Python文件读写优化:提升文件读写效率,加速数据处理
发布时间: 2024-06-24 22:46:58 阅读量: 147 订阅数: 64 

Python读写文件
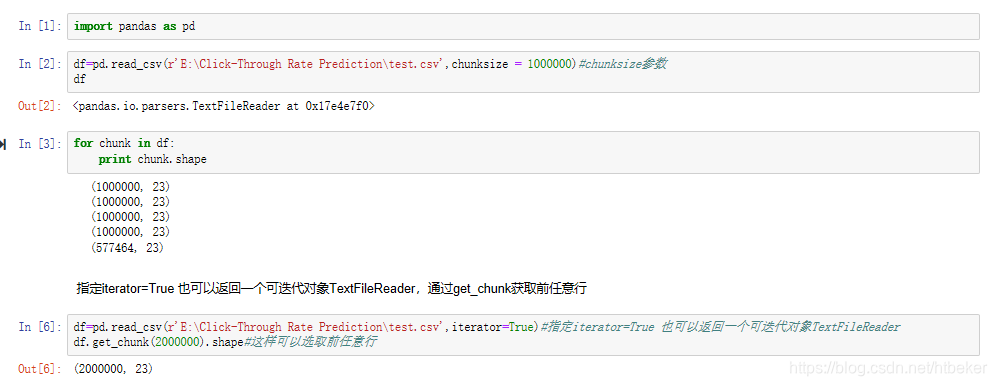
# 1. Python文件读写的基本原理
Python文件读写是操作文件内容的基本功能,理解其原理至关重要。文件读写本质上是通过操作系统提供的系统调用来实现的。在Python中,文件操作通过`open()`函数完成,它接受两个参数:文件名和读写模式。
读写模式指定了文件打开的方式,常见的模式有`'r'`(只读)、`'w'`(只写)、`'a'`(追加)和`'r+'`(读写)。不同模式下,文件的读写权限和行为有所不同。例如,`'r'`模式只能读取文件,而`'w'`模式会覆盖现有文件内容。
# 2. Python文件读写优化技巧
### 2.1 文件读写模式和缓冲区
#### 2.1.1 不同文件读写模式的对比
Python提供了多种文件读写模式,不同的模式对文件读写的效率和功能有不同的影响。常见的文件读写模式如下:
| 模式 | 描述 |
|---|---|
| `r` | 以只读模式打开文件 |
| `w` | 以只写模式打开文件,如果文件不存在则创建 |
| `a` | 以追加模式打开文件,如果文件不存在则创建 |
| `r+` | 以读写模式打开文件 |
| `w+` | 以读写模式打开文件,如果文件不存在则创建 |
| `a+` | 以读写模式打开文件,如果文件不存在则创建 |
| `x` | 以独占模式打开文件,如果文件已存在则报错 |
| `x+` | 以独占读写模式打开文件,如果文件已存在则报错 |
#### 2.1.2 缓冲区的概念和优化方法
缓冲区是计算机内存中的一块区域,用于临时存储数据。在文件读写中,缓冲区可以提高读写效率,因为它可以减少对磁盘的访问次数。
Python使用缓冲区来存储文件读写操作的数据。当执行读操作时,数据会被从磁盘读取到缓冲区中,然后从缓冲区中返回给程序。当执行写操作时,数据会被写入到缓冲区中,然后在适当的时候被刷新到磁盘上。
缓冲区的大小可以通过`buffering`参数进行设置。默认情况下,缓冲区大小为4096字节。可以通过设置`buffering`参数为0来禁用缓冲,或者设置一个更大的值来增加缓冲区大小。
增加缓冲区大小可以提高读写效率,但也会增加内存消耗。因此,需要根据实际情况进行权衡。
### 2.2 数据结构和算法选择
#### 2.2.1 数据结构的选择对读写效率的影响
数据结构的选择对文件读写的效率有很大的影响。不同的数据结构具有不同的特性,在不同的场景下有不同的优势。
常用的数据结构包括:
* **列表:**顺序存储元素,可以快速访问任意元素。
* **元组:**顺序存储元素,不可修改。
* **字典:**以键值对的形式存储元素,可以快速根据键查找元素。
* **集合:**存储不重复的元素,可以快速判断元素是否存在。
在文件读写中,选择合适的数据结构可以减少内存消耗,提高读写效率。例如,如果需要存储大量顺序数据,可以使用列表或元组。如果需要快速查找元素,可以使用字典。
#### 2.2.2 算法的优化策略
算法的优化策略也可以提高文件读写效率。常用的算法优化策略包括:
* **减少不必要的读写操作:**只读取或写入必要的最小数据量。
* **批量读写操作:**将多个读写操作合并为一次操作,减少磁盘访问次数。
* **使用索引:**为文件创建索引,可以快速定位数据。
* **使用多线程或多进程:**将文件读写操作并行化,提高效率。
### 2.3 文件系统优化
#### 2.3.1 文件系统类型和性能差异
不同的文件系统类型具有不同的性能特性。常见的文件系统类型包括:
* **NTFS:**Windows系统默认文件系统,具有良好的性能和稳定性。
* **FAT32:**旧式文件系统,性能较差,但兼容性较好。
* **EXT4:**Linux系统默认文件系统,具有良好的性能和稳定性。
选择合适的文件系统类型可以提高文件读写效率。例如,对于需要频繁读写大文件的场景,可以使用NTFS或EXT4文件系统。
#### 2.3.2 文件组织和索引优化
文件组织和索引优化可以提高文件读写的效率。常见的优化方法包括:
* **文件碎片整理:**将文件碎片整理到一起,减少磁盘寻道时间。
* **创建索引:**为文件创建索引,可以快速定位数据。
* **使用文件系统缓存:**将经常访问的文件数据缓存到内存中,提高读写速度。
# 3.1 文件读写性能测试
**3.1.1 性能测试工具和方法**
文件读写性能测试是评估文件读写操作效率的重要手段。常用的性能测试工具包括:
- **Unix Benchmarks**:一种跨平台的基准测试套件,提供文件读写性能测试模块。
- **IOzone**:一个专门用于文件系统性能测试的工具,支持多种文件读写操作的测试。
- **fio**:一个灵活且可扩展的文件系统基准测试工具,允许用户自定义测试参数。
性能测试方法包括:
- **单线程测试**:使用单个线程执行文件读写操作,测量单线程下的性能。
- **多线程测试**:使用多个线程并发执行文件读写操作,测量多线程下的性能和可扩展性。
- **随机读写测试**:模拟实际应用中随机访问文件的场景,测量随机读写性能。
- **顺序读写测试**:模拟顺序访问文件的场景,测量顺序读写性能。
**3.1.2 不同优化策略的性能对比**
通过性能测试,可以比较不同优化策略对文件读写性能的影响。例如:
| 优化策略 | 性能提升 |
|---|---|
| 使用缓冲区 | 显著提升 |
| 选择高效的数据结构 | 中等提升 |
| 优化算法 | 中等提升 |
| 优化文件系统 | 取决于文件系统类型 |
**表格 1:不同优化策略的性能提升**
**代码块:性能测试示例**
```python
import timeit
def single_thread_write(filename, size):
with open(filename, "wb") as f:
f.write(b"0" * size)
def multi_thread_write(filename, size, num_threads):
from threading import Thread
threads = []
for _ in range(num_threads):
thread = Thread(target=single_thread_write, args=(filename, size))
threads.append(thread)
for thread in threads:
thread.start()
for thread in threads:
thread.join()
# 测试单线程写性能
timeit.timeit("single_thread_write('test.bin', 1024 * 1024)", number=10)
# 测试多线程写性能
timeit.timeit("multi_thread_write('test.bin', 1024 * 1024, 4)", number=10)
```
**代码逻辑分析:**
- `single_thread_write` 函数使用单线程向文件写入指定大小的数据。
- `multi_thread_write` 函数使用多线程并发向文件写入指定大小的数据。
- `timeit` 模块用于测量函数执行时间。
通过比较 `single_thread_write` 和 `multi_thread_write` 函数的执行时间,可以评估多线程优化对文件写性能的提升。
# 4. Python文件读写高级应用
本章节主要介绍Python文件读写的高级应用,包括流处理、与数据库集成以及与云存储集成。
### 4.1 文件读写流处理
#### 4.1.1 流处理的概念和优势
流处理是一种处理数据流的范例,其中数据流是一个连续的数据项序列。流处理的优势在于它可以处理大数据量,而无需将整个数据集加载到内存中。这对于处理大型文件或实时数据流非常有用。
#### 4.1.2 流处理在文件读写中的应用
Python中可以使用`iter()`方法将文件对象转换为一个可迭代对象,从而实现流处理。以下代码演示了如何使用流处理读取文件:
```python
with open("large_file.txt", "r") as f:
for line in f:
# 处理每一行
pass
```
流处理还可以用于写入文件,如下所示:
```python
with open("large_file.txt", "w") as f:
for line in data:
f.write(line)
```
### 4.2 文件读写与数据库集成
#### 4.2.1 文件数据与数据库的交互
文件数据和数据库数据之间可以进行交互,以实现数据存储和管理的互补性。文件可以作为数据库数据的备份或补充,也可以作为数据库操作的输入或输出。
#### 4.2.2 文件读写作为数据库操作的补充
文件读写可以作为数据库操作的补充,例如:
* **数据导出:**将数据库中的数据导出到文件中,以便进行备份或进一步分析。
* **数据导入:**从文件中导入数据到数据库中,以更新或补充现有数据。
* **数据转换:**将数据库中的数据转换为不同的格式,并将其保存到文件中。
### 4.3 文件读写与云存储集成
#### 4.3.1 云存储的概念和优势
云存储是一种将数据存储在远程服务器上的服务。云存储的优势在于它提供了高可用性、可扩展性和成本效益。
#### 4.3.2 文件读写与云存储的结合应用
Python可以与各种云存储服务集成,例如Amazon S3、Microsoft Azure Blob Storage和Google Cloud Storage。以下代码演示了如何使用Python将文件上传到Amazon S3:
```python
import boto3
# 创建S3客户端
s3 = boto3.client("s3")
# 上传文件到S3
s3.upload_file("local_file.txt", "my-bucket", "remote_file.txt")
```
# 5. Python文件读写高级应用
### 5.1 文件读写流处理
#### 5.1.1 流处理的概念和优势
流处理是一种处理数据流的计算范例,它允许应用程序在数据生成时对其进行实时处理,而无需等待数据全部收集完成。与批处理相比,流处理具有以下优势:
- **实时性:**流处理可以立即处理数据,从而实现对事件的快速响应。
- **可扩展性:**流处理可以处理大量数据流,即使数据量不断增长。
- **容错性:**流处理系统通常具有容错机制,可以处理数据丢失或损坏的情况。
#### 5.1.2 流处理在文件读写中的应用
在文件读写中,流处理可以用于以下场景:
- **实时日志分析:**将日志文件作为数据流,实时分析日志事件,检测异常或安全问题。
- **数据管道:**将文件数据作为输入流,通过一系列处理步骤,将其转换为所需的格式或存储到其他系统中。
- **数据流式传输:**将文件数据作为输出流,将其传输到其他应用程序或设备进行进一步处理或显示。
### 5.2 文件读写与数据库集成
#### 5.2.1 文件数据与数据库的交互
文件数据与数据库可以相互交互,实现数据共享和处理:
- **文件数据导入数据库:**将文件数据加载到数据库中,以供查询和分析。
- **数据库数据导出到文件:**将数据库数据导出到文件中,以进行备份、存档或进一步处理。
- **文件数据作为数据库视图:**将文件数据作为数据库视图,允许用户查询文件数据而无需直接访问文件。
#### 5.2.2 文件读写作为数据库操作的补充
文件读写可以作为数据库操作的补充,提供以下好处:
- **数据存储扩展:**当数据库容量不足时,可以将数据存储到文件中,作为数据库的扩展。
- **数据备份:**定期将数据库数据备份到文件中,以防止数据丢失。
- **数据分析:**将数据库数据导出到文件中,以便使用外部工具进行分析或处理。
### 5.3 文件读写与云存储集成
#### 5.3.1 云存储的概念和优势
云存储是一种通过互联网访问存储和管理数据的服务。与本地存储相比,云存储具有以下优势:
- **可访问性:**数据可以从任何有互联网连接的地方访问。
- **可扩展性:**云存储可以根据需要自动扩展或缩小。
- **可靠性:**云存储提供冗余和备份机制,确保数据的安全性和可用性。
#### 5.3.2 文件读写与云存储的结合应用
文件读写与云存储可以结合使用,实现以下场景:
- **文件存储和备份:**将文件存储到云存储中,作为本地存储的备份或扩展。
- **文件共享:**通过云存储共享文件,允许多个用户同时访问和协作。
- **文件流式传输:**将文件数据从云存储流式传输到应用程序或设备,以进行实时处理或显示。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在深入探讨 Python 文件读写、数据结构、算法、网络编程、数据库优化等核心技术。通过深入浅出的讲解和丰富的实战案例,帮助读者全面掌握 Python 编程中的关键技能。从基础概念到进阶技巧,本专栏提供了一条清晰的学习路径,让读者能够快速提升编程能力。无论你是初学者还是经验丰富的开发者,都能在这里找到有价值的知识和实用的解决方案,助力你的 Python 编程之旅。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
无线通信的黄金法则:CSMA_CA与CSMA_CD的比较及实战应用

# 摘要
本文系统地探讨了无线通信中两种重要的载波侦听与冲突解决机制:CSMA/CA(载波侦听多路访问/碰撞避免)和CSMA/CD(载波侦听多路访问/碰撞检测)。文中首先介绍了CSMA的基本原理及这两种协议的工作流程和优劣势,并通过对比分析,深入探讨了它们在不同网络类型中的适用性。文章进一步通
Go语言实战提升秘籍:Web开发入门到精通

# 摘要
Go语言因其简洁、高效以及强大的并发处理能力,在Web开发领域得到了广泛应用。本文从基础概念到高级技巧,全面介绍了Go语言Web开发的核心技术和实践方法。文章首先回顾了Go语言的基础知识,然后深入解析了Go语言的Web开发框架和并发模型。接下来,文章探讨了Go语言Web开发实践基础,包括RES
【监控与维护】:确保CentOS 7 NTP服务的时钟同步稳定性
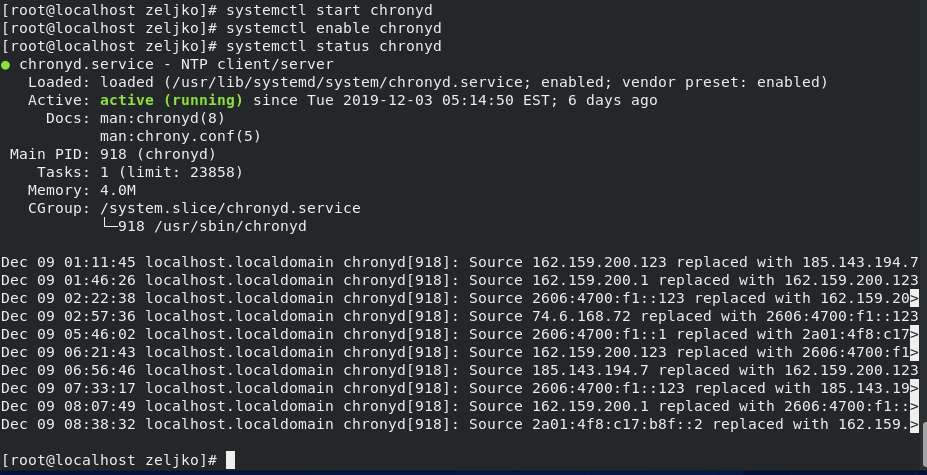
# 摘要
本文详细介绍了NTP(Network Time Protocol)服务的基本概念、作用以及在CentOS 7系统上的安装、配置和高级管理方法。文章首先概述了NTP服务的重要性及其对时间同步的作用,随后深入介绍了在CentOS 7上NTP服务的安装步骤、配置指南、启动验证,以及如何选择合适的时间服务器和进行性能优化。同时,本文还探讨了NTP服务在大规模环境中的应用,包括集
【5G网络故障诊断】:SCG辅站变更成功率优化案例全解析
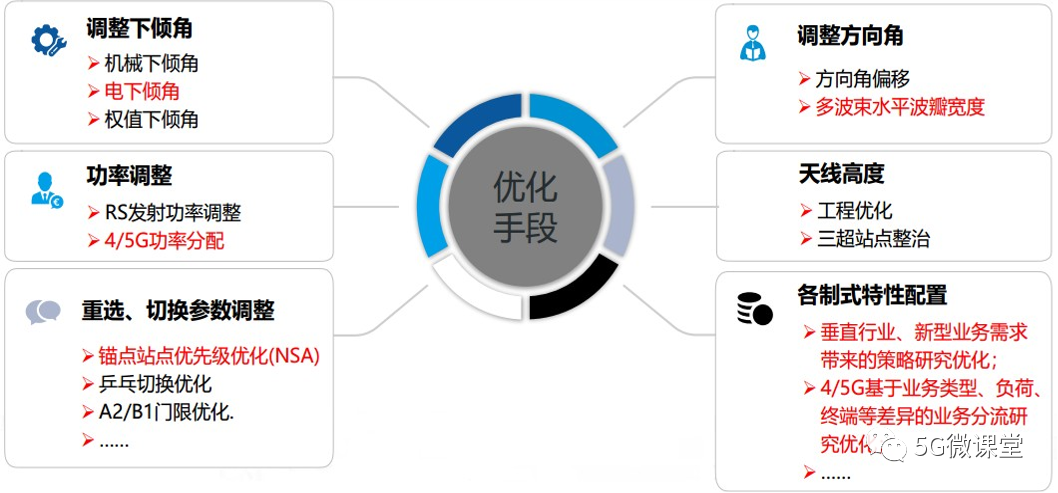
# 摘要
随着5G网络的广泛应用,SCG辅站作为重要组成部分,其变更成功率直接影响网络性能和用户体验。本文首先概述了5G网络及SCG辅站的理论基础,探讨了SCG辅站变更的技术原理、触发条件、流程以及影响成功率的因素,包括无线环境、核心网设备性能、用户设备兼容性等。随后,文章着重分析了SCG辅站变更成功率优化实践,包括数据分析评估、策略制定实施以及效果验证。此外,本文还介绍了5
PWSCF环境变量设置秘籍:系统识别PWSCF的关键配置

# 摘要
本文全面阐述了PWSCF环境变量的基础概念、设置方法、高级配置技巧以及实践应用案例。首先介绍了PWSCF环境变量的基本作用和配置的重要性。随后,详细讲解了用户级与系统级环境变量的配置方法,包括命令行和配置文件的使用,以及环境变量的验证和故障排查。接着,探讨了环境变量的高级配
掌握STM32:JTAG与SWD调试接口深度对比与选择指南

# 摘要
随着嵌入式系统的发展,调试接口作为硬件与软件沟通的重要桥梁,其重要性日益凸显。本文首先概述了调试接口的定义及其在开发过程中的关键作用。随后,分别详细分析了JTAG与SWD两种常见调试接口的工作原理、硬件实现以及软件调试流程。在此基础上,本文对比了JTAG与SWD接口在性能、硬件资源消耗和应用场景上的差异,并提出了针对STM32微控制器的调试接口选型建议。最后,本文探讨
ACARS社区交流:打造爱好者网络

# 摘要
ACARS社区作为一个专注于ACARS技术的交流平台,旨在促进相关技术的传播和应用。本文首先介绍了ACARS社区的概述与理念,阐述了其存在的意义和目标。随后,详细解析了ACARS的技术基础,包括系统架构、通信协议、消息格式、数据传输机制以及系统的安全性和认证流程。接着,本文具体说明了ACARS社区的搭
Paho MQTT消息传递机制详解:保证消息送达的关键因素
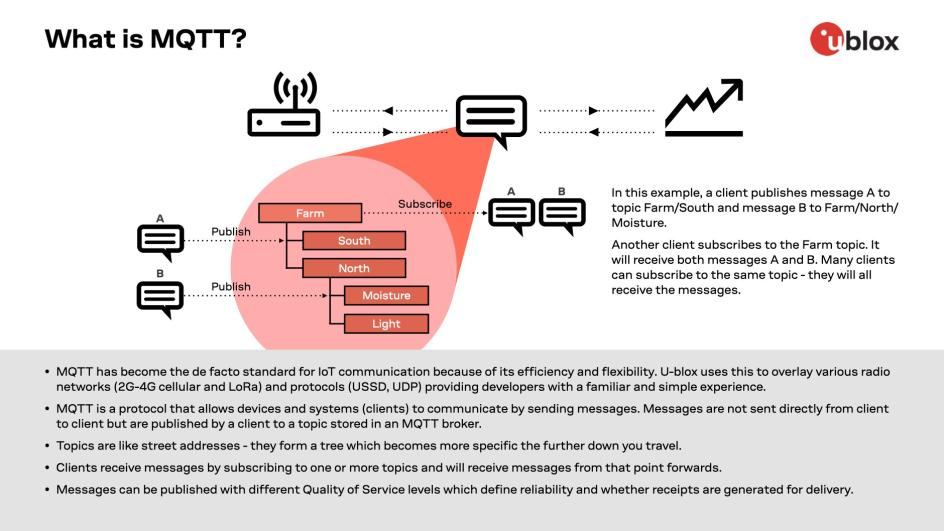
# 摘要
本文深入探讨了MQTT消息传递协议的核心概念、基础机制以及保证消息送达的关键因素。通过对MQTT的工作模式、QoS等级、连接和会话管理的解析,阐述了MQTT协议的高效消息传递能力。进一步分析了Paho MQTT客户端的性能优化、安全机制、故障排查和监控策略,并结合实践案例,如物联网应用和企业级集成,详细介绍了P
保护你的数据:揭秘微软文件共享协议的安全隐患及防护措施{安全篇

# 摘要
本文对微软文件共享协议进行了全面的探讨,从理论基础到安全漏洞,再到防御措施和实战演练,揭示了协议的工作原理、存在的安全威胁以及有效的防御技术。通过对安全漏洞实例的深入分析和对具体防御措施的讨论,本文提出了一个系统化的框架,旨在帮助IT专业人士理解和保护文件共享环境,确保网络数据的安全和完整性。最
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )