




【数据整合流程优化】:合并查询结果的艺术与科学


数据分析的试金石:A/B测试的科学与艺术
摘要
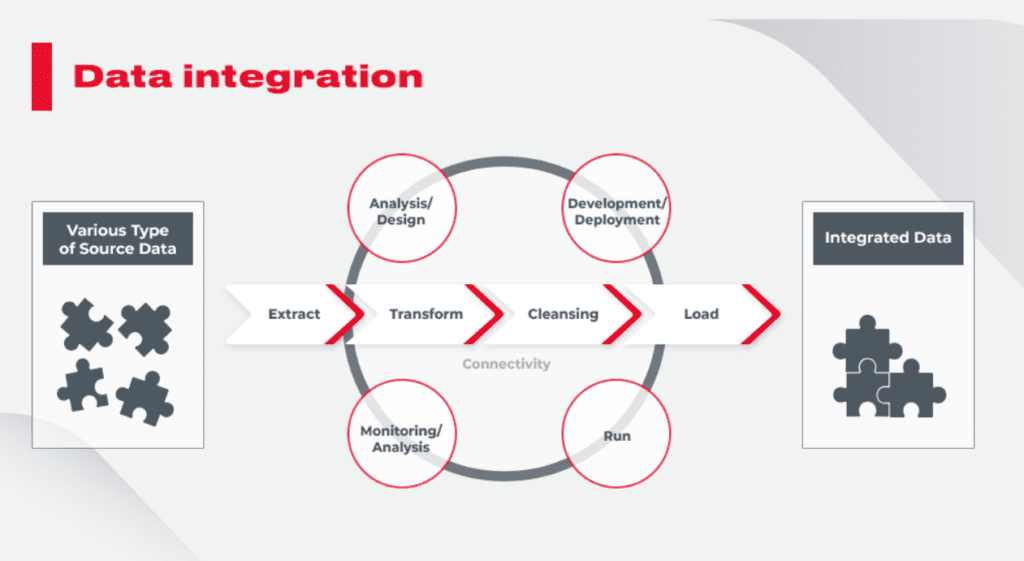
数据整合是数据科学和信息管理中的关键步骤,涉及从多个源收集、合并和清洗数据。本文介绍了数据整合流程的基础知识,强调了高效数据合并的理论基础,包括数据模型与关系、数据一致性与完整性,以及查询优化与性能提升。文章还探讨了实践中的具体技巧,如数据预处理、合并查询的实现和大数据集处理策略。此外,本文还分析了自动化和标准化在数据整合流程中的作用,以及面对人工智能应用、非结构化数据处理以及云计算环境所带来的未来趋势和挑战。
关键字
数据整合;数据模型;关系型数据库;查询优化;数据预处理;自动化ETL;标准规范;大数据处理;人工智能;云计算安全
参考资源链接:SQL教程:UNION操作符在DM数据库中的应用
1. 数据整合流程的基础知识
数据整合流程作为IT行业中的重要环节,涉及从不同数据源提取、转换、整合并加载(ETL)数据以供分析、报告和决策支持使用。该流程的基础知识包括数据源的识别、数据质量的评估、数据转换的需求分析,以及数据整合的目标定义。在处理数据整合流程时,首先需要了解数据模型的基本概念,例如实体-关系模型(ER模型),它是理解数据在数据库中如何组织的关键。其次,掌握关系型数据库中的数据关联,比如主键和外键如何实现表之间的连接关系,这对于创建有效的数据整合策略至关重要。在下一章节中,我们将深入探讨高效数据合并的理论基础,以及优化数据整合流程的具体实践技巧。
2. 高效数据合并的理论基础
2.1 数据模型与关系
2.1.1 数据模型的基本概念
数据模型是一套用于描述数据结构、数据操作和数据约束的规范,它是数据管理和操作的基础。在数据整合过程中,理解并正确应用数据模型是实现高效数据合并的前提。数据模型通常由三个核心部分组成:数据结构、数据操作和数据约束。数据结构定义了数据的类型、关系和组织方式,数据操作涉及对数据进行增加、删除、修改等行为,而数据约束则确保数据的一致性和正确性。
2.1.2 关系型数据库中的数据关联
关系型数据库是一种基于关系模型的数据库,其中数据以行和列的形式存储在表中。表之间的数据关联是通过共有的字段(键)来实现的。在关系型数据库中,主键(Primary Key)用于唯一标识表中的每一行,外键(Foreign Key)则用于建立表之间的链接,确保数据的关联性和完整性。通过SQL中的JOIN操作,可以实现不同表之间基于键的关联查询,是实现复杂数据合并的基础。
2.2 数据一致性与完整性
2.2.1 一致性保持的策略
数据一致性指的是数据在多个操作中保持一致的状态,不会出现矛盾或错误。保持数据一致性的策略包括事务控制、约束设置和触发器等。事务控制确保一系列操作要么全部成功,要么全部失败,从而维持数据状态的正确性。在数据库中设置适当的约束(如主键、外键、唯一性、检查约束等)可以预防无效或不一致的数据输入。触发器是一种特殊类型的存储过程,它会在特定的数据库事件发生时自动执行,用于在数据更新前后进行额外的检查和操作,从而维护数据的一致性。
2.2.2 完整性约束的重要性
完整性约束是数据库设计中用于维护数据准确性和一致性的规则。它确保了数据在进行增删改操作时,不会破坏数据的逻辑一致性。完整性约束包括实体完整性、参照完整性和用户定义完整性。实体完整性保证了主键字段的唯一性;参照完整性通过外键约束确保了表间数据的关联性;用户定义完整性则允许数据库管理员根据业务需求设定其他约束条件。缺失这些约束可能导致数据冗余、不一致,甚至业务逻辑上的错误。
2.3 查询优化与性能提升
2.3.1 查询计划分析
查询计划是数据库管理系统(DBMS)在执行一个查询时所使用的详细步骤和操作序列。理解查询计划对于优化查询性能至关重要。查询计划分析包括识别查询中使用的索引、JOIN操作的顺序和类型、表扫描与索引扫描的选择、排序和分组操作的处理方式等。在关系型数据库中,查询优化器根据统计信息和成本模型来生成查询计划,并选择成本最低的执行路径。开发者可以通过查询分析器等工具来审查和理解特定查询的执行计划。
2.3.2 性能调优技巧
性能调优的目标是提高数据库查询的效率,减少响应时间,并提升系统整体性能。性能调优可以从多个方面入手,包括但不限于索引优化、查询重写、资源管理、硬件升级等。通过创建适当的索引可以显著提高查询的响应速度,尤其是在处理大型数据集时。查询重写意味着改写SQL语句以减少资源消耗,比如避免使用全表扫描、优化JOIN条件和减少不必要的计算等。合理地分配系统资源和定期进行维护也是提高性能的有效手段。在必要时,还可以考虑硬件升级来支撑更高效的数据库操作。
- -- 一个简单的JOIN操作示例
- SELECT orders.*, customers.*
- FROM orders
- JOIN customers ON orders.customer_id = customers.id;
上述SQL语句演示了一个基本的内连接(INNER JOIN)操作,它用于合并orders和customers两个表的数据。在实际的查询优化过程中,分析和理解类似JOIN操作的执行计划,以及如何根据这些计划调整查询语句,是提升数据库性能的关键步骤。
在本章节中,我们探讨了数据合并的理论基础,包括数据模型、关系、一致性和完整性的重要性,以及查询优化和性能提升的策略。这些知识构成了数据整合流程的基石,对实现高效和稳定的数据合并至关重要。在下一章节中,我们将深入探讨数据整合实践技巧,包括数据预处理、合并查询的实现,以及处理大数据集的策略。
3. 数据整合实践技巧
数据整合不仅仅是一个理论概念,它还包含了丰富的实践技巧和方法论。在这一章节中,我们将深入了解如何执行高效的数据预处理,合并查询,并探索处理大数据集的策略。
3.1 数据预处理方法
数据预处理是数据整合流程的首要步骤,它确保了输入数据的质量,为后续的数据处理和分析工作奠定基础。
3.1.1 数据清洗技术
数据清洗涉及识别和修正(或删除)数据中的错误和不一致性,这通常包含以下几个关键的子步骤:
- 去除重复记录:重复数据会干扰分析结果,因此在整合之前需要被识别和剔除。
- 纠正错误:数据集中的拼写错误、不规范的数据格式、异常值都需要被纠正。
- 处理缺失值:缺失数据可能会影响分析结果的准确性,预处理阶段需要填补或剔除这些缺失数据。
下面是一个简单Python代码示例,用于识别和处理数据集中的重复记录:
- import pandas as pd
- # 假设df是一个pandas DataFrame,包含需要处理的数据
- # 识别重复记录
- duplicates = df[df.duplicated()]
- # 删除重复记录
- df_cleaned = df.drop_duplicates()
- # 检查处理后的数据集
- print(df_cleaned.head())
在上述代码块中,duplicated() 函数帮助我们找出重复的记录,并将其存储在变量 duplicates 中。使用 drop_duplicates() 函数,我们可以去除这些重复记录,并将清理后的数据集存储在 df_cleaned 中。这种方法是数据预处理中常见的操作,能有效提升数据质量。
3.1.2 数据格式化和转换
数据格式化和转换是另一个关键的数据预处理步骤,

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐

专栏目录

文章持续更新中,敬请期待~
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【FLUKE_8845A_8846A深度剖析】:揭秘5大高级功能与高效应用策略
【地理信息系统实用指南】:10个技巧助你精通高德地图API
时间序列分析:用R语言进行精准预测与建模的策略
无线网络设计与优化:顶尖专家的理论与实践
快速排序性能提升:在多核CPU环境下实现并行化的【秘诀】
【虚拟网络环境的性能优化】:eNSP结合VirtualBox的最佳实践
【权威指南】:掌握AUTOSAR BSW模块,专家级文档解读
MSP430与HCSR04超声波模块的距离计算优化方法
EPLAN高级功能解锁:【条件化内容】:提升设计质量的创新方法


专栏目录
文章持续更新中,敬请期待~
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















