MySQL优化基础:9个技巧助你立竿见影提升数据库性能
发布时间: 2024-12-06 19:52:48 阅读量: 20 订阅数: 19 

MySQL数据库设计与优化实战:提升查询性能与系统稳定性
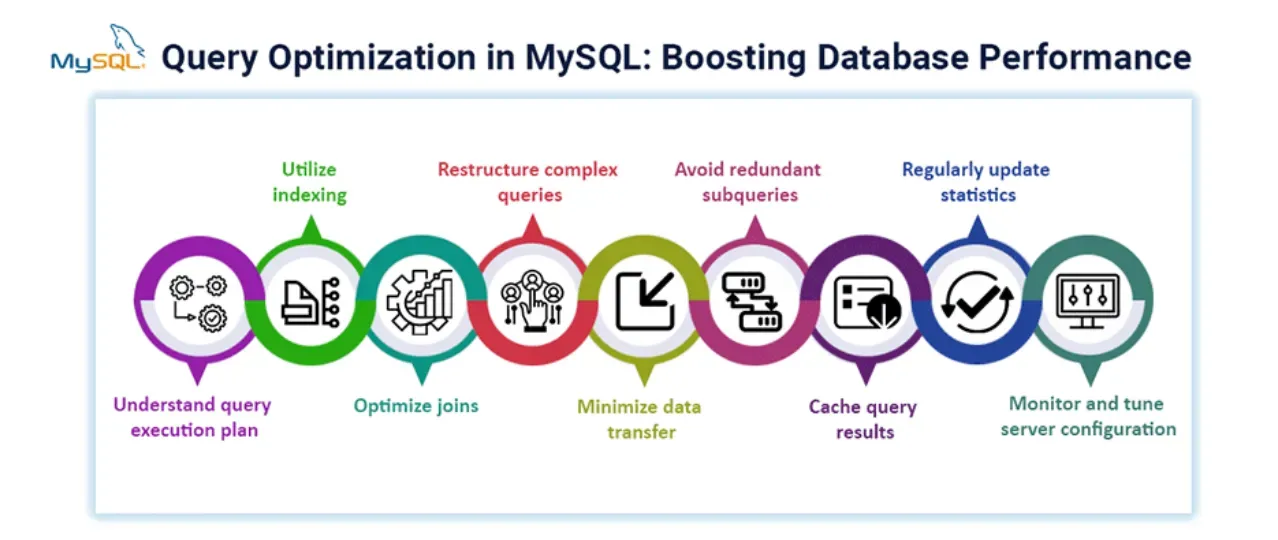
# 1. MySQL优化概述
MySQL作为最流行的开源数据库之一,其性能优化是确保数据密集型应用稳定运行的关键。随着业务数据量的增长,数据库操作的效率对系统性能的影响愈发显著。优化MySQL数据库不仅能提升查询速度和数据处理能力,还可以降低硬件资源消耗,确保系统的可扩展性和高可用性。在本章中,我们将从整体上介绍MySQL优化的概要,包括优化的目的、常见的优化方法和优化流程,为后续章节的深入讨论打下基础。
# 2. 索引优化技巧
索引是数据库优化中的核心话题之一,它对于数据库的性能有着决定性的影响。良好的索引设计可以大大提高查询效率,减少数据检索时间,而不恰当的索引则可能成为性能瓶颈。本章将深入探讨索引的基本概念、工作原理、选择合适的索引类型、以及如何通过实践进行索引优化。
## 2.1 索引的基本概念与重要性
索引在数据库中类似于图书的目录,它能够帮助数据库管理系统快速找到数据表中的特定记录。通过使用索引,可以避免全表扫描,大幅度减少数据检索所需的时间。
### 2.1.1 索引的工作原理
索引通常是一张表或者一个数据结构,存储了数据库表中字段的额外信息,这些额外信息可以是字段值及其指向的数据记录的位置(物理位置或逻辑位置)。当查询涉及索引列时,数据库使用索引记录来快速定位到数据行,而不是顺序扫描整个表。
以B-Tree索引为例,索引是按照树形结构来组织数据,使得数据的查询与插入操作能保持对数时间复杂度。B-Tree索引能够优化对范围查询的性能,尤其适用于等值查询和范围查询。
### 2.1.2 选择合适的索引类型
MySQL支持多种索引类型,包括B-Tree索引、哈希索引、全文索引和空间索引等。选择合适的索引类型对于提高查询效率至关重要。
- **B-Tree索引**:适用于全键值、键值范围或键值前缀查找。它是最常见的索引类型,支持数据的顺序访问。
- **哈希索引**:仅适用于全键值等值比较,对于范围查询支持不佳,但在数据仓库场景中,因其高效率而被广泛使用。
- **全文索引**:用于文本数据的搜索,特别是在大数据量的文本搜索中表现出色。
- **空间索引**:用于地理位置数据的存储和查询,例如GIS应用中的地理对象。
了解索引类型及其特点,有助于在不同的场景下做出合适的选择,以达到优化性能的目的。
## 2.2 索引优化实践
### 2.2.1 创建和删除索引的最佳实践
创建索引时,应考虑以下几点最佳实践:
1. **选择高选择性的列**:选择性指的是列中不同值的数量与表中总行数的比例。具有高选择性的列作为索引列可以更有效地减少搜索范围。
2. **不要索引不必要的列**:不是所有的列都需要索引,每个额外的索引都会占用存储空间并影响写操作的性能。
3. **考虑索引的列顺序**:对于组合索引(多列索引),索引的列顺序至关重要。要根据查询模式将高选择性、频繁用于查询条件的列放在前面。
```sql
-- 示例:创建一个多列索引
CREATE INDEX idx_name_age ON users(name, age);
```
在删除索引时,最佳实践包括:
1. **定期进行索引审查**:通过监控查询性能,确定哪些索引没有被利用或者使用频率非常低。
2. **谨慎删除索引**:在删除索引之前,确保该索引对数据库的性能提升不再有帮助。
3. **使用索引监视工具**:大多数数据库管理系统提供了监控工具来帮助识别不活跃的索引。
### 2.2.2 索引维护与碎片整理
随着数据的频繁增删改,索引可能会产生碎片,导致性能下降。进行索引维护和碎片整理有助于保持索引的最优性能。
索引碎片整理可以通过重建索引的方式来完成。在MySQL中,可以使用`OPTIMIZE TABLE`命令来整理表及其索引:
```sql
-- 重建表和索引,消除碎片
OPTIMIZE TABLE table_name;
```
在进行索引维护时,需要考虑以下几点:
1. **定期监控索引性能**:使用系统工具或自定义脚本来监控索引碎片情况和查询性能。
2. **选择合适的维护时间**:在业务低峰期执行索引维护操作,减少对业务的影响。
### 2.2.3 索引优化案例分析
通过具体的案例分析,可以更直观地了解索引优化的应用。
假设有一个电子商务网站的订单表`orders`,其包含字段`customer_id`、`order_date`、`status`等。网站经常需要按`customer_id`和`order_date`查询用户的订单。由于`customer_id`是一个经常用于查询的字段,且每个用户ID对应多个订单,因此为`customer_id`添加索引是合理的。
```sql
-- 为customer_id添加索引
CREATE INDEX idx_customer_id ON orders(customer_id);
```
然而,如果`customer_id`的基数(不同值的数量)非常低,即该列的值分布不均匀,那么可能需要考虑为`customer_id`和`order_date`创建组合索引。
```sql
-- 创建组合索引
CREATE INDEX idx_customer_order_date ON orders(customer_id, order_date);
```
这样,当查询涉及这两个字段时,组合索引可以更高效地工作。
索引优化不仅限于增加或删除索引。优化还涉及索引结构的选择、维护以及定期的性能监控,所有这些都需要根据实际的查询模式和数据分布来调整。通过实际案例分析,可以更好地理解索引优化的实践应用,帮助数据库管理员作出更加合理的决策。
# 3. 查询优化策略
## 3.1 SQL查询优化基础
### 3.1.1 理解查询执行计划
查询执行计划是数据库管理系统(DBMS)用于描述如何执行SQL查询的内部算法。理解执行计划对于优化查询至关重要,因为它揭示了查询处理的每个步骤、所涉及的表、操作类型以及使用的索引。
为了查看查询的执行计划,大多数的SQL数据库提供了`EXPLAIN`或类似的命令。例如,在MySQL中,你可以这样使用它:
```sql
EXPLAIN SELECT * FROM users WHERE age > 30;
```
这个命令会返回查询的详细执行计划,包括查询类型、访问的表、使用的索引、行被估计扫描的次数等。掌握如何阅读和理解这些信息,可以帮助你发现性能瓶颈,并对查询进行针对性的优化。
### 3.1.2 查询优化的常见误区
在进行查询优化时,开发者和DBA(数据库管理员)可能会落入一些常见误区,这些误区可能会误导他们采取不当的优化措施。以下是几个常见的误区:
- **过度索引:** 索引可以提高查询性能,但不是越多越好。每个索引都会占用额外的存储空间,并且在插入、更新或删除操作时也会增加额外的维护成本。
- **忽略查询缓存:** 一些数据库支持查询结果缓存,但开发人员可能会忽视这种优化方法。如果缓存策略配置得当,它可以显著提高频繁执行相同查询的应用程序的性能。
- **忽略统计信息:** 数据库依赖统计信息来生成查询执行计划。如果统计信息过时或不准确,可能导致生成效率低下的查询计划。
- **对SQL注入过度担忧:** 虽然确保SQL查询的安全性很重要,但过分追求安全措施而牺牲查询效率并不是一个好的做法。使用参数化查询既可以提高安全性也可以保持查询效率。
避免这些误区有助于更加系统和科学地进行查询优化,从而达到更好的性能提升。
## 3.2 查询优化实践
### 3.2.1 分页查询优化技巧
在Web应用程序中,分页查询是一个常见的需求,它允许用户浏览大量数据的子集。但是,分页查询可能会因为使用不当而导致性能问题,特别是在数据量很大时。
优化分页查询的一个有效技巧是使用`LIMIT`和`OFFSET`语句,但应当谨慎使用`OFFSET`,因为它可能导致大量数据的扫描。以下是一个分页查询的例子:
```sql
SELECT * FROM users ORDER BY id LIMIT 10 OFFSET 100;
```
在上述查询中,数据库会先排序`110`行数据,然后丢弃前`100`行,只返回剩下的`10`行。如果`OFFSET`很大,性能影响也会很显著。
一种替代方案是使用主键进行分页:
```sql
SELECT * FROM users WHERE id > (SELECT id FROM users LIMIT 10 OFFSET 990) LIMIT 10;
```
这种方法通过限制范围查找,避免了大范围的排序操作,能够更加高效地获取数据。
### 3.2.2 联合查询优化
当多个表需要通过某种关系连接起来时,联合查询就变得必要。然而,不恰当的使用联合查询可能会产生笛卡尔积,导致结果集的大小呈指数级增长,从而消耗大量资源。
为了优化联合查询,以下是几个实用的策略:
- **确保连接条件上的索引:** 使用索引可以显著提高连接操作的效率。
- **选择合适的连接类型:** MySQL提供了多种连接类型(如`INNER JOIN`、`LEFT JOIN`等)。选择正确的连接类型可以减少不必要的行处理,加快查询速度。
- **减少返回的数据量:** 只选择需要的列,而非使用`SELECT *`,这样可以减少数据传输和处理的量。
### 3.2.3 子查询与临时表优化
子查询和临时表是SQL中强大的工具,能够实现复杂的逻辑,但它们也可能成为性能瓶颈。
子查询可以通过多种方式优化:
- **尽可能使用关联子查询(correlated subqueries)代替非关联子查询:** 关联子查询只对每条外部查询的行执行一次,而非关联子查询对每一行都执行一次,效率更高。
- **转换子查询为JOIN操作:** 在某些情况下,将子查询转换为JOIN操作可以减少数据处理的复杂度。
临时表的优化建议包括:
- **使用内存中的临时表:** 在支持内存临时表的数据库系统中,使用内存临时表可以大大加快临时表的存取速度。
- **减少对临时表的I/O操作:** 尽量在临时表上执行必要的操作,避免不必要的数据写入和读取。
以下是一个将子查询优化为JOIN操作的示例:
```sql
-- 子查询版本
SELECT * FROM orders WHERE customer_id IN (SELECT id FROM customers WHERE active = 1);
-- JOIN版本
SELECT orders.* FROM orders JOIN customers ON orders.customer_id = customers.id WHERE customers.active = 1;
```
在JOIN版本中,数据库引擎可以优化查询计划,使用合适的索引,减少数据扫描量,从而提高效率。
通过以上章节的内容,我们可以看到,查询优化并不仅仅是理论知识,更包含了一系列实用的技巧和策略。针对不同的查询类型和操作,理解和应用这些优化策略,能够帮助我们显著提升数据库的查询性能。
# 4. 服务器和硬件优化
随着业务量的增长,仅依靠软件层面的优化往往不能完全满足数据库性能的要求。服务器和硬件层面的优化成为了不可或缺的一环。在本章节中,我们将探讨如何通过调整服务器配置、合理分配硬件资源以及选择正确的架构模式,来提升MySQL数据库的整体性能。
## 4.1 服务器性能调优
服务器性能调优主要涉及操作系统和数据库配置的优化。恰当的参数调整不仅可以使得数据库运行更加高效,还可以提升其稳定性。
### 4.1.1 配置文件参数调整
MySQL数据库的配置文件通常位于`/etc/my.cnf`或`/etc/mysql/my.cnf`,其中包含许多对数据库性能有着直接影响的参数。以下是一些常用的配置参数及其作用:
- `innodb_buffer_pool_size`: 控制InnoDB存储引擎的缓冲池大小,该参数是影响InnoDB性能的最大因素。
- `thread_cache_size`: 服务器能够缓存多少线程,减少线程创建和销毁的开销。
- `query_cache_size`: 用于缓存查询结果,对于经常执行相同查询的系统有明显的性能提升。
- `max_connections`: 限制同时打开的连接数,防止MySQL服务器耗尽资源。
配置文件的修改通常需要重启数据库服务才能生效。修改之前最好备份原有的配置文件,以便出现问题时能够快速恢复。
```ini
[mysqld]
innodb_buffer_pool_size = 1G
thread_cache_size = 16
query_cache_size = 32M
max_connections = 200
```
### 4.1.2 线程缓存与连接池优化
数据库连接管理是影响性能的另一个重要因素。线程缓存可以减少服务器创建和销毁线程的开销。连接池则能够管理数据库连接,复用现有连接而不是每次请求都创建新的连接,大大降低了开销。
以下是使用连接池的一些最佳实践:
- 根据业务需求设置`thread_cache_size`,通常在高并发场景下,一个较小的值也可以带来性能上的改善。
- 监控线程使用情况,通过`SHOW STATUS LIKE 'Thread%';`查看线程的统计信息,以调整参数。
```sql
SHOW STATUS LIKE 'Thread%';
```
## 4.2 硬件资源的合理配置
硬件资源的合理配置包括对内存、磁盘I/O和CPU资源的优化。下面我们将深入探讨如何根据数据库的特点对这些资源进行优化。
### 4.2.1 内存使用策略
数据库服务器对内存的需求较高,合理配置内存对于性能优化至关重要。
- InnoDB存储引擎会利用内存作为缓冲池(`innodb_buffer_pool_size`),提高数据和索引的缓存能力。
- MySQL还使用内存进行查询缓存(`query_cache_size`),但自MySQL 5.7起,查询缓存已被废弃,需要根据使用的MySQL版本决定是否启用。
```sql
SHOW VARIABLES LIKE 'innodb_buffer_pool_size';
```
### 4.2.2 磁盘I/O优化
磁盘I/O往往是性能瓶颈的常见来源,优化策略包括但不限于:
- 使用固态硬盘(SSD)替代传统硬盘(HDD),提高随机读写性能。
- 选择合适的文件系统,如对于MySQL,通常推荐使用XFS文件系统。
- 使用RAID技术可以提高磁盘的读写速度,保障数据的安全性。
### 4.2.3 CPU资源管理
CPU资源对数据库性能有着直接的影响,合理配置CPU资源包括:
- 为数据库操作分配足够多的CPU核心。
- 设置CPU亲和性,使MySQL服务器进程尽可能在固定的核心上运行。
- 在高并发环境下,考虑使用CPU绑定,避免进程在不同核心间频繁切换带来的性能损失。
```bash
# 通过taskset命令绑定进程到指定的CPU核心
taskset -cp [核心编号] [进程ID]
```
## 4.3 优化案例分析
在实际工作中,往往需要结合具体的业务场景进行优化。接下来我们将分析一个典型的优化案例。
### 案例分析
某中型电商网站面临每日高流量访问,数据库服务器经常出现性能瓶颈。通过分析发现,其主要瓶颈在于磁盘I/O延迟。
#### 优化步骤:
1. **硬件升级**:首先,将传统硬盘更换为SSD,显著提高了随机读写性能。
2. **配置调整**:增大`innodb_buffer_pool_size`至服务器物理内存的70%,减少磁盘I/O操作。
3. **RAID应用**:将多个SSD组成RAID 10阵列,提升性能并保障数据冗余。
#### 结果评估:
在实施以上优化措施后,数据库的响应时间大幅降低,业务量增长的同时,系统稳定性也得到了保障。
通过本章节的介绍,我们可以看到,服务器和硬件的优化对提升MySQL的整体性能至关重要。合理配置和管理这些资源,可以大幅提高数据库的处理能力。接下来的章节将继续探讨架构级别的优化策略,以进一步提高数据库系统的可用性和扩展性。
# 5. 架构级别的优化
## 5.1 数据库复制与分片
数据库复制和分片是提升大型系统性能和可用性的关键架构策略。它们能够帮助我们解决单点故障问题,实现数据的高可用性和读写分离,从而提升整体的系统性能。
### 5.1.1 主从复制机制及其优化
主从复制是一种常用的数据备份和高可用技术,其核心在于将主服务器(master)的更新操作实时复制到一个或多个从服务器(slave)。
- **工作机制**:
- 在主服务器上,所有的数据更改操作(如INSERT、UPDATE、DELETE)都会被记录到二进制日志(binary log)中。
- 从服务器会连接到主服务器并请求二进制日志中的更新,然后在自己的数据库上重新执行这些更新操作。
- 通过这个复制机制,主从服务器的数据可以保持一致性。
- **优化方法**:
- 使用异步复制保持主从之间的数据一致性,同时减少主服务器的负担。
- 采用多线程复制来加快数据同步的速度。
- 定期检查复制延迟,确保数据一致性。
- 对于读多写少的应用,可以将读操作负载均衡地分配到从服务器上。
### 5.1.2 分片策略与实施
分片(Sharding),即将大型数据库拆分为更小、更易于管理的数据库片段,这些片段可以分布在不同的服务器上。
- **常见分片策略**:
- 范围分片(Range Sharding):根据数据范围将数据拆分到不同分片。
- 哈希分片(Hash Sharding):通过哈希函数决定数据应存放在哪个分片上。
- 列表分片(List Sharding):数据根据预定义的列表值进行分片。
- **实施步骤**:
- **分析数据和负载模式**:了解数据访问模式,确定分片的键和策略。
- **选择分片键**:根据数据和查询模式,选择最佳的分片键。
- **实现分片逻辑**:在应用层或者数据库层实现分片逻辑。
- **数据分布与迁移**:将现有数据分布到不同的分片,并处理后续数据动态迁移问题。
### 代码块示例(配置分片键):
```sql
-- 创建分片表
CREATE TABLE orders (
order_id INT AUTO_INCREMENT,
customer_id INT,
order_date DATETIME,
-- 其他列
PRIMARY KEY (order_id),
-- 分片键选择
INDEX (customer_id)
);
```
## 5.2 缓存应用与负载均衡
在架构级别的优化中,缓存和负载均衡是提升读取性能和分散负载的重要手段。
### 5.2.1 缓存机制的选择与配置
缓存的使用可以极大地减少对后端数据库的直接访问次数,从而降低数据库的压力,提高系统的响应速度。
- **常见缓存策略**:
- 最近最少使用(LRU)缓存。
- 先进先出(FIFO)缓存。
- 最不经常使用(LFU)缓存。
- **配置示例**(以Redis为例):
```conf
# redis.conf 配置示例
maxmemory 2gb # 设置最大内存限制
maxmemory-policy allkeys-lru # 使用LRU策略回收缓存
```
### 5.2.2 负载均衡策略与工具
负载均衡可以将进入的网络流量分配到多个服务器上,以提高系统吞吐量和可用性。
- **常见负载均衡算法**:
- 轮询(Round Robin)。
- 加权轮询(Weighted Round Robin)。
- 最小连接(Least Connections)。
- **工具选择**:
- Nginx、HAProxy 作为软件负载均衡器。
- AWS ELB、Azure Load Balancer 作为云服务提供商的负载均衡服务。
## 5.3 高可用性解决方案
高可用性是指系统能够在极端情况下继续提供服务的能力,对于关键业务来说,高可用性是不可或缺的。
### 5.3.1 高可用架构概述
高可用架构是指通过多种冗余机制,保障系统即便在个别组件故障时也能持续提供服务。
- **核心组件**:
- 主备服务器(Active-Passive)。
- 主从复制(Master-Slave)。
- 集群(Clustering)。
- **实施方法**:
- 对于数据库服务,建立主从复制架构,并通过自动故障转移机制实现高可用。
- 实现数据定期备份以及灾难恢复计划,确保数据安全。
### 5.3.2 MySQL故障转移与恢复
在高可用架构中,MySQL故障转移和恢复机制是保证服务连续性的重要环节。
- **故障检测**:通过心跳检测、监控告警等方式快速发现故障。
- **自动故障转移**:使用MySQL Router或Orchestrator等工具进行自动故障切换。
- **数据恢复**:在故障切换后,确保从主节点同步数据至新的主节点。
在实施高可用架构时,应详细规划每个环节,并通过定期演练确保预案的有效性。随着系统的不断扩展,架构优化应是一个持续的过程,需要不断地评估、调整和优化。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏“MySQL开发者社区的资源与支持”为MySQL开发者提供了一系列全面的资源和支持。从优化基础到高级索引技巧,从构建监控系统到数据备份和恢复,专栏涵盖了MySQL数据库管理的各个方面。深入的技术解析、实战指南和专家见解使开发者能够提升数据库性能、优化查询、确保数据完整性并构建高可用性架构。专栏还探讨了MySQL 8.0的新特性、数据分区技术、MySQL与NoSQL混合架构以及动态SQL构建技巧,帮助开发者掌握最新的技术趋势和最佳实践。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【BLE设备管理实战】:Python中Bluepy应用技巧全解析

参考资源链接:[使用Python的bluepy库轻松操作BLE设备](https://wenku.csdn.net/doc/62j3doa3jk?spm=1055.2635.3001.10343)
# 1. BLE设备与Python编程基础
## 1.1 BLE技术概述
蓝牙低功耗(Bl
【电子工程师的IEC 60115-1:2020电路设计指南】:掌握标准影响与应用

参考资源链接:[IEC 60115-1:2020 电子设备固定电阻器通用规范英文完整版](https://wenku.csdn.net/doc/6412b722be7fbd1778d49356?spm=1055.2635.3001.10343)
# 1. IEC 60115-1:2020标准概述
## 1.1 标准简
Keil 5芯片项目迁移全攻略:从旧版本到新版本的无缝过渡

参考资源链接:[Keil5软件:C51与ARM版本芯片添加指南](https://wenku.csdn.net/doc/64532401ea0840391e76f34d?spm=1055.2635.3001.10343)
# 1. Keil 5芯片项目迁移概述
在现代嵌入式系统开发中,Keil MDK-ARM是许多开发者的首选工具,特别是在针对ARM处理器的芯片项目开发中。随着技术的不断进步,软件开发环境也需要相应更新升级以满
MA2灯光控台编程艺术:3个高效照明场景编写技巧

参考资源链接:[MA2灯光控台:集成系统与全面兼容的创新解决方案](https://wenku.csdn.net/doc/6412b5a7be7fbd1778d43ec8?spm=1055.2635.3001.10343)
# 1. MA2灯光控台编程基础
## 1.1 灯光控台概述
MA2灯光控台是一种先进的灯光控制设备,广泛应用于剧院、
CAE工具的完美搭档:FEMFAT无缝集成数据流教程
参考资源链接:[FEMFAT疲劳分析教程:参数设置与模型导入详解](https://wenku.csdn.net/doc/5co5x8g8he?spm=1055.2635.3001.10343)
# 1. FEMFAT工具概述与安装配置
FEMFAT是一款广泛应用于工程领域的疲劳分析软件,能够对各类结构件进行疲劳寿命评估。本章旨在介绍FEMFAT的基本概念、核心功能以及如何在计算机上完成安装与配置,以确保接下来的分析工作能够顺利进行。
## 1.1 FEMFAT简介
FEMFAT,全称“Finite Element Method Fatigue Analysis Tool”,是由德国著名的
项目管理更高效:ROST CM6功能深度使用与最佳实践!
参考资源链接:[ROST CM6使用手册:功能详解与操作指南](https://wenku.csdn.net/doc/79d2n0f5qe?spm=1055.2635.3001.10343)
# 1. ROST CM6项目管理概述
项目管理是确保项目按计划、预算和既定目标成功完成的关键。ROST CM6作为一套全面的项目管理解决方案,它将项目规划、执行、跟踪和控制等多个环节紧密地结合起来。本章将概述ROST CM6如何支持项目生命周期的各个阶段,帮助项目负责人和团队成员提高效率、降低风险,并确保项目目标得以实现。
在开始之前,重要的是要了解ROST CM6背后的基本原则和功能,这样我们才能
深入挖掘系统潜力:银河麒麟SP3内核调优实战指南

参考资源链接:[银河麒麟服务器OS V10 SP1-3升级指南:从SP1到SP3的详细步骤](https://wenku.csdn.net/doc/v5saogoh07?spm=1055.2635.3001.10343)
# 1. 银河麒麟SP3内核概述
银河麒麟SP3操作系统作为国产Linux发行版的重要成员,其内核的稳定性和安全性一直受到业界的广泛关注。在了解银河麒麟
【STAR-CCM+参数设置详解】:案例驱动的参数调优教程

参考资源链接:[STAR-CCM+ 9.06中文教程:案例详解与关键功能](https://wenku.csdn.net/doc/2j6jrqe2mn?spm=1055.2635.3001.10343)
# 1. STAR-CCM+简介与参数设置基础
## 1
【打造您的MAX96712项目】
参考资源链接:[MAX96712:GMSL转CSI-2/CPHY解封装与多路视频传输方案](https://wenku.csdn.net/doc/6w06d6psx6?spm=1055.2635.3001.10343)
# 1. MAX96712项目概览
## 1.1 MAX96712项目介绍
MAX96712项目代表了一个高度集成的多用途应
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )