Kubernetes中的故障排除和故障恢复
发布时间: 2024-01-18 17:27:36 阅读量: 59 订阅数: 23 

netshoot:Docker + Kubernetes网络对瑞士军队容器进行故障排除
# 1. 介绍
## 1.1 什么是Kubernetes
Kubernetes是一个开源的容器管理平台,用于自动化部署、扩展和管理容器化应用程序的工具。它提供了一个可靠的、弹性的、高效的方式来管理容器,从而简化了应用程序的部署、监控和扩展。
Kubernetes提供了一个集中的控制平面,可以管理和编排容器化应用程序,同时也提供了一组API和工具来管理容器集群。它通过使用容器的轻量级和可移植性,使得应用程序可以在不同的主机上运行,无需关注底层基础设施。
Kubernetes还具有高可用性、自动化部署和弹性伸缩等特性,可以帮助用户更好地管理和调度容器化应用程序。它提供了强大的故障排查和故障恢复机制,可以自动检测和处理容器故障,从而保证应用程序的稳定性和可靠性。
## 1.2 故障排除和故障恢复的重要性
在使用Kubernetes管理容器化应用程序时,故障排除和故障恢复是非常重要的。由于容器化应用程序可能运行在不同的主机上,不同的容器可能会有不同的故障问题。
故障排除是指在容器化应用程序出现故障时,通过识别和定位问题的根本原因,来解决和修复故障。故障恢复是指在故障排除完成后,将应用程序恢复到正常运行状态的过程。
故障排除和故障恢复的重要性体现在以下几个方面:
1. 提高应用程序的稳定性和可靠性:通过及时排查和修复故障,可以减少应用程序的宕机时间,提高用户体验。
2. 保证系统的高可用性:通过故障排除和故障恢复机制,可以保证系统在面对故障时能够自动切换和恢复,确保应用程序的高可用性。
3. 提高运维效率:通过故障排除和故障恢复的自动化机制,可以减少人工干预的时间和工作量,提高运维效率。
因此,对于使用Kubernetes管理容器化应用程序的用户来说,掌握故障排除和故障恢复的技巧和工具是非常重要的。在接下来的章节中,我们将介绍一些Kubernetes故障排除的常用技术和工具,帮助用户更好地解决和恢复故障。
# 2. Kubernetes故障排除
Kubernetes是一个强大的容器编排平台,但在使用过程中难免会遇到各种故障。故障排除是保证Kubernetes集群稳定运行的关键之一,它可以帮助我们发现问题并及时解决,保证应用程序的可用性和性能。本章节将介绍Kubernetes故障排除的一些常见方法和工具。
### 2.1 监控和日志记录
在进行故障排除之前,我们首先需要具备监控和日志记录的能力。监控可以帮助我们实时监视集群和应用程序的状态,及时发现异常情况。日志记录则可以帮助我们记录和分析系统中发生的事件和错误信息。Kubernetes提供了一些内置的监控和日志记录机制,同时也可以结合第三方工具来进行监控和日志记录。
在Kubernetes中,我们可以使用Prometheus进行集群的监控,Prometheus可以采集各个组件的指标,并进行展示和告警。另外,我们还可以使用Grafana进行图形化展示和可视化。
对于日志记录,Kubernetes提供了一些内置的日志记录机制,比如kube-apiserver、kube-controller-manager和kubelet日志。我们可以使用kubectl命令行工具来查看这些日志。另外,我们还可以使用第三方工具,比如ELK(Elasticsearch、Logstash、Kibana)来进行日志记录和分析。
### 2.2 异常检测和诊断
当我们发现集群或应用程序出现异常情况时,我们需要进行异常检测和诊断。异常检测可以帮助我们发现异常的指标或事件,而诊断则可以帮助我们确定异常发生的原因。在Kubernetes中,我们可以使用Prometheus的查询语言PromQL进行异常检测和诊断。
常见的异常检测方法包括设置阈值告警、设置异常指标的监控、设置异常事件的监控等。通过监控和分析这些异常情况,我们可以快速定位问题所在,并采取相应的措施进行修复。
### 2.3 故障根因分析
故障根因分析是故障排除的最关键环节之一,它可以帮助我们找到故障的根本原因。在Kubernetes中,故障的根因一般包括网络问题、资源耗尽、存储问题、节点故障等。
对于网络问题,我们可以通过检查网络配置、网络拓扑以及网络连接状态来进行分析。对于资源耗尽,我们可以通过检查集群的资源使用情况,比如CPU、内存、存储等来进行分析。对于存储问题,我们可以检查存储卷和存储类的状态,以及检查存储服务的运行状态。
对于节点故障,我们可以通过检查节点的健康状态、节点上运行的Pod的状态等来进行分析。同时,我们还可以根据事件日志和错误日志来追踪问题,找出故障的根本原因。
需要注意的是,在进行故障根因分析时,我们需要结合监控数据、日志记录、异常检测和诊断等多种信息源进行综合分析。
# 3. 常见的Kubernetes故障
Kubernetes作为容器编排和管理系统,在使用过程中可能会遇到各种故障问题。了解并识别常见的Kubernetes故障对于保障应用的稳定运行十分重要。本章将介绍几种常见的Kubernetes故障情况以及相应的解决方法。
#### 3.1 无法启动或停止Pod
在实际使用Kubernetes过程中,可能会遇到Pod无法启动或停止的情况。这可能是由于镜像拉取问题、调度失败、资源限制等多种原因导致的。针对这种情况,可以通过以下方法进行故障排除和解决:
示例代码(kubectl命令行):
```shell
# 查看Pod状态
kubectl get pod <pod-name> -n <namespace>
# 查看Pod日志
kubectl logs <pod-name> -n <namespace>
# 查看Pod描述
kubectl describe pod <pod-name> -n <namespace>
# 查看事件记录
kubectl get events -n <namespace>
```
**故障排除总结:**
- 如果Pod处于Pending状态,可能是资源不足导致的,需要检查节点资源情况。
- 如果Pod处于CrashLoopBackOff状态,可能是应用程序内部出现了错误,需要查看日志进行排查。
#### 3.2 资源耗尽
Kubernetes集群中的资源包括CPU、内存、存储等,当这些资源耗尽时会导致应用程序无法正常运行。针对资源耗尽问题,需要进行监控和合理的资源分配管理,同时及时进行故障排除。
示例代码(Prometheus查询语句):
```yaml
# 查询CPU使用率
kube_pod_container_resource_requests_cpu_cores
# 查询内存使用情况
kube_pod_container_resource_requests_memory_bytes
```
**故障排除总结:**
- 利用Prometheus等监控工具对集群资源进行监控,发现资源高占用情况。
- 通过水平扩展等方式,调整资源分配以解决资源耗尽问题。
#### 3.3 网络问题
Kubernetes集群中的网络问题可能导致Pod之间无法通信、外部访问受阻等情况。解决网络问题需要对网络配置、服务发现等方面进行全面排查。
示例代码(kubectl网络诊断工具):
```shell
# 查看网络配置
kubectl get svc
# 运行网络测试工具
kubectl exec -ti <test-pod-name> -n <namespace> -- curl <url>
```
**故障排除总结:**
- 检查网络配置、Service、Ingress等资源的状态和配置情况。
- 使用curl等工具测试Pod之间的网络通信情况,帮助定位网络问题。
#### 3.4 存储问题
Kubernetes中存储问题可能导致数据丢失、应用程序无法读写数据等情况。针对存储问题,需要对持久卷、存储类、PV/PVC等进行排查和故障恢复。
示例代码(kubectl存储命令):
```shell
# 查看PV/PVC状态
kubectl get pv,pvc -n <namespace>
# 查看存储类
kubectl get storageclass
```
**故障排除总结:**
- 通过PV/PVC的状态,排查存储卷挂载、访问权限等情况。
- 检查存储后端系统,如NFS、Ceph等,确保存储服务正常运行。
#### 3.5 节点故障
Kubernetes集群中节点故障可能导致Pod调度失败、应用程序无法正常运行等问题。及时发现和应对节点故障对于保障集群的稳定运行至关重要。
示例代码(kubectl节点故障排查):
```shell
# 查看节点状态
kubectl get nodes
# 查看节点事件记录
kubectl describe node <node-name>
# 在节点上进行故障诊断
kubectl describe pod -n <namespace>
```
**故障排除总结:**
- 及时发现节点故障,并进行故障恢复和替换操作。
- 通过节点事件记录和Pod描述排查故障原因。
以上是对常见的Kubernetes故障情况及解决方法的介绍,对于保障Kubernetes集群的稳定运行十分重要。通过监控、日志记录和故障排除,可以有效应对各种故障情况,并保证应用程序的可靠性。
# 4. 故障排除工具和技术
在Kubernetes故障排除过程中,有许多工具和技术可以帮助管理员更轻松地发现和解决问题。下面将介绍一些常用的故障排除工具和技术。
#### 4.1 kubectl命令行工具
kubectl是Kubernetes的命令行工具,可以用于与Kubernetes集群进行交互。通过kubectl命令,管理员可以查看集群状态、创建/删除资源对象、查看日志、执行命令等。以下是一些常用的kubectl命令示例:
```bash
# 查看集群节点状态
kubectl get nodes
# 查看特定Pod的日志
kubectl logs <pod-name>
# 执行命令在特定Pod中
kubectl exec -it <pod-name> -- /bin/sh
```
#### 4.2 Kubernetes Dashboard
Kubernetes Dashboard是一个Web用户界面,可以用来查看集群的各种信息、管理资源、查看日志等。通过Dashboard,管理员可以方便地监控集群状态和进行故障排除。以下是Dashboard的一些功能特点:
- 查看各种资源对象的状态
- 查看Pod日志
- 创建/删除资源对象
#### 4.3 Prometheus和Grafana
Prometheus是一个开源的监控和警报工具,而Grafana是一个数据可视化工具。结合使用Prometheus和Grafana可以实现对Kubernetes集群的全面监控和性能分析,并且可以通过警报功能及时发现和解决故障问题。以下是一些Prometheus和Grafana的应用场景:
- 监控CPU、内存、网络等资源的使用情况
- 基于指标设置警报规则
- 创建各种仪表盘进行数据可视化
#### 4.4 日志管理工具
Kubernetes集群中的日志是故障排除过程中重要的信息来源。因此,使用日志管理工具可以帮助管理员更好地分析和理解集群中的问题。常见的日志管理工具包括ELK Stack(Elasticsearch、Logstash、Kibana)、Fluentd等。这些工具可以收集、存储和展示集群中的日志信息,为故障排除提供支持。
通过以上工具和技术,管理员可以更加高效地进行Kubernetes集群的故障排除和问题解决。
# 5. 故障恢复的最佳实践
Kubernetes的故障排除是维护稳定和可靠的集群环境的关键部分,但故障恢复同样重要。本章将介绍一些故障恢复的最佳实践,包括备份和恢复策略、自动扩展和弹性计算、健康检查和自动故障转移,以及灾难恢复。
#### 5.1 备份和恢复策略
在面对Kubernetes集群故障时,备份和恢复策略是非常关键的。你可以利用Kubernetes自身的资源对象(如Deployment、StatefulSet等)以及持久卷(Persistent Volumes)来进行备份。另外,工具如Velero(以前称为Heptio Ark)提供了针对Kubernetes集群的备份和恢复功能,可以帮助你更好地应对各种故障情况。
#### 5.2 自动扩展和弹性计算
Kubernetes提供了水平自动扩展(Horizontal Pod Autoscaler)的功能,可以根据CPU利用率或自定义指标来自动扩展Pod数量。此外,还可以结合Kubernetes的调度器和亲和性/反亲和性设置,实现对不同节点资源的合理调度,从而提高集群的弹性和容错能力。
#### 5.3 健康检查和自动故障转移
通过在Deployment或Pod的配置中添加健康检查(Liveness Probe)和就绪检查(Readiness Probe),可以及时发现Pod的健康状态,并在出现故障时进行自动故障转移,保证服务的可用性。Kubernetes的控制器会监控这些检查状态,并根据设定的条件自动进行Pod的重启或替换。
#### 5.4 灾难恢复
灾难恢复(Disaster Recovery)是应对严重故障或灾难事件的关键策略,而Kubernetes Operator框架提供了一种自定义控制器的机制,可以用来编写和部署灾难恢复方案。另外,合理设计多集群架构、跨区域部署和数据复制策略,也是确保灾难恢复的重要手段。
### 结语
合理的故障恢复策略是Kubernetes集群稳定和高可用的关键所在。通过备份和恢复策略、自动扩展和弹性计算、健康检查和自动故障转移,以及灾难恢复等最佳实践,可以有效提高集群的故障容忍能力,保障业务的持续性和稳定性。
# 6.1 常见故障案例分析
在实际的Kubernetes集群运维中,常见的故障案例包括但不限于:
- Pod 异常退出或无法启动
- 节点资源耗尽导致服务不可用
- 网络配置错误导致跨集群通信问题
- 存储卷挂载失败引起数据丢失
针对这些故障案例,我们将结合实际案例,分析导致故障的原因,并提出相应的解决方法和预防措施。
### 6.2 故障排除的最佳实践
在进行Kubernetes故障排除时,我们应该遵循一些最佳实践,包括但不限于:
- 及时收集并分析集群监控数据
- 使用适当的故障排除工具和技术进行定位
- 对故障进行分类和优先级划分
- 实施故障排除前后的验证和测试
这些最佳实践可以帮助我们高效地定位并解决Kubernetes集群中的故障问题。
### 6.3 实用建议和经验分享
除了故障排除的理论知识外,我们还将分享一些实际的经验和建议,包括但不限于:
- 如何构建高可用的Kubernetes集群架构
- 如何设计有效的监控和日志记录机制
- 如何制定灾难恢复和备份策略
这些实用建议和经验分享将有助于读者更好地理解和应用Kubernetes故障排除的知识。
以上是第六章的部分内容,涵盖了常见故障案例分析、故障排除的最佳实践以及实用建议和经验分享。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏为您详细介绍Kubernetes(简称k8s)中的各种存储卷,涵盖了常见的存储卷类型及其特性。从存储卷的概述开始,逐一介绍了空白存储卷、主机路径存储卷、空目录存储卷、本地存储卷、网络存储卷、分布式存储卷、动态存储卷等。同时,还深入探讨了PersistentVolume和PersistentVolumeClaim的概念及其生命周期,存储类、卷模式、CSI存储插件、数据持久化策略、数据备份和恢复、存储性能调优以及故障排除和故障恢复等重要主题。此外,还呈现了扩展性和容量规划以及存储安全性在Kubernetes中的应用。通过本专栏的学习,读者将全面了解Kubernetes中的存储卷及其相关概念,掌握灵活、高效、安全的存储解决方案。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深入浅出Java天气预报应用开发:零基础到项目框架搭建全攻略

# 摘要
Java作为一种流行的编程语言,在开发天气预报应用方面显示出强大的功能和灵活性。本文首先介绍了Java天气预报应用开发的基本概念和技术背景,随后深入探讨了Java基础语法和面向对象编程的核心理念,这些为实现天气预报应用提供了坚实的基础。接着,文章转向Java Web技术的应用,包括Servlet与JSP技术基础、前端技术集成和数据库交互技术。在
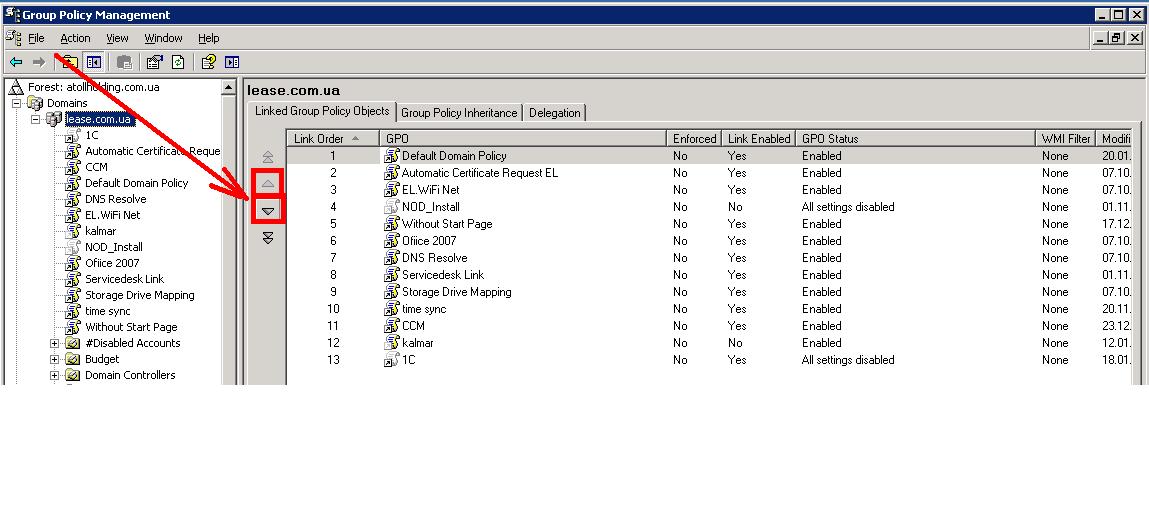
【GPO高级管理技巧】:提升域控制器策略的灵活性与效率
# 摘要
本论文全面介绍了组策略对象(GPO)的基本概念、策略设置、高级管理技巧、案例分析以及安全策略和自动化管理。GPO作为一种在Windows域环境中管理和应用策略的强大工具,广泛应用于用户配置、计算机配置、安全策略细化与管理、软件安装与维护。本文详细讲解了策略对象的链接与继承、WMI过滤器的使用以及GPO的版本控制与回滚策略,同时探讨了跨域策略同步、脚本增强策略灵活性以及故障排除与
高级CMOS电路设计:传输门创新应用的10个案例分析

# 摘要
本文全面介绍了CMOS电路设计基础,特别强调了传输门的结构、特性和在CMOS电路中的工作原理。文章深入探讨了传输门在高速数据传输、模拟开关应用、低功耗设计及特殊功能电路中的创新应用案例,以及设计优化面临的挑战,包括噪声抑制、热效应管理,以及传输门的可靠性分析。此外,本文展望了未来CMOS技术与传输门相结合的趋势,讨论了新型
计算机组成原理:指令集架构的演变与影响

# 摘要
本文综合论述了计算机组成原理及其与指令集架构的紧密关联。首先,介绍了指令集架构的基本概念、设计原则与分类,详细探讨了CISC、RISC架构特点及其在微架构和流水线技术方面的应用。接着,回顾了指令集架构的演变历程,比较了X86到X64的演进、RISC架构(如ARM、MIPS和PowerPC)的发展,以及SIMD指令集(例如AVX和NEON)的应用实例。文章进一步分析了指令集
KEPServerEX秘籍全集:掌握服务器配置与高级设置(最新版2018特性深度解析)
# 摘要
KEPServerEX作为一种广泛使用的工业通信服务器软件,为不同工业设备和应用程序之间的数据交换提供了强大的支持。本文从基础概述入手,详细介绍了KEPServerEX的安装流程和核心特性,包括实时数据采集与同步,以及对通讯协议和设备驱动的支持。接着,文章深入探讨了服务器的基本配置,安全性和性能优化的高级设
TSPL2批量打印与序列化大师课:自动化与效率的完美结合

# 摘要
TSPL2是一种广泛应用于打印和序列化领域的技术。本文从基础入门开始,详细探讨了TSPL2的批量打印技术、序列化技术以及自动化与效率提升技巧。通过分析TSPL2批量打印的原理与优势、打印命令与参数设置、脚本构建与调试等关键环节,本文旨在为读者提供深入理解和应用TSPL2技术的指
【3-8译码器构建秘籍】:零基础打造高效译码器

# 摘要
3-8译码器是一种广泛应用于数字逻辑电路中的电子组件,其功能是从三位二进制输入中解码出八种可能的输出状态。本文首先概述了3-8译码器的基本概念及其工作原理,并
EVCC协议源代码深度解析:Gridwiz代码优化与技巧

# 摘要
本文全面介绍了EVCC协议和Gridwiz代码的基础结构、设计模式、源代码优化技巧、实践应用分析以及进阶开发技巧。首先概述了EVCC协议和Gridwiz代码的基础知识,随后深入探讨了Gridwiz的架构设计、设计模式的应用、代码规范以及性能优化措施。在实践应用部分,文章分析了Gridwiz在不同场景下的应用和功能模块,提供了实际案例和故障诊断的详细讨论。此外,本文还探讨了
JFFS2源代码深度探究:数据结构与算法解析

# 摘要
JFFS2是一种广泛使用的闪存文件系统,设计用于嵌入式设备和固态存储。本文首先概述了JFFS2文件系统的基本概念和特点,然后深入分析其数据结构、关键算法、性能优化技术,并结合实际应用案例进行探讨。文中详细解读了JFFS2的节点类型、物理空间管理以及虚拟文件系统接口,阐述了其压
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )