深入掌握Taggit:项目中标签管理的高级应用
发布时间: 2024-10-16 23:48:55 阅读量: 39 订阅数: 30 
# 1. Taggit的概念与基础应用
在这一章节中,我们将探讨Taggit的基本概念,并介绍如何在项目中实现基础的标签功能。Taggit是一种在Web开发中常用的标签管理工具,它能够帮助开发者快速地为内容对象添加、管理和查询标签。在很多Web应用中,例如博客系统、内容管理系统和电商平台,Taggit都是一个不可或缺的功能,它不仅能够提高内容的可检索性,还能够增强用户体验。
## Taggit的基本概念
Taggit的核心是一个标签系统,它允许用户为内容对象(如文章、商品、视频等)分配一个或多个标签。这些标签可以是用户自定义的,也可以是预设的分类标签。在技术实现上,Taggit通常涉及到数据库的设计,以及与之相关的数据模型和查询逻辑。
## Taggit的基础应用
实现Taggit的基础应用,通常需要完成以下步骤:
1. **定义标签模型**:在数据库中创建一个标签表,用于存储标签的名称、描述等基本信息。
2. **关联对象模型**:在内容对象的模型中添加对标签的支持,通常是通过外键关联到标签表。
3. **用户界面**:设计用户界面元素,如标签云、标签选择器等,让用户能够方便地添加和管理标签。
```python
# 示例代码:定义一个简单的标签模型
class Tag(models.Model):
name = models.CharField(max_length=50, unique=True)
description = models.TextField(blank=True)
```
通过上述步骤,开发者可以快速实现一个基本的标签功能,为内容对象添加标签,以及通过标签来检索内容。然而,这只是Taggit功能的冰山一角,后续章节将深入探讨Taggit的高级特性和在不同场景下的应用。
# 2. Taggit的高级特性解析
## 2.1 Taggit的标签分类与管理
### 2.1.1 分类标签的创建与编辑
在本章节中,我们将深入探讨Taggit的高级特性,首先从标签分类与管理开始。分类标签的创建与编辑是Taggit管理中的核心功能之一。通过分类标签,可以将实体数据根据不同的属性或特征进行分组,从而方便地进行数据组织和检索。
#### 创建分类标签
创建分类标签通常涉及定义标签的属性和层级结构。在许多应用中,标签可以具有属性,如颜色、权重或其他元数据,这些属性可以用于进一步的数据过滤和排序。
```python
from taggit.models import Tag, TaggedItem
# 创建一个新的分类标签
tag = Tag.objects.create(name='编程', slug='programming')
# 将标签与特定的实体关联
tagged_item = TaggedItem.objects.create(tag=tag, content_object=some_object)
```
在上述代码中,我们首先导入了`Tag`和`TaggedItem`模型,然后创建了一个名为“编程”的标签,并将其与特定对象关联。这里的`some_object`代表需要标记的实体对象。
#### 编辑分类标签
编辑分类标签通常涉及到更新标签的属性,比如名称、描述或层级结构。在某些情况下,可能需要对标签进行合并、拆分或重新分类。
```python
# 更新标签属性
tag.name = '软件开发'
tag.save()
# 关联到新的对象
tagged_item.content_object = another_object
tagged_item.save()
```
在编辑过程中,我们可以简单地更改标签的属性,并保存更改。同时,标签关联的对象也可以更新,以反映新的关联关系。
### 2.1.2 分类标签的存储与检索
标签的存储与检索是另一个重要的方面,它影响到系统的性能和响应速度。Taggit提供了一种高效的方式来存储和检索标签数据。
#### 存储机制
Taggit使用关系型数据库来存储标签和标签项。每个标签存储为一个单独的记录,标签项则是标签与实体对象之间的关联。
```sql
-- 假设数据库表结构如下
CREATE TABLE tags (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100),
slug VARCHAR(100) UNIQUE
);
CREATE TABLE tagged_items (
id INT AUTO_INCREMENT PRIMARY KEY,
tag_id INT,
content_type_id INT,
object_id BIGINT,
FOREIGN KEY (tag_id) REFERENCES tags(id)
);
```
在数据库层面,`tags`表存储标签的基本信息,`tagged_items`表存储标签与实体对象之间的关联关系。通过这种结构,可以快速检索与特定标签关联的所有对象。
#### 检索机制
检索标签通常涉及到根据不同的条件过滤标签列表,例如标签名称、对象类型或特定对象的关联标签。
```python
# 根据标签名称检索
tags = Tag.objects.filter(name__startswith='编程')
# 根据对象检索关联的标签
related_tags = TaggedItem.objects.filter(content_object=some_object)
# 根据对象类型检索关联的标签
content_type_tags = TaggedItem.objects.filter(content_type=ContentType.objects.get_for_model(MyModel))
```
在上述代码中,我们展示了如何根据不同的条件检索标签。这些检索操作通常利用数据库的索引来提高性能。
### 2.1.3 分类标签的权限控制
在某些应用场景中,对标签的访问和编辑权限需要进行控制。Taggit支持基于Django内置的权限系统来实现这一点。
#### 权限控制机制
Taggit可以利用Django的权限系统来控制用户对标签的访问和编辑权限。例如,可以为不同的用户组分配对特定标签的只读或编辑权限。
```python
from django.contrib.auth.models import Group
from django.contrib.contenttypes.models import ContentType
from taggit.models import Tag
# 创建一个用户组
group = Group.objects.create(name='标签编辑者')
# 分配权限
content_type = ContentType.objects.get_for_model(Tag)
permission = Permission.objects.create(
codename='change_tag',
name='Can change tags',
content_type=content_type
)
group.permissions.add(permission)
# 将用户添加到组
user.groups.add(group)
```
在上述代码中,我们首先创建了一个新的用户组,并为该组分配了一个修改标签的权限。然后,将一个用户添加到该组中,从而赋予该用户修改标签的权限。
#### 权限的应用
在实际应用中,权限系统可以用于控制用户对标签的编辑操作。例如,只有拥有编辑权限的用户才能创建或修改标签。
```python
# 检查用户是否有权限编辑标签
def can_edit_tag(user, tag):
return user.has_perm('taggit.change_tag', tag)
# 示例:用户尝试编辑标签
if can_edit_tag(user, tag):
# 执行编辑操作
pass
else:
# 提示无权限
pass
```
在上述示例中,我们定义了一个函数`can_edit_tag`来检查用户是否有权限编辑标签。根据用户的权限状态,执行相应的操作。
## 2.2 Taggit的标签关联功能
### 2.2.1 标签与对象的关联机制
Taggit通过关联模型`TaggedItem`将标签与对象关联起来。每个`TaggedItem`实例代表一个标签与特定对象之间的关联。
#### 关联模型
`TaggedItem`模型包含三个主要字段:`tag`(指向`Tag`模型的外键),`content_type`(指向`ContentType`模型的外键),以及`object_id`(对象的ID)。
```python
# 创建关联示例
tagged_item = TaggedItem(tag=my_tag, content_object=my_object)
tagged_item.save()
```
在上述代码中,我们创建了一个新的`TaggedItem`实例,将一个标签与一个对象关联起来。`content_object`字段指向被标记的对象。
### 2.2.2 多对多关联的实现与优化
Taggit支持标签与对象之间的多对多关系。这意味着一个对象可以有多个标签,一个标签也可以关联多个对象。
#### 多对多关系
在Django中,多对多关系是通过`ManyToManyField`字段实现的。在Taggit中,`TaggedItem`模型的`content_type`和`object_id`字段共同构成了一个隐式的多对多关系。
```python
class MyModel(models.Model):
# ...
tags = models.ManyToManyField('taggit.Tag', through='taggit.TaggedItem')
```
在上述代码中,`MyModel`模型通过`ManyToManyField`与`Tag`模型建立了多对多关系。`through`参数指定了中间模型`TaggedItem`。
#### 优化策略
为了提高多对多关系的性能,Taggit可以利用数据库索引来优化查询。
```sql
-- 为多对多关系创建索引
CREATE INDEX tagged_items_tag_id_content_type_id_object_id ON tagged_items(tag_id, content_type_id, object_id);
```
在上述SQL语句中,我们创建了一个复合索引,覆盖了`tag_id`、`content_type_id`和`object_id`字段。这有助于提高多对多查询的性能。
### 2.2.3 标签权重与排序的应用
在某些应用场景中,可能需要为标签分配权重,以便根据权重对标签进行排序。
#### 权重分配
Taggit没有内置的权重字段,但可以通过扩展模型来添加自定义权重。
```python
class TaggedItemExtended(models.Model):
tag = models.ForeignKey('taggit.Tag', on_delete=models.CASCADE)
content_object = models.ForeignKey('contenttypes.ContentType', on_delete=models.CASCADE)
object_id = models.PositiveIntegerField()
weight = models.IntegerField(default=1)
class Meta:
indexes = [
models.Index(fields=['tag', 'weight']),
]
```
在上述代码中,我们创建了一个扩展的`TaggedItem`模型`TaggedItemExtended`,添加了一个`weight`字段来表示权重。
#### 排序应用
在检索标签时,可以根据权重对结果进行排序。
```python
# 根据权重检索并排序标签
tags = TaggedItemExtended.objects.all().annotate(tag_name=Concat('tag__name', Value('#'), output_field=CharField())).order_by('-weight')
```
在上述代码中,我们使用了`annotate`和`Concat`函数来生成一个带有标签名称和分隔符的新字段,并根据`weight`字段的值进行降序排序。
## 2.3 Taggit的过滤与搜索优化
### 2.3.1 基于标签的搜索过滤策略
Taggit支持基于标签的搜索过滤,允许用户根据标签名称或属性过滤对象。
#### 简单过滤
简单的标签过滤通常涉及到查询与特定标签关联的对象。
```python
# 简单地根据标签名称过滤
items = my_model.objects.filter(tags__name='编程')
```
在上述代码中,我们使用了Django的跨关系查询语法`tags__name`来过滤与标签名称为“编程”的对象。
#### 复杂过滤
复杂的过滤可能涉及到多个标签的组合,或者标签与对象属性的组合。
```python
# 复杂过滤:标签组合
items = my_model.objects.filter(tags__name__in=['编程', '软件开发']).distinct()
# 标签与对象属性组合
items = my_model.objects.filter(tags__name='编程', name='我的项目')
```
在上述代码中,我们展示了如何使用`__in`查询来过滤同时关联多个标签的对象,以及如何结合对象属性进行过滤。
### 2.3.2 搜索性能的优化技巧
搜索性能的优化对于提供良好的用户体验至关重要。Taggit提供了一些内置的优化技巧,以及一些通用的优化方法。
#### 数据库索引
在数据库层面,创建合适的索引是优化搜索性能的关键。
```sql
-- 为标签名称和对象ID创建索引
CREATE INDEX tags_name ON tags(name);
CREATE INDEX tagged_items_content_type_id_object_id ON tagged_items(content_type_id, object_id);
```
在上述SQL语句中,我们创建了索引来加速标签名称的搜索和标签项的查询。
#### 缓存
缓存是另一个提高搜索性能的常用技巧。Taggit提供了内置的缓存机制,可以通过缓存中间件来实现。
```python
# 在Django设置中启用缓存
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.locmem.LocMemCache',
}
}
# 使用缓存
from django.core.cache import cache
from taggit.utils import (
edit_distance,
get_edit_dist_cache_key,
)
key = get_edit_dist_cache_key('编程', '软件开发')
cache_value = cache.get(key)
if cache_value is None:
cache_value = edit_distance('编程', '软件开发')
cache.set(key, cache_value, 60 * 60) # 缓存1小时
```
在上述代码中,我们展示了如何使用缓存来存储标签之间的编辑距离,以优化基于相似性的搜索。
### 2.3.3 搜索结果的呈现与处理
在最终呈现搜索结果时,需要考虑结果的排序和分页。
#### 排序
搜索结果可以根据相关性或其他标准进行排序。
```python
# 根据标签权重排序
items = my_model.objects.annotate(tag_weight=Max('tags__taggeditem__weight')).order_by('-tag_weight')
```
在上述代码中,我们通过注释查询集来计算每个对象关联的标签权重的最大值,并根据这个值进行降序排序。
#### 分页
分页可以限制搜索结果的数量,并提高页面加载速度。
```python
from django.core.paginator import Paginator
# 分页处理
paginator = Paginator(items, 10) # 每页10个项目
page_number = request.GET.get('page')
page_obj = paginator.get_page(page_number)
```
在上述代码中,我们使用Django的`Paginator`类来实现分页。用户可以通过指定页码来访问不同页面的搜索结果。
# 3. Taggit在不同场景下的实践应用
### 3.1 Taggit在内容管理系统中的应用
Taggit在内容管理系统(CMS)中的应用是其最常见的场景之一,它能够有效地组织和分类内容,提高用户的信息检索效率。
#### 3.1.1 标签云的实现与展示
标签云是一种通过视觉化的标签集合来展示内容频率的工具,它通常用于博客、新闻网站和论坛等在线平台。在CMS中实现标签云,可以增强用户界面的互动性,同时提供直观的内容分类视图。
**实现步骤:**
1. **创建标签云的模板页面**:首先,你需要创建一个专门用于展示标签云的页面模板。
2. **列出所有标签**:从数据库中查询出所有的标签。
3. **计算标签权重**:为每个标签分配一个权重值,通常是基于标签关联内容的数量。
4. **生成标签云数据**:根据标签权重生成相应的HTML代码。
5. **展示标签云**:在模板页面中展示生成的标签云。
**示例代码:**
```python
# Python 伪代码,用于演示生成标签云的过程
from django import template
from content.models import Tag
register = template.Library()
@register.inclusion_tag('tagcloud.html')
def show_tag_cloud():
tags = Tag.objects.all().annotate(
weight=models.ExpressionWrapper(
Count('taggit_taggeditem_items'),
output_field=models.IntegerField()
)
).order_by('-weight')
return {'tags': tags}
```
**标签权重计算与展示:**
| 标签 | 关联内容数量 | 权重 |
| --- | --- | --- |
| IT | 500 | 500 |
| 技术 | 300 | 300 |
| 新闻 | 200 | 200 |
| ... | ... | ... |
**标签云视觉化效果:**
:
tag = get_object_or_404(Tag, slug=tag_slug)
content_list = tag.taggit_taggeditem_items.all().select_related('content_object')
return render(request, 'tag_detail.html', {'tag': tag, 'content_list': content_list})
```
### 3.1.3 标签与SEO的结合
标签在CMS中的应用还可以与搜索引擎优化(SEO)相结合,通过合理的标签使用,提高内容在搜索引擎中的排名。
**实现步骤:**
1. **优化标签描述**:为每个标签撰写独特且相关的描述。
2. **使用标签元数据**:在内容页面中使用标签相关的元数据。
3. **构建内部链接**:利用标签创建内部链接,增强网站结构的深度。
4. **避免重复内容**:确保标签页面的内容不与其他页面重复。
**标签优化策略:**
| 策略 | 说明 |
| --- | --- |
| 标签描述优化 | 提供独特且相关的标签描述 |
| 元数据使用 | 在HTML中使用<meta>标签 |
| 内部链接构建 | 创建标签页面与其他内容页面的链接 |
| 避免内容重复 | 确保标签页面内容的唯一性 |
在本章节中,我们介绍了Taggit在内容管理系统中的应用,包括标签云的实现、标签聚合内容的展示以及标签与SEO的结合。通过具体的实现步骤和示例代码,我们展示了如何在CMS中有效地利用Taggit提升用户体验和搜索引擎排名。标签云的视觉化效果不仅美化了页面,还增强了用户的互动性。标签聚合内容的展示方式则为用户提供了快速找到相关内容的途径。此外,标签与SEO的结合能够进一步提升网站的可见性和访问量。本章节内容为Taggit在内容管理系统中的应用提供了详细的实践指导。
# 4. Taggit的性能优化与扩展
在本章节中,我们将深入探讨Taggit的性能优化与扩展性设计。随着系统规模的增长,性能瓶颈往往会成为开发者面临的主要挑战之一。为了确保Taggit在大规模数据下的高效运作,我们需要从数据库性能优化、缓存应用以及可扩展性设计三个方面进行考量。
## 4.1 Taggit的数据库性能优化
数据库作为存储和检索标签信息的核心组件,其性能直接影响到整个系统的响应速度和稳定性。优化数据库性能,是提升Taggit性能的关键步骤。
### 4.1.1 数据库索引的构建与优化
在数据库中,索引是提高查询效率的重要手段。对于Taggit来说,由于涉及到大量的标签关联和检索操作,合理的索引设计尤为关键。
#### 索引类型的选择
首先,我们需要确定使用何种类型的索引。通常情况下,B-tree索引适用于绝大多数情况,尤其是在标签数量较多且关联查询频繁的场景下。
```sql
CREATE INDEX idx_tag_name ON tags (name);
```
#### 索引的维护
索引虽然能提高查询效率,但也会增加写操作的成本。因此,我们需要定期维护索引,包括重建索引以保持其性能,以及删除不再使用的索引以节省资源。
```sql
-- 重建索引
ALTER TABLE tags MODIFY COLUMN name VARCHAR(255) NOT NULL;
```
### 4.1.2 查询优化策略
查询优化是数据库性能优化的另一个重要方面。通过优化查询语句,可以显著减少数据库的负载,提高响应速度。
#### 使用EXPLAIN分析查询
使用`EXPLAIN`关键字可以分析查询的执行计划,帮助我们了解查询是如何执行的,以及如何进行优化。
```sql
EXPLAIN SELECT * FROM tags WHERE name = 'example';
```
#### 优化JOIN操作
在涉及到多表关联查询时,优化JOIN操作可以提高查询效率。合理使用JOIN类型,如INNER JOIN、LEFT JOIN等,并确保JOIN条件上存在索引。
```sql
SELECT * FROM tags
JOIN tag关联表 ON tags.id = tag关联表.tag_id
WHERE tags.name = 'example';
```
### 4.1.3 数据库分表分库策略
当数据量增长到一定规模后,单一数据库可能无法满足性能要求。此时,可以通过分表分库的方式来提升性能。
#### 分表策略
分表策略包括垂直分表和水平分表。垂直分表是指将宽表拆分为多个表,每个表只包含部分列;水平分表则是将数据分散到多个结构相同的表中。
```sql
-- 水平分表示例
CREATE TABLE tags_partitioned (
id INT AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
...
) PARTITION BY HASH(id) PARTITIONS 4;
```
#### 分库策略
分库是指将数据分布到多个数据库实例中。分库可以是垂直分库,即将不同的业务数据存储在不同的数据库中;也可以是水平分库,即将相同业务的数据分散到多个数据库中。
```sql
-- 分库配置示例(伪代码)
config.add_shard('db shard 1', ['**.*.*.*:3306', '**.*.*.*:3306']);
```
## 4.2 Taggit的缓存应用
缓存是提升系统性能的另一个重要手段。通过缓存频繁访问的数据,可以减少数据库的查询次数,从而提高系统的整体性能。
### 4.2.1 标签缓存机制的实现
Taggit的标签缓存机制可以缓存标签数据,减少数据库的读取压力。我们可以使用Redis等内存数据库来实现这一机制。
#### 缓存数据结构设计
设计合理的缓存数据结构是实现高效缓存的前提。例如,可以使用哈希表来存储标签数据,键为标签ID,值为标签对象。
```python
# Python伪代码,使用Redis缓存标签数据
def get_tag_from_cache(tag_id):
cached_tag = redis.hget('tags', tag_id)
if cached_tag:
return pickle.loads(cached_tag)
else:
tag = db.get_tag_by_id(tag_id)
redis.hset('tags', tag_id, pickle.dumps(tag))
return tag
```
### 4.2.2 缓存数据的一致性维护
缓存数据的一致性维护是确保系统正确性的重要环节。在数据更新时,需要同时更新缓存中的数据。
#### 删除缓存策略
当标签数据更新时,可以通过删除缓存的方式来维护数据的一致性。
```python
def update_tag(tag_id, new_data):
db.update_tag(tag_id, new_data)
redis.delete('tags:' + tag_id)
```
### 4.2.3 缓存策略的性能评估
为了确保缓存策略的有效性,需要定期进行性能评估,分析缓存命中率、缓存失效次数等指标。
#### 性能评估工具
可以使用如`memtier_benchmark`等工具来模拟缓存读写操作,评估缓存性能。
```bash
# 使用memtier_benchmark进行性能评估
memtier_benchmark -s localhost -p 6379 -t 10 -c 10000 -r 1000 --pipeline=5
```
## 4.3 Taggit的可扩展性设计
随着业务的发展,系统的可扩展性变得尤为重要。Taggit的可扩展性设计需要考虑模块化设计、插件机制以及第三方集成。
### 4.3.1 标签系统的模块化设计
模块化设计可以帮助我们更好地维护和扩展Taggit系统。通过将系统分为多个模块,每个模块负责一部分功能,可以简化系统的复杂度。
#### 模块化架构图
```mermaid
graph LR
A[核心模块] -->|依赖| B[标签存储模块]
A -->|依赖| C[标签管理模块]
A -->|依赖| D[标签缓存模块]
B -->|实现| E[数据库接口]
C -->|实现| F[标签分类接口]
D -->|实现| G[Redis接口]
```
### 4.3.2 插件机制与第三方集成
通过提供插件机制,可以方便地引入第三方功能,如数据分析、用户行为分析等。
#### 插件加载流程
```mermaid
graph LR
A[插件加载器] --> B[加载核心插件]
A --> C[加载第三方插件]
B --> D[核心功能]
C --> E[第三方功能]
```
### 4.3.3 标签系统的可扩展实践案例
在实际应用中,我们可以根据不同的业务需求,设计和实现可扩展的标签系统。
#### 实践案例
例如,一个内容管理系统可能会根据内容类型、作者、发布时间等多种维度来扩展标签系统。
```python
# Python伪代码,扩展标签系统以支持作者维度
class TagManager:
def __init__(self):
self.tag_stores = {
'default': TagStore(),
'author': AuthorTagStore()
}
def get_tags_by_author(self, author_id):
return self.tag_stores['author'].get_tags_by_author(author_id)
```
以上就是对Taggit性能优化与扩展性设计的详细探讨。通过数据库性能优化、缓存应用以及可扩展性设计,我们可以确保Taggit在大规模数据和复杂业务场景下的高效运作。
# 5. Taggit的安全性与合规性考虑
## 5.1 Taggit的数据安全
### 5.1.1 数据加密与访问控制
Taggit作为一个用于管理标签的工具,虽然主要功能是增强内容的可检索性和分类,但在数据安全方面同样不容忽视。数据加密是保障Taggit数据安全的基础手段之一。通过对敏感数据进行加密,可以防止未授权访问和数据泄露的风险。常见的加密方式包括对称加密和非对称加密,如AES和RSA算法。
在实现数据加密时,需要考虑以下几个方面:
- **加密算法选择**:选择适合的加密算法,确保数据的安全性和性能需求。
- **密钥管理**:密钥是解密数据的关键,需要安全地生成、存储和分发密钥。
- **加密范围**:决定哪些数据需要加密,例如标签名称、关联对象的ID等。
- **访问控制**:实现基于角色的访问控制(RBAC),确保只有授权用户才能访问和修改标签数据。
例如,下面是一个简单的代码示例,展示了如何使用Python对字符串进行AES加密:
```python
from Crypto.Cipher import AES
from Crypto.Random import get_random_bytes
from Crypto.Util.Padding import pad
import base64
# 生成密钥
key = get_random_bytes(16) # AES密钥长度为16, 24或32字节
# 待加密的数据
data = 'Sensitive Tag Data'
# 对数据进行填充,使其长度符合AES块大小要求
padded_data = pad(data.encode(), AES.block_size)
# 创建AES加密器实例
cipher = AES.new(key, AES.MODE_CBC)
# 加密数据
encrypted_data = cipher.encrypt(padded_data)
# 将加密后的数据进行Base64编码,便于存储和传输
base64_encoded_data = base64.b64encode(encrypted_data).decode('utf-8')
print(f'Encrypted data (base64): {base64_encoded_data}')
```
在这个示例中,我们首先生成了一个随机的AES密钥,然后对需要加密的字符串数据进行填充,以满足AES算法对数据长度的要求。接着,我们创建了一个AES加密器实例,并使用它来加密数据。最后,我们将加密后的数据进行Base64编码,以便于存储和传输。
### 5.1.2 数据备份与恢复策略
在任何系统中,数据备份都是保障数据安全的重要手段。Taggit系统也不例外。备份策略应该定期执行,并且能够快速恢复数据,以应对意外情况,如硬件故障、软件错误或人为操作失误。
在设计备份策略时,需要考虑以下因素:
- **备份频率**:根据数据变更的频率和重要性来确定备份的频率。
- **备份类型**:可以选择全备份或增量备份,全备份备份所有数据,而增量备份只备份自上次备份以来发生变化的数据。
- **存储位置**:备份数据应该存储在安全的位置,避免与原始数据位于同一物理或虚拟环境中,以防灾难性事件影响。
- **恢复时间目标(RTO)和数据恢复点目标(RPO)**:确定在发生故障时,数据能够恢复的时间点,以及可接受的数据丢失量。
### 5.1.3 安全审计与日志分析
为了维护系统的安全性,Taggit系统需要实施安全审计和日志分析。安全审计可以定期进行,以检查系统配置和访问模式是否符合安全标准。日志分析则用于跟踪和审查用户的操作行为,以便及时发现和响应可疑活动。
安全审计和日志分析应该包括以下几个方面:
- **审计策略**:定义审计的范围、频率和责任人。
- **日志记录**:记录所有关键操作,包括用户的登录、数据访问、修改和删除操作。
- **日志存储**:确保日志文件的安全存储,防止被未授权人员访问或篡改。
- **日志分析**:使用自动化工具对日志进行分析,以便发现异常行为和潜在的安全威胁。
## 5.2 Taggit的合规性挑战
### 5.2.1 数据隐私保护法规
随着数据隐私保护法规的日益严格,如欧盟的通用数据保护条例(GDPR),Taggit系统需要确保其操作符合相关法律法规。这些法规要求对个人数据的处理提供透明度,并赋予数据主体对其个人信息的控制权。
在合规性方面,Taggit系统需要考虑以下几个方面:
- **数据最小化**:只收集和存储完成指定任务所必需的最少数据量。
- **用户同意**:在收集和处理个人数据之前,获取数据主体的明确同意。
- **数据主体权利**:确保用户能够访问、更正、删除或转移其个人数据。
- **数据泄露通知**:在发现数据泄露时,及时通知受影响的用户和监管机构。
### 5.2.2 标签内容的合规审查
在某些应用场景中,标签内容可能包含敏感信息,如个人身份信息或其他受保护的属性。因此,Taggit系统需要实施内容合规审查机制,以确保标签的使用不违反法律法规。
合规审查机制应该包括以下几个方面:
- **自动化审查**:使用自然语言处理技术自动检测和过滤敏感内容。
- **人工审查**:在必要时,由专业人员进行人工审查标签内容。
- **审查标准**:制定明确的审查标准和流程,确保一致性。
- **审查日志**:记录审查活动,以便于后续的审计和分析。
### 5.2.3 国际合规性标准与实践
由于Taggit系统可能在全球范围内使用,因此需要遵守不同国家和地区的合规性标准。这些标准可能包括数据隐私保护、跨境数据传输限制、信息安全等级保护等。
在国际合规性方面,Taggit系统需要考虑以下几个方面:
- **多法域合规性**:了解和遵守多个国家和地区的法律法规。
- **数据本地化**:在某些国家或地区,可能需要将数据存储在本地服务器上。
- **合规性评估**:定期进行合规性评估,确保系统符合最新的法规要求。
- **合规性培训**:对团队成员进行合规性培训,提高他们对相关法律和标准的认识。
在本章节中,我们探讨了Taggit在数据安全和合规性方面的考虑。数据加密和访问控制是保护敏感数据的基础,而数据备份和恢复策略则是确保数据可用性的关键。安全审计和日志分析帮助及时发现和响应安全威胁。合规性挑战要求我们不仅要遵守数据隐私保护法规,还要对标签内容进行合规审查,并考虑国际合规性标准。通过实施这些措施,我们可以确保Taggit系统在保障数据安全和遵守法律法规方面的有效性。
# 6. Taggit的未来趋势与发展方向
## 6.1 Taggit在人工智能领域的应用
随着人工智能技术的飞速发展,Taggit在这一领域的应用前景变得极为广阔。机器学习和自然语言处理技术的融合,为标签系统的自动化和智能化提供了新的可能性。
### 6.1.1 机器学习与标签自动分类
机器学习技术可以帮助Taggit系统自动识别和分类数据,减少人工干预的需求。例如,通过对大量文本数据进行训练,Taggit可以学会识别不同类型的标签,并自动将它们分类到相应的标签库中。这种自动化分类减少了手动标签的工作量,提高了效率和准确性。
```python
# 示例:简单的文本分类器
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import make_pipeline
# 假设我们有一些文本数据和对应的标签
texts = ['这是技术文章', '这是娱乐新闻', '这是科技新闻']
tags = ['技术', '娱乐', '科技']
# 创建一个简单的文本分类器
model = make_pipeline(TfidfVectorizer(), MultinomialNB())
# 训练模型
model.fit(texts, tags)
```
### 6.1.2 自然语言处理与标签生成
自然语言处理(NLP)技术可以使Taggit系统更好地理解文本内容,从而生成更加准确和相关的标签。例如,通过情感分析,系统可以识别文本的情感倾向,并据此生成情感标签。
```python
# 示例:使用NLP进行情感分析
from textblob import TextBlob
# 假设我们有一些文本数据
texts = ['我非常喜欢这篇技术文章', '这篇文章很无聊', '这篇文章内容很丰富']
# 使用TextBlob进行情感分析
for text in texts:
blob = TextBlob(text)
print(f"Text: {text}\nSentiment: {blob.sentiment.polarity}")
```
### 6.1.3 AI驱动的个性化标签推荐
人工智能还可以用于实现个性化的标签推荐。通过分析用户的浏览历史、购买行为和社交媒体活动,Taggit系统可以推荐与用户兴趣高度相关的标签,从而提升用户体验。
```python
# 示例:简单的个性化标签推荐算法
from collections import defaultdict
import numpy as np
# 假设我们有一些用户数据和商品标签
user_views = {'user1': ['技术', '科技'], 'user2': ['娱乐', '电影']}
product_tags = ['技术', '娱乐', '科技', '电影']
# 推荐算法
def recommend_tags(user, user_views, product_tags, top_n=3):
# 计算用户与标签的关联度
tag_scores = defaultdict(int)
for tag in product_tags:
for user_tag in user_views[user]:
if tag == user_tag:
tag_scores[tag] += 1
else:
tag_scores[tag] -= 0.5
# 根据分数推荐标签
recommended_tags = sorted(tag_scores, key=tag_scores.get, reverse=True)[:top_n]
return recommended_tags
# 为user1推荐标签
print(f"Recommended tags for user1: {recommend_tags('user1', user_views, product_tags)}")
```
## 6.2 Taggit的跨平台整合
跨平台整合是Taggit系统发展的另一个重要方向。随着用户使用的设备和平台日益多样化,Taggit需要能够在不同平台之间同步和整合数据。
### 6.2.1 多平台数据同步与整合
多平台数据同步确保用户在不同设备和平台上的标签信息保持一致。例如,用户在手机上创建的标签可以同步到云端,并在电脑上使用。
### 6.2.2 微服务架构下的标签管理
在微服务架构中,Taggit作为独立的服务与其他服务进行交互,提高了系统的灵活性和可扩展性。这要求Taggit能够与其他服务进行高效的数据交换和协调工作。
### 6.2.3 云原生技术在Taggit中的应用
云原生技术如容器化、微服务和持续集成/持续部署(CI/CD)可以增强Taggit的可靠性和可维护性。这些技术使Taggit能够快速适应变化,并提供更加稳定的服务。
## 6.3 Taggit的社区与开源贡献
开源社区为Taggit的发展提供了强大的动力。通过社区的贡献,Taggit可以不断吸收新的想法和技术,保持其在市场上的竞争力。
### 6.3.1 开源项目中的Taggit实践
在开源项目中,Taggit可以帮助管理文档、代码库和其他项目资源。它提供了一种高效的方式来组织和检索项目内容。
### 6.3.2 社区资源与学习路径
社区提供了丰富的资源和学习路径,帮助开发者更好地理解和使用Taggit。这些资源包括官方文档、教程、论坛和代码示例。
### 6.3.3 贡献指南与开发者生态
开源项目通常有一套明确的贡献指南,鼓励开发者参与项目贡献。这有助于形成一个健康的开发者生态,推动Taggit的长期发展。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python Taggit 库的 taggit.managers 模块,为 Python 开发人员提供了标签管理的全面指南。从快速入门到高级用法,本专栏涵盖了构建高效标签系统所需的关键概念,包括核心概念解析、性能优化、最佳实践以及与 Django 的集成。通过案例研究,本专栏展示了如何使用 taggit.managers 轻松创建标签云。无论您是刚接触 Taggit 还是寻求深入了解其高级功能,本专栏都能为您提供宝贵的见解和实践指南。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【16位加法器设计秘籍】:全面揭秘高性能计算单元的构建与优化

# 摘要
本文对16位加法器进行了全面的研究和分析。首先回顾了加法器的基础知识,然后深入探讨了16位加法器的设计原理,包括二进制加法基础、组成部分及其高性能设计考量。接着,文章详细阐述
三菱FX3U PLC编程:从入门到高级应用的17个关键技巧

# 摘要
三菱FX3U PLC是工业自动化领域常用的控制器之一,本文全面介绍了其编程技巧和实践应用。文章首先概述了FX3U PLC的基本概念、功能和硬件结构,随后深入探讨了
【Xilinx 7系列FPGA深入剖析】:掌握架构精髓与应用秘诀
# 摘要
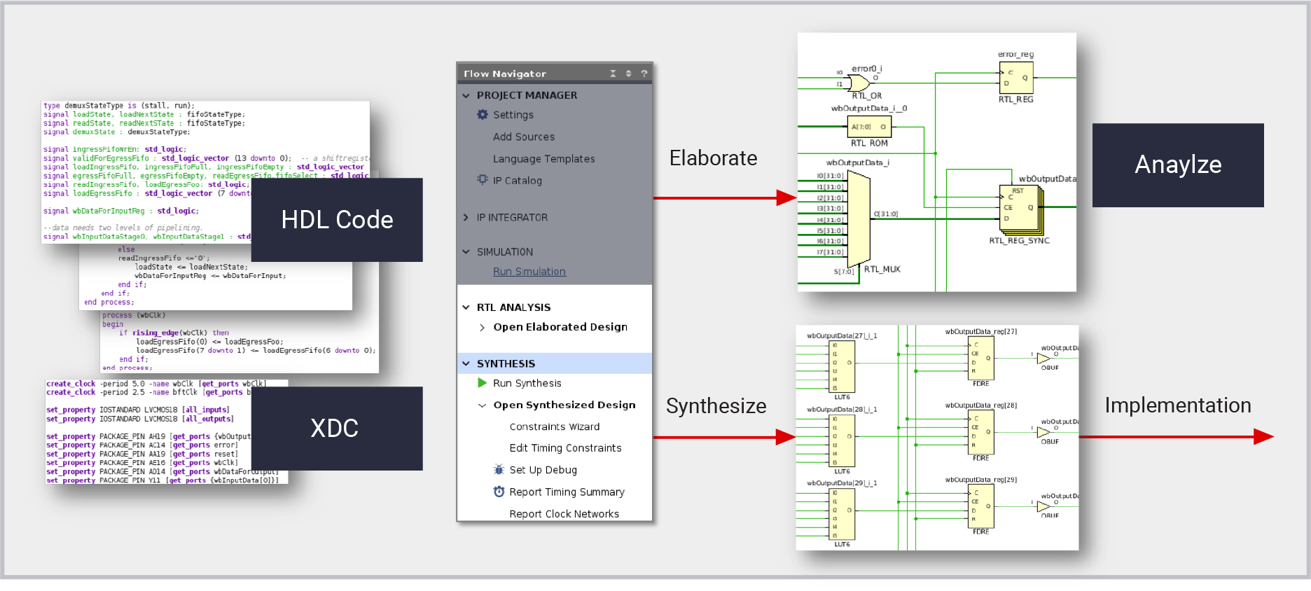
本文详细介绍了Xilinx 7系列FPGA的关键特性及其在工业应用中的广泛应用。首先概述了7系列FPGA的基本架构,包括其核心的可编程逻辑单元(PL)、集成的块存储器(BRAM)和数字信号处理(DSP)单元。接着,本文探讨了使用Xilinx工具链进行FPGA编程与配置的流程,强调了设计优化和设备配置的重要性。文章进一步分析了7系列FPGA在
【图像技术的深度解析】:Canvas转JPEG透明度保护的终极策略

# 摘要
随着Web技术的不断发展,图像技术在前端开发中扮演着越来越重要的角色。本文首先介绍了图像技术的基础和Canvas绘
【MVC标准化:肌电信号处理的终极指南】:提升数据质量的10大关键步骤与工具
# 摘要
MVC标准化是肌电信号处理中确保数据质量的重要步骤,它对于提高测量结果的准确性和可重复性至关重要。本文首先介绍肌电信号的生理学原理和MVC标准化理论,阐述了数据质量的重要性及影响因素。随后,文章深入探讨了肌电信号预处理的各个环节,包括噪声识别与消除、信号放大与滤波技术、以及基线漂移的校正方法。在提升数据质量的关键步骤部分,本文详细描述了信号特征提取、MVC标准化的实施与评估,并讨论了数据质量评估与优化工具。最后,本文通过实验设计和案例分析,展示了MVC标准化在实践应用中的具
ISA88.01批量控制:电子制造流程优化的5大策略

# 摘要
本文首先概述了ISA88.01批量控制标准,接着深入探讨了电子制造流程的理论基础,包括原材料处理、制造单元和工作站的组成部分,以及流程控制的理论框架和优化的核心原则。进一步地,本文实
【Flutter验证码动画效果】:如何设计提升用户体验的交互

# 摘要
随着移动应用的普及和安全需求的提升,验证码动画作为提高用户体验和安全性的关键技术,正受到越来越多的关注。本文首先介绍Flutter框架下验证码动画的重要性和基本实现原理,涵盖了动画的类型、应用场景、设计原则以及开发工具和库。接着,文章通过实践篇深入探讨了在Flutter环境下如何具体实现验证码动画,包括基础动画的制作、进阶技巧和自定义组件的开发。优化篇
ENVI波谱分类算法:从理论到实践的完整指南
# 摘要
ENVI软件作为遥感数据处理的主流工具之一,提供了多种波谱分类算法用于遥感图像分析。本文首先概述了波谱分类的基本概念及其在遥感领域的重要性,然后介绍了ENVI软件界面和波谱数据预处理的流程。接着,详细探讨了ENVI软件中波谱分类算法的实现方法,通过实践案例演示了像元级和对象级波谱分类算法的操作。最后,文章针对波谱分类的高级应用、挑战及未来发展进行了讨论,重点分析了高光谱数据分类和深度学习在波谱分类中的应用情况,以及波谱分类在土地覆盖制图和农业监测中的实际应用。
# 关键字
ENVI软件;波谱分类;遥感图像;数据预处理;分类算法;高光谱数据
参考资源链接:[使用ENVI进行高光谱分
【天线性能提升密籍】:深入探究均匀线阵方向图设计原则及案例分析
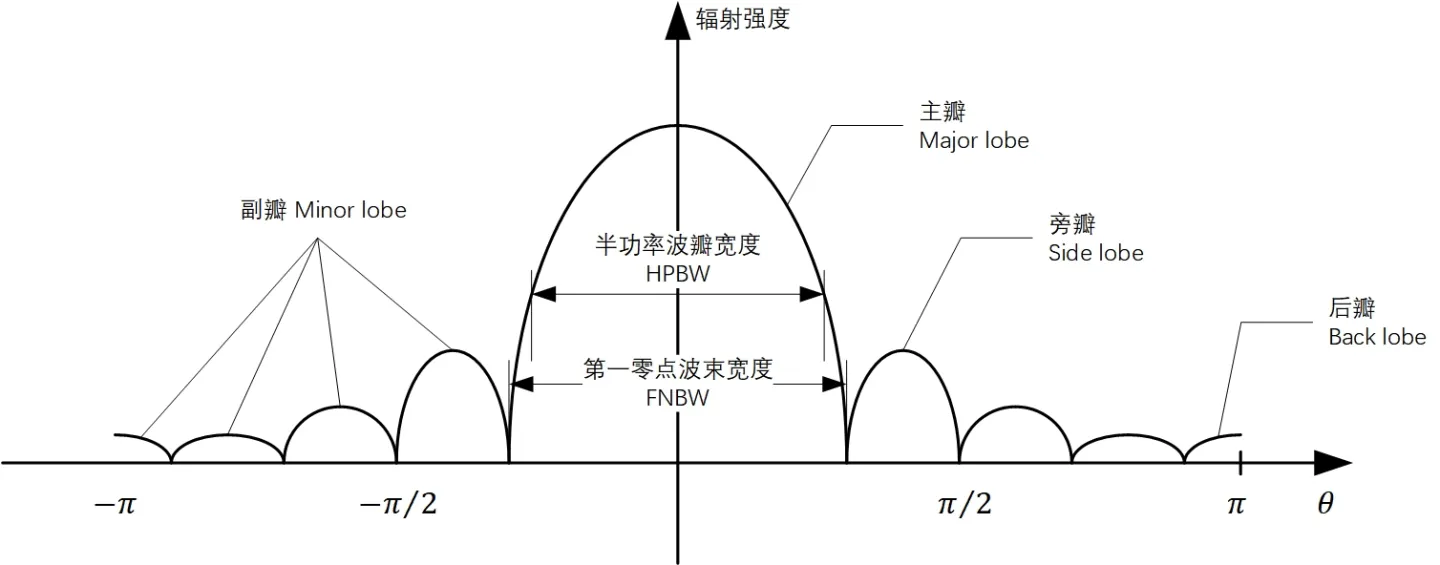
# 摘要
本文深入探讨了均匀线阵天线的基础理论及其方向图设计,旨在提升天线系统的性能和应用效能。文章首先介绍了均匀线阵及方向图的基本概念,并阐述了方向图设计的理论基础,包括波束形成与主瓣及副瓣特性的控制。随后,论文通过设计软件工具的应用和实际天线系统调试方法,展示了方向图设计的实践技巧。文中还包含了一系列案例分析,以实证研究验证理论,并探讨了均匀线阵性能
【兼容性问题】快解决:专家教你确保光盘在各设备流畅读取
/i.s3.glbimg.com/v1/AUTH_08fbf48bc0524877943fe86e43087e7a/internal_photos/bs/2021/L/w/I3DfXKTAmrqNi0rGtG5A/2014-06-24-cd-dvd-bluray.png)
# 摘要
光盘作为一种传统的数据存储介质,其兼容性问题长
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )