【全面解析MySQL架构】:从存储引擎到查询优化的终极指南
发布时间: 2024-12-06 22:10:52 阅读量: 11 订阅数: 18 

MySQL数据库项目深度解析: 存储引擎、查询优化与高可用
# 1. MySQL架构概述
MySQL是一种流行的开源关系型数据库管理系统(RDBMS),以其高性能、可靠性、易用性和灵活性而著称。为了深入理解MySQL,我们首先需要了解其核心架构,包括客户端、服务器以及存储引擎的概念。
## 1.1 MySQL架构总览
MySQL的架构大致可以划分为连接层、服务层、引擎层和文件系统。连接层负责处理客户端连接、授权认证以及安全通信;服务层包含SQL解析器、优化器以及缓存等关键组件;存储引擎层则负责具体的数据存储和提取操作;最底层是文件系统,用于实际的数据文件存储。
## 1.2 关键组件作用
- **连接管理器**:负责建立和维护与客户端的连接,执行认证授权等操作。
- **SQL接口**:提供用户执行SQL语句的接口。
- **查询解析器**:将用户的SQL语句解析成解析树。
- **优化器**:选择最优化的查询路径。
- **缓存**:缓存查询结果以提高性能。
- **存储引擎API**:提供接口给存储引擎来处理数据存储和检索。
通过这些核心组件,MySQL能够在用户提交查询请求后,高效地从磁盘获取数据并返回给用户。随着我们深入了解,我们将探索这些组件如何协同工作,以及如何对它们进行调优以提高性能。
# 2. 深入存储引擎
## 2.1 存储引擎的作用与分类
### 2.1.1 存储引擎的基本概念
存储引擎是MySQL数据库架构中的一个重要组件,它是用来处理数据的读写请求和管理数据文件的组件。不同的存储引擎提供不同的功能和特性,允许用户根据实际需要选择最合适的存储引擎以满足特定的需求。
在数据库中,存储引擎通过一组API与服务器进行交互,这些API处理各种操作如:数据的增删改查,索引管理等。通常情况下,用户在创建表时可以选择存储引擎,不同的存储引擎对于性能、事务支持、锁定水平等方面有着不同的影响。
### 2.1.2 常见存储引擎的比较分析
在MySQL中,最常使用的存储引擎包括InnoDB和MyISAM,它们各有千秋:
- **InnoDB**:InnoDB是MySQL的默认存储引擎,提供了事务支持、行级锁定和外键约束等高级特性。它支持MVCC(多版本并发控制),这对于高并发场景非常重要。InnoDB也支持完整的ACID事务。
- **MyISAM**:MyISAM是另一种广泛使用的存储引擎,它以读取和插入操作的性能优秀著称。相比于InnoDB,它不具备事务功能,不支持行级锁定,且只有表级锁定。但它在某些查询密集型的应用中仍然非常有效。
除了这些,还有其他如Memory、Archive、CSV等存储引擎,每个都有其特定的适用场景。如Memory引擎把数据存储在内存中,适合于频繁读取的数据;Archive存储引擎适合存储大量的日志数据,并且提供了压缩功能。
## 2.2 InnoDB存储引擎
### 2.2.1 InnoDB的架构与特性
InnoDB存储引擎是MySQL中最为复杂和功能强大的存储引擎。InnoDB具有以下几个显著的架构特点和特性:
- **事务处理**:InnoDB支持事务,并且是行级锁定。它采用多版本并发控制(MVCC)以支持高并发事务处理,同时保证数据的完整性和一致性。
- **外键约束**:InnoDB支持外键,有助于维护数据库中不同表之间的数据的完整性。
- **缓冲池**:InnoDB使用缓冲池来提高性能,缓冲池中缓存了数据和索引,使得频繁访问的数据能够快速被读取。
- **双写缓冲区**:InnoDB引入了双写缓冲区来防止损坏,确保数据页的一致性,特别是当发生系统崩溃时。
### 2.2.2 InnoDB的事务处理机制
InnoDB的事务处理机制是它区别于其他存储引擎的核心特性之一。InnoDB支持ACID事务,以下是一些关键点:
- **原子性**:InnoDB通过日志文件如Redo Log记录所有事务操作,确保了事务的原子性。如果事务失败,它可以使用日志文件回滚到操作前的状态。
- **一致性**:InnoDB确保在发生故障时,数据仍然保持一致状态。这通过事务日志和检查点机制来实现。
- **隔离性**:InnoDB提供了不同的事务隔离级别,如读未提交(RU)、读已提交(RC)、可重复读(RR)和串行化(SERIALIZE),以满足不同的业务需求。
- **持久性**:一旦事务提交,所作的更改会被永久保存到数据库中,即使系统崩溃也不会丢失。
## 2.3 MyISAM存储引擎
### 2.3.1 MyISAM的结构特点
MyISAM存储引擎是MySQL早期版本中默认的存储引擎,它有着自己的结构特点:
- **表级锁定**:MyISAM使用表级锁定机制,这意味着当一个线程对表进行写操作时,其他线程必须等待,这在高并发情况下可能成为瓶颈。
- **压缩表和索引**:MyISAM存储引擎支持对表进行动态或静态压缩。这有助于节省磁盘空间和内存使用,尤其是在处理只读数据时。
- **全文索引**:MyISAM提供了全文索引功能,非常适合于需要快速的全文搜索的应用。
### 2.3.2 MyISAM与性能优化
在使用MyISAM存储引擎时,有一些性能优化的方法可以考虑:
- **表锁定管理**:在操作MyISAM表时,需要合理安排表的读写顺序,减少锁定时间。
- **键缓存**:可以配置多个键缓存来优化MyISAM表的索引访问速度。
- **文件系统选择**:MyISAM将数据和索引存储在单独的文件中,选择一个高性能的文件系统对性能有很大影响。
- **定期优化表**:通过OPTIMIZE TABLE命令定期优化表结构和索引可以提高MyISAM的性能。
在本章节中,我们详细介绍了存储引擎的分类,以及MySQL中最常用的两个存储引擎InnoDB和MyISAM的具体特性和优化方法。在实际应用中,选择合适的存储引擎对于数据库的性能和可靠性有着重要的影响,所以理解不同存储引擎的特性对于数据库管理员来说是非常必要的。接下来的章节将深入探讨数据存储机制和索引策略,为我们提供更全面的数据库性能优化视角。
# 3. 数据存储与索引策略
## 3.1 数据存储机制
### 3.1.1 表的逻辑结构与物理存储
MySQL中的数据表在逻辑上可以看作由行和列组成的关系型数据结构,但在物理存储上,则依赖于所选的存储引擎。在讨论存储引擎之前,了解表的逻辑结构与物理存储之间的差异,对于设计高效的数据表至关重要。
逻辑结构指的是表的schema,即数据的类型、长度、约束等信息,这些信息定义在表的创建语句中,并存储在系统表空间(system tablespace)或表的表空间(tablespace)。物理存储,则涉及到数据文件如何在磁盘上存储,包括数据文件、索引文件、事务日志文件等。
在InnoDB存储引擎中,数据是以页(Page)为单位存储的,默认页大小为16KB。InnoDB将数据和索引都存储在页中,这些页又被组织成区(Extent),一个区包含64个连续的页。表的逻辑结构被映射到这些页上,形成了InnoDB的聚簇索引(Clustered Index)。聚簇索引决定了数据在物理上的存储顺序,使得主键索引的查询非常迅速。
MyISAM存储引擎则使用不同的物理存储方式。它将数据文件(.MYD)和索引文件(.MYI)分开存储。数据文件包含了所有的行数据,而索引文件则包含了表的索引信息。MyISAM不使用聚簇索引,所以主键和非主键索引在物理存储上是分开的。
### 3.1.2 数据文件的组织方式
数据文件的组织方式对于性能有着极大的影响。理解数据文件是如何组织的,可以帮助我们进行更合理的数据库设计和优化。
在InnoDB存储引擎中,数据文件被组织成一个或多个表空间。这些表空间可以被细分为段(Segment)、区(Extent)和页(Page)。这种多级结构保证了存储空间的有效利用,并且让数据更加集中,减少了磁盘I/O操作,从而提升了性能。
而MyISAM存储引擎将每张表的数据存储在一个单独的`.MYD`文件中,索引存储在`.MYI`文件中。由于索引和数据是分离的,这可能导致大量的随机I/O操作,尤其是在涉及到大量索引的情况下。
在选择存储引擎时,需要根据实际的应用场景来决定如何组织数据文件。比如,如果事务处理和一致性是首要考虑的因素,则InnoDB是更好的选择;如果表数据主要用于读取,且更新操作不频繁,MyISAM可能是一个更优的存储方式。
## 3.2 索引原理与实践
### 3.2.1 索引的类型与选择
索引是数据库中提高查询效率的重要数据结构,它能够加快数据检索的速度,但同时也会增加数据库的存储开销以及降低插入、更新和删除操作的速度。
MySQL支持多种类型的索引:
- B-Tree索引:这是最常见的索引类型,支持键值的排序访问。在MySQL中,InnoDB和MyISAM存储引擎默认使用的是B-Tree索引。
- 哈希索引:基于哈希表实现,只能用于精确匹配的查询,并且对于数据的排序无能为力。
- 全文索引(Full-Text):用于全文搜索,主要用来在文本数据中搜索关键词。
- 空间索引(Spatial):用于地理数据类型,用来处理地理空间数据。
索引的选择需要根据具体的查询模式和数据特性来决定。例如,对于经常用于查询条件的字段,建立索引能显著提高查询性能。但是,索引也不是越多越好,过多的索引会增加维护成本和写操作的负担。通常,我们会对主键、外键、经常用于查询的列以及经常需要排序、分组的列建立索引。
### 3.2.2 索引的创建与优化
创建索引是提高数据库查询效率的关键步骤,但创建索引并不是简单的过程。在创建索引时,需要考虑如下因素:
- 选择合适的列:对于经常用于查询条件的列创建索引,但避免对经常更新的列或者数据重复度高的列创建索引。
- 索引的列顺序:对于多列索引,需要考虑查询条件中列的顺序,因为查询条件和索引列顺序不匹配时可能不会使用索引。
- 考虑索引的碎片:随着时间的推移,表中数据的增删改会造成索引出现碎片。定期使用`OPTIMIZE TABLE`语句,或者在某些情况下重建索引,可以减少碎片,提高查询效率。
在创建索引时,应使用`CREATE INDEX`语句,例如:
```sql
CREATE INDEX idx_column_name ON table_name (column_name);
```
优化索引时,可以使用`EXPLAIN`语句来查看查询的执行计划,了解是否利用了索引:
```sql
EXPLAIN SELECT * FROM table_name WHERE column_name = 'value';
```
如果发现查询没有使用索引,需要检查上述因素是否合理,并考虑是否需要调整索引策略。
索引的维护和优化是一个持续的过程,需要不断地通过监控和分析来调优索引策略。合理的索引可以大大提高数据操作的效率,但如果索引策略不当,反而会成为性能的瓶颈。
在接下来的章节中,我们将继续探讨查询优化和执行计划分析,这将帮助我们进一步提高数据库查询的性能。
# 4. 查询优化与执行计划分析
在处理大量数据和复杂查询时,优化MySQL的查询执行是提高数据库性能的关键。一个精心设计的查询不仅能够减少数据的检索时间,还能减少服务器的负载。本章节将深入探讨查询优化,以及如何通过执行计划分析来识别和改进潜在的性能瓶颈。
## 4.1 查询执行过程解析
### 4.1.1 SQL语句的解析与预处理
当用户执行一个SQL查询时,MySQL首先会对该语句进行解析和预处理。解析阶段,服务器将SQL语句的文本字符串转换成一个查询树(query tree),这是一种内部数据结构,用于表示SQL语句中的各种元素,例如表、列、表达式等。预处理阶段包括检查查询语法正确性、表和列的名称是否存在、确定数据类型以及确定是否需要权限来执行该语句。
```sql
SELECT * FROM users WHERE id = 1;
```
在上述示例中,`SELECT`语句首先被解析成查询树,然后进行预处理以验证`users`表和`id`列的有效性。
### 4.1.2 查询执行的内部流程
查询执行的内部流程涉及多个步骤,包括确定查询的执行计划、执行实际的数据检索以及返回结果集。执行计划是查询优化器生成的一系列操作指令,用以高效地从数据库中检索数据。优化器会考虑多种因素来确定最佳的查询路径,如表的大小、可用索引、查询条件等。
### 代码逻辑分析
查询执行的伪代码逻辑可简单表示为:
```pseudo
function execute_query(query)
parsed_query = parse(query) // 解析查询语句
if not validate(parsed_query)
return error // 验证失败,返回错误
execution_plan = optimizer.determine_plan(parsed_query) // 生成执行计划
result_set = executor.execute(execution_plan) // 执行计划
return result_set // 返回结果集
```
在实际的MySQL实现中,这个过程涉及到多个组件和优化技术,如索引选择、join算法选择、子查询处理等。
## 4.2 执行计划的获取与解读
### 4.2.1 EXPLAIN命令的使用
为了理解MySQL是如何执行特定查询的,可以使用`EXPLAIN`命令获取查询的执行计划。该命令不执行查询,而是显示了查询的执行方式。
```sql
EXPLAIN SELECT * FROM users WHERE age > 30;
```
执行上述命令后,MySQL会返回一个结果集,其中包含了诸如`id`, `select_type`, `table`, `type`, `possible_keys`, `key`, `key_len`, `ref`, `rows`, `filtered`, `Extra`等字段,这些字段提供了关于查询执行的详细信息。
### 4.2.2 基于执行计划的查询优化
通过解读`EXPLAIN`命令的输出,可以判断查询是否可以优化。例如,如果`type`字段显示为`ALL`,意味着MySQL对表进行了全表扫描,这时可能需要考虑添加合适的索引来优化该查询。
```sql
EXPLAIN SELECT * FROM users WHERE name = 'Alice';
```
如果显示`possible_keys`为NULL,而`key`也为NULL,这表明没有合适的索引被用于查询,此时添加索引可能会显著提高查询性能。
## 4.3 常见查询优化技巧
### 4.3.1 索引失效与解决方案
索引失效是数据库性能问题的常见原因。索引失效通常发生在查询条件不符合索引的排序规则时,或者使用了函数操作导致索引无法使用。例如:
```sql
SELECT * FROM users WHERE YEAR(birthdate) = 1990;
```
在这个例子中,虽然`birthdate`字段上有索引,但由于`YEAR()`函数的使用,索引无法被应用。优化此类查询的一个方法是避免在索引列上使用函数,或者创建一个包含该函数结果的函数索引。
### 4.3.2 子查询与联接的性能对比
在某些情况下,子查询可能会比联接查询执行得更慢。子查询在每个外部查询行上执行一次,这可能导致大量的重复计算。相比之下,联接查询可以在一个单一的操作中完成相同的工作,这通常更加高效。
```sql
-- 子查询版本
SELECT * FROM orders WHERE customer_id IN (SELECT id FROM customers WHERE active = 1);
-- 联接版本
SELECT orders.* FROM orders JOIN customers ON orders.customer_id = customers.id WHERE customers.active = 1;
```
通过对比执行计划,可以明显看出联接版本的查询性能更优,因为优化器可以更有效地使用索引,并且减少了重复的查找操作。
## 总结
查询优化和执行计划分析是确保MySQL性能的关键环节。通过使用`EXPLAIN`命令和其他分析工具,数据库管理员能够发现并解决查询性能问题。理解查询执行的内部流程、索引失效的原因,以及子查询与联接查询的性能差异,对于优化数据库查询至关重要。在实际应用中,不断监控和调整查询策略可以帮助维护一个高效、响应迅速的数据库系统。
# 5. MySQL高可用与扩展性
在现代的IT环境中,数据的高可用性和系统的扩展性对于提供稳定、可靠和高性能的服务至关重要。在本章节中,我们将深入探讨如何通过复制、分区、分片和集群技术来提升MySQL数据库的高可用性和扩展性。我们还将讨论负载均衡的最佳实践,以确保系统能够有效地应对高并发和大数据量的场景。
## 5.1 复制与主从架构
### 5.1.1 MySQL复制的工作原理
MySQL复制是一个将数据从一个MySQL数据库服务器(主服务器)复制到一个或多个MySQL数据库服务器(从服务器)的过程。复制操作是异步进行的,这意味着从服务器不需要与主服务器实时连接。
复制的工作流程如下:
1. **记录二进制日志(binlog)**:主服务器会记录所有对数据库的更改,并将这些更改写入二进制日志文件中。这些更改包括插入、更新、删除操作等。
2. **复制二进制日志**:从服务器连接到主服务器,并请求从上次复制停止的位置开始读取二进制日志文件。
3. **应用事件**:从服务器接收二进制日志事件并应用到自己的数据库中,执行与主服务器相同的数据更改。
### 5.1.2 主从同步的配置与故障排查
配置MySQL主从复制涉及一系列步骤,包括但不限于:
- 在主服务器上配置`server-id`,确保每个服务器ID是唯一的。
- 启用二进制日志记录,并定义一个唯一的日志文件名和偏移量。
- 在从服务器上设置`server-id`,并指定主服务器的地址、日志文件名和偏移量。
- 在从服务器上启动复制进程,并检查复制状态。
一旦配置完成,复制过程中可能会遇到的问题包括:
- **复制延迟**:由于网络延迟或资源限制,从服务器可能会落后于主服务器。
- **主键冲突**:如果两个服务器同时尝试插入具有相同主键的记录,可能会发生冲突。
- **数据一致性问题**:在复制过程中,可能会出现数据不一致的情况,特别是在多表更新的事务中。
故障排查通常涉及检查错误日志、查看复制状态,并使用`SHOW SLAVE STATUS`命令来识别复制过程中的问题。
## 5.2 分区与分片策略
### 5.2.1 分区的优势与类型
分区是将一个表的行数据分布到多个独立的物理结构中,这样做可以提高查询性能和管理大型表的能力。分区的优势包括:
- **提高查询效率**:针对特定分区的查询可以显著减少需要搜索的数据量。
- **优化管理操作**:分区表的维护操作如备份和修复可以并行进行,提高效率。
- **便于数据归档**:旧数据可以移动到较低性能的存储,而无需迁移整个表。
MySQL支持的分区类型包括:
- **范围分区**:根据列值范围分区。
- **列表分区**:根据列值列表分区。
- **散列分区**:根据哈希函数的结果分区。
- **键分区**:类似于散列分区,但使用列值的哈希。
- **组合分区**:结合上述分区类型,如范围-列表分区。
### 5.2.2 分片的策略与实践
分片是将数据表分散存储在多个数据库中,以提供更好的可伸缩性和性能。分片策略的选择取决于应用的具体需求和数据的访问模式。
分片策略的例子包括:
- **水平分片**:将表中的行分散到不同的服务器上。
- **垂直分片**:将表的列分散到不同的服务器上。
在实践中,分片可以动态地进行,以响应数据量的增长。分片也带来了复杂性,如跨分片的事务处理和数据一致性问题。
## 5.3 MySQL集群与负载均衡
### 5.3.1 集群技术的原理与应用
MySQL集群通过提供多个数据库服务器的冗余和分布式处理能力,增强了系统的可用性和性能。集群的原理基于以下几个概念:
- **数据冗余**:每个节点都持有数据的副本,这样即使某个节点失败,其他节点仍然可以提供数据。
- **负载分担**:读操作可以在多个节点间分担,以提高性能。
- **故障自动恢复**:集群应该能够自动检测和处理节点失败的情况。
在实际应用中,常见的MySQL集群解决方案包括:
- **MySQL Replication**:通过配置多个从服务器来实现简单集群。
- **InnoDB Cluster**:结合Group Replication,提供高可用性的解决方案。
### 5.3.2 负载均衡的配置与最佳实践
负载均衡是指分配工作负载到多个服务器的过程,以确保没有单一服务器过载。在MySQL环境中,负载均衡可以通过以下几种方式实现:
- **硬件负载均衡器**:使用专用硬件设备(如F5 BIG-IP)来分配数据库请求。
- **软件负载均衡器**:如HAProxy或Nginx,运行在标准服务器上,提供灵活的配置和优化。
- **DNS轮询**:通过周期性地更改DNS记录来分配请求到不同的服务器。
最佳实践包括:
- **会话保持**:确保来自同一客户端的请求总被路由到同一服务器。
- **健康检查**:定期检查服务器的健康状态,以避免将请求发送到故障服务器。
- **容错**:配置多个负载均衡器以提供高可用性。
在总结本章内容之前,以上阐述了MySQL实现高可用性和扩展性的多种技术,涵盖了复制、分区、分片、集群和负载均衡的原理、实践及配置方法。下一章,我们将探讨MySQL的安全性,包括认证、授权、审计和加密等关键概念。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《MySQL的ORM框架使用指南》专栏深入探讨了ORM框架在MySQL数据库中的应用。从SQL语言基础到MySQL架构的全面解析,再到ORM框架的内部原理和使用技巧,专栏提供了全面的知识体系。它涵盖了Hibernate、Entity Framework等流行框架的实战指南,以及ORM框架的性能调优、数据迁移、安全防护等高级主题。此外,专栏还提供了对象关系映射、单元测试、数据库API设计和复杂查询处理等方面的深入见解。通过阅读本专栏,读者可以全面掌握ORM框架在MySQL数据库中的使用,提升数据库交互效率,构建可靠、高效的数据访问层。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Fluent安装与配置全攻略】:第三章深入详解与最佳实践

参考资源链接:[Fluent 中文帮助文档(1-28章)完整版 精心整理](https://wenku.csdn.net/doc/6412b6cbbe7fbd1778d
【信号完整性与布线】:等长布线的原理与实践,专家级分析
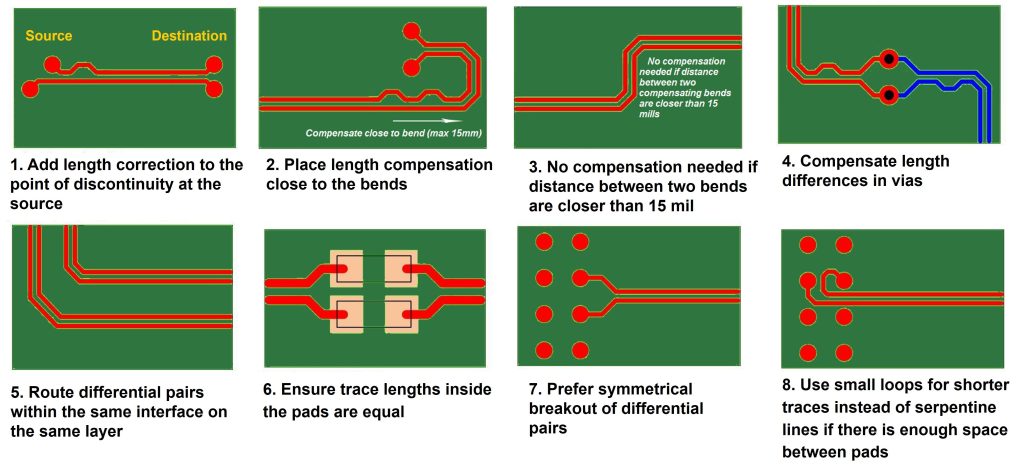
参考资源链接:[PCIe/SATA/USB布线规范:对内等长与延迟优化](https://wenku.csdn.net/doc/6412b727be7fbd1778d49479?spm=1055.2635.3001.10343)
# 1. 信号完整性与布线基础
## 1.1 信号完整性简介
在高速数
WinCC 7.2 Web发布与SCADA系统集成:实现工业自动化无缝对接

参考资源链接:[Wincc7.2Web发布操作介绍.docx](https://wenku.csdn.net/doc/6412b538be7fbd1778d425f9?spm=1055.2635.3001.10343)
# 1. WinCC 7.2 Web发布概述
随着工业4.0的推进,Web发布技术已成为连接企业与工业自动化系统的关键桥梁。WinCC 7.2作为一个工业自动化领域的强大工具,其Web发布功能为企业提供
【代码审查的艺术】:提升代码质量的有效方法

参考资源链接:[DeST学习指南:建筑模拟与操作详解](https://wenku.csdn.net/doc/1gim1dzxjt?spm=1055.2635.3001.10343)
# 1. 代码审查
【9899-202x并发编程革新】:内存模型与原子操作的全新视角
参考资源链接:[C语言标准ISO-IEC 9899-202x:编程规范与移植性指南](https://wenku.csdn.net/doc/4kmc3jauxr?spm=1055.2635.3001.10343)
# 1. 并发编程与内存模型基础
在现代计算机系统设计中,内存模型是构建高效并发程序不可或缺的基础。理解内存模型能帮助开发者编写出更加稳定、高效的并发代码。本章从基础层面探讨并发编程的基本概念,引入内存模型的概念,并简要介绍其在现代计算机系统中的重要性。
## 1.1 并发编程简介
并发编程是多线程或多进程环境下的一种编程范式。随着多核处理器的普及,合理利用并发技术已成为提升程序
【ITK-SNAP多模式应用】:不同类型图像抠图及Mask保存的策略(全面分析)
参考资源链接:[ITK-SNAP教程:图像背景去除与区域抠图实例](https://wenku.csdn.net/doc/64534cabea0840391e779498?spm=1055.2635.3001.10343)
# 1. ITK-SNAP简介及多模式图像处理基础
## 1.1 ITK-SNAP概述
ITK-SNAP是一个广泛应用于医学成像领域的开源软件,它集成了图像分割、3D注册、图像预处理等功能。其直观的用户界面和强大的算法支持,使得它在处理多模式图像时显得尤为出色。
## 1.2 多模式图像处理基础
在医学图像处理中,多模式图像指的是结合使用不同的成像技术得到的一系列图像,
【Windows 7 64位系统秘籍】:精通安装与优化SQL Server 2000的10大技巧

参考资源链接:[Windows7 64位环境下安装SQL Server 2000的步骤](https://wenku.csdn.net/doc/7du6ymw7ni?spm=1055.2635.3001.10343)
# 1
【永磁同步电机:20年经验的终极指南】:深入揭示电机性能与应用的关键

参考资源链接:[永磁同步电机电流与转速环带宽计算详解](https://wenku.csdn.net/doc/nood6mjd91?spm=1055.2635.3001.10343)
# 1. 永磁同步电机的理论基础
永磁同步电机(PMSM)以其高效率、高功率密度和优良的动态性能在现代电机技术中占据着重要地位。本章将对PMSM的基本原理和关键技术要素进行介绍,为后续章节中设计、
【Zynq-7000 SoC新手必读】:5分钟速览UG585,轻松入门Xilinx Zynq

参考资源链接:[ug585-Zynq-7000-TRM.pdf](https://wenku.csdn.net/doc/6401acf3cce7214c316edbe7?spm=1055.2635.3001.10343)
# 1. Zynq-7000 SoC概述
## Zynq-7000 SoC的架构简介
Zynq-700
【九齐单片机定时器_计数器应用】:NYIDE中高级计时技巧

参考资源链接:[NYIDE 8位单片机开发软件中文手册(V3.1):全面教程](https://wenku.csdn.net/doc/1p9i8oxa9g?spm=1055.2635.3001.10343)
# 1. 九齐单片机定时器与计数器基础
## 定时器与计数器概述
九齐单片机(如常见的9series)是微电子
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )