C#索引器深度剖析:掌握高级特性,实现最佳实践
发布时间: 2024-10-18 21:02:27 阅读量: 22 订阅数: 20 
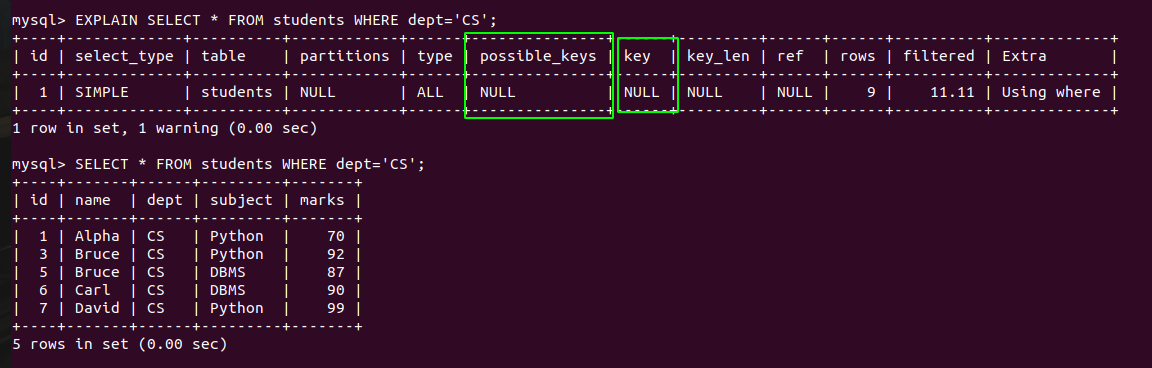
# 1. C#索引器基础
索引器是C#编程语言中的一种特殊属性,它允许对象被像数组一样索引。通过定义一个索引器,类或结构可以使用方括号([])语法访问集合中的元素。它是面向对象编程中的一个非常实用的特性,使代码更加直观和易于理解。了解索引器的基础知识对于有效使用C#进行开发是至关重要的。本章将从基础概念入手,为您介绍索引器的定义、使用和简单实现,为后续章节中更高级的用法打下坚实的基础。
# 2. 索引器的高级特性
## 2.1 索引器的参数和返回类型
### 2.1.1 参数的种类和选择
在C#中,索引器的参数可以是任何类型,这为设计自定义集合提供了极大的灵活性。参数通常用于定义访问集合中元素的方式。例如,一个索引器可以接受一个整数索引来访问数组中的元素,或者接受两个整数索引来访问二维数组中的元素。对于更复杂的集合类型,参数也可以是字符串、自定义类型或者其他复杂的类型。
选择合适的参数类型对于设计易于使用的索引器至关重要。例如,如果索引器被用于字典类型的数据结构中,那么使用字符串或自定义的键类型作为参数,将比使用整数索引更加直观。
#### 代码分析
下面的代码示例展示了一个带有整数和字符串参数的索引器的实现:
```csharp
public class CustomCollection<T>
{
private Dictionary<string, T> _dictionary = new Dictionary<string, T>();
public T this[string key]
{
get { return _dictionary[key]; }
set { _dictionary[key] = value; }
}
public T this[int index]
{
get { return _dictionary.ElementAt(index).Value; }
set { _dictionary.Add(index.ToString(), value); }
}
}
```
在这段代码中,`CustomCollection<T>`类有两个索引器。第一个接受一个字符串参数,它对应于字典中的键。第二个接受一个整数参数,它通过`ElementAt`方法来获取与字典中键对应的值,但这里为了演示,我们假设它将整数索引用作键的一部分。这样的设计允许开发者通过不同的方式访问集合中的元素。
### 2.1.2 返回值类型的重要性
索引器的返回值类型决定了可以从中获取什么类型的数据。通常,返回值类型应与集合中存储的数据类型一致,但也可以通过返回接口或基类来提供更大的灵活性。例如,一个集合可能存储`Person`对象,但其索引器可能返回一个`IIdentifiable`接口,这样就可以返回该对象的基本信息。
#### 代码分析
以下代码展示了一个索引器返回一个接口的示例:
```csharp
public interface IIdentifiable
{
string Id { get; }
string Name { get; }
}
public class Person : IIdentifiable
{
public string Id { get; set; }
public string Name { get; set; }
// other properties and methods
}
public class PersonCollection
{
private List<Person> _persons = new List<Person>();
public IIdentifiable this[int index]
{
get { return _persons[index]; }
}
}
```
在这个例子中,`PersonCollection`类的索引器返回一个`IIdentifiable`接口实例。这允许调用者以一个更通用的方式访问对象的标识信息,而不是直接访问`Person`类的所有属性。这样做的好处是增加了代码的可维护性和扩展性,因为如果将来`IIdentifiable`接口需要添加新方法或属性,`PersonCollection`不需要做出改变。
## 2.2 泛型索引器的应用
### 2.2.1 泛型索引器的基本概念
泛型在C#中是一种强大的特性,它允许在定义类、方法、接口等时使用类型参数。泛型索引器是指索引器使用泛型类型参数作为其操作的数据的类型。这样做的好处是能够创建适用于多种类型的数据结构,增加代码的复用性,并且在编译时提供类型安全的保证。
#### 代码分析
以下是一个使用泛型索引器的简单例子:
```csharp
public class GenericCollection<T>
{
private List<T> _items = new List<T>();
public T this[int index]
{
get { return _items[index]; }
set { _items[index] = value; }
}
}
```
在这个例子中,`GenericCollection<T>`是一个泛型集合类,它有一个泛型索引器。这个类可以用于存储任何类型的对象,例如`int`、`string`、`Person`等。
### 2.2.2 泛型索引器在集合中的应用
泛型索引器在集合类中非常有用,特别是当集合需要支持多种数据类型时。通过使用泛型,开发者可以创建既灵活又类型安全的数据结构。
#### 代码分析
```csharp
public class MyGenericList<T> : List<T>
{
public new T this[int index]
{
get { return base[index]; }
set { base[index] = value; }
}
}
```
在上述代码中,`MyGenericList<T>`继承自`List<T>`。我们通过重写索引器来提供额外的逻辑处理。如果`List<T>`支持泛型,那么`MyGenericList<T>`也继承了这个特性,因此它也是一个泛型集合。这使得`MyGenericList<T>`能够支持任何类型的数据,而调用者在编译时就能享受到类型检查的好处。
## 2.3 索引器与属性的对比
### 2.3.1 属性和索引器的异同
属性和索引器都是一种访问封装数据的方式。属性提供了对单个数据项的访问,而索引器则允许通过参数列表访问数据项的集合。简单来说,属性可以看作是一个特殊形式的索引器,只不过索引器可以有多个参数,而属性没有。
#### 表格对比
| 特性 | 属性 Property | 索引器 Indexer |
|------------|------------------------------|------------------------------------|
| 访问方式 | 通过成员名访问 | 通过索引操作符访问 |
| 参数数量 | 无参数,或有get/set访问器 | 可以有多个参数 |
| 用途 | 访问或设置单个数据项 | 访问或设置一个数据集中的特定项 |
| 示例 | public int Age { get; set; } | public T this[int index] { get; set; } |
### 2.3.2 如何在设计时选择使用属性还是索引器
在选择使用属性还是索引器时,主要考虑数据访问的模式。如果数据访问模式类似与访问数组或集合中的元素,那么索引器是更合适的选择。如果数据访问模式更像是访问一个单一的数据字段,那么应该使用属性。
#### 代码分析
```csharp
public class Person
{
// 使用属性
public string Name { get; set; }
// 使用索引器,例如可以通过索引器访问某个人的某一年龄组
private Dictionary<int, string> ageGroups = new Dictionary<int, string>();
public string this[int age]
{
get { return ageGroups.ContainsKey(age) ? ageGroups[age] : null; }
set { ageGroups[age] = value; }
}
}
```
在这个例子中,`Name`属性表示一个人的名字,这是一个单一的数据字段,因此使用属性访问更合适。而`ageGroups`集合存储了与年龄相关的标签,每一年龄对应一个标签,因此我们使用索引器来访问这些数据,从而模拟了数组或字典的行为。
在实际设计中,开发者应该根据实际需求选择最适合的方式。属性提供了一种简洁和直接的方式来访问单个数据项,而索引器则为访问集合中的数据提供了灵活性。
# 3. C#索引器的实现技巧
## 3.1 实现自定义集合的索引器
### 3.1.1 设计一个可索引的集合类
在C#中实现一个可索引的集合类是一个常见的需求,特别是在处理需要快速访问的数据集合时。索引器允许集合类的实例像数组一样使用索引访问元素。下面是一个简单的自定义集合类的示例,它包含一个整数数组,并通过索引器进行访问。
```csharp
public class IndexedCollection
{
private int[] _items;
public IndexedCollection(int size)
{
_items = new int[size];
}
public int this[int index]
{
get
{
if (index < 0 || index >= _items.Length)
{
throw new ArgumentOutOfRangeException(nameof(index));
}
return _items[index];
}
set
{
if (index < 0 || index >= _items.Length)
{
throw new ArgumentOutOfRangeException(nameof(index));
}
_items[index] = value;
}
}
}
```
索引器 `this[int index]` 允许我们使用类似 `collection[index]` 的语法访问集合中的元素。在上面的例子中,索引器被设置为私有成员数组 `_items` 的索引访问器。
### 3.1.2 索引器的性能优化
在实现索引器时,性能是一个重要的考虑因素。确保索引器的性能,需要关注以下几个方面:
- 确保索引器的实现尽可能简洁,避免在索引器中执行复杂的逻辑。
- 在索引器的get和set访问器中,检查索引的有效性是必要的,但应尽量减少检查的次数,或将其放置在索引器外部进行。
- 如果索引器访问的数据需要频繁修改,考虑使用数据结构来优化性能,例如使用哈希表来实现键到值的映射。
```csharp
public int this[string key]
{
get
{
if (_dictionary.TryGetValue(key, out int value))
{
return value;
}
throw new KeyNotFoundException("The key " + key + " was not found in the collection.");
}
set
{
_dictionary[key] = value;
}
}
```
在上述示例中,我们使用了一个私有的字典 `_dictionary` 来存储键值对,索引器通过键访问值,提高了访问的效率。
## 3.2 索引器的重载与扩展
### 3.2.1 索引器重载的原则和技巧
索引器重载允许为同一类定义多个索引器,以支持不同的索引类型或参数数量。在重载索引器时,必须确保它们的签名不同,以便编译器能够根据提供的参数来区分它们。
```csharp
public class MultiDimensionalCollection
{
private int[,] _matrix;
public MultiDimensionalCollection(int rows, int cols)
{
_matrix = new int[rows, cols];
}
public int this[int row, int col] => _matrix[row, col];
public int this[long row, long col] => _matrix[(int)row, (int)col];
}
```
在这个例子中,我们定义了一个二维矩阵集合类,重载了两个索引器:一个使用 `int` 类型的索引,另一个使用 `long` 类型的索引。注意,`long` 类型的索引器在返回值前会将索引值转换为 `int` 类型,因为内部数据结构 `int[,]` 仅支持 `int` 索引。
### 3.2.2 索引器的扩展方法
扩展方法是C#中一种强大的特性,允许你为现有的类型添加新的方法,而不必修改原始类型。为索引器添加扩展方法可以进一步增强集合的可用性。
```csharp
public static class CollectionExtensions
{
public static void Add<T>(this T[] array, T element)
{
Array.Resize(ref array, array.Length + 1);
array[array.Length - 1] = element;
}
}
```
在上面的代码中,我们为数组类型 `T[]` 添加了一个名为 `Add` 的扩展方法。这样,任何数组实例都可以使用 `array.Add(newElement)` 的语法来添加元素了。需要注意的是,扩展方法不能用于索引器本身,但可以用于那些索引器使用的类型。
## 3.3 索引器与LINQ集成
### 3.3.1 索引器在LINQ查询中的作用
LINQ(语言集成查询)是C#中用于以声明性的方式操作数据的一组技术。索引器可以与LINQ集成,使得数据集合更加易于操作和查询。
```csharp
var collection = new IndexedCollection(10);
// 使用LINQ查询获取大于5的所有元素
var query = from item in collection
where item > 5
select item;
```
在这个例子中,我们通过LINQ查询语句 `where` 来查询集合中所有大于5的元素。如果我们的 `IndexedCollection` 类实现了 `IEnumerable<T>` 接口,那么它就可以直接用于LINQ查询。
### 3.3.2 实现可查询的数据结构
在C#中,要使自定义的数据结构支持LINQ查询,通常需要实现 `IEnumerable<T>` 或 `IQueryable<T>` 接口。以下是一个简单的可查询集合的实现示例:
```csharp
public class QueryableCollection<T> : IEnumerable<T>
{
private List<T> _items = new List<T>();
public void Add(T item)
{
_items.Add(item);
}
public IEnumerator<T> GetEnumerator()
{
return _items.GetEnumerator();
}
IEnumerator IEnumerable.GetEnumerator()
{
return GetEnumerator();
}
}
```
通过实现 `IEnumerable<T>` 接口,`QueryableCollection<T>` 现在可以用于LINQ查询:
```csharp
var queryableCollection = new QueryableCollection<int>();
queryableCollection.Add(3);
queryableCollection.Add(5);
queryableCollection.Add(8);
var results = from item in queryableCollection
where item > 4
select item;
foreach (var item in results)
{
Console.WriteLine(item);
}
```
这样,`QueryableCollection<int>` 就可以作为查询的数据源了。通过实现 `IEnumerable<T>` 或 `IQueryable<T>`,索引器的集合不仅限于快速访问,还可以实现复杂的查询操作。
# 4. 索引器最佳实践案例分析
在深入理解了C#索引器的基本概念、高级特性和实现技巧之后,我们即将步入本章的核心部分——最佳实践案例分析。在本章中,我们将探索索引器在现实世界中的应用,展示它们如何在各种场景下为开发者提供便利和性能上的提升。
## 4.1 索引器在数据绑定中的应用
索引器在图形界面编程中扮演着重要角色,尤其是在数据绑定的场景中,它们可以大大简化数据访问和更新的过程。我们将重点关注索引器在WinForms和WPF框架中的应用,并探讨它们在处理自定义数据结构时的潜力。
### 4.1.1 索引器在WinForms/WPF中的使用
在WinForms和WPF应用中,数据绑定是一项关键的技术,它允许UI元素自动更新以反映底层数据的变化。索引器可以在此扮演重要角色,特别是在需要从复杂数据结构中检索数据时。
假设我们有一个`Employee`类,其中包含多个属性,如`Id`、`Name`、`Department`等。在WPF中,我们可以使用`ListBox`控件来展示一个`Employee`对象列表。通过实现一个索引器,我们可以简化对员工列表的访问逻辑。
```csharp
public class EmployeeCollection : List<Employee>
{
public Employee this[int index]
{
get => base[index];
set => base[index] = value;
}
}
```
这段代码中,我们通过继承`List<Employee>`并实现索引器,使得我们可以像访问数组一样访问集合中的元素。这样的实现可以让我们在绑定到UI控件时更加方便。
### 4.1.2 索引器在***数据绑定的应用
在某些情况下,我们可能会遇到需要将数据源绑定到具有多个字段的自定义对象上。使用索引器,我们可以创建一个中间的数据访问层,这层封装了数据源并提供了一个清晰的接口。
考虑以下场景,我们有一个从数据库动态生成的报表数据集`ReportData`,它包含了一系列的记录,每条记录由`DataRecord`类的实例表示。`DataRecord`类包含多个属性,如`Year`、`Revenue`等。
```csharp
public class ReportData
{
private readonly Dictionary<string, DataRecord> records;
public DataRecord this[string key]
{
get => records[key];
set => records[key] = value;
}
public ReportData(Dictionary<string, DataRecord> dataRecords)
{
records = dataRecords;
}
}
```
在这个例子中,我们创建了一个`ReportData`类,它在内部使用一个字典来存储`DataRecord`对象。通过实现一个字符串键的索引器,我们可以快速访问具有特定键的报表数据。
## 4.2 索引器在复杂数据结构中的应用
复杂数据结构通常需要高度定制化的访问逻辑。索引器可以用来提供这些结构的数据访问接口,从而简化数据的检索和管理过程。
### 4.2.1 多维数据结构的索引器设计
在处理多维数据结构时,索引器提供了一种简洁的方式来访问数据元素。例如,我们可能需要创建一个二维数组来表示地理数据,其中每一行代表不同的测量点,每一列代表不同的测量时间。
```csharp
public class GeoDataCollection
{
private readonly double[,] data;
public GeoDataCollection(int rows, int columns)
{
data = new double[rows, columns];
}
public double this[int row, int column]
{
get => data[row, column];
set => data[row, column] = value;
}
}
```
通过实现一个具有两个整数参数的索引器,我们可以像访问标准二维数组一样检索和更新地理数据。
### 4.2.2 索引器在表达式树中的应用
表达式树是处理复杂数据结构时的强大工具之一。索引器可以和表达式树结合,以支持更为复杂的数据查询操作。
在某些情况下,我们可能需要根据复杂的条件来检索数据。通过表达式树,我们可以构建动态的查询条件,然后通过索引器实现这些条件的评估。
```csharp
public class ExpressionDataCollection
{
private readonly List<DataRecord> records;
public DataRecord this(Expression<Func<DataRecord, bool>> predicate)
{
var filteredRecords = records.Where(***pile()).FirstOrDefault();
return filteredRecords;
}
public ExpressionDataCollection(List<DataRecord> dataRecords)
{
records = dataRecords;
}
}
```
在这个例子中,我们实现了一个索引器,它接受一个表达式作为参数,并返回满足该表达式条件的第一个`DataRecord`对象。
## 4.3 设计模式与索引器结合
设计模式为软件设计提供了标准化的方法论。索引器可以与某些设计模式结合使用,以提供更为优雅的解决方案。
### 4.3.1 索引器在迭代器模式中的应用
迭代器模式允许以统一的接口遍历容器中的所有元素,而不暴露容器的内部结构。索引器可以用来实现迭代器模式,为客户端提供元素的顺序访问。
考虑一个简单的例子,我们需要遍历一个整数集合,并将其打印出来。通过实现一个索引器,我们可以这样实现迭代器模式:
```csharp
public class IntegerCollection : IEnumerable<int>
{
private readonly List<int> collection;
public IntegerCollection()
{
collection = new List<int>();
}
public void Add(int value)
{
collection.Add(value);
}
public int this[int index]
{
get => collection[index];
set => collection[index] = value;
}
public IEnumerator<int> GetEnumerator()
{
for (int i = 0; i < collection.Count; i++)
{
yield return this[i];
}
}
}
```
这里,通过`IEnumerable<int>`接口,我们提供了对`IntegerCollection`的遍历支持,而内部实现的索引器允许`GetEnumerator`方法按顺序访问集合中的每个元素。
### 4.3.2 索引器在访问者模式中的应用
访问者模式用于对某个对象结构中的元素执行操作,而无需改变元素类。索引器可以提供一个用于访问结构元素的访问点,使访问者能够执行具体的操作。
假设我们有一个图形对象的集合,其中包括圆形、矩形和三角形。我们可以定义一个访问者接口`IGraphVisitor`,然后为每个图形类型实现`Accept`方法。索引器可以在这个场景下提供一个访问点。
```csharp
public interface IGraphVisitor
{
void Visit(Circle circle);
void Visit(Rectangle rectangle);
void Visit(Triangle triangle);
}
public abstract class Shape
{
public abstract void Accept(IGraphVisitor visitor);
}
public class ShapeCollection : IEnumerable<Shape>
{
private readonly List<Shape> shapes;
public Shape this[int index]
{
get => shapes[index];
}
public void Add(Shape shape)
{
shapes.Add(shape);
}
public IEnumerator<Shape> GetEnumerator()
{
return shapes.GetEnumerator();
}
}
public class GraphVisitor : IGraphVisitor
{
public void Visit(Circle circle) { /* Visit Circle */ }
public void Visit(Rectangle rectangle) { /* Visit Rectangle */ }
public void Visit(Triangle triangle) { /* Visit Triangle */ }
}
```
在这个例子中,`ShapeCollection`提供了一个索引器用于访问不同的`Shape`对象。每个图形对象都有一个`Accept`方法,它允许访问者对象对图形对象执行操作。这样一来,我们可以轻松地遍历图形集合并执行具体的操作,而无需修改图形对象本身。
以上章节内容仅展示了索引器在真实世界应用中的一小部分案例。索引器的灵活性和多功能性使其在开发过程中具有极大的价值。随着进一步的学习和实践,您将能够发现索引器更多的应用场景,从而提升您的开发效率和软件质量。
# 5. 索引器的扩展性和安全性
## 5.1 扩展索引器的访问权限
索引器不仅可以被定义为public,还可以设置为private、protected等访问修饰符,以控制外部对索引器的访问程度。适当控制访问权限,不仅可以提高代码的封装性,还可以防止敏感数据的错误访问。
```csharp
public class SecureList<T> {
private T[] items;
public SecureList(int capacity) {
items = new T[capacity];
}
public T this[int index] {
get {
if (index < 0 || index >= items.Length) {
throw new ArgumentOutOfRangeException("Index was out of range");
}
return items[index];
}
private set {
if (index < 0 || index >= items.Length) {
throw new ArgumentOutOfRangeException("Index was out of range");
}
items[index] = value;
}
}
}
```
在上面的代码中,我们创建了一个`SecureList`类,其索引器是受保护的。这意味着只有`SecureList`类的子类或者同一程序集中的代码能够修改或读取索引器的值。
## 5.2 索引器与线程安全
在多线程环境下,索引器的线程安全性至关重要。如果不正确处理,可能会导致资源竞争和数据不一致。为了保证线程安全,可以使用锁(如Monitor)或者线程安全的数据结构。
```csharp
using System;
using System.Threading;
public class ThreadSafeList<T> {
private T[] items;
private readonly object locker = new object();
public ThreadSafeList(int capacity) {
items = new T[capacity];
}
public T this[int index] {
get {
lock (locker) {
return items[index];
}
}
set {
lock (locker) {
if (index < 0 || index >= items.Length) {
throw new ArgumentOutOfRangeException("Index was out of range");
}
items[index] = value;
}
}
}
}
```
此代码段展示了如何实现一个线程安全的索引器。通过使用`lock`语句,我们确保了在多线程环境下对索引器的访问是同步的。
## 5.3 索引器的异常处理
索引器应当具备良好的异常处理机制。当索引器操作出现问题时,应当抛出合适的异常,帮助用户快速定位问题所在。
```csharp
public class ErrorHandlingList<T> {
private T[] items;
public ErrorHandlingList(int capacity) {
items = new T[capacity];
}
public T this[int index] {
get {
try {
return items[index];
} catch (IndexOutOfRangeException ex) {
throw new Exception("Index out of range.", ex);
}
}
set {
try {
items[index] = value;
} catch (IndexOutOfRangeException ex) {
throw new Exception("Index out of range.", ex);
}
}
}
}
```
在此代码段中,我们通过try-catch块捕获并处理了可能发生的`IndexOutOfRangeException`异常,这保证了当索引超出预定义范围时,用户可以得到一个清晰的错误信息。
通过上述三种方式,我们可以有效地扩展索引器的功能,同时确保使用索引器时的安全性和稳定性。在实现索引器时,这些考虑是必不可少的,它们有助于开发出健壮和易于维护的代码。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 C# 索引器的各个方面,提供了一系列全面且实用的指南。从基础概念到高级特性,该专栏涵盖了索引器的所有内容,包括如何有效使用它们、如何选择索引器和属性之间的最佳选项、如何重载索引器以提高代码可读性和可维护性,以及如何自定义集合类的构建。此外,该专栏还探讨了索引器与多维数组、LINQ、并发编程、事件处理、异常处理、数据绑定、反射、自定义属性、序列化和异步编程之间的关系。通过深入的分析和丰富的代码示例,该专栏旨在帮助读者掌握索引器,并将其应用于各种场景中,从而提升代码质量和开发效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
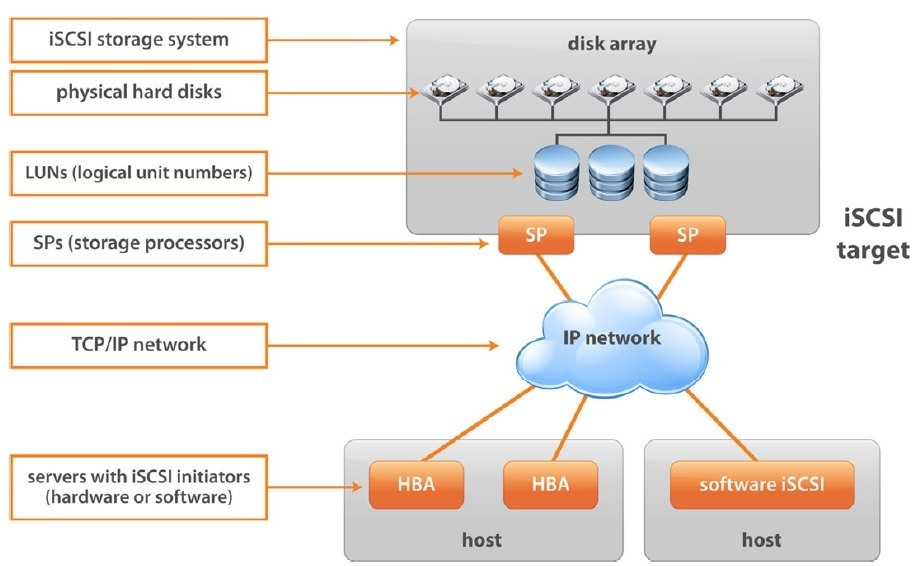
【存储扩容技巧】:用iSCSI在Windows Server 2008 R2中拓展存储空间
# 摘要
本文全面介绍了iSCSI技术,包括其在Windows Server 2008 R2中的配置和高级应用,重点阐述了iSCSI启动器和目标服务器的设置、存储池的管理、监测与维护,以及虚拟化环境中的应用。通过对不同企业环境中iSCSI应用案例的分析,展示
【中文文档编辑效率提升】:5个技巧让你告别加班

# 摘要
随着数字化办公的需求日益增长,中文文档编辑效率的提升已成为提高工作效率的关键。本文从中文排版与格式化、自动化工具的应用以及写作效率的提升等多个方面入手,探讨了当前提高中文文档编辑效率的有效策略。通过对理论的深入分析与实践技巧的详细介绍,本文旨在帮助用户掌握一系列文档编辑技巧,包
大数据环境下的EDEM理论应用:机遇与挑战并存

# 摘要
EDEM理论在大数据环境下提供了独特的数据处理、分析及应用的优势,随着大数据技术的迅速发展,该理论在实践中的应用与挑战也日益显著。本文首先概述了EDEM理论的基本概念,随后详细探讨了其在数据采集、处理和分析等方面的应用,并分析了在大数据环境下所面临的诸如数据安全、数据质量控制以及数据隐私保护等挑战。同时,文章也着重讨论了EDEM理论与大数据技术结合的机遇,并展望了大数据产业未来的发展前景。通过深入分析,本文旨在为大数据环境下EDEM理论
【硬件兼容性升级】:SAM-5新要求下硬件适配的策略与技巧
# 摘要
随着技术的快速发展,硬件兼容性对于确保系统性能和稳定性至关重要,同时也带来了诸多挑战。本文首先介绍了SAM-5规范的起源与发展以及其中的关键硬件要求,随后阐述了硬件兼容性评估的理论基础和实践流程,并探讨了硬件升级策略。接着,通过具体案例分析了内存、存储设备及处理器适配升级的过程,
LPDDR5接口优化与数据传输效率:JEDEC JESD209-5B标准下的传输挑战与策略

# 摘要
本文全面概述了LPDDR5接口技术,强调了数据传输中的关键挑战和系统级接口优化策略。文章首先介绍了LPDDR5的技术特性及其技术指标,并分析了在数据传输过程中遇到的性能瓶颈,包括信号完整性和功耗管理问题。随后,详细解读了JESD209-5B标准,探讨了在该标准下的接口操作、数据校验和测试要求。文章接着探讨了提升数据传输效率的技术,如高速信号
【构建高效EtherCAT网络】:专业指南与实践要点分析

# 摘要
本文对EtherCAT网络技术进行了全面的概述,包括其技术原理、设备配置和网络调试维护策略。首先,介绍EtherCAT网络的基本概念及其协议栈和帧结构,强调了其高性能和实时性的特点。其次,详细讨论了EtherCAT网络的同步机制、容错设计以及如何进行有效的设备选择和网络拓扑构建。接着,文章提供了网络调试和维护的实用工
【从入门到精通】:马尔可夫模型在深度学习与自然语言处理中的实践技巧
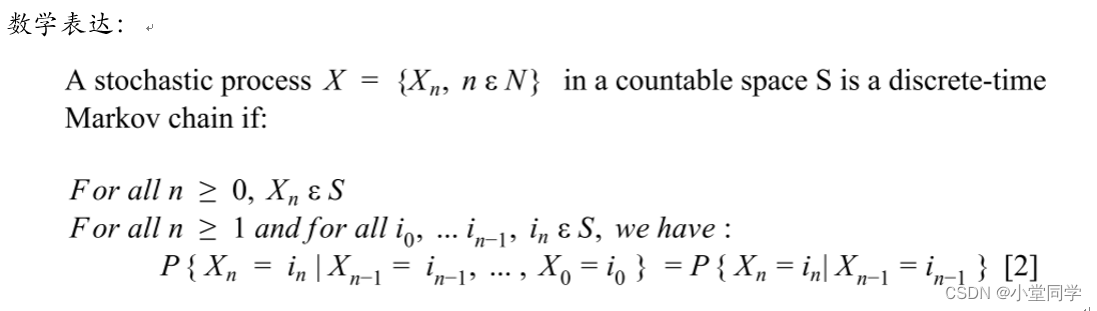
# 摘要
本文系统性地探讨了马尔可夫模型的基础理论及其在深度学习、自然语言处理和高级应用领域中的实际应用。首先,概述了马尔可夫模型的基本概念及其在深度学习中的应用,重点分析了马尔可夫链与循环神经网络(RNN)的结合方法以及在深度学习框架中的实现。接着,深入探讨了马尔可夫模型在自然语言处理中的应用,包括文本生成、语言模型构建及分词和词性标注。此外,本文还介绍了马尔可夫决策过程在强化学习中的应用,以及在语音识别中的最新进展。最后,通过案例分析和实
【iOS用户数据迁移:沙盒限制下的策略与工具】

# 摘要
iOS用户数据迁移是一个复杂的过程,涉及用户和应用需求的分析、数据迁移理论模型的建立、迁移工具的使用以及安全隐私的保护。本文首先概述了iOS用户数据迁移的背景和需求,然后深入探讨了iOS沙盒机制对数据迁移的影响及其挑战。接着,本文基于数据迁移的理论基础,分析了迁移过程中的关键问题,并提出了相应的策略和工具。重点介绍了内置迁移工具、第三方解决方案以及自定义迁移脚本的应
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )