掌握IP地址高效解析和处理技巧:PHP IP数据库,助你提升代码效率
发布时间: 2024-08-02 03:33:19 阅读量: 24 订阅数: 30 

# 1. IP地址解析的基础**
IP地址解析是将IP地址转换为可读格式的过程,例如地理位置或域名。它在网络安全、网站分析和内容定制等领域至关重要。
IP地址解析通常使用IP地址数据库,其中包含IP地址范围及其对应的地理信息。这些数据库可以是二进制或文本格式,并可以通过PHP API或正则表达式解析。
解析单个IP地址相对简单,但批量解析可能需要优化,例如使用多线程或缓存机制,以提高性能和效率。
# 2. PHP IP数据库的原理与应用
### 2.1 IP地址数据库的结构和格式
#### 2.1.1 IP地址数据库的二进制格式
IP地址数据库通常采用二进制格式存储,以提高查询效率。二进制格式的IP地址数据库通常由以下部分组成:
- **头部信息:**包含数据库版本、数据格式等元数据。
- **索引表:**将IP地址范围映射到数据记录的位置。
- **数据记录:**包含每个IP地址范围的详细信息,如国家/地区、城市、邮政编码等。
#### 2.1.2 IP地址数据库的文本格式
IP地址数据库也可以采用文本格式存储,便于阅读和编辑。文本格式的IP地址数据库通常采用CSV或TXT格式,每行代表一个IP地址范围和相关信息。
### 2.2 PHP IP数据库的安装和使用
#### 2.2.1 IP地址数据库的下载和安装
常用的PHP IP地址数据库包括MaxMind GeoIP和IP2Location。这些数据库可以在供应商网站上下载。下载后,将数据库文件解压到指定目录即可。
#### 2.2.2 PHP IP数据库的API使用
PHP提供了GeoIP扩展,可以方便地使用IP地址数据库。GeoIP扩展提供了以下主要函数:
- `geoip_open()`:打开IP地址数据库文件。
- `geoip_record_by_addr()`:根据IP地址获取数据记录。
- `geoip_close()`:关闭IP地址数据库文件。
```php
<?php
// 打开IP地址数据库
$gi = geoip_open('path/to/database.dat', GEOIP_STANDARD);
// 根据IP地址获取数据记录
$record = geoip_record_by_addr($gi, '1.2.3.4');
// 输出数据记录中的国家/地区
echo $record->country_name;
// 关闭IP地址数据库
geoip_close($gi);
?>
```
# 3. IP地址解析的实践技巧
### 3.1 单个IP地址的解析
#### 3.1.1 使用PHP IP数据库解析单个IP地址
PHP IP数据库提供了 `ip2long()` 和 `long2ip()` 两个函数,用于将 IP 地址转换为长整型和将长整型转换为 IP 地址。我们可以使用这些函数来解析单个 IP 地址。
```php
<?php
$ip = '192.168.1.1';
$long = ip2long($ip);
echo long2ip($long); // 192.168.1.1
?>
```
#### 3.1.2 使用正则表达式解析单个IP地址
我们也可以使用正则表达式来解析单个 IP 地址。以下正则表达式可以匹配 IPv4 地址:
```
/^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/
```
```php
<?php
$ip = '192.168.1.1';
if (preg_match('/^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/', $ip)) {
echo 'Valid IPv4 address';
} else {
echo 'Invalid IPv4 address';
}
?>
```
### 3.2 批量IP地址的解析
#### 3.2.1 使用PHP IP数据库批量解析IP地址
PHP IP数据库提供了 `ip2long_range()` 和 `long2ip_range()` 两个函数,用于将 IP 地址范围转换为长整型范围和将长整型范围转换为 IP 地址范围。我们可以使用这些函数来批量解析 IP 地址。
```php
<?php
$ips = ['192.168.1.1', '192.168.1.2', '192.168.1.3'];
$longs = ip2long_range($ips);
echo long2ip_range($longs); // 192.168.1.1-192.168.1.3
?>
```
#### 3.2.2 使用多线程技术优化批量解析
当需要解析大量 IP 地址时,我们可以使用多线程技术来优化解析速度。以下代码使用多线程技术批量解析 IP 地址:
```php
<?php
$ips = ['192.168.1.1', '192.168.1.2', '192.168.1.3', ...];
$threads = [];
foreach ($ips as $ip) {
$thread = new Thread(function () use ($ip) {
$long = ip2long($ip);
echo long2ip($long) . PHP_EOL;
});
$threads[] = $thread;
}
foreach ($threads as $thread) {
$thread->start();
}
foreach ($threads as $thread) {
$thread->join();
}
?>
```
# 4. IP地址处理的进阶应用
### 4.1 IP地址归属地的获取
#### 4.1.1 使用PHP IP数据库获取IP地址归属地
PHP IP数据库提供了获取IP地址归属地的功能,具体步骤如下:
```php
<?php
// 加载IP地址数据库
$ipdb = new IP2Location\Database('IP2LOCATION-LITE-DB1.BIN');
// 解析单个IP地址
$ip = '1.1.1.1';
$location = $ipdb->lookup($ip);
// 输出归属地信息
echo $location->countryName . ', ' . $location->regionName . ', ' . $location->cityName;
?>
```
#### 4.1.2 使用第三方API获取IP地址归属地
除了PHP IP数据库,还可以使用第三方API来获取IP地址归属地,例如:
- **MaxMind GeoIP2 API**:提供准确的IP地址归属地信息,包括国家、州/省、城市等。
- **IPStack API**:提供丰富的IP地址信息,包括地理位置、时区、语言等。
使用第三方API的步骤通常如下:
1. 注册并获取API密钥。
2. 根据API文档编写代码。
3. 发送HTTP请求并解析响应。
### 4.2 IP地址黑名单的管理
#### 4.2.1 使用PHP IP数据库管理IP地址黑名单
PHP IP数据库提供了管理IP地址黑名单的功能,具体步骤如下:
```php
<?php
// 加载IP地址数据库
$ipdb = new IP2Location\Database('IP2LOCATION-LITE-DB1.BIN');
// 创建黑名单
$blacklist = [];
// 添加IP地址到黑名单
$ip = '1.1.1.1';
$blacklist[] = $ip;
// 从黑名单中删除IP地址
unset($blacklist[array_search($ip, $blacklist)]);
// 检查IP地址是否在黑名单中
if (in_array($ip, $blacklist)) {
// 执行操作
}
?>
```
#### 4.2.2 使用Redis或MySQL管理IP地址黑名单
除了PHP IP数据库,还可以使用Redis或MySQL等数据库来管理IP地址黑名单,具体步骤如下:
- **Redis**:使用SET命令添加IP地址,使用DEL命令删除IP地址,使用EXISTS命令检查IP地址是否存在。
- **MySQL**:创建一张包含IP地址字段的表,使用INSERT命令添加IP地址,使用DELETE命令删除IP地址,使用SELECT命令检查IP地址是否存在。
# 5. IP地址解析和处理的性能优化
**5.1 缓存机制的应用**
缓存机制是提高IP地址解析和处理性能的有效手段。通过将解析结果缓存起来,可以避免重复解析相同IP地址,从而显著提升解析效率。
**5.1.1 使用Memcached或Redis缓存解析结果**
Memcached和Redis都是流行的分布式缓存系统,可以用于缓存IP地址解析结果。它们提供了高性能、低延迟的缓存服务,非常适合于IP地址解析这种频繁读写操作的场景。
```php
// 使用Memcached缓存IP地址解析结果
$memcached = new Memcached();
$memcached->addServer('localhost', 11211);
$key = 'ip_address_127.0.0.1';
$result = $memcached->get($key);
if (!$result) {
// 解析IP地址并缓存结果
$result = resolveIpAddress('127.0.0.1');
$memcached->set($key, $result, 3600);
}
```
**5.1.2 使用本地文件缓存解析结果**
对于解析量较小的场景,也可以使用本地文件作为缓存介质。将解析结果存储在文件中,下次解析相同IP地址时直接从文件中读取,可以有效减少解析时间。
```php
// 使用本地文件缓存IP地址解析结果
$cacheFile = 'ip_address_cache.txt';
if (file_exists($cacheFile)) {
$result = file_get_contents($cacheFile);
} else {
// 解析IP地址并缓存结果
$result = resolveIpAddress('127.0.0.1');
file_put_contents($cacheFile, $result);
}
```
**5.2 多线程和异步技术的应用**
当需要批量解析大量IP地址时,多线程和异步技术可以显著提升解析效率。
**5.2.1 使用多线程技术优化批量解析**
多线程技术允许同时执行多个任务,从而充分利用多核CPU的计算能力。对于批量解析IP地址,可以将解析任务分配给多个线程,并发执行,提高解析速度。
```php
// 使用多线程技术优化批量解析
$threads = [];
$ipAddresses = ['127.0.0.1', '127.0.0.2', '127.0.0.3'];
foreach ($ipAddresses as $ipAddress) {
$thread = new Thread(function () use ($ipAddress) {
$result = resolveIpAddress($ipAddress);
// 处理解析结果
});
$threads[] = $thread;
}
foreach ($threads as $thread) {
$thread->start();
}
foreach ($threads as $thread) {
$thread->join();
}
```
**5.2.2 使用异步技术优化批量解析**
异步技术允许在不阻塞当前线程的情况下执行任务。对于批量解析IP地址,可以使用异步技术将解析任务提交到异步队列,由队列异步执行解析任务。
```php
// 使用异步技术优化批量解析
$eventLoop = React\EventLoop\Factory::create();
$ipAddresses = ['127.0.0.1', '127.0.0.2', '127.0.0.3'];
foreach ($ipAddresses as $ipAddress) {
$eventLoop->addTimer(0, function () use ($ipAddress) {
$result = resolveIpAddress($ipAddress);
// 处理解析结果
});
}
$eventLoop->run();
```
# 6. IP地址解析和处理的最佳实践
### 6.1 IP地址数据库的选择
#### 6.1.1 不同IP地址数据库的比较
| 数据库 | 特点 | 优点 | 缺点 |
|---|---|---|---|
| MaxMind GeoIP | 商业数据库,提供准确的地理位置信息 | 高精度,广泛使用 | 收费 |
| GeoLite2 | MaxMind提供的免费数据库,提供基本地理位置信息 | 免费,易于使用 | 精度较低 |
| IP2Location | 商业数据库,提供详细的地理位置信息,包括邮政编码 | 详细的信息,支持多种语言 | 收费 |
| DB-IP | 免费数据库,提供基本的地理位置信息 | 免费,体积小 | 精度较低,更新频率较低 |
#### 6.1.2 根据需求选择合适的IP地址数据库
选择IP地址数据库时,需要考虑以下因素:
- **精度要求:**如果需要高精度的地理位置信息,则需要选择MaxMind GeoIP或IP2Location等商业数据库。
- **功能需求:**如果需要详细的地理位置信息,如邮政编码,则需要选择IP2Location等支持此功能的数据库。
- **成本:**如果预算有限,则可以考虑使用GeoLite2等免费数据库。
- **更新频率:**如果需要最新的地理位置信息,则需要选择更新频率较高的数据库。
### 6.2 IP地址解析和处理的安全性
#### 6.2.1 防止IP地址欺骗
IP地址欺骗是指攻击者伪造其IP地址,以冒充其他设备或用户。为了防止IP地址欺骗,可以采取以下措施:
- **使用IP地址黑名单:**将已知的欺骗IP地址添加到黑名单中,并阻止其访问系统。
- **验证IP地址的真实性:**使用正则表达式或其他方法验证IP地址的格式是否正确。
- **使用SSL/TLS加密:**使用SSL/TLS加密通信,防止攻击者截获和修改IP地址。
#### 6.2.2 避免IP地址泄露
IP地址泄露可能导致隐私问题和安全风险。为了避免IP地址泄露,可以采取以下措施:
- **使用VPN或代理:**使用VPN或代理可以隐藏真实的IP地址。
- **禁用WebRTC:**WebRTC是一种Web技术,允许浏览器直接进行点对点通信。禁用WebRTC可以防止泄露IP地址。
- **使用匿名浏览器:**使用Tor或DuckDuckGo等匿名浏览器可以隐藏IP地址。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
PHP IP数据库专栏提供从入门到精通的IP地址查询技术指南。它揭秘了IP地址背后的秘密,并提供了高效解析和处理技巧。专栏深入探索了IP地址查询原理和实践,涵盖了从基础到高级的技术。它还提供了优化查询性能的秘诀,以及解决常见问题的解决方案。此外,专栏还介绍了构建自己的IP地址数据库的方法,以及IP地址查询在网络安全、数据分析、电子商务、社交媒体、移动应用、云计算、物联网、人工智能、区块链和元宇宙中的应用。通过遵循专栏中的最佳实践和避免常见误区,开发人员可以轻松驾驭IP地址查询技术,提升代码效率,并为用户提供更好的体验。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【笔记本性能飙升】:DDR4 SODIMM vs DDR4 DIMM,内存选择不再迷茫
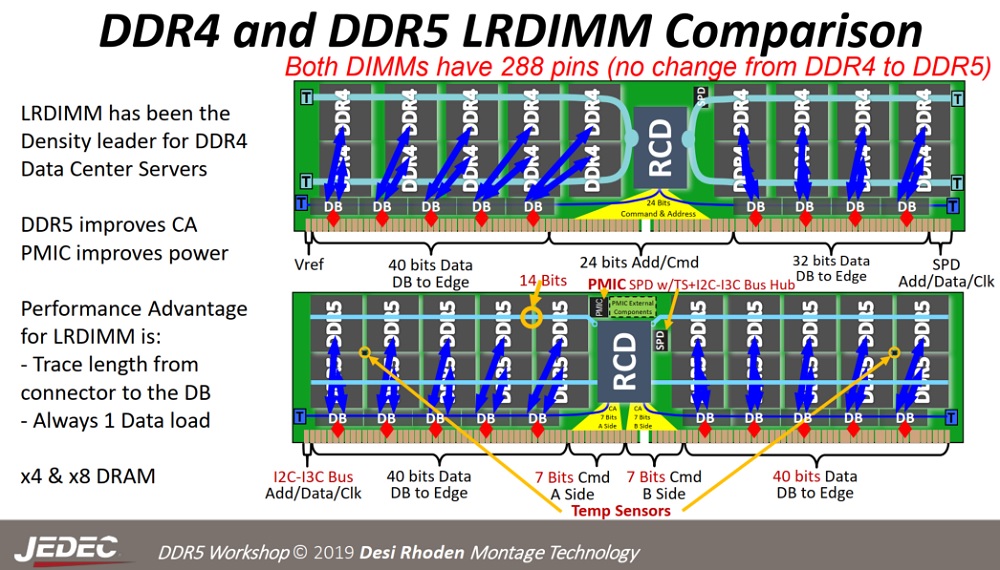
参考资源链接:[DDR4_SODIMM_SPEC.pdf](https://wenku.csdn.net/doc/6412b732be7fbd1778d496f2?spm=1055.2635.3001.10343)
# 1. 内存技术的演进与DDR4标准
## 1.1 内存技术的历史回顾
内存技术经历了从最
【防止过拟合】机器学习中的正则化技术:专家级策略揭露

参考资源链接:[《机器学习(周志华)》学习笔记.pdf](https://wenku.csdn.net/doc/6412b753be7fbd1778d49
【高级电路故障排除】:PIN_delay设置错误的诊断与修复,恢复系统稳定性
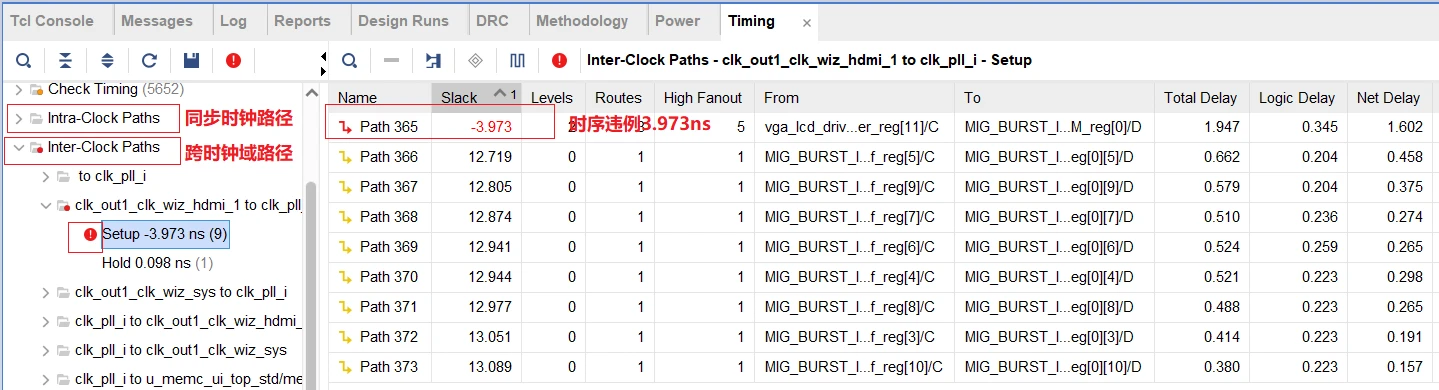
参考资源链接:[Allegro添加PIN_delay至高速信号的详细教程](https://wenku.csdn.net/doc/6412b6c8be7fbd1778d47f6b?spm=1055.2635.3001.10343)
# 1. PIN_delay设置的重要性与影响
在当今的IT和电子工程领域,PIN_delay参数的设置对于确保系统稳定性和
【GX Works3版本控制】:如何管理PLC程序的版本更新,避免混乱

参考资源链接:[三菱GX Works3编程手册:安全操作与应用指南](https://wenku.csdn.net/doc/645da0e195996c03ac442695?spm=1055.2635.3001.10343)
# 1. GX Works3版本控制概论
在PLC(可编程逻辑控制器)编程中,随着项目规模的增长和团队协作的复杂化,版本控制已经成为了一个不可或缺的工具。GX Wo
【GNSS高程数据处理坐标系统宝典】:选择与转换的专家指南

参考资源链接:[GnssLevelHight:高精度高程拟合工具](https://wenku.csdn.net/doc/6412b6bdbe7fbd1778d47cee?spm=1055.2635.3001.10343)
# 1. GNSS高程数据处理基础
在本章中,我们将探讨全球导航卫星系统(GNSS)高程数据处理的
【跨平台GBFF文件解析】:兼容性问题的终极解决方案

参考资源链接:[解读GBFF:GenBank数据的核心指南](https://wenku.csdn.net/doc/3cym1yyhqv?spm=1055.2635.3001.10343)
# 1. 跨平台文件解析的挑战与GBFF格式
跨平台应用在现代社会已经成为一种常态,这不仅仅表现在不同操作系统之间的兼容,还包括不同硬件平台以及网络环境。在文件解析这一层面,
STEP7 GSD文件安装:兼容性分析,确保不同操作系统下的正确安装
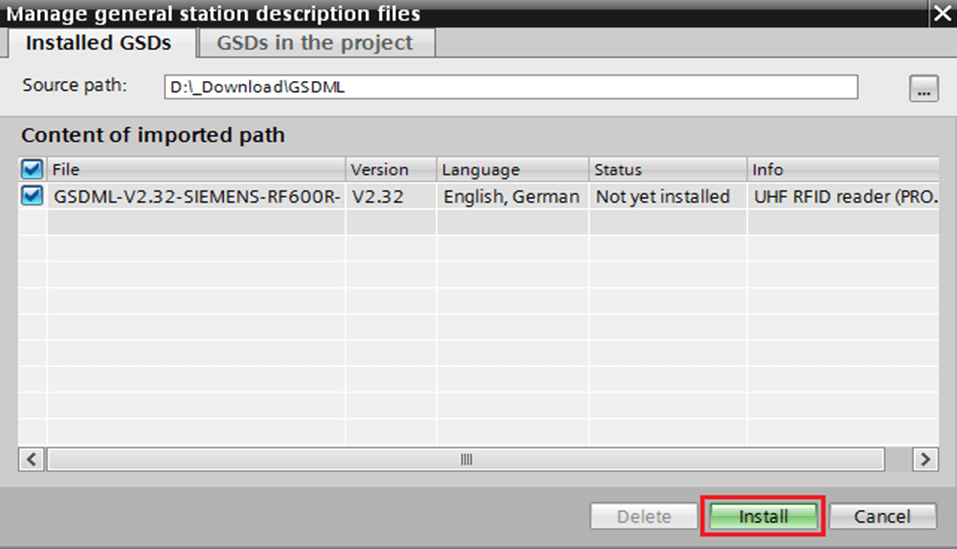
参考资源链接:[解决STEP7中GSD安装失败问题:解除引用后重装](https://wenku.csdn.net/doc/6412b5fdbe7fbd1778d451c0?spm=1055.2635.3001.10343)
# 1. STEP7 GSD文件简介
在自动化和工业控制系统领域,STEP7(也称为TIA Portal)是西门子广泛
【自定义宏故障处理】:发那科机器人灵活性与稳定性并存之道
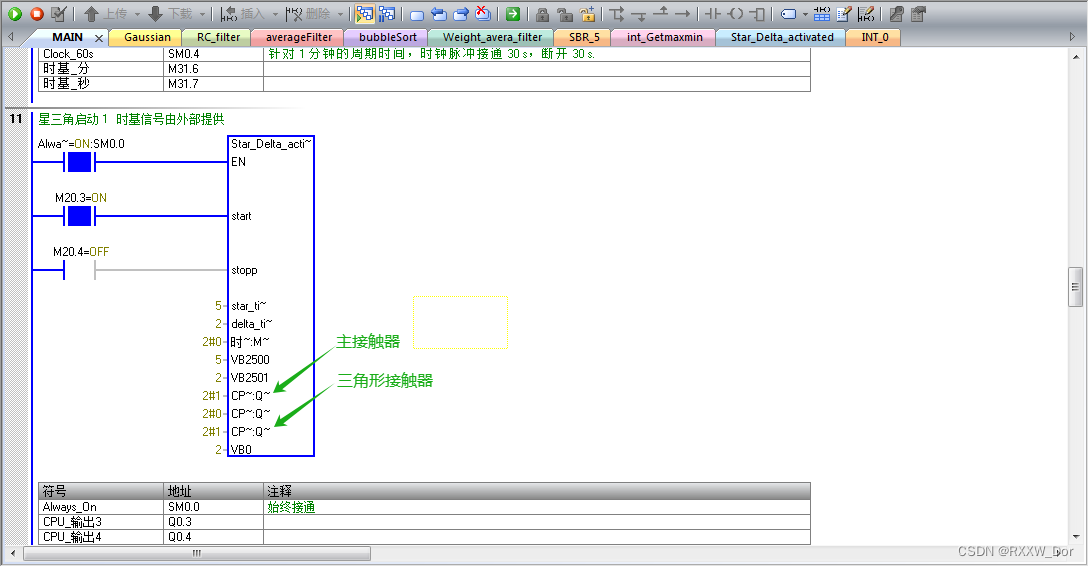
参考资源链接:[发那科机器人SRVO-037(IMSTP)与PROF-017(从机断开)故障处理办法.docx](https://wenku.csdn.net/doc/6412b7a1be7fbd1778d4afd1?spm=1055.2635.3001.10343)
# 1. 发那科机器人自定义宏概述
自定义宏是发那科机器人编程中的一个强大工具,它允许用户通过参数化编程来简化重复性任务和复杂逻辑
台达PLC编程常见错误剖析:新手到专家的防错指南
参考资源链接:[台达PLC ST编程语言详解:从入门到精通](https://wenku.csdn.net/doc/6401ad1acce7214c316ee4d4?spm=1055.2635.3001.10343)
# 1. 台达PLC编程简介
台达PLC(Programmable Logic Controller)
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )