函数都用于求解线性方程组`A * x = b`。`linsolve`使用LU分解法,`inv`使用逆矩阵法,`mldivide`使用高斯消去法。
**参数说明:**
- `linsolve(A, b)`:`A`是系数矩阵,`b`是常数项向量。
- `inv(A)`:`A`是系数矩阵。
- `mldivide(A, b)`:`A`是系数矩阵,`b`是常数项向量。
### 2.2 符号计算
**2.2.1 符号表达式和操作**
符号计算涉及使用符号(变量、函数等)而不是数字进行计算。MATLAB提供了`syms`函数来创建符号变量,并提供了各种函数来执行符号操作,包括:
- `diff`:求导数。
- `int`:求积分。
- `simplify`:化简表达式。
```
% 创建符号变量
x = sym('x');
y = sym('y');
% 求导数
dx = diff(x^2 + y^2, x);
% 求积分
int_xy = int(x*y, x);
% 化简表达式
simplified_expr = simplify((x + y)^2);
% 打印结果
disp(dx);
disp(int_xy);
disp(simplified_expr);
```
**逻辑分析:**
上述代码中,`syms`函数用于创建符号变量`x`和`y`。`diff`函数用于求导数,`int`函数用于求积分,`simplify`函数用于化简表达式。
**参数说明:**
- `syms(name)`:`name`是符号变量的名称。
- `diff(expr, var)`:`expr`是要求导的表达式,`var`是要对哪个变量求导。
- `int(expr, var)`:`expr`是要求积分的表达式,`var`是要对哪个变量求积分。
- `simplify(expr)`:`expr`是要化简的表达式。
### 2.3 优化算法
**2.3.1 优化问题的建模**
优化算法用于求解优化问题,即找到一个函数的最小值或最大值。MATLAB提供了各种函数来建模和求解优化问题,包括:
- `fminunc`:使用无约束优化算法求解无约束优化问题。
- `fmincon`:使用约束优化算法求解约束优化问题。
- `optimset`:设置优化算法的选项。
```
% 定义目标函数
objective_function = @(x) x^2 + 2*x + 1;
% 求解无约束优化问题
x_optimal = fminunc(objective_function, 0);
% 打印最优解
disp(x_optimal);
```
**逻辑分析:**
上述代码中,`fminunc`函数用于求解无约束优化问题。`objective_function`是目标函数,`0`是初始猜测值。
**参数说明:**
- `fminunc(fun, x0)`:`fun`是目标函数,`x0`是初始猜测值。
- `fmincon(fun, x0, A, b, Aeq, beq, lb, ub, nonlcon)`:`fun`是目标函数,`x0`是初始猜测值,`A`和`b`是线性不等式约束,`Aeq`和`beq`是线性等式约束,`lb`和`ub`是变量的下界和上界,`nonlcon`是非线性约束。
# 3.1 数组和矩阵
#### 3.1.1 数组和矩阵的基本操作
MATLAB 中的数组和矩阵是数据结构的基本组成部分。数组是一组相同数据类型的元素的有序集合,而矩阵是具有行和列结构的二维数组。
**数组创建和访问**
```matlab
% 创建一个包含数字的数组
array = [1, 2, 3, 4, 5];
% 创建一个包含字符的数组
char_array = ['a', 'b', 'c', 'd', 'e'];
% 访问数组中的元素
disp(array(3)); % 输出:3
disp(char_array(2)); % 输出:b
```
**矩阵创建和访问**
```matlab
% 创建一个 3x3 矩阵
matrix = [1, 2, 3; 4, 5, 6; 7, 8, 9];
% 访问矩阵中的元素
disp(matrix(2, 3)); % 输出:6
```
#### 3.1.2 数组和矩阵的处理技巧
MATLAB 提供了丰富的函数和操作符来处理数组和矩阵。
**数组和矩阵操作**
```matlab
% 数组连接
array1 = [1, 2, 3];
array2 = [4, 5, 6];
combined_array = [array1, array2]; % 输出:[1, 2, 3, 4, 5, 6]
% 矩阵加法
matrix1 = [1, 2, 3; 4, 5, 6];
matrix2 = [7, 8, 9; 10, 11, 12];
sum_matrix = matrix1 + matrix2; % 输出:[8, 10, 12; 14, 16, 18]
```
**数组和矩阵查询**
```matlab
% 查找数组中的最大值
max_value = max(array); % 输出:5
% 查找矩阵中特定元素的位置
[row, col] = find(matrix == 6); % 输出:row = 2, col = 3
```
**数组和矩阵转换**
```matlab
% 将数组转换为矩阵
matrix = reshape(array, [3, 2]); % 输出:[1, 2; 3, 4; 5, 6]
% 将矩阵转换为数组
array = matrix(:); % 输出:[1, 2, 3, 4, 5, 6]
```
# 4. MATLAB算法实现**
**4.1 排序算法**
排序算法用于将给定数据集中的元素按特定顺序排列。MATLAB提供了多种排序算法,包括:
**4.1.1 冒泡排序和选择排序**
**冒泡排序**通过比较相邻元素并交换顺序来对列表进行排序。算法从列表的开头开始,逐个元素比较,并将较大的元素交换到列表的末尾。该过程重复进行,直到列表完全排序。
```matlab
function sortedList = bubbleSort(list)
n = length(list);
for i = 1:n-1
for j = 1:n-i
if list(j) > list(j+1)
temp = list(j);
list(j) = list(j+1);
list(j+1) = temp;
end
end
end
sortedList = list;
end
```
**选择排序**通过找到列表中最小元素并将其与当前元素交换来对列表进行排序。算法从列表的开头开始,逐个元素比较,并将最小元素交换到列表的开头。该过程重复进行,直到列表完全排序。
```matlab
function sortedList = selectionSort(list)
n = length(list);
for i = 1:n-1
minIndex = i;
for j = i+1:n
if list(j) < list(minIndex)
minIndex = j;
end
end
temp = list(i);
list(i) = list(minIndex);
list(minIndex) = temp;
end
sortedList = list;
end
```
**4.1.2 快速排序和归并排序**
**快速排序**是一种分治算法,它将列表划分为较小的部分,对这些部分进行排序,然后合并它们以获得排序后的列表。算法选择一个枢纽元素,将列表划分为比枢纽元素小的元素和比枢纽元素大的元素。然后,递归地对这两个子列表应用快速排序。
```matlab
function sortedList = quickSort(list)
if length(list) <= 1
return;
end
pivot = list(1);
left = [];
right = [];
for i = 2:length(list)
if list(i) < pivot
left = [left, list(i)];
else
right = [right, list(i)];
end
end
sortedLeft = quickSort(left);
sortedRight = quickSort(right);
sortedList = [sortedLeft, pivot, sortedRight];
end
```
**归并排序**也是一种分治算法,它将列表划分为较小的部分,对这些部分进行排序,然后合并它们以获得排序后的列表。算法将列表划分为两个相等大小的子列表,递归地对这两个子列表应用归并排序,然后合并它们以获得排序后的列表。
```matlab
function sortedList = mergeSort(list)
if length(list) <= 1
return;
end
mid = floor(length(list) / 2);
left = list(1:mid);
right = list(mid+1:end);
sortedLeft = mergeSort(left);
sortedRight = mergeSort(right);
sortedList = merge(sortedLeft, sortedRight);
end
function mergedList = merge(left, right)
mergedList = [];
i = 1;
j = 1;
while i <= length(left) && j <= length(right)
if left(i) < right(j)
mergedList = [mergedList, left(i)];
i = i + 1;
else
mergedList = [mergedList, right(j)];
j = j + 1;
end
end
while i <= length(left)
mergedList = [mergedList, left(i)];
i = i + 1;
end
while j <= length(right)
mergedList = [mergedList, right(j)];
j = j + 1;
end
end
```
**4.2 搜索算法**
搜索算法用于在给定数据集或结构中查找特定元素。MATLAB提供了多种搜索算法,包括:
**4.2.1 线性搜索和二分搜索**
**线性搜索**通过逐个元素比较来搜索列表中的特定元素。算法从列表的开头开始,逐个元素比较,直到找到目标元素或到达列表的末尾。
```matlab
function index = linearSearch(list, target)
for i = 1:length(list)
if list(i) == target
index = i;
return;
end
end
index = -1;
end
```
**二分搜索**通过将列表划分为较小的部分并比较中间元素来搜索列表中的特定元素。算法从列表的开头和末尾开始,比较中间元素与目标元素。如果中间元素等于目标元素,则返回中间元素的索引。否则,算法将列表划分为比中间元素小的元素和比中间元素大的元素,并递归地对较小的部分应用二分搜索。
```matlab
function index = binarySearch(list, target)
low = 1;
high = length(list);
while low <= high
mid = floor((low + high) / 2);
if list(mid) == target
index = mid;
return;
elseif list(mid) < target
low = mid + 1;
else
high = mid - 1;
end
end
index = -1;
end
```
**4.2.2 哈希表和二叉树搜索**
**哈希表**是一种数据结构,它将键映射到值。键是用于标识值的唯一标识符。哈希表使用散列函数将键转换为哈希值,然后将键-值对存储在哈希表中的相应桶中。搜索哈希表中的元素涉及计算目标元素的哈希值并检索相应的桶。
```matlab
hashTable = containers.Map();
hashTable('key1') = 'value1';
hashTable('key2') = 'value2';
value = hashTable('key1');
```
**二叉树搜索**是一种数据结构,它将元素存储在二叉树中。二叉树中的每个节点最多有两个子节点,称为左子节点和右子节点。元素按升序存储在二叉树中,左子节点中的元素小于父节点,右子节点中的元素大于父节点。搜索二叉树中的元素涉及从根节点开始并比较目标元素与当前节点。如果目标元素小于当前节点,则算法移动到左子节点。如果目标元素大于当前节点,则算法移动到右子节点。该过程重复进行,直到找到目标元素或到达叶节点。
```matlab
class Node
constructor(value)
this.value = value;
this.left = null;
this.right = null;
end
end
class BinarySearchTree
constructor()
this.root = null;
end
insert(value)
if this.root is null
this.root = new Node(value);
return;
end
this._insert(value, this.root);
end
_insert(value, node)
if value < node.value
if node.left is null
node.left = new Node(value);
else
this._insert(value, node.left);
end
else
if node.right is null
node.right = new Node(value);
else
this._insert(value, node.right);
end
end
end
search(value)
if this.root is null
return null;
end
return this._search(value, this.root);
end
_search(value, node)
if value == node.value
return node;
elseif value < node.value
if node.left is null
return null;
else
return this._search(value, node.left);
end
else
if node.right is null
return null;
else
return this._search(value, node.right);
end
end
end
end
```
**4.3 图算法**
图是一种数据结构,它将顶点和边连接起来。顶点表示图中的元素,而边表示顶点之间的连接。图算法用于解决各种问题,例如路径查找、连通性分析和最小生成树。
**4.3.1 图的基本概念和表示**
图可以用邻接矩阵或邻接表来表示。邻接矩阵是一个二维数组,其中元素表示顶点之间的权重。邻接表是一个列表,其中每个元素
# 5. MATLAB数据结构与算法的综合应用
### 5.1 数据预处理和特征提取
**5.1.1 数据清洗和归一化**
数据预处理是机器学习中的关键步骤,它可以提高模型的性能和准确性。数据清洗涉及删除异常值、处理缺失值和转换数据以使其适合建模。归一化是将数据缩放或转换到特定范围内,以提高算法的收敛性和准确性。
**代码块 1:数据清洗和归一化**
```
% 导入数据
data = importdata('data.csv');
% 删除异常值
data(data.value > 1000, :) = [];
% 处理缺失值
data.age(isnan(data.age)) = mean(data.age);
% 归一化数据
data.value = normalize(data.value);
```
**代码逻辑分析:**
* `importdata()` 函数从 CSV 文件导入数据。
* `data(data.value > 1000, :) = []` 删除值大于 1000 的异常行。
* `data.age(isnan(data.age)) = mean(data.age)` 使用平均值填充缺失的年龄值。
* `normalize(data.value)` 将 `value` 列归一化到 [0, 1] 范围内。
**5.1.2 特征选择和降维**
特征选择和降维是减少数据维度和提高模型性能的技术。特征选择涉及选择与目标变量最相关的特征,而降维将数据投影到较低维度的空间。
**代码块 2:特征选择和降维**
```
% 特征选择
features = selectFeatures(data, 'target', 'value');
% 降维
[~, score] = pca(data(:, features));
```
**代码逻辑分析:**
* `selectFeatures()` 函数使用目标变量 `value` 选择最相关的特征。
* `pca()` 函数执行主成分分析 (PCA) 以将数据投影到较低维度的空间。
### 5.2 机器学习算法实现
**5.2.1 线性回归和逻辑回归**
线性回归和逻辑回归是用于预测连续变量和二元分类变量的监督学习算法。
**代码块 3:线性回归和逻辑回归**
```
% 线性回归
model = fitlm(data(:, features), data.value);
% 逻辑回归
model = fitglm(data(:, features), data.target, 'Distribution', 'binomial');
```
**代码逻辑分析:**
* `fitlm()` 函数拟合线性回归模型。
* `fitglm()` 函数拟合逻辑回归模型,指定二项分布。
**5.2.2 决策树和支持向量机**
决策树和支持向量机是用于分类和回归的非监督学习算法。
**代码块 4:决策树和支持向量机**
```
% 决策树
tree = fitctree(data(:, features), data.target);
% 支持向量机
model = fitcsvm(data(:, features), data.target);
```
**代码逻辑分析:**
* `fitctree()` 函数拟合决策树分类器。
* `fitcsvm()` 函数拟合支持向量机分类器。
# 6. MATLAB数据结构与算法的优化**
**6.1 性能分析和优化**
**6.1.1 代码优化技巧**
* **向量化操作:**使用向量化操作代替循环,可以显著提高代码效率。
* **避免不必要的函数调用:**函数调用会带来开销,尽量将函数调用次数最小化。
* **预分配内存:**在循环中预分配内存可以减少内存分配的开销。
* **使用 JIT 编译:**MATLAB 的 JIT 编译器可以将 MATLAB 代码编译为机器码,从而提高执行速度。
**6.1.2 并行计算和分布式计算**
* **并行计算:**MATLAB 支持并行计算,可以通过使用并行化工具箱来利用多核处理器。
* **分布式计算:**MATLAB Distributed Computing Server 允许在多台计算机上分发计算任务。
**6.2 数据结构和算法的选择**
**6.2.1 数据结构的性能比较**
| 数据结构 | 访问速度 | 插入速度 | 删除速度 |
|---|---|---|---|
| 数组 | O(1) | O(n) | O(n) |
| 链表 | O(n) | O(1) | O(1) |
| 哈希表 | O(1) | O(1) | O(1) |
| 树 | O(log n) | O(log n) | O(log n) |
**6.2.2 算法的复杂度分析**
* **时间复杂度:**算法执行所需的时间,通常表示为 O(n),其中 n 是输入数据的数量。
* **空间复杂度:**算法执行所需的内存空间,通常表示为 O(n),其中 n 是输入数据的数量。
通过分析算法的复杂度,可以选择最适合特定问题的算法。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏《MATLAB什么意思》深入探索了MATLAB编程语言的方方面面,旨在为初学者和经验丰富的用户提供全面的指南。从入门秘籍到语法精髓,专栏涵盖了MATLAB的各个方面,包括数据结构、算法、代码质量、图形绘制、数值计算、图像处理、信号处理、虚拟建模、并行计算、机器学习、深度学习、云计算、大数据分析、程序效率、调试技巧、代码重构、程序可靠性、版本差异和社区支持。通过深入浅出的讲解和丰富的示例,专栏旨在帮助读者掌握MATLAB的强大功能,并将其应用于各种领域,例如数据分析、科学计算、工程建模和机器学习。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
10分钟掌握Delft3D:界面、功能与快速上手指南
# 摘要
Delft3D是一款功能强大的综合水力学模拟软件,广泛应用于河流、河口、海洋以及水质管理等领域。本文首先介绍了Delft3D的软件概述和用户界面布局,详细阐述了其操作流程和功能模块的使用。随后,通过具体案例展示了如何快速上手实践,包括建立水动力模型、沉积物模拟以及水质模拟等。本文还讨论了Delft3D的进阶应用技巧,涉及模型设置、脚本自动化和模型校准等高级技术。最后,通过案例分析与应用拓展章节,探讨了该软件在实际项目中的应用效果,并对未来Delft3D的发展趋势进行了展望,指出其在软件技术革新和多领域应用拓展方面的潜力。
# 关键字
Delft3D;水力学模拟;界面布局;操作流程;
61850标准深度解读:IedModeler建模要点全掌握
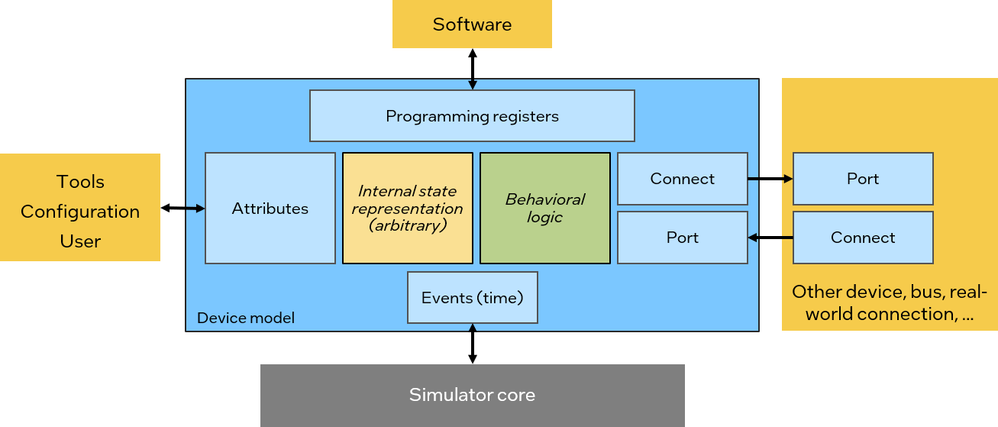
# 摘要
IEC 61850标准为电力系统的通信网络和系统间的数据交换提供了详细的规范,而IedModeler作为一款建模工具,为实现这一标准提供了强有力的支持。本文首先介绍了IEC 61850标准的核心概念和IedModeler的定位,然后深入探讨了基于IEC 61850标准的建模理论及其在IedModele
GitLab与Jenkins集成实战:构建高效自动化CI_CD流程
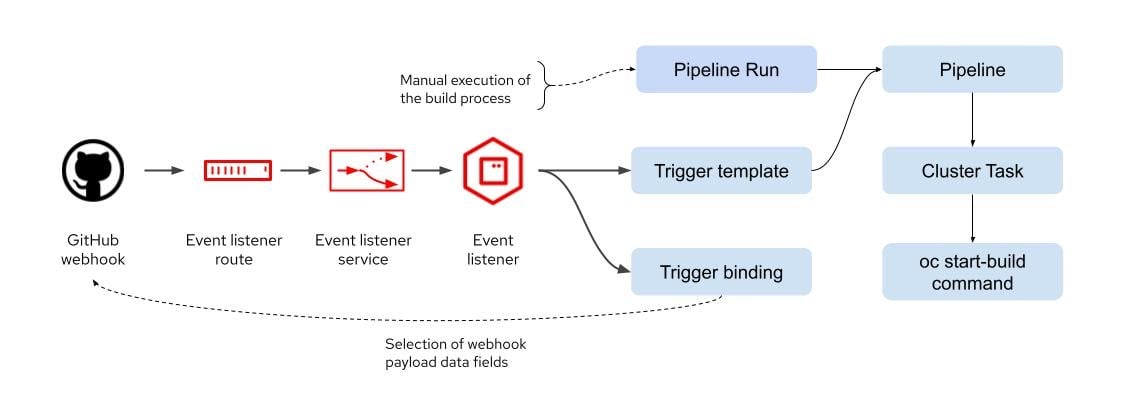
# 摘要
本文深入探讨了GitLab与Jenkins集成在自动化CI/CD流程中的应用,提供了从基础配置到高级功能实现的全面指导。首先介绍了GitLab和Jenkins的基础知识,包括它们的安装、配置以及Webhook的使用。随后,深入分析了Jenkins与GitLab的集成方式,以及如何通过构建流水线来实现代码的持续集成和
C#编程进阶:如何高效实现字符串与Unicode的双向转换

# 摘要
本文深入探讨了字符串与Unicode的基础概念,解析了Unicode编码的原理及其在内存中的表示方法,同时分析了C#编程语言中字符串和Unicode编码转换的实践案例。通过介绍编码转换过程中可能遇到的问题及其最佳实践,本文旨在提供高效字符串处理的技术方案和优化方法。文章还展望了C#字符串与Unicode转换技术的未来,讨论了当前技术的局限性、挑战和发展方向,并对开发者在这一领域的技能提升提供了建议
CAXA数据交换秘籍:XML与数据库交互技术全攻略

# 摘要
随着现代工业设计与制造信息化的快速发展,CAXA数据交换技术在提高设计效率与资源共享方面扮演着越来越重要的角色。本文首先介绍了CAXA数据交换的基础知识,并详细探讨了XML在CAXA数据交换中的应用,包括XML的定义、结构、数据交换格式的优势及与数据库的交互技术。接着,本文分析了数据库在CAXA数据交换中的关键作用,涵盖了数据库知识、与XML的交互以及安全性与性能优化。在实践应用部分,文章详细讨论了C
【24小时内掌握Java Web开发】:快速构建你的蛋糕甜品商城系统
# 摘要
本论文旨在全面介绍Java Web开发的过程和技术要点,从环境配置到高级特性的应用,再到系统测试与优化。文章首先概述了Java Web开发的基本概念,然后详细讲解了开发环境的搭建,包括JDK安装、IDE配置和Web服务器与容器的设置。接下来,文章深入探讨了Java Web的基础技术,例如Servlet的生命周期、JSP的使用和MVC设计模式。此外,本文通
【EXCEL高级函数技巧揭秘】:掌握这些技巧,让你的表格数据动起来

# 摘要
本文全面探讨了Excel中的高级函数和数据处理技巧,旨在帮助读者提升数据处理效率和准确性。文章首先对Excel高级函数进行概述,随后深入讨论核心数据处理函数,包括基于条件的数据检索、数据动态统计与分析以及错误值处理。接着,我们转向财务与日期时间函数,探讨了其在财务分析及日期时间运算中的应用。文章还介绍了数组函数与公式的高级应用和调试技巧,以及如何将Excel函数与Power Qu
大型项目中的EDID256位设计模式:架构与模块化策略专家指南
# 摘要
EDID256位设计模式是本文讨论的核心,它提供了一种创新的架构设计思路。本文首先概述了EDID256位设计模式的基本概念和架构设计的理论基础,探讨了架构设计原则、模块化架构的重要性以及如何进行架构评估与选择。接着,深入解析了模块化策略在实践中的应用,包括模块化拆分、设计、
【科学计算工具箱】:掌握现代科学计算必备工具与库,提升工作效率

# 摘要
本文详细介绍了科学计算工具箱在现代数据处理和分析中的应用。首先概述了科学计算的重要性以及常用科学计算工具和库。接着,深入探讨了Python在科学计算中的应用,包括其基础语法、科学计算环境的配置、核心科学计算库的使用实践,以及可视化技术。第三章和第四章分别介绍了数学优化方法和科学计算的高级应用,如机器学习
【PCIe虚拟化实战】:应对虚拟环境中的高性能I_O挑战
# 摘要
本文综述了PCIe虚拟化技术,涵盖了虚拟化环境下PCIe架构的关键特性、资源管理、实现方法以及性能优化和安全考量。在技术概览章节中,文章介绍了PCIe在虚拟化环境中的应用及其对资源管理的挑战。实现方法与实践章节深入探讨了硬件辅助虚拟化技术和软件虚拟化技术在PCIe中的具体应用,并提供了实战案例分析。性能优化章节着重分析了当前PCIe性能监控工具和优化技术,同时预测了未来发展的可能方向。最后,文章在安全考量章节中提出了虚拟化环境中PCIe所面临的安全威胁,并提出了相应的安全策略和管理最佳实践。整体而言,本文为PCIe虚拟化的研究和应用提供了全面的技术指南和未来展望。
# 关键字
PC
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )