【Optparse终极指南】:精通Python命令行参数解析
发布时间: 2024-10-07 12:54:44 阅读量: 84 订阅数: 29 

Python命令行参数解析模块optparse使用实例

# 1. Optparse简介与安装配置
在当今的软件开发领域,命令行工具以其强大的功能和灵活性在各种应用场景中扮演着重要角色。在Python中,Optparse是一个广泛使用的库,它帮助开发者创建标准的命令行接口(CLI)。本章我们将首先介绍Optparse的基本概念,并一步步引导读者完成其安装与配置。
Optparse(选项解析器)是Python标准库的一部分,主要用于解析命令行选项和参数。它提供了一种便捷的方式来创建可读性好、格式化的命令行界面。使用Optparse,开发者可以定义一系列的选项和参数,同时为每个选项设定预期的类型,如整数、浮点数或字符串。
安装Optparse是相对直接的过程,因为它是Python标准库的一部分,通常不需要单独安装。但在使用前,我们需要了解如何配置它以适应不同项目的具体需求。配置Optparse涉及创建解析器对象,并定义一系列参数和选项。通过这一系列操作,Optparse能够为用户提供清晰易懂的使用说明和帮助信息。
下面是一个简单的例子,展示如何安装和配置Optparse:
```python
import optparse
def main():
# 创建解析器对象
parser = optparse.OptionParser()
# 添加选项
parser.add_option("-v", "--verbose",
action="store_true", dest="verbose",
help="print status messages to stdout")
# 解析命令行参数
(options, args) = parser.parse_args()
if __name__ == '__main__':
main()
```
在此示例中,我们创建了一个带有`-v`或`--verbose`选项的命令行工具,该选项控制是否打印详细的状态信息。这只是Optparse功能的冰山一角,后续章节将进一步深入探讨Optparse的核心概念和高级用法。
# 2. Optparse核心概念与基础用法
## 2.1 参数解析器的创建与配置
### 2.1.1 构建基本的解析器
Optparse是Python中用于解析命令行参数的库,它通过为程序创建一个参数解析器来实现这一功能。参数解析器的创建通常在程序的主入口部分完成,这样可以确保在执行任何实际代码之前命令行参数已经被正确解析。
```python
import optparse
def main():
parser = optparse.OptionParser()
(options, args) = parser.parse_args()
print(options)
if __name__ == '__main__':
main()
```
在上面的代码段中,我们首先导入了`optparse`模块。随后定义了一个`main`函数,它创建了一个`OptionParser`实例。这个实例默认会创建一个标准的帮助消息,包含程序名和版本号等信息。之后,我们调用`parse_args`方法来解析命令行参数,并将结果分别赋值给`options`和`args`变量。`options`是一个命名空间对象,其中包含了所有解析出的选项,而`args`则是一个列表,包含了所有未被解析的参数。
### 2.1.2 添加参数说明与类型
Optparse允许程序员为每个命令行选项添加详细的说明,并可以指定该选项的类型,如字符串、整数等。这些说明会在用户运行程序时提供的帮助信息中显示。
```python
from optparse import OptionParser
def main():
parser = OptionParser(usage="usage: %prog [options] arg1 arg2")
parser.add_option("-v", "--verbose", action="store_true", dest="verbose",
help="make lots of noise [default=False]")
parser.add_option("-q", "--quiet", action="store_false", dest="verbose",
help="be vewwy quiet [default=False]")
parser.add_option("-f", "--file", type="string", dest="filename",
help="write report to FILE", metavar="FILE")
parser.add_option("-n", "--lines", type="int", dest="num_lines",
help="print NUM lines of the report [default=10]", default=10)
(options, args) = parser.parse_args()
print(options)
print(args)
if __name__ == '__main__':
main()
```
在该示例中,我们添加了四个选项:
- `-v` 或 `--verbose`:用于控制程序输出的详细程度。
- `-q` 或 `--quiet`:与`-v`相反,用于静默模式。
- `-f` 或 `--file`:指定输出文件的名称,需要是字符串类型。
- `-n` 或 `--lines`:指定要打印的行数,需要是整数类型。
`action`参数定义了当这个选项被激活时应该做什么操作。`store_true`表示如果指定了该选项,则将对应的属性设置为`True`;`store_false`则将对应的属性设置为`False`。`dest`参数是`options`对象中对应选项的属性名。
## 2.2 简单参数的处理
### 2.2.1 长选项与短选项的设置
长选项(long option)是指像`--verbose`这样的长字符串选项,它们更具可读性。短选项(short option)则是像`-v`这样的单字符选项,它们更加简洁。在Optparse中可以同时定义长选项和短选项,增加程序的灵活性。
```python
parser.add_option("-v", "--verbose", action="store_true", dest="verbose",
help="make lots of noise [default=False]")
```
在该例子中,`-v`和`--verbose`都被定义为控制输出详细程度的选项。长选项和短选项在使用时是等价的,用户可以任意选择其中一种来激活该功能。
### 2.2.2 默认值的指定与使用
为参数指定默认值可以确保程序在没有被提供该参数时,仍然能够正常运行。在Optparse中,可以通过设置`default`参数来指定参数的默认值。
```python
parser.add_option("-n", "--lines", type="int", dest="num_lines",
help="print NUM lines of the report [default=10]", default=10)
```
在这个选项中,我们为`-n`和`--lines`指定了一个默认值10,这意味着如果没有明确指定该选项,程序将默认打印10行输出。
## 2.3 高级参数的处理
### 2.3.1 多值选项与可变参数
有时需要处理可以接受多个值的命令行选项,或者一个选项可能会跟随一个可变数量的参数。Optparse支持这些高级用法,可以很好地应对多种参数的需求。
```python
parser.add_option("-f", "--files", type="string", action="append", dest="filenames",
help="input FILE to process [default=None]", metavar="FILE")
```
在上述代码中,`--files`选项可以接受多个文件名作为参数,每个文件名都将被添加到`filenames`列表中。这是通过设置`action="append"`来实现的,它会将所有遇到的参数添加到`options.filenames`列表中。
### 2.3.2 选项组的创建与应用
对于具有逻辑关联的一组选项,可以通过创建选项组(OptionGroup)来进行分组管理,这样在输出帮助信息时会更加清晰。
```python
group = optparse.OptionGroup(parser, "Output Options",
"Options controlling output of the program")
group.add_option("-o", "--output", dest="output",
help="set output directory [default=.]")
group.add_option("-t", "--timestamps", action="store_true", dest="timestamps",
help="include timestamps in output [default=False]")
parser.add_option_group(group)
```
这里我们创建了一个名为“Output Options”的选项组,并添加了`--output`和`--timestamps`两个选项。之后,我们将这个选项组添加到解析器中,这样在输出帮助信息时,这两个选项会出现在“Output Options”标题下,使帮助信息更加清晰。
# 3. Optparse在实际项目中的应用
## 3.1 命令行界面设计原则
### 3.1.1 用户体验的重要性
用户体验(UX)是衡量一个命令行界面好坏的重要指标。一个友好的命令行界面应当能够让用户以最少的精力完成他们的工作。在设计命令行界面时,应当考虑以下用户体验原则:
- 简洁明了:命令行工具应当有一个直观的命令结构,避免复杂的命令嵌套,减少用户记忆负担。
- 提供帮助:内建的帮助信息应当详尽,可以快速告知用户各个选项的作用。
- 明确的错误提示:当用户输入错误时,应提供清晰的错误信息,而不是让人困惑的错误代码。
- 快速响应:用户在输入命令后,应得到快速的响应,减少等待时间。
- 用户定制化:允许用户根据自己的喜好和需求进行配置,比如设置默认选项、配置文件等。
### 3.1.2 命令行界面的设计流程
设计命令行界面时,可以遵循以下流程:
1. 需求分析:确定工具需要完成哪些任务,每个任务需要哪些参数。
2. 设计命令结构:将不同功能分解为不同的命令和子命令,确保用户易于理解和记忆。
3. 创建帮助信息:提前准备帮助文档,确保每一个命令和选项都有相应的说明。
4. 开发原型:快速开发一个基本可用的命令行工具原型,实现主要功能。
5. 用户测试:邀请目标用户进行测试,收集反馈进行优化。
6. 持续迭代:根据用户反馈不断改进工具,增加新功能,优化用户体验。
## 3.2 Optparse的高级功能
### 3.2.1 子命令的处理与实现
在复杂的应用中,我们可能会遇到需要支持子命令的情况。Optparse模块支持子命令的定义,这允许我们创建更为复杂的命令行界面。子命令通常用于区分功能区,每个子命令可以有自己的参数集。下面是一个如何在Optparse中处理子命令的示例代码:
```python
from optparse import OptionParser
def main():
parser = OptionParser()
subparsers = parser.add_subparsers(help='sub-command help')
# 创建子命令解析器
parser_scan = subparsers.add_parser('scan', help='start a scan')
parser_scan.add_argument('--path', action='store', type=str, help='specify scan path')
parser_clean = subparsers.add_parser('clean', help='clean up scan results')
parser_clean.add_argument('--all', action='store_true', help='clean all results')
# 解析命令行参数
(options, args) = parser.parse_args()
if options.path is not None:
# 执行scan子命令相关操作
pass
elif options.all:
# 执行clean子命令相关操作
pass
else:
parser.print_help()
if __name__ == '__main__':
main()
```
### 3.2.2 帮助信息的自定义与输出
Optparse模块会自动帮助用户生成帮助信息,但有时我们需要根据自己的需求自定义帮助信息的内容和格式。Optparse允许我们通过覆盖`usage`方法来实现这一点。下面是一个自定义帮助信息输出的代码示例:
```python
from optparse import OptionParser
class CustomHelpParser(OptionParser):
def usage(self):
return "Usage: %prog [OPTIONS] [COMMAND]\n"
def format_help(self):
usage = self.usage()
formatter = self.get帮助 formatter()
formatter.add_usage(usage, self.option_list, [], "Commands: scan, clean")
formatter.add_option(self.help_option)
formatter.add_text("\nOptions:")
formatter.start_options()
for option in self.option_list:
if option.help is not self._OptHelpFormatter.help_positional:
formatter.add_option(option)
formatter.end_options()
formatter.add_text("\nCommands:")
formatter.start_options()
formatter.add_text("scan -- start a scan\n")
formatter.add_text("clean -- clean up scan results\n")
formatter.end_options()
return formatter.format_help()
def main():
parser = CustomHelpParser()
# 省略子命令定义等代码
if __name__ == '__main__':
main()
```
## 3.3 实战演练:构建复杂命令行工具
### 3.3.1 多选项与多值参数的应用
在设计复杂的命令行工具时,经常会遇到需要支持多个选项或需要多个值的参数。Optparse提供了`add_option`方法,其`action`参数可以设置为`append`,这允许用户为同一参数多次赋值。下面是一个使用多值参数的例子:
```python
from optparse import OptionParser
def main():
parser = OptionParser()
parser.add_option('-f', '--file', action='append', type='string', help='specify file names')
parser.add_option('-v', action='store_true', help='enable verbose mode')
(options, args) = parser.parse_args()
if options.v:
print("Verbose mode is enabled.")
if options.***
***
***"File:", f)
else:
parser.error("No files specified")
if __name__ == '__main__':
main()
```
### 3.3.2 错误处理与用户反馈机制
良好的错误处理和用户反馈机制对于提高用户体验至关重要。当用户犯错时,命令行工具应该清晰地告知用户错误原因,并提供一些指导。Optparse模块通过`error`方法实现了基本的错误处理机制,该方法在参数解析出错时会被调用,它默认会打印出错信息并退出程序。然而,我们可以在程序中自定义这个行为以提供更人性化的错误处理。以下是一个定制错误处理逻辑的示例:
```python
from optparse import OptionParser
def main():
parser = OptionParser()
parser.add_option('-f', '--file', action='store', type='string', help='specify a file name')
(options, args) = parser.parse_args()
if not options.***
***"You must specify a file name with the -f or --file option.")
try:
with open(options.file, 'r') as f:
print(f.read())
except IOError as e:
parser.error("Error opening file: " + str(e))
if __name__ == '__main__':
main()
```
上述代码演示了如何结合自定义错误处理逻辑,提供清晰的用户反馈。
在本章节中,我们深入了解了Optparse在实际项目中的应用,涵盖了设计原则、高级功能以及实战演练。通过具体案例,我们展现了如何利用Optparse构建复杂的命令行工具,以满足项目中的各种需求。
# 4. Optparse与其他库的整合与比较
## 4.1 Optparse与argparse的对比分析
### 4.1.1 功能与性能的比较
Optparse和argparse都是Python标准库中用于处理命令行参数的模块,但是随着Python的发展,argparse已经成为了推荐的参数解析库。在功能上,argparse提供了更为丰富的功能和更灵活的配置选项。
argparse在Optparse的基础上改进了对子命令的支持,使得能够更加方便地为复杂程序提供清晰的命令结构。同时,argparse提供了自动生成帮助和使用说明的功能,而Optparse则需要手动编写帮助信息。
在性能方面,argparse通常比Optparse更优,特别是在处理大量参数或复杂参数结构时。argparse的内部实现更加高效,使用了更少的内存,并且解析速度更快。
### 4.1.2 兼容性与迁移指南
从Optparse迁移到argparse相对容易,argparse模块提供了很多与Optparse类似的接口。然而,迁移过程中需要注意的是,argparse的默认行为与Optparse有所不同,特别是在参数的命名和帮助信息的生成上。因此,迁移时可能需要对现有代码进行一些小的调整。
对于那些已经在使用Optparse并且希望迁移到argparse的项目,可以使用argparse提供的`convert_arg_line_to_args`函数,它可以帮助开发者逐步将旧的参数格式转换为新的格式。另外,argparse的设计也更加注重代码的可读性和扩展性,因此在迁移过程中应考虑这些因素,以便更好地利用argparse的优势。
## 4.2 与第三方库的整合方案
### 4.2.1 使用Click简化命令行工具开发
Click是另一个流行的命令行接口库,它在argparse的基础上进一步简化了命令行工具的开发。Click的语法更接近于编写Web框架Flask的风格,因此对于熟悉Flask的开发者来说,使用Click将非常直观。
Click的一个显著优势是它支持参数的继承和组合,这使得在构建复杂的命令行应用时,能够更加模块化和可重用。Click还内置了强大的帮助文档和自动完成支持。
使用Click时,开发者可以定义多个命令函数,每个函数对应不同的操作。Click通过装饰器来配置每个命令的行为,这样的方式比argparse更加直观。例如:
```python
import click
@click.group()
def cli():
***
***mand()
def run():
"""Run the application."""
click.echo("Running the application.")
if __name__ == "__main__":
cli()
```
在上面的例子中,我们定义了一个命令行组`cli`,并在其下定义了一个子命令`run`。点击框架会自动处理命令行参数,并调用相应的函数。
### 4.2.2 Plumbum与其他库的互操作性
Plumbum是一个Python库,用于创建和运行外部命令行程序,并与之交互。它的一个主要特点是允许从Python代码中直接运行和管理外部程序,而不需要手动调用`os.system`或`subprocess`模块。
Plumbum与Optparse、argparse等参数解析库的整合,主要体现在创建外部命令行工具时,可以利用这些库处理命令行参数,而Plumbum负责运行这些命令。这种设计为开发者提供了极大的灵活性,使得他们可以根据需要选择合适的参数解析库。
例如,可以将Optparse或argparse解析的结果作为参数传递给Plumbum的`LocalCommand`对象:
```python
from plumbum.cmd import ls
from plumbum import local
def run_custom_command(args):
command = local[ls]("-l", args.directory)
click.echo(command())
```
在这个例子中,`run_custom_command`函数接受由argparse或其他解析库提供的参数`args.directory`,然后使用Plumbum的`local`对象执行`ls -l`命令。
整合Plumbum不仅限于运行外部命令,还包括管道操作、进程间通信、多进程支持等高级功能。这些功能为构建复杂的命令行应用提供了有力支持。
接下来的内容,将会深入探讨Optparse的优化与未来展望,包括性能优化策略、内存管理以及Python命令行参数解析工具的发展趋势。
# 5. Optparse的优化与未来展望
## 5.1 性能优化与内存管理
在构建高性能的命令行应用时,性能优化和内存管理是不可忽视的两个方面。Optparse作为一个Python库,虽然在功能上可能不如argparse或Click全面,但在性能和内存使用方面仍有优化空间。
### 5.1.1 代码级别的性能提升技巧
为了提升Optparse解析命令行参数的性能,我们可以从代码层面进行一些优化:
- **使用生成器避免内存溢出**:当我们处理大量数据时,应该尽量使用生成器来代替列表,这样可以按需生成数据而不是一次性加载到内存中。
- **预分配内存**:对于需要存储大量数据的场景,提前分配固定大小的内存空间可以减少Python内部频繁的内存分配和回收操作。
- **避免全局变量**:在Python中,全局变量的使用会使得它们一直保持在内存中,直到程序结束。尽量减少全局变量的使用,有助于改善内存管理。
下面是一个简单的示例,展示如何使用生成器来处理大量数据:
```python
def generate_large_data():
for i in range(1000000):
yield i
def process_data(generator):
for item in generator:
# 处理数据
pass
# 使用生成器来避免一次性将所有数据加载到内存中
process_data(generate_large_data())
```
### 5.1.2 内存泄漏的监控与预防
监控内存泄漏是保证程序稳定运行的关键。Python中的`tracemalloc`模块可以帮助我们监控内存使用情况:
```python
import tracemalloc
tracemalloc.start()
# 模拟使用Optparse进行参数解析的代码块
# ...
# 捕获快照进行内存分析
snapshot = tracemalloc.take_snapshot()
top_stats = snapshot.statistics('lineno')
for stat in top_stats[:10]:
print(stat)
```
预防内存泄漏的措施包括:
- **避免无限循环**:确保所有的循环都有退出条件。
- **正确关闭资源**:比如文件句柄、数据库连接等,使用`with`语句可以帮助自动管理资源的释放。
- **使用弱引用**:当不再需要某个对象时,可以让其他对象对该对象的引用变为弱引用,从而允许垃圾收集器回收它。
## 5.2 Python命令行参数解析的发展趋势
随着Python的发展,命令行参数解析库也在不断更新与迭代。了解发展趋势对于把握Optparse的未来定位和选择替代工具都至关重要。
### 5.2.1 新兴工具的探索与分析
社区中不断有新的命令行解析工具涌现。以下是一些值得探索的工具:
- **Click**:一个非常流行的命令行接口创建库,它在argparse的基础上提供了更简单的API,并支持创建复杂的命令行工具。
- **Typer**:一个基于类型提示的工具,旨在让定义命令行接口变得更加简单和直观。
- **Docopt**:使用自然语言描述命令行接口,从描述中自动生成代码,适合那些想要用最少代码定义命令行的用户。
### 5.2.2 社区动态与未来展望
随着Python 3的普及和Python核心开发者的推动,社区正逐步推动向更加现代化的命令行解析库过渡。Optparse在未来的角色可能会有所转变,但它所体现的简单和易用性理念将继续影响新的库的设计。
- **向Typer等库的过渡**:Typer的设计哲学与Optparse相似,但它结合了类型提示的优势,成为了许多新项目的首选。
- **Python 3.10 新特性**:PEP 612引入了Pattern Matching,未来可能会有库利用这一特性来改善命令行参数的解析和处理。
- **持续集成与测试**:社区趋向于更多的集成测试和持续集成流程,以确保命令行工具在不同环境中的稳定性和兼容性。
通过不断优化和更新,Optparse及其衍生库将继续为Python社区提供强大的命令行参数解析能力。而作为开发者,紧跟社区动态,掌握新兴工具和语言特性,是保持个人竞争力的关键。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Optparse 专栏,您的 Python 命令行参数解析指南。本专栏深入探讨了 Optparse 库,从基础到高级技巧,以及定制选项处理的秘诀。我们涵盖了 Optparse 的各个方面,包括实战指南、适应新潮流的策略、替代方案比较、代码示例、最佳实践和 Python 项目中的最佳应用。通过本专栏,您将精通 Optparse,并能够打造用户友好的命令行界面、自动化脚本并高效处理复杂的参数解析场景。无论您是 Optparse 新手还是经验丰富的开发者,本专栏都将为您提供所需的知识和技巧,以充分利用 Optparse 的强大功能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
CENTUM VP软件安装与配置:新手指南,一步步带你成为专家
# 摘要
本文全面介绍了CENTUM VP软件的安装、配置及优化流程,并通过实战应用案例展示了其在工业过程控制中的实际运用。首先概述了CENTUM VP软件的特点和系统要求,接着详细阐述了安装前期的准备工作、安装过程中的关键步骤,以及安装后系统验证的重要性。本文重点探讨了CENTUM VP的高级配置
【CST-2020 GPU加速实战】:从入门到精通,案例驱动的学习路径
# 摘要
随着计算需求的不断增长,GPU加速已成为提高计算效率的关键技术。本文首先概述了CST-2020软件及其GPU加速功能,介绍了GPU加速的原理、工作方式以及与CPU的性能差异。随后,探讨了CST-2020在实际应用中实现GPU加速的技巧,包括基础设置流程、高级策略以及问题诊断与解决方法。通过案例研究,文章分析了GPU
【Vue翻页组件全攻略】:15个高效技巧打造响应式、国际化、高安全性的分页工具
# 摘要
本文详细探讨了Vue翻页组件的设计与实现,首先概述了翻页组件的基本概念、应用场景及关键属性和方法。接着,讨论了设计原则和最佳实践,强调了响应式设计、国际化支持和安全性的重要性。进一步阐述了实现高效翻页逻辑的技术细节,包括分页算法优化、与Vue生命周期的协同,以及交互式分页控件的构建。此外,还着重介绍了国际化体验的打
Pspice信号完整性分析:高速电路设计缺陷的终极解决之道
# 摘要
信号完整性是高速电路设计中的核心问题,直接影响电路性能和可靠性。本文首先概述了信号完整性分析的重要性,并详细介绍了相关理论基础,包括信号完整性的概念、重要性、常见问题及其衡量指标。接着,文章深入探讨了Pspice模拟工具的功能和在信号完整性分析中的应用,提出了一系列仿真流程和高级技巧。通过对Pspice工具在具体案例中的应用分析,本文展示了如何诊断和解决高速电路中的反射、串
实时系统设计师的福音:KEIL MDK中断优化,平衡响应与资源消耗
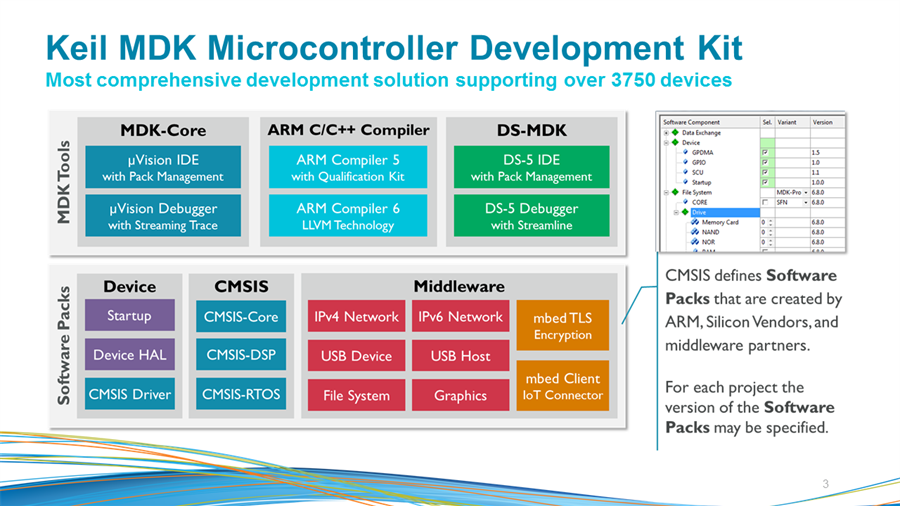
# 摘要
本文深入探讨了实时系统中中断管理的重要性,分析了MDK中断管理机制
iText-Asian字体专家:解决字体显示问题的5大技巧

# 摘要
本文全面介绍了iText-Asian字体专家的使用和挑战,深入探讨了iText-Asian字体显示的问题,并提供了一系列诊断和解决策略。文章首先概
面板数据处理终极指南:Stata中FGLS估计的优化与实践

# 摘要
本文系统地介绍了面板数据处理的基础知识、固定效应与随机效应模型的选择与估计、广义最小二乘估计(FGLS)的原理与应用,以及优化策略和高级处理技巧。首先,文章提供了面板数据模型的理论基础,并详细阐述了固定效应模型与随机效应模型的理论对比及在Stata中的实现方法。接着,文章深入讲解了FGLS估计的数学原理和在Stat
ngspice蒙特卡洛分析:电路设计可靠性评估权威指南
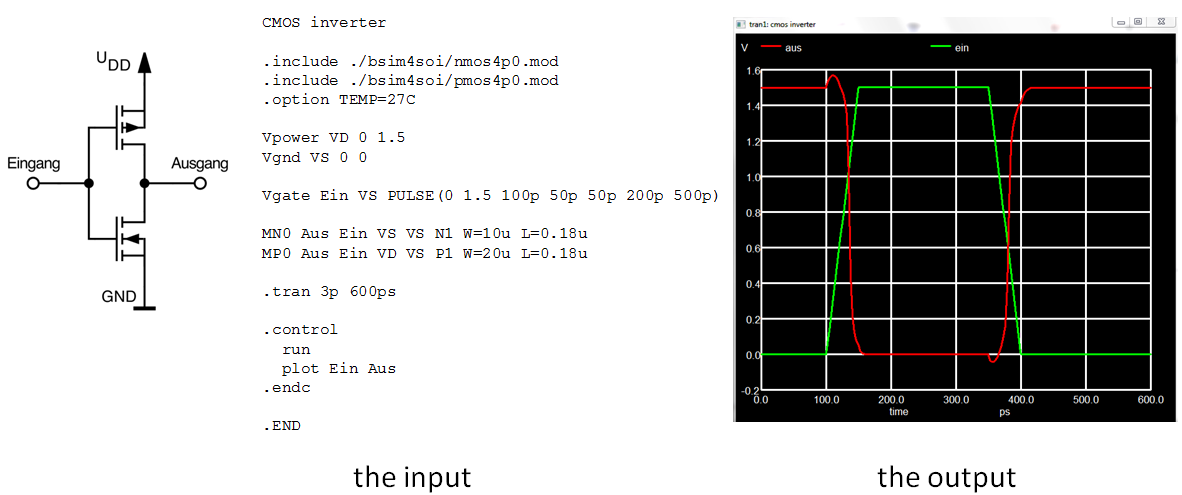
# 摘要
本文系统阐述了ngspice软件在电路设计中应用蒙特卡洛分析的基础知识、操作实践和高级技巧。通过介绍蒙特卡洛方法的理论基础、电路可靠性评估以及蒙特卡洛分析的具体流程,本文为读者提供了在ngspice环境下进行电路模拟、参数分析和可靠性测试的详细指南。此外,本文还探讨了在电路设计实践中如何通过蒙特卡洛分析进行故障模拟、容错分析和电路优化,以及如何搭建和配置ngspice模拟环境。最后,文章通过实际案例分析展示了蒙特卡洛分
红外循迹项目案例深度分析:如何从实践中学习并优化设计
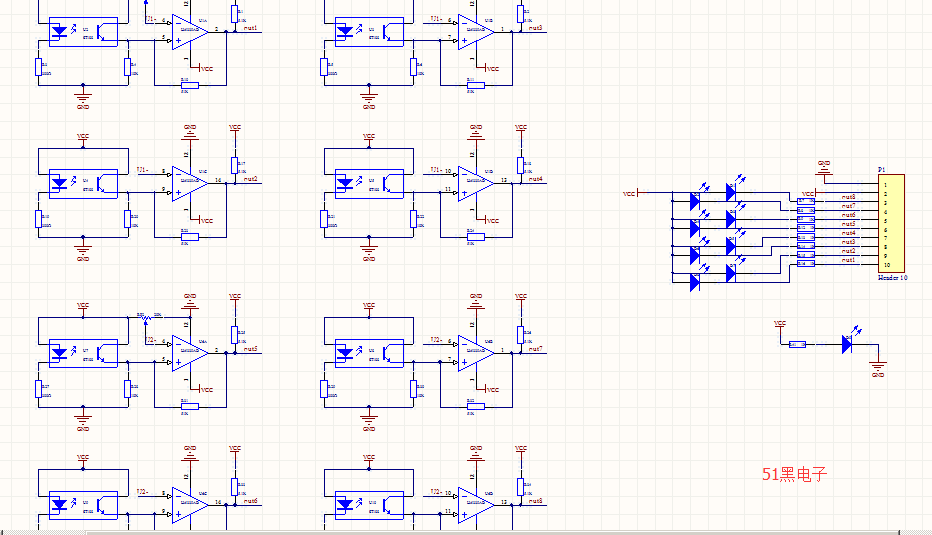
# 摘要
红外循迹技术作为一种精确引导和跟踪技术,在自动化和机器人技术中具有广泛的应用。本文首先概述了红外循迹技术的基本概念和理论基础,继而详细介绍了一个具体的红外循迹项目从设计基础到实践应用的过程。项目涉及硬件搭建、电路设计、软件算法开发,并针对实现和复杂环境下的适应性进行了案例实践。本文还探讨了红外循迹设计过程中的挑战,并提出相应的解决方案,包括创新设计思路与方法,如多传感器融合技术和机器学习应用。最后,文章探讨了红外循迹技术的进阶扩展、项目管
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )