CentOS7 中安装与配置Kibana数据可视化实践
发布时间: 2024-05-01 09:44:51 阅读量: 96 订阅数: 73 
# 1. Kibana 简介
Kibana 是一个开源的数据可视化工具,用于探索、分析和展示 Elasticsearch 中存储的数据。它允许用户创建交互式图表、仪表盘和地图,以帮助他们理解和利用数据。Kibana 与 Elasticsearch 紧密集成,提供了一个强大的平台,用于从日志、指标和事件数据中提取有价值的见解。
# 2. Kibana 安装与配置
### 2.1 Kibana 安装
**步骤:**
1. 确保已安装 Java 8 或更高版本。
2. 下载 Kibana RPM 包:
```
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.17.3-x86_64.rpm
```
3. 安装 Kibana:
```
sudo rpm -ivh kibana-7.17.3-x86_64.rpm
```
### 2.2 Kibana 配置
#### 2.2.1 Kibana 配置文件
Kibana 的主要配置文件位于 `/etc/kibana/kibana.yml`。以下是一些重要的配置选项:
| 配置项 | 描述 |
|---|---|
| server.host | Kibana 侦听的 IP 地址 |
| server.port | Kibana 侦听的端口 |
| elasticsearch.hosts | Elasticsearch 集群的地址 |
| kibana.index | Kibana 存储其数据的 Elasticsearch 索引 |
#### 2.2.2 Kibana 日志文件
Kibana 日志文件位于 `/var/log/kibana/kibana.log`。该日志文件包含有关 Kibana 运行状态和错误的信息。
**代码块:**
```
cat /var/log/kibana/kibana.log | grep error
```
**逻辑分析:**
此命令使用 `grep` 命令从 Kibana 日志文件中过滤出所有包含 "error" 字符串的行,显示 Kibana 运行期间发生的错误。
**参数说明:**
- `cat /var/log/kibana/kibana.log`:读取 Kibana 日志文件。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐
专栏简介
本专栏全面解析了 CentOS7 操作系统的安装和配置过程。从安装前的硬件兼容性检测到安装过程中的常见错误分析,再到磁盘分区、网络配置和常见服务启动失败原因分析,提供了详细的指南。安装后,专栏涵盖了软件更新、系统维护、防火墙配置、用户管理、网络服务优化以及各种软件和技术的安装和配置,包括 Apache、MySQL、PostgreSQL、Tomcat、Docker、Kubernetes、Jenkins、Git、Prometheus、Elasticsearch、Kibana、Kafka、Redis、SELinux、NFS、NTP 和 RAID。此外,专栏还提供了日常系统性能监控和优化方法,帮助读者充分利用 CentOS7 系统。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
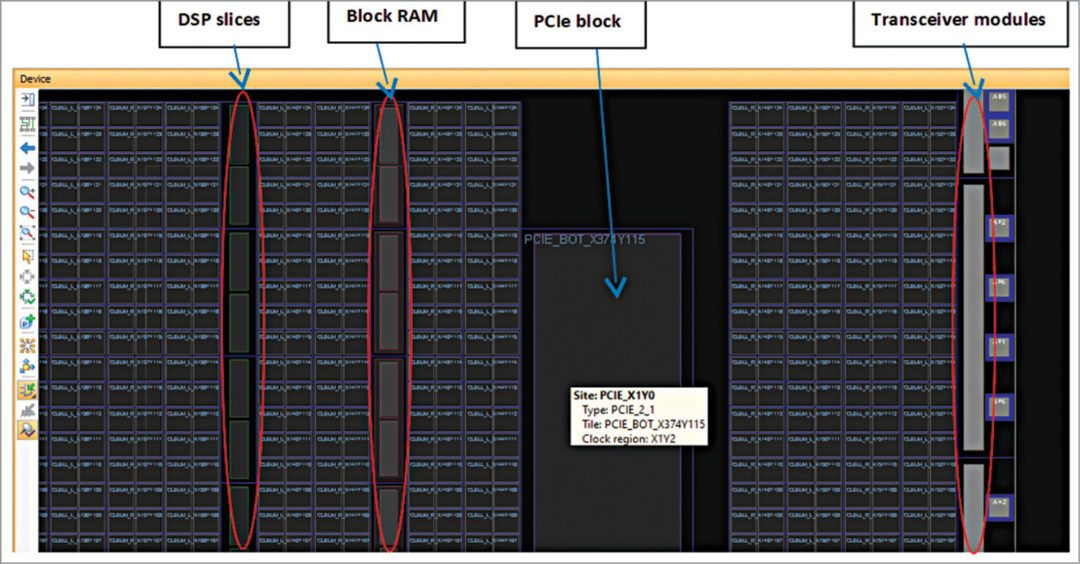
【性能优化】:提升Virtex-5 FPGA RocketIO GTP Transceiver效率的实用指南
# 摘要
本文针对Virtex-5 FPGA RocketIO GTP Transceiver的性能优化进行了全面的探讨。首先介绍了GTP Transceiver的基本概念和性能优化的基础理论,包括信号完整性、时序约束分析以及功耗与热管理。然后,重点分析了硬件设计优化实践,涵盖了原理图设计、PCB布局布线策略以及预加重与接收端均衡的调整。在固件开发方面,文章讨论了GTP初始化与配置优化、串行协议栈性能调优及专用IP核的
【LBM方柱绕流模拟中的热流问题】:理论研究与实践应用全解析

# 摘要
本文全面探讨了Lattice Boltzmann Method(LBM)在模拟方柱绕流问题中的应用,特别是在热流耦合现象的分析和处理。从理论基础和数值方法的介绍开始,深入到流场与温度场相互作用的分析,以及热边界层形成与发展的研究。通过实践应用章节,本文展示了如何选择和配置模拟软
MBIM协议版本更新追踪:最新发展动态与实施策略解析

# 摘要
随着移动通信技术的迅速发展,MBIM(Mobile Broadband Interface Model)协议在无线通信领域扮演着越来越重要的角色。本文首先概述了MBIM协议的基本概念和历史背景,随后深入解析了不同版本的更新内容,包括新增功能介绍、核心技术的演进以及技术创新点。通过案例研究,本文探讨了MB
海泰克系统故障处理快速指南:3步恢复业务连续性
# 摘要
本文详细介绍了海泰克系统的基本概念、故障影响,以及故障诊断、分析和恢复策略。首先,概述了系统的重要性和潜在故障可能带来的影响。接着,详细阐述了在系统出现故障时的监控、初步响应、故障定位和紧急应对措施。文章进一步深入探讨了系统
从零开始精通DICOM:架构、消息和对象全面解析
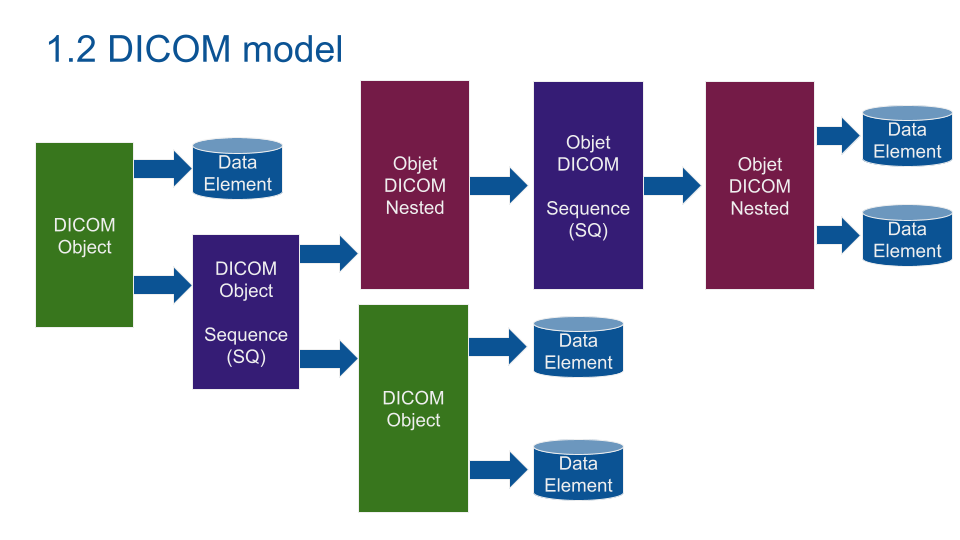
# 摘要
DICOM(数字成像和通信医学)标准是医疗影像设备和信息系统中不可或缺的一部分,本文从DICOM标准的基础知识讲起,深入分析了其架构和网络通信机制,消息交换过程以及安全性。接着,探讨了DICOM数据对象和信息模型,包括数据对象的结构、信息对象的定义以及映射资源的作用。进一步,本文分析了DICOM在医学影像处理中的应用,特别是医学影像设备的DICOM集成、医疗信息系统中的角色以及数据管理与后处理的
配置管理数据库(CMDB):最佳实践案例与深度分析

# 摘要
本文系统地探讨了配置管理数据库(CMDB)的概念、架构设计、系统实现、自动化流程管理以及高级功能优化。首先解析了CMDB的基本概念和架构,并对其数据模型、数据集成策略以及用户界面进行了详细设计说明。随后,文章深入分析了CMDB自
【DisplayPort over USB-C优势大揭秘】:为何技术专家力荐?

# 摘要
DisplayPort over USB-C作为一种新兴的显示技术,将DisplayPort视频信号通过USB-C接口传输,提供了更高带宽和多功能集成的可能性。本文首先概述了DisplayPort over USB-C技术的基础知识,包括标准的起源和发展、技术原理以及优势分析。随后,探讨了在移动设备连接、商
RAID级别深度解析:IBM x3650服务器数据保护的最佳选择

# 摘要
本文全面探讨了RAID技术的原理与应用,从基本的RAID级别概念到高级配置及数据恢复策略进行了深入分析。文中详细解释了RAID 0至RAID 6的条带化、镜像、奇偶校验等关键技术,探讨了IBM x3650服务器中RAID配置的实际操作,并分析了不同RAID级别在数据保护、性能和成本上的权衡。此外,本文还讨论了RAID技术面临的挑战,包括传统技术的局限性和新兴技术趋势,预测了RAID在硬件加速和软件定义存储领域的发展方向。通过对RAID技术的深入
【jffs2数据一致性维护】

# 摘要
本文全面探讨了jffs2文件系统及其数据一致性的理论与实践操作。首先,概述了jffs2文件系统的基本概念,并分析了数据一致性的基础理论,包括数据一致性的定义、重要性和维护机制。接着,详细描述了jffs2文件系统的结构以及一致性算法的核心组件,如检测和修复机制,以及日志结构和重放策略。在实践操作部分,文章讨论了如何配置和管理jffs2文件系统,以及检查和维护
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )