深入理解Diffie-Hellman密钥交换
发布时间: 2024-04-03 03:21:17 阅读量: 40 订阅数: 25 

基于Diffie-Hellman协议的密钥交换
# 1. Diffie-Hellman密钥交换简介
1.1 密钥交换的基本概念
在网络通信中,密钥交换是一种重要的加密技术,用于安全地共享密钥以加密和解密通信数据。通过密钥交换算法,通信双方可以在不直接传输密钥的情况下协商出一个共享密钥。
1.2 Diffie-Hellman密钥交换的历史背景
Diffie-Hellman密钥交换是由Whitfield Diffie和Martin Hellman于1976年提出的,被认为是公钥密码学的开创性发明之一。该方法允许双方在公开的通信信道上协商出一个共享密钥,实现了密钥交换的安全性。
1.3 Diffie-Hellman密钥交换的工作原理
Diffie-Hellman密钥交换算法基于离散对数问题,通过数学原理实现安全的密钥协商。通信双方约定一个公开的素数p和一个生成元g,然后各自选择私密数a和b,并通过一系列数学运算计算出共享密钥。这个共享密钥只有通信双方知道,从而保证了通信数据的机密性。
# 2. 数学背景与算法原理
Diffie-Hellman密钥交换算法是基于离散对数问题的。在这一章节中,我们将深入探讨离散对数问题以及Diffie-Hellman密钥交换算法的具体原理和步骤。通过对数学背景的理解,我们可以更好地把握这一经典密码学算法的实质。让我们一起来详细了解吧!
# 3. Diffie-Hellman密钥交换在网络通信中的应用
Diffie-Hellman密钥交换作为一种重要的加密算法,在网络通信中有着广泛的应用。下面将介绍它在TLS/SSL协议、SSH协议和VPN技术中的具体应用情况。
#### 3.1 TLS/SSL协议中的Diffie-Hellman密钥交换
在TLS/SSL协议中,Diffie-Hellman密钥交换被用于建立安全的通信通道。客户端和服务器端可以通过Diffie-Hellman密钥交换协商出一个对称密钥,用于后续的数据加密和解密过程。通常情况下,TLS/SSL协议会结合RSA等非对称加密算法与Diffie-Hellman密钥交换一起使用,以保证通信的安全性。
```python
# Python代码示例:TLS/SSL中Diffie-Hellman密钥交换
from cryptography.hazmat.primitives.asymmetric import dh
from cryptography.hazmat.primitives import serialization
parameters = dh.generate_parameters(generator=2, key_size=2048)
private_key = parameters.generate_private_key()
public_key = private_key.public_key()
serialized_params = parameters.parameter_bytes(encoding=serialization.Encoding.PEM, format=serialization.ParameterFormat.PKCS3)
serialized_private_key = private_key.private_bytes(encoding=serialization.Encoding.PEM, format=serialization.PrivateFormat.PKCS8)
serialized_public_key = public_key.public_bytes(encoding=serialization.Encoding.PEM, format=serialization.PublicFormat.SubjectPublicKeyInfo)
print("Diffie-Hellman Parameters:\n", serialized_params.decode())
print("Private Key:\n", serialized_private_key.decode())
print("Public Key:\n", serialized_public_key
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以 OpenSSL 为核心,深入探讨了 C/S 通信的安全实现。从 OpenSSL 的基本概念入手,逐步深入了解 SSL/TLS 加密原理、证书生成、服务器配置等。通过搭建客户端和服务器,掌握 OpenSSL 在 C/S 通信中的应用。此外,还涵盖了 SSL 证书验证、加密套件破解、密钥交换算法、SSL 握手过程、性能优化等高级主题。同时,专栏也提供了 SSL/TLS 协议版本配置、SSL 终止、透明代理等实用知识。通过对 OpenSSL 的全面解析和实践演练,本专栏旨在帮助读者建立对 OpenSSL 安全通信的深刻理解,并提升其在实际应用中的能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
空间统计学新手必看:Geoda与Moran'I指数的绝配应用
# 摘要
本论文深入探讨了空间统计学在地理数据分析中的应用,特别是运用Geoda软件进行空间数据分析的入门指导和Moran'I指数的理论与实践操作。通过详细阐述Geoda界面布局、数据操作、空间权重矩阵构建以及Moran'I指数的计算和应用,本文旨在为读者提供一个系统的学习路径和实操指南。此外,本文还探讨了如何利用Moran'I指数进行有效的空间数据分析和可视化,包括城市热岛效应的空间分析案例研究。最终,论文展望了空间统计学的未来
【Python数据处理秘籍】:专家教你如何高效清洗和预处理数据

# 摘要
随着数据科学的快速发展,Python作为一门强大的编程语言,在数据处理领域显示出了其独特的便捷性和高效性。本文首先概述了Python在数据处理中的应用,随后深入探讨了数据清洗的理论基础和实践,包括数据质量问题的认识、数据清洗的目标与策略,以及缺失值、异常值和噪声数据的处理方法。接着,文章介绍了Pandas和NumPy等常用Python数据处理库,并具体演示了这些库在实际数
【多物理场仿真:BH曲线的新角色】:探索其在多物理场中的应用
# 摘要
本文系统介绍了多物理场仿真的理论基础,并深入探讨了BH曲线的定义、特性及其在多种材料中的表现。文章详细阐述了BH曲线的数学模型、测量技术以及在电磁场和热力学仿真中的应用。通过对BH曲线在电机、变压器和磁性存储器设计中的应用实例分析,本文揭示了其在工程实践中的重要性。最后,文章展望了BH曲线研究的未来方向,包括多物理场仿真中BH曲线的局限性
【CAM350 Gerber文件导入秘籍】:彻底告别文件不兼容问题
# 摘要
本文全面介绍了CAM350软件中Gerber文件的导入、校验、编辑和集成过程。首先概述了CAM350与Gerber文件导入的基本概念和软件环境设置,随后深入探讨了Gerber文件格式的结构、扩展格式以及版本差异。文章详细阐述了在CAM350中导入Gerber文件的步骤,包括前期
【秒杀时间转换难题】:掌握INT、S5Time、Time转换的终极技巧
# 摘要
时间表示与转换在软件开发、系统工程和日志分析等多个领域中起着至关重要的作用。本文系统地梳理了时间表示的概念框架,深入探讨了INT、S5Time和Time数据类型及其转换方法。通过分析这些数据类型的基本知识、特点、以及它们在不同应用场景中的表现,本文揭示了时间转换在跨系统时间同步、日志分析等实际问题中的应用,并提供了优化时间转换效率的策略和最
【传感器网络搭建实战】:51单片机协同多个MLX90614的挑战

# 摘要
本论文首先介绍了传感器网络的基础知识以及MLX90614红外温度传感器的特点。接着,详细分析了51单片机与MLX90614之间的通信原理,包括51单片机的工作原理、编程环境的搭建,以及传感器的数据输出格式和I2C通信协议。在传感器网络的搭建与编程章节中,探讨了网络架构设计、硬件连接、控制程序编写以及软件实现和调试技巧。进一步
Python 3.9新特性深度解析:2023年必知的编程更新
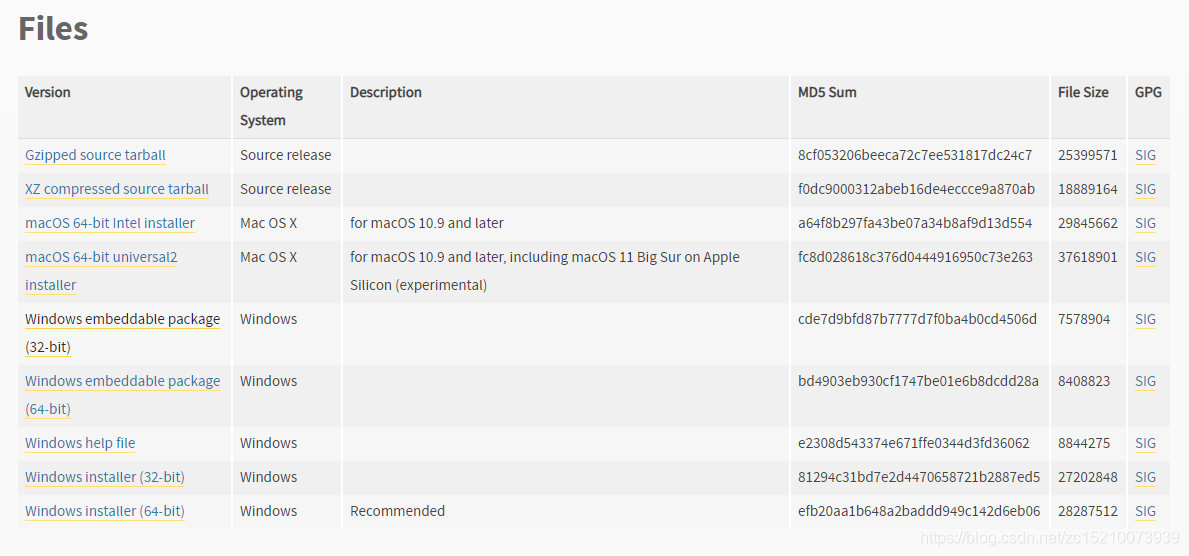
# 摘要
随着编程语言的不断进化,Python 3.9作为最新版本,引入了多项新特性和改进,旨在提升编程效率和代码的可读性。本文首先概述了Python 3.
金蝶K3凭证接口安全机制详解:保障数据传输安全无忧
# 摘要
金蝶K3凭证接口作为企业资源规划系统中数据交换的关键组件,其安全性能直接影响到整个系统的数据安全和业务连续性。本文系统阐述了金蝶K3凭证接口的安全理论基础,包括安全需求分析、加密技术原理及其在金蝶K3中的应用。通过实战配置和安全验证的实践介绍,本文进一步阐释了接口安全配置的步骤、用户身份验证和审计日志的实施方法。案例分析突出了在安全加固中的具体威胁识别和解决策略,以及安全优化对业务性能的影响。最后
【C++ Builder 6.0 多线程编程】:性能提升的黄金法则
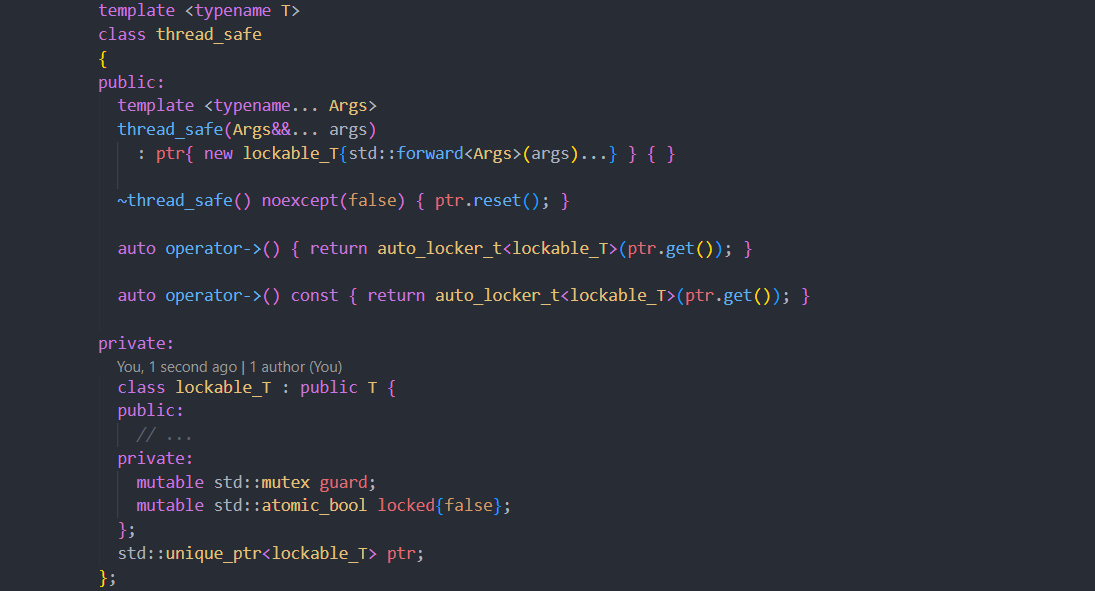
# 摘要
随着计算机技术的进步,多线程编程已成为软件开发中的重要组成部分,尤其是在提高应用程序性能和响应能力方面。C++ Builder 6.0作为开发工具,提供了丰富的多线程编程支持。本文首先概述了多线程编程的基础知识以及C++ Builder 6.0的相关特性,然后深入探讨了该环境下线程的创建、管理、同步机制和异常处理。接着,文章提供了多线程实战技巧,包括数据共享
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )