【Apache POI零基础入门】:5小时掌握文档操作的高效秘籍
发布时间: 2025-01-03 17:31:27 阅读量: 15 订阅数: 14 
# 摘要
Apache POI是一个广泛使用的Java库,用于读取和写入Microsoft Office格式的文件。本文从Apache POI的概述和环境配置开始,介绍了其基础操作、高级实践以及在企业级应用中的最佳实践。通过深入探讨POI的架构和组件,文档的创建、编辑、读取与解析,以及进阶的数据处理和性能优化技术,本文为读者提供了全面的Apache POI使用指南。最后,文章通过实战项目案例演示了POI在实际工作中的应用,并对未来发展趋势进行了展望,旨在帮助开发者提高开发效率并优化代码质量。
# 关键字
Apache POI;文件操作;文档编辑;数据处理;性能优化;企业级应用
参考资源链接:[Apache POI动态生成Word docx与PDF转换:优缺点分析](https://wenku.csdn.net/doc/4ev6103xpd?spm=1055.2635.3001.10343)
# 1. Apache POI概述与环境配置
## 1.1 Apache POI简介
Apache POI是一个开源的Java库,专门用于处理Microsoft Office文档格式。它允许开发者创建、修改和显示Microsoft Office格式的文件,比如Excel,Word和PowerPoint等。由于它的功能强大并且易于使用,Apache POI已成为处理办公文档的首选库。
## 1.2 环境配置
要开始使用Apache POI,首先需要在项目中添加POI库的依赖。如果你使用的是Maven,可以在`pom.xml`文件中添加以下依赖:
```xml
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>YOUR_POI_VERSION</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>YOUR_POI_VERSION</version>
</dependency>
```
请将`YOUR_POI_VERSION`替换为当前POI的最新稳定版本号。
## 1.3 基础操作准备
安装好依赖后,你可以开始编写代码来操作Office文档。在深入学习Apache POI之前,建议先熟悉一些基础概念,例如`Workbook`, `Sheet`, `Row`, `Cell`等,这些是操作Excel文档的基本单位。接下来,让我们进入第二章,探索Apache POI更具体的基础操作。
# 2. Apache POI基础操作
Apache POI作为Java处理Microsoft Office文档的开源库,提供了丰富的API来操作Excel和Word文档。在本章节中,我们将深入探讨Apache POI的基本使用方法,包括其架构和组件、文档的创建与编辑以及读取与解析。
## 2.1 Apache POI的架构和组件
Apache POI的架构设计允许开发者轻松地处理Microsoft Office文档。了解POI的核心类和接口以及如何处理工作簿、工作表和单元格,是掌握POI的基础。
### 2.1.1 POI的核心类和接口
Apache POI项目包含了一套丰富的类和接口,涵盖了从简单的文本文件到复杂的电子表格和文档的所有内容。核心的几个包如下:
- `org.apache.poi`:包含处理不同Microsoft Office文档的通用工具类。
- `org.apache.poi.ss`:包含处理Excel文档的类和接口,其中`usermodel`和`hssf.usermodel`等子包提供了对旧版HSSF和新版XSSF格式的支持。
- `org.apache.poi.hslf`:包含处理PowerPoint文档的类和接口。
- `org.apache.poi.hwpf`:包含处理Word文档的类和接口。
例如,创建一个新的Excel工作簿可以使用`XSSFWorkbook`类:
```java
import org.apache.poi.ss.usermodel.*;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
public class WorkbookExample {
public static void main(String[] args) throws Exception {
Workbook wb = new XSSFWorkbook(); // 创建一个Excel工作簿
Sheet sheet = wb.createSheet("Example Sheet"); // 创建一个工作表
// 添加一些数据
Row row = sheet.createRow(0);
Cell cell = row.createCell(0);
cell.setCellValue("Hello, POI!");
// ...
// 写入到文件
try (FileOutputStream out = new FileOutputStream("workbook.xlsx")) {
wb.write(out);
}
// 最后不要忘记关闭工作簿资源
wb.close();
}
}
```
### 2.1.2 工作簿、工作表和单元格基础
在Apache POI中,一个工作簿(Workbook)可以包含多个工作表(Sheet),每个工作表可以包含多个行(Row),每个行可以包含多个单元格(Cell)。单元格可以包含不同的数据类型,如数字、字符串、公式等。
要创建一个简单的Excel文件并填充数据,可以使用以下步骤:
```java
// 创建一个新的工作簿
XSSFWorkbook workbook = new XSSFWorkbook();
// 创建一个工作表sheet
XSSFSheet sheet = workbook.createSheet("Sheet1");
// 创建一行row
XSSFRow row = sheet.createRow(0);
// 在行中创建单元格cell,并设置值为字符串
XSSFCreator cell = row.createCell(0);
cell.setCellValue("First row, first cell");
// ...
```
单元格的数据类型需要在设置值之前就确定,POI提供了不同的方法来设置不同类型的数据:
```java
cell.setCellValue("Hello, World!"); // 文本类型
cell.setCellValue(123); // 数字类型
cell.setCellValue(12.3); // 浮点数类型
cell.setCellFormula("A1+B2"); // 公式类型
```
工作簿、工作表和单元格的操作是Apache POI中最基础的操作,掌握它们对于进一步使用POI进行文档操作至关重要。
## 2.2 文档的创建与编辑
Apache POI不仅支持创建文档,还支持对现有文档的编辑,这使得开发者可以灵活地处理文档内容和样式。
### 2.2.1 创建Excel和Word文档
创建Excel文档使用`XSSFWorkbook`类,创建Word文档使用`XWPFDocument`类。
```java
// 创建一个新的Excel文档
XSSFWorkbook workbook = new XSSFWorkbook();
// 创建一个新的Word文档
XWPFDocument document = new XWPFDocument();
```
创建后,可以添加工作表(Sheet)或段落(Paragraph)。
### 2.2.2 修改文档内容和样式
编辑文档的内容和样式是办公自动化中非常常见的需求。Apache POI提供了丰富的API来进行这些操作。
- 修改Excel单元格的内容:
```java
// 假设已经有一个工作簿workbook和工作表sheet
XSSFSheet sheet = workbook.getSheet("Sheet1");
XSSFRow row = sheet.getRow(1);
if(row == null) {
row = sheet.createRow(1);
}
XSSFCreator cell = row.createCell(0);
cell.setCellValue("Updated Value");
```
- 修改Word段落样式:
```java
// 假设已经有一个Word文档document
XWPFParagraph p = document.createParagraph();
XWPFRun r = p.createRun();
r.setText("Hello, Apache POI!");
r.setBold(true); // 设置为粗体
```
通过编写代码,我们可以对文档中的数据、格式、样式进行动态修改。
## 2.3 文档的读取与解析
文档的读取和解析是Apache POI的另一项重要功能,允许我们从现有的文档中提取数据和元数据。
### 2.3.1 读取Excel和Word文档的数据
读取Excel文档数据,我们可以使用`WorkbookFactory.create()`方法从文件中创建工作簿对象,并遍历工作表和单元格。
```java
// 打开一个现有的Excel文件
FileInputStream fis = new FileInputStream("workbook.xlsx");
Workbook workbook = WorkbookFactory.create(fis);
Sheet sheet = workbook.getSheetAt(0);
// 遍历行
for(Row row : sheet) {
// 遍历列
for(Cell cell : row) {
// 读取数据
String value = getCellValue(cell);
// ...
}
}
```
### 2.3.2 解析文档结构和属性
解析Word文档时,可以读取文档的结构、段落、图片、表格等。使用`XWPFDocument`类可以读取文档,并解析出结构和内容。
```java
// 打开一个现有的Word文件
FileInputStream fis = new FileInputStream("document.docx");
XWPFDocument document = new XWPFDocument(fis);
// 解析并遍历段落
for(XWPFParagraph p : document.getParagraphs()) {
// 获取并打印文本
String text = p.getText();
// ...
}
```
文档的读取和解析是Apache POI的高级用法,可以用来提取重要数据进行进一步分析和处理。
在本章节中,我们已经学习了Apache POI的架构、组件,以及如何进行文档的创建、编辑、读取和解析。这些基础知识为深入理解和使用Apache POI打下了坚实的基础。接下来,在第三章中,我们将进一步深入探讨Apache POI的进阶应用,包括高级文档操作技巧、数据操作与分析以及大文件处理和性能优化。
# 3. Apache POI进阶实践
## 3.1 高级文档操作技巧
### 3.1.1 公式和图表的处理
在处理Excel文档时,公式和图表的使用是不可或缺的部分。Apache POI通过`HSSFFormulaParser`类提供了公式的解析支持,而图表的创建则需要利用`HSSFPatriarch`和相关类来操作。下面我们将深入探讨如何在Apache POI中处理公式和图表。
#### 公式处理
Apache POI中处理公式的API相对直观。例如,要设置单元格A1中的公式为`=SUM(B1:B10)`,可以使用如下代码:
```java
Cell cellA1 = rowA.createCell((short) 0);
cellA1.setCellType(Cell.CELL_TYPE_FORMULA);
cellA1.setCellFormula("SUM(B1:B10)");
```
注意,设置单元格类型为`CELL_TYPE_FORMULA`,这是必须的步骤,否则公式不会被正确地处理。
#### 图表处理
Apache POI支持多种图表,包括柱状图、折线图、饼图等。以下是一个简单的柱状图创建示例:
```java
HSSFSheet sheet = workbook.createSheet("Chart Demo");
HSSFRow row = sheet.createRow(0);
row.createCell(0).setCellValue("Column 1");
row.createCell(1).setCellValue("Column 2");
// 创建数据源
HSSFPatriarch patriarch = sheet.createDrawingPatriarch();
HSSFClientAnchor anchor = new HSSFClientAnchor(0, 0, 0, 0, 0, 2, 4, 10);
HSSFDrawing chart = (HSSFDrawing) patriarch.createGroup(anchor);
// 创建柱状图对象并添加数据源
HSSFCreationHelper helper = workbook.getCreationHelper();
HSSFChart chartObj = chart.createChart(helper.createAreaReference(new CellRangeAddress(0, 0, 0, 1)),
helper.createAreaReference(new CellRangeAddress(0, 0, 2, 3)));
chartObj.setTitleText("Bar Chart Example");
HSSFChartLegend legend = chartObj.getChartLegend();
legend.setPosition(LegendPosition.TOP_RIGHT);
// 添加系列数据
HSSFSeries series = chartObj.getSeries()[0];
series.setFirstRow(1);
series.setLastRow(1);
series.setFirstCol(0);
series.setLastCol(0);
series.setTitle("Column 1");
```
上述代码演示了如何创建一个简单的柱状图,并将其绑定到指定的单元格区域。图表的详细配置和样式调整可以通过`HSSFChart`和`HSSFSeries`等对象完成。
### 3.1.2 样式的应用与自定义
样式是文档中统一视觉元素的一种有效手段。Apache POI提供了丰富的API来处理单元格样式,如字体、颜色、边框等。在这一节,我们将深入了解如何应用和自定义样式。
#### 字体和颜色
要设置单元格的字体和颜色,需要先创建`HSSFFont`和`HSSFCellStyle`对象:
```java
HSSFFont font = workbook.createFont();
font.setFontName("Arial");
font.setFontHeightInPoints((short) 10);
font.setColor(HSSFColor.BLACK.index);
HSSFCellStyle cellStyle = workbook.createCellStyle();
cellStyle.setFont(font);
```
#### 边框
接下来,添加边框可以使用`setBottomBorderColor()`, `setTopBorderColor()`, `setLeftBorderColor()`, 和 `setRightBorderColor()`方法:
```java
cellStyle.setBorderBottom(BorderStyle.THIN);
cellStyle.setBottomBorderColor(HSSFColor.BLACK.index);
cellStyle.setBorderTop(BorderStyle.THIN);
cellStyle.setTopBorderColor(HSSFColor.BLACK.index);
```
#### 对齐和数据格式
对齐方式和数据格式也是样式的一部分:
```java
cellStyle.setAlignment(HSSFCellStyle.ALIGN_CENTER);
cellStyle.setVerticalAlignment(HSSFCellStyle.VERTICAL_CENTER);
HSSFFormat format = workbook.createDataFormat();
cellStyle.setDataFormat(format.getFormat("@"));
```
以上代码展示了如何创建一个居中对齐的样式,并设置了数据格式为文本。
Apache POI的样式应用非常灵活,通过上述基本操作,可以创建出多样化的样式,并将其应用到单元格中。自定义样式通常在处理复杂的文档布局时非常重要,例如,可以在表格中突出显示特定的行或列,或者为不同的数据段设置不同的背景颜色以区分不同的数据组。
### 3.2 数据操作与分析
#### 3.2.1 复杂数据结构的处理
在处理复杂的Excel数据时,Apache POI提供了强大的数据结构处理能力,如合并单元格、条件格式等。在本小节,我们将探索如何使用POI来操作这些复杂的Excel数据结构。
##### 合并单元格
合并单元格通常用于强调或整合数据。在Apache POI中,可以通过以下代码实现:
```java
HSSFSheet sheet = workbook.getSheetAt(0);
HSSFRow row = sheet.createRow(2);
HSSFCell cell = row.createCell(1);
cell.setCellValue("合并单元格示例");
// 合并第二行的第三列到第四列
sheet.addMergedRegion(new CellRangeAddress(2, 2, 2, 3));
```
##### 条件格式
条件格式化可以基于单元格的值改变其样式。例如,我们可以为值大于50的单元格设置黄色背景:
```java
HSSFCellStyle cellStyle = workbook.createCellStyle();
cellStyle.setFillForegroundColor(HSSFColor.YELLOW.index);
cellStyle.setFillPattern(FillPatternType.SOLID_FOREGROUND);
HSSFFormat format = workbook.createDataFormat();
cellStyle.setDataFormat(format.getFormat("@"));
HSSFConditionalFormattingRule rule = workbook.createConditionalFormattingRule(ComparisonOperator.GREATER_THAN, "50");
PatternFormatting pattern = rule.createPatternFormatting();
pattern.setConditionValue("50");
pattern.setCellStyle(cellStyle);
CellRangeAddress[] regions = {CellRangeAddress.valueOf("A1:A10")};
HSSFFormattingPaintFormattingHelper helper = workbook.getCreationHelper().createFormattingHelper();
helper.addConditionalFormatting(sheet, regions, rule);
```
##### 数据透视表
数据透视表是处理大型数据集时的强大工具。以下是创建数据透视表的步骤:
```java
HSSFPivotTable pivotTable = sheet.createPivotTable(new CellRangeAddress(1, 10, 1, 1),
new CellRangeAddress(1, 10, 2, 2), sheet);
pivotTable.addRowLabel(0);
pivotTable.addColumnLabel(DataConsolidateFunction.SUM, 1);
```
#### 3.2.2 数据透视表和高级筛选
数据透视表和高级筛选是数据操作与分析的高级话题。在Apache POI中,它们提供了对数据的强大控制能力。
##### 高级筛选
高级筛选允许用户根据复杂的条件筛选数据。在Apache POI中,它可以通过设置`AutoFilter`来实现:
```java
HSSFSheet sheet = workbook.getSheetAt(0);
AutoFilter filter = sheet.setAutoFilter(CellRangeAddress.valueOf("A1:B10"));
```
##### 数据透视表
数据透视表是Excel中的一个功能强大的工具,可以快速汇总和分析大量数据。在Apache POI中,创建数据透视表涉及到一系列的步骤:
```java
HSSFSheet sheet = workbook.getSheetAt(0);
HSSFPivotTable pivotTable = sheet.createPivotTable(
new CellRangeAddress(1, 10, 1, 1), // 位置
new CellRangeAddress(1, 10, 2, 2), // 数据源
sheet
);
// 添加行标签
pivotTable.addRowLabel(0);
// 添加数据项
pivotTable.addColumnLabel(DataConsolidateFunction.SUM, 1);
```
在Apache POI中处理高级数据分析功能可能会比较复杂,特别是数据透视表。不过,一旦掌握了这些功能,你就能对数据进行深入的洞察和分析。
### 3.3 大文件处理和性能优化
#### 3.3.1 大型Excel文件操作技巧
处理大型文件时,Apache POI可能面临性能和内存管理的问题。以下是一些处理大型Excel文件时的实用技巧:
##### 流式读取
避免一次性加载整个工作簿到内存中,而是采用流式读取的方式来处理单元格。Apache POI提供了`SXSSFWorkbook`类,它可以支持以流的方式写入大型文件,减少了内存消耗:
```java
SXSSFWorkbook workbook = new SXSSFWorkbook();
SXSSFSheet sheet = workbook.createSheet();
for (int i = 0; i < 100000; i++) {
SXSSFRow row = sheet.createRow(i);
SXSSFCell cell = row.createCell(0);
cell.setCellValue(i);
}
FileOutputStream out = new FileOutputStream("large.xlsx");
workbook.write(out);
out.close();
workbook.dispose();
```
注意,在使用`SXSSFWorkbook`时,需要调用`dispose()`方法来清理内存。
##### 内存优化
当处理大型文件时,选择合适的对象类型也十分重要。例如,避免使用`HSSFWorkbook`而使用`XSSFWorkbook`,因为`XSSFWorkbook`是基于XML格式,支持更高效的读写操作。
#### 3.3.2 性能优化的方法和实践
性能优化是一个持续的过程,涉及代码的每一部分。在使用Apache POI时,以下几个建议可以帮助提高性能:
##### 缓存技术
合理利用缓存技术可以提高数据处理效率。例如,在处理大型文档时,可以将重复使用的样式、字体等缓存起来,减少重复创建。
```java
private static HSSFCellStyle commonStyle;
public static HSSFCellStyle getCommonStyle(HSSFWorkbook wb) {
if (commonStyle == null) {
commonStyle = wb.createCellStyle();
// 设置样式属性
}
return commonStyle;
}
```
##### 优化数据写入
尽量减少不必要的数据写入,例如,避免在循环中频繁调用`setCellFormula`或者`setCellStyle`等方法,这些操作会带来较高的性能开销。
```java
// 避免在循环中频繁设置样式
for (int i = 0; i < 1000; i++) {
Row row = sheet.createRow(i);
for (int j = 0; j < 10; j++) {
Cell cell = row.createCell(j);
cell.setCellValue(i * j);
cell.setCellStyle(commonStyle);
}
}
```
##### 使用合适的POI版本
Apache POI的版本之间在性能和功能上有所差异。选择最新的稳定版本,并且确保它适合你的需求。
此外,使用单元测试来监控性能变化,持续调整优化策略,也是一个好的实践。例如,在每次重构代码后,可以运行性能测试来确保优化不会引入新的性能问题。
通过这些技巧和实践,你可以在保持代码整洁的同时,提高Apache POI操作的性能,特别是在处理大型文件时。
在这一章中,我们探索了Apache POI进阶实践的各种技巧和方法。从高级文档操作到大文件处理,我们逐步深入介绍了如何有效地使用Apache POI库来解决实际问题。在下一章,我们将通过具体案例来展示这些技巧在实战项目中的应用。
# 4. Apache POI实战项目案例
## 4.1 批量文档生成与管理
### 4.1.1 自动化批量创建文档
在企业日常运作中,经常需要生成大量格式化文档,如合同、报告等。Apache POI提供强大的API,通过编程方式实现文档的批量创建和管理,从而大幅提高工作效率。
假设我们要创建一个自动化系统,用于批量生成合同文档。首先,我们会准备一个模板文件,然后利用Apache POI读取模板文件,填充其中的数据变量,并创建新的文档保存。
以下是一个简单的示例代码,演示如何使用Apache POI批量创建Excel文档:
```java
import org.apache.poi.ss.usermodel.*;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import java.io.FileOutputStream;
import java.io.IOException;
public class BatchDocumentGenerator {
public static void main(String[] args) {
try {
// 加载模板Excel文件
Workbook workbook = new XSSFWorkbook("template.xlsx");
Sheet sheet = workbook.getSheetAt(0);
// 假设模板中有一个A2单元格用于填充数据
Cell cell = sheet.getRow(1).getCell(0);
cell.setCellValue("数据填充");
// 将填充后的文档另存为新的文件
FileOutputStream out = new FileOutputStream("output.xlsx");
workbook.write(out);
// 关闭文件流和工作簿资源
out.close();
workbook.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
```
在这个例子中,我们首先加载了一个名为"template.xlsx"的Excel模板文件,然后在指定的单元格位置填充了静态数据,并将这个工作簿保存为"output.xlsx"。在实际应用中,你可能需要在循环中处理多个数据源,并且动态填充模板,保存为不同的文件。
代码执行逻辑说明:
- `Workbook workbook = new XSSFWorkbook("template.xlsx");`: 加载名为"template.xlsx"的Excel模板文件。
- `Sheet sheet = workbook.getSheetAt(0);`: 获取模板中第一个工作表。
- `Cell cell = sheet.getRow(1).getCell(0);`: 获取第二行第一列的单元格。
- `cell.setCellValue("数据填充");`: 设置单元格的值。
- `FileOutputStream out = new FileOutputStream("output.xlsx");`: 创建一个文件输出流,指向新生成的文件。
- `workbook.write(out);`: 将工作簿写入到输出流。
- `out.close();` 和 `workbook.close();`: 关闭文件输出流和工作簿资源。
接下来,我们可以编写循环逻辑,将每个客户的数据填充到模板中,并生成独立的文档文件。
通过类似的自动化流程,Apache POI使得文档创建和管理变得简单、高效。在本部分的后续段落中,我们将深入探讨如何实现版本控制、文档追踪等更高级的功能。
# 5. ```
# 第五章:Apache POI最佳实践与未来展望
## 5.1 常见问题解决方案
### 5.1.1 跨平台兼容性问题处理
在使用Apache POI进行文档操作时,开发者可能遇到跨平台兼容性问题,这通常涉及到不同操作系统间文件格式的差异,特别是在处理Excel文件时尤为明显。由于不同版本的Microsoft Office在不同操作系统上可能有不同的实现,因此同一份Excel文件在不同系统上可能会出现格式错乱或者内容显示不正确的情况。
为了处理这类问题,开发者可以采取以下策略:
1. **统一Excel文件版本**:在创建Excel文件时,尽量使用较低版本的格式(如XLS而非XLSX),以确保在旧版Office上也能正确打开。
2. **使用OOXML标准**:OOXML是基于XML的Open Office标准,对于XLSX文件格式,Apache POI提供了完整的支持,这样可以确保Excel文件的兼容性。
3. **测试不同环境**:在开发过程中,使用多种操作系统环境进行测试,确保文档的显示和操作无误。
4. **使用最新版本的Apache POI**:Apache POI会不断更新,以修复已知的兼容性问题,因此使用最新版本可以在一定程度上减少兼容性问题的发生。
### 5.1.2 大型项目中的POI应用策略
当处理大型项目时,文档的数量和规模可能会显著增加,这时就需要注意POI应用策略以提高效率和可维护性。处理大型项目时,常见的问题包括内存管理、读写性能和代码维护性。
为了有效应对这些问题,开发者可以遵循以下策略:
1. **采用流式处理**:避免一次性加载整个大型文档到内存中,使用POI的流式API(如SXSSF)来逐行读写数据,这样可以有效降低内存消耗。
2. **使用事件驱动模型**:对于解析大型文档,可以考虑使用事件驱动模型来逐事件处理文档内容,而不是一次性读取整个文档。
3. **代码模块化**:将处理文档的代码分解为多个模块,针对不同部分的文档操作使用专门的类或函数,有助于提升代码的可读性和可重用性。
4. **优化算法和数据结构**:针对读写大型文件,对涉及的算法和数据结构进行优化,比如使用合适的集合类型存储解析后的数据。
## 5.2 POI在企业级应用中的实践
### 5.2.1 集成到企业应用中的经验分享
企业级应用经常需要处理大量数据,这些数据需要以文档的形式呈现给最终用户,或者用于进一步的数据分析和报告。在这些场景中,Apache POI通常被用于自动化文档的生成和处理。
Apache POI集成到企业应用中的经验分享包括:
1. **选择合适的POI组件**:根据需要生成的文档类型选择合适的POI组件(如HSSF、XSSF或HWPF、XWPF)。
2. **设计合理的数据模型**:定义清晰的数据结构来组织需要写入文档的数据,保证数据的可扩展性和易维护性。
3. **异常处理机制**:在文档操作中,确保异常能够被妥善捕获并处理,尤其是在涉及到文件I/O操作时。
4. **资源管理**:在处理完文档后,确保所有资源(如文件流、Workbook、Sheet等)都正确关闭,以避免资源泄漏。
### 5.2.2 安全性和效率的最佳实践
在企业应用中,安全性和效率始终是最重要的考虑因素。Apache POI在使用时需要注意以下最佳实践:
1. **避免资源竞争**:在多线程环境下,确保对文档的访问不会引起资源竞争或冲突,这可能需要适当的线程同步机制。
2. **文档内容校验**:对于外部输入生成的文档,要进行充分的内容校验,防止潜在的注入攻击。
3. **性能监控和调优**:定期对POI操作进行性能监控,并根据监控结果进行必要的调优,比如优化数据处理逻辑,调整缓存大小等。
4. **文档签名和加密**:对敏感文档实施数字签名和加密,确保文档的安全性和完整性。
## 5.3 POI的发展趋势和展望
### 5.3.1 新版本特性分析
Apache POI项目持续演进,新版本的发布通常会带来新的特性和性能提升。开发者应当紧跟POI的最新进展,以便更好地利用这些新特性。
新版本特性分析可能包括:
1. **新特性概览**:研究新版本中新增的特性,比如对新Office格式的支持,或者对旧版本中存在bug的修复。
2. **性能改进**:评估新版本的性能改进,特别是对于大型文件处理能力的提升。
3. **API变更**:注意API的变更,以便及时调整已有代码。
4. **社区反馈**:查看社区反馈,了解其他开发者使用新版本的体验和建议。
### 5.3.2 未来应用场景预测
随着技术的发展,Apache POI未来可能会在以下场景中得到更广泛的应用:
1. **云文档处理**:随着云计算的普及,将文档处理和存储迁移到云端将变得越来越常见,POI在云环境下的应用将是一个重要的发展方向。
2. **自动化报表生成**:在大数据和BI领域,Apache POI能够帮助开发者快速生成数据报表,预计这一功能将会得到更加深入的挖掘和应用。
3. **文档内容分析**:利用POI提供的API,可以实现对文档的深入内容分析,如结构化数据提取,智能化的内容索引等。
4. **协作工具集成**:与各种在线协作工具的集成,如集成到在线文档编辑器中,实现文档的实时共享和协作编辑。
综上所述,Apache POI作为一款功能强大的Java库,在文档处理方面具有广泛的应用场景。未来,随着版本的不断更新和功能的不断扩展,它将继续为开发者提供更多的可能性和便利性。
```
# 6. Apache POI在云原生环境中的应用
## 6.1 云原生概念与Apache POI的结合
在当今的IT环境中,云原生技术的发展迅速,越来越多的应用需要部署在云平台上。云原生环境给Apache POI带来了新的应用场景和挑战。首先,我们需要理解云原生的基本概念,以及其对传统Java应用如Apache POI处理文档时的影响。
云原生是指软件应用在云端设计、构建、运行和管理的方式。这种模式有助于企业以更加灵活、可扩展和高效的方式运行其服务。云原生应用通常利用容器化技术,如Docker和Kubernetes,以便于在不同的云环境下一致地部署和管理。
云原生环境对Apache POI的影响主要表现在两个方面:一是POI应用的打包和部署方式;二是POI在处理大型文档时的资源优化问题。本章节将探讨如何将Apache POI集成到云原生应用中,并介绍一些优化技术和最佳实践。
### 6.1.1 Apache POI的容器化部署
容器化部署是云原生应用的一个核心特性,它可以帮助开发者封装应用及其依赖,保证应用在不同的环境中有相同的运行表现。使用Docker容器封装Apache POI应用,可以简化部署过程并减少环境间的不一致性问题。
例如,一个简单的Dockerfile用于部署Apache POI应用可能如下所示:
```Dockerfile
# 使用官方Java基础镜像
FROM openjdk:8-jdk-alpine
# 设置容器的工作目录
WORKDIR /app
# 将依赖文件复制到容器中
COPY pom.xml .
COPY src ./src
# 执行Maven构建命令
RUN mvn clean package
# 将构建好的应用复制到容器中
COPY target/my-poi-app.jar my-poi-app.jar
# 暴露端口(如果有需要)
EXPOSE 8080
# 运行应用
ENTRYPOINT ["java","-jar","/app/my-poi-app.jar"]
```
通过这个Dockerfile,开发者可以构建出一个包含Apache POI应用的容器镜像。之后,可以使用`docker build`和`docker run`命令轻松部署应用。
## 6.2 部署Apache POI应用到Kubernetes集群
Kubernetes是一个开源的容器编排系统,用于自动化容器化应用程序的部署、扩展和操作。在部署到Kubernetes时,通常需要创建一个yaml文件来描述POI应用的部署细节。
一个典型的Kubernetes部署配置文件`poi-deployment.yaml`可能如下所示:
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: poi-application
spec:
replicas: 3
selector:
matchLabels:
app: poi
template:
metadata:
labels:
app: poi
spec:
containers:
- name: poi-container
image: my-poi-app:latest
ports:
- containerPort: 8080
```
上述配置定义了一个名为`poi-application`的部署对象,其中包含3个副本,使用我们之前构建的Docker镜像`my-poi-app:latest`。接下来,可以使用`kubectl apply -f poi-deployment.yaml`命令应用这个配置,从而在Kubernetes集群中部署POI应用。
## 6.3 Apache POI在云原生环境中的性能优化
在云原生环境中,资源是动态分配和回收的,这可能会导致Apache POI应用在处理大型文档时遇到性能波动。因此,在云原生环境中部署POI应用时,需要考虑性能优化策略。
### 6.3.1 使用本地存储提升I/O性能
针对Apache POI处理大型文件时的I/O瓶颈问题,可以考虑使用持久化卷(Persistent Volume)挂载到容器中,提供本地存储访问。这样可以减少网络I/O的影响,提高文档读写速度。
在Kubernetes中配置持久化卷可以如下:
```yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: poi-pv-claim
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
```
然后,在POI应用的部署配置中,将其作为卷挂载到容器内的特定目录:
```yaml
volumeMounts:
- name: poi-storage
mountPath: "/data"
volumes:
- name: poi-storage
persistentVolumeClaim:
claimName: poi-pv-claim
```
通过这种方式,POI应用就可以直接访问挂载的本地存储,提高文档处理的效率。
### 6.3.2 利用自动扩展优化资源管理
在Kubernetes集群中,可以根据实际的负载情况,动态调整POI应用的副本数量。通过定义Horizontal Pod Autoscaler(HPA),当应用的负载增加时,可以自动增加更多的POI应用实例来处理额外的工作负载。
以下是一个HPA配置示例:
```yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: poi-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: poi-application
minReplicas: 3
maxReplicas: 10
targetCPUUtilizationPercentage: 80
```
这个配置说明,当POI应用的CPU使用率超过80%时,会自动扩展副本数到最大10个。这样可以确保在处理大量文档时,POI应用始终有足够的资源来处理请求。
## 6.4 云原生环境中的Apache POI应用监控与日志
在云原生环境中,监控和日志管理是确保应用稳定运行的关键。通过集成云监控和日志服务,开发者可以实时了解应用的运行状况并快速响应潜在的问题。
### 6.4.1 使用Prometheus和Grafana进行应用监控
Prometheus是一个开源的监控系统,适用于记录各种实时时间序列数据。结合Grafana,可以创建直观的仪表板来展示监控数据。
在Kubernetes中部署Prometheus和Grafana的步骤包括:
1. 使用Helm包管理工具安装Prometheus Operator。
2. 创建一个Prometheus实例来收集应用指标。
3. 安装Grafana并配置数据源为Prometheus。
4. 在Grafana中创建仪表板以展示Apache POI应用的性能指标。
### 6.4.2 集成云原生日志解决方案
Kubernetes支持多种日志解决方案,如ELK(Elasticsearch, Logstash, Kibana)堆栈和Loki。开发者可以选择适合的方案,将POI应用的日志集中收集和分析。
以使用Loki为例,步骤如下:
1. 部署Loki到Kubernetes集群中。
2. 通过Promtail代理收集POI应用的日志。
3. 使用Grafana配置Loki作为数据源,并创建日志查询仪表板。
通过这些方法,开发者可以有效地监控和记录Apache POI应用在云原生环境中的运行情况,从而快速地响应可能出现的问题。
至此,我们已经讨论了如何将Apache POI应用迁移到云原生环境,并介绍了容器化部署、在Kubernetes集群中部署POI应用、以及如何进行性能优化和监控。在后续的章节中,我们将深入探讨Apache POI在不同云服务平台的具体应用案例和最佳实践。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以 Apache POI 为核心,深入探讨了 Java 开发者在文档操作方面的各种技术和实践。从入门基础到高级技巧,从 Word 文档自动化处理到 Word 到 PDF 的无缝转换,再到动态文档生成和 PDF 格式化优化,专栏全面覆盖了文档操作的方方面面。同时,专栏还提供了性能提升秘诀、兼容性保障、模块化构建、持续集成实战、模板设计艺术、微服务应用案例等实用内容,帮助开发者高效解决文档处理中的各种挑战。无论是初学者还是经验丰富的开发者,都可以从本专栏中找到有价值的知识和见解。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【ArchestrA IDE新手到高手】:掌握12个实用技巧和高级功能

# 摘要
ArchestrA IDE作为一款功能强大的集成开发环境,提供了从基础到高级的全方位开发支持。本文首先概述了ArchestrA IDE的基本功能,紧接着深入探讨了实用技巧、高级功能,并通过实战案例分析展示了其在工业自动化和
从零开始学习STK:界面布局与基础设置,成为专家

# 摘要
本文主要介绍卫星工具包(STK)的基础知识、界面布局、设置技巧、实操练习以及分析工具的运用和项目实战案例。首先,对STK的基本概念和安装方法进行了介绍。随后,深入解析了STK界面布局,包括基本了解和高级操作,帮助用户更高效地进行自定义设置和操作。接着,本文详细讲解了STK的基础设置和高级设置技巧,包括时间、坐标系、卫星轨道、传感器和设备设置等。通过实操练习,引导用户掌握STK基本操作和高级应用实践,如卫星
SAP FI PA认证必经之路:C-TS4FI-2021考试概览

# 摘要
本文全面介绍了SAP FI PA认证的各个方面,旨在为准备C-TS4FI-2021考试的个人提供详细的指导。首先概述了认证的基本信息,接着详细解析了考试内容,包括核心模块功能和重要的财务主题。此外,本文还探讨了实战技巧,如考试形式、高效学习方法及应对考试压力的策略。文章进一步分析了认证后的职业发展路径,包括职业机会、行业需求和持续专业成
功率因数校正全攻略:PFC电感的作用与优化技巧

# 摘要
本文首先介绍了功率因数校正(PFC)的基础知识,随后深入探讨了PFC电感的作用和设计原理,包括电感的基础概念、设计要素和性能优化方法。在实践应用章节中,文章分析了PFC电感在不同类型的PFC系统中的应用案例,以及如何进行测试、性能评估和故障诊断。文章第四章着重于PFC电感的制造工艺和材料选择,同时考虑了其环境适应
OrCAD-Capture-CIS层次化设计术:简化复杂电路的管理之道
# 摘要
本文系统地介绍了OrCAD Capture CIS及其层次化设计的基本理念与实践方法。首先概述了OrCAD Capture CIS的基本功能和应用,接着深入探讨了层次化设计的理论基础和复用的重要性,以及它对项目管理与产品迭代的正面影响。文章还详细介绍了如何在OrCAD Capture CIS中实现层次化设计,并通过案例分析展示了层次化设计在实际复杂电路中的应用与效益。最后,文章探讨了层次化设计的优化策略、版本控制与团队协作的重要性,并对其未来发展趋势和最佳实践进行了展望。
# 关键字
OrCAD Capture CIS;层次化设计;设计复用;电路设计;版本控制;团队协作
参考资源
中国移动故障管理:故障分析的科学方法,流程揭秘

# 摘要
本文旨在全面概述中国移动故障管理的实践和理论,强调故障管理对于维护通信系统稳定运行的重要性。通过分析故障管理的定义、重要性以及理论基础,本文详细介绍了故障分析的科学方法论,包括问题解决的五步法、故障树分析法(FTA)和根本原因分析(RCA)。接着,本文详解了故障分析流程,涵盖故障的报告、记录、诊断、定位以及修复和预防策略。通过实际案例分析,本文提供了故障管理在移动网络和移动服务中的应用实例。最后,本文
图腾柱电路元件选型宝典:关键参数一网打尽

# 摘要
图腾柱电路作为一种高效能、低阻抗的电路结构,在数字电子设计中广泛应用。本文首先介绍了图腾柱电路的基本概念和关键参数,继而深入解析其工作原理和设计基础,特别关注了图腾柱电路的不同工作模式及其关键电路参数。在元件选型部分,本文提供了详细的逻辑门IC选型技巧、驱动能力优化方
Fluent故障排除专家课:系统性故障排除与故障排除策略

# 摘要
本文全面探讨了Fluent故障排除的理论与实践,提供了从基础概念到高级应用的完整故障排除知识体系。文章首先概述了故障排除的重要
【数字滤波器设计】:DSP面试中的5大必考技能
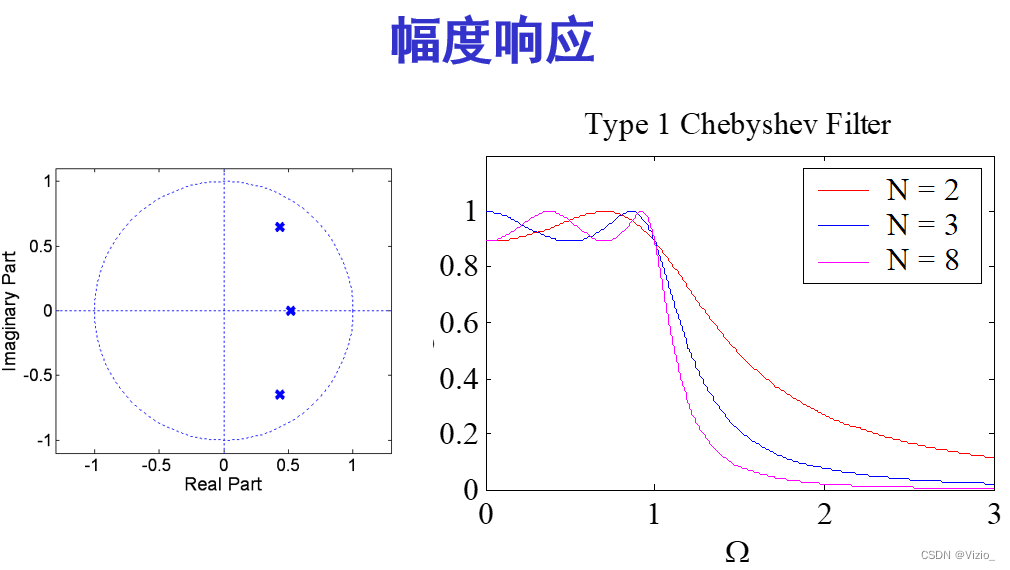
# 摘要
本文系统地介绍了数字滤波器的设计基础、理论方法和实践应用。首先,概述了数字滤波器的基本概念、分类以及数字信号处理的基础知识。接着,详细探讨了滤波器的设计方法,包括窗口法、频率采样法和最优化设计技术。第三章重点分析了数字滤波器设计工具的使用,以及在数字信号处理器(DSP)中实现滤波器算法的案例。文章还讨论了进阶技巧,如多速率信号处理和自适应滤波器设计,并展望了滤波器设计技术的未来趋势,包括深度学习的应
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )