Linux环境下Oracle数据库安装准备工作详解
发布时间: 2024-02-25 06:21:44 阅读量: 51 订阅数: 24 

在Linux下安装Oracle数据库
# 1. 硬件和系统要求
1. **硬件要求**
在安装Oracle数据库前,首先需要确保硬件满足Oracle的要求。一般来说,硬件要求包括至少2GB的内存,10GB的硬盘空间,以及特定的CPU要求。如果硬件不符合这些要求,可能会导致安装过程中的性能问题或者失败。
2. **操作系统选择**
Oracle数据库可以运行在多种操作系统上,比如Linux、Windows、Unix等。在本文中,我们将以Linux操作系统为例进行安装说明。在选择操作系统时,需要注意Oracle数据库支持的版本和兼容性。
3. **硬件和系统的准备工作**
在安装Oracle数据库之前,还需要进行一些硬件和系统的准备工作,包括但不限于:确保硬盘空间充足、操作系统版本符合要求、关闭防火墙、安装必要的软件工具等。这些准备工作将有助于顺利完成Oracle数据库的安装。
# 2. Oracle数据库软件下载与安装
在这一章节中,我们将详细介绍如何在Linux环境下进行Oracle数据库软件的下载与安装。
1. **下载Oracle数据库软件**
- 首先,访问Oracle官方网站,进入软件下载页面。
- 选择适合您操作系统版本的Oracle数据库软件,并点击下载按钮开始下载。
```shell
# 在Linux命令行中使用wget命令下载Oracle数据库软件安装包
wget https://www.oracle.com/database/enterprise-edition/downloads/
```
- 下载完成后,解压文件并进入解压后的目录。
2. **安装Oracle数据库软件**
- 在解压后的目录中找到安装文件,并执行安装命令。
```shell
# 执行Oracle数据库软件的安装命令
./runInstaller
```
- 根据安装向导的提示,选择安装类型、安装路径等参数,并点击“安装”按钮开始安装过程。
3. **配置Oracle数据库软件**
- 安装完成后,按照安装向导的提示进行必要的配置,包括数据库名称、监听端口、管理员密码等信息。
```sql
-- 在SQL命令行中配置Oracle数据库实例
CREATE DATABASE mydb
USER sys IDENTIFIED BY mypassword
USER system IDENTIFIED BY mypassword
LOGFILE GROUP 1 ('/u01/oradata/mydb/redo01.log') SIZE 100M,
GROUP 2 ('/u01/oradata/mydb/redo02.log') SIZE 100M
MAXLOGFILES 5
MAXLOGHISTORY 100
MAXDATAFILES 100
MAXINSTANCES 1
CHARACTER SET AL32UTF8;
```
- 配置完成后,启动Oracle数据库服务,检查服务状态并验证数据库是否正常运行。
通过以上步骤,您可以成功下载并安装Oracle数据库软件,并进行必要的配置,使其可以在Linux环境下正常运行。在接下来的章节中,我们将介绍系统参数调整的相关内容。
# 3. 系统参数调整
在安装Oracle数据库之前,需要对系统参数进行调整以确保数据库软件能够正常运行。这包括对内核、网络和文件系统参数的调整。
#### 1. 内核参数调整
首先,我们需要对Linux操作系统的内核参数进行调整,以确保数据库能够正常运行。以下是一些常见的内核参数设置:
```bash
# 设置共享内存大小
sudo sysctl -w kernel.shmmax=4294967296
sudo sysctl -w kernel.shmall=2097152
# 设置最大进程数
sudo sysctl -w kernel.pid_max=65536
# 设置文件描述符数量
sudo sysctl -w fs.file-max=6815744
# 设置最大线程数
sudo sysctl -w kernel.threads-max=8192
```
#### 2. 网络参数调整
在安装Oracle数据库时,网络参数也是非常重要的。我们需要调整Linux系统的网络参数以确保数据库可以正常访问网络。
```bash
# 设置TCP连接保持时间
sudo sysctl -w net.ipv4.tcp_keepalive_time=300
sudo sysctl -w net.ipv4.tcp_keepalive_intvl=30
sudo sysctl -w net.ipv4.tcp_keepalive_probes=5
# 设置TCP连接最大保持时间
sudo sysctl -w net.ipv4.tcp_fin_timeout=30
```
#### 3. 文件系统参数调整
最后,我们还需要对文件系统参数进行调整,以提高数据库的性能和稳定性。
```bash
# 设置文件打开限制
sudo vi /etc/security/limits.conf
oracle soft nofile 1024
oracle hard nofile 65536
# 设置临时文件目录权限
sudo chmod 1777 /tmp
```
通过以上调整,可以提高Oracle数据库在Linux环境下的稳定性和性能,确保数据库软件能够顺利安装和运行。
# 4. 用户和权限设置
#### 1. 创建Oracle安装用户
在Linux环境下,为了安全起见,我们需要创建一个专门用于安装和管理Oracle数据库的用户。以下是创建Oracle安装用户的步骤:
```bash
# 创建一个名为oracle的用户
sudo useradd -m -s /bin/bash oracle
# 设置oracle用户的密码
sudo passwd oracle
```
#### 2. 设置用户环境变量
创建完用户之后,我们需要设置该用户的环境变量,以便后续安装和配置Oracle数据库时能够顺利进行。我们可以编辑oracle用户的.bash_profile文件来设置环境变量,例如:
```bash
# 切换至oracle用户
su - oracle
# 编辑.bash_profile文件
vi ~/.bash_profile
# 添加以下环境变量配置
export ORACLE_BASE=/opt/oracle
export ORACLE_HOME=$ORACLE_BASE/product/12.2.0/dbhome_1
export ORACLE_SID=orcl
export PATH=$PATH:$ORACLE_HOME/bin
# 保存并退出.bash_profile文件
```
#### 3. 设置用户权限和目录
在安装Oracle数据库之前,我们还需为oracle用户设置相应的权限和目录,以确保其具备执行安装和管理数据库的权限。以下是设置用户权限和目录的步骤:
```bash
# 创建安装目录并设置权限
sudo mkdir -p /opt/oracle
sudo chown -R oracle:oinstall /opt/oracle
sudo chmod -R 775 /opt/oracle
# 创建数据存储目录并设置权限
sudo mkdir -p /opt/oracle/oradata
sudo chown -R oracle:oinstall /opt/oracle/oradata
sudo chmod -R 775 /opt/oracle/oradata
```
以上是在Linux环境下针对Oracle数据库安装过程中用户和权限设置的详细步骤与代码示例。在安装Oracle数据库前,请务必按照上述步骤进行用户和权限的设置,以确保数据库能够顺利安装和运行。
# 5. 安装依赖软件
1. **安装依赖软件包**
在安装Oracle数据库之前,需要确保系统安装了必要的软件包。以下是在Linux环境下安装Oracle数据库所需的常见软件包:
```bash
# 安装必要的软件包
sudo yum install binutils -y
sudo yum install compat-libcap1 -y
sudo yum install compat-libstdc++-33 -y
sudo yum install compat-libstdc++-33.i686 -y
sudo yum install elfutils-libelf -y
sudo yum install elfutils-libelf-devel -y
sudo yum install fontconfig-devel -y
sudo yum install glibc -y
sudo yum install glibc.i686 -y
sudo yum install glibc-devel -y
sudo yum install ksh -y
sudo yum install libaio -y
sudo yum install libaio-devel -y
sudo yum install libXrender -y
sudo yum install libXrender-devel -y
sudo yum install libX11 -y
sudo yum install libXau -y
sudo yum install libXi -y
sudo yum install libXtst -y
sudo yum install libgcc -y
sudo yum install librdmacm-devel -y
sudo yum install libstdc++ -y
sudo yum install libstdc++.i686 -y
sudo yum install libstdc++-devel -y
sudo yum install libxcb -y
sudo yum install make -y
sudo yum install net-tools -y
sudo yum install nfs-utils -y
sudo yum install python -y
sudo yum install python-configobj -y
sudo yum install python-rtslib -y
sudo yum install python-six -y
sudo yum install targetcli -y
sudo yum install smartmontools -y
sudo yum install sysstat -y
sudo yum install unixODBC -y
sudo yum install unixODBC-devel -y
```
2. **配置依赖软件**
安装完依赖软件包后,需要进行相应的配置,确保软件包可以正常运行,例如设置环境变量、启动服务等。
```bash
# 配置依赖软件
# 设置环境变量
export LD_LIBRARY_PATH=$ORACLE_HOME/lib:$LD_LIBRARY_PATH
# 启动sysstat服务
sudo systemctl start sysstat
sudo systemctl enable sysstat
# 启动smartd服务
sudo systemctl start smartd
sudo systemctl enable smartd
# 启动nfs服务
sudo systemctl start nfs
sudo systemctl enable nfs
```
在安装依赖软件完成后,可以继续进行Oracle数据库的安装工作。
通过上述步骤,你可以在Linux环境下进行Oracle数据库前的依赖软件安装及配置工作。
# 6. 数据库安装前的检查与准备
在安装Oracle数据库之前,需要进行一系列的检查和准备工作,以确保安装过程顺利进行,并避免出现潜在的问题。
1. **确认安装前的准备工作**
在开始安装Oracle数据库之前,确保已经完成以下准备工作:
- 确保系统符合Oracle数据库的硬件和操作系统要求
- 确保已经下载了正确版本的Oracle数据库软件
- 确保系统参数已经进行了调整
- 确保已经创建了Oracle安装用户,并设置了必要的权限
- 确保安装了所需的依赖软件,并进行了相应的配置
2. **执行安装前的检查**
在执行安装前的检查之前,可以使用Oracle提供的预安装检查工具来检查系统是否满足安装要求。例如,在Linux系统下可以通过以下命令执行预安装检查:
```shell
./runInstaller -checkPrereqs
```
检查完成后,会输出相应的检查结果,确保系统符合要求后才能继续安装过程。
3. **备份重要数据**
在安装Oracle数据库之前,务必备份系统中重要的数据,以防安装过程中出现意外导致数据丢失。可以使用系统自带的备份工具,或者第三方备份软件进行数据备份操作。
通过以上的安装前准备工作,可以有效地减少安装过程中出现的问题,保障Oracle数据库的安装顺利进行。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以“Linux_Oracle 11g RAC安装与管理实战”为主题,涵盖了多篇文章,包括“Linux基础知识与使用技巧初探”,“Oracle 11g RAC架构与核心概念解析”,“Oracle 11g RAC安装与配置步骤详解”,“Linux下Oracle数据库安全管理与控制”,“Linux环境下Oracle数据库的安全备份与恢复实践”,以及“Oracle RAC集群与分布式数据库系统的异地多活部署”。在这些文章中,读者将从基础知识到实际操作,全面了解Linux和Oracle数据库的相关内容。无论是初学者还是有经验的管理员都能在本专栏中找到有价值的信息,学习到安装、配置、管理和安全等方面的实战技巧,为应对复杂环境下的挑战提供了解决方案。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【C#与汇川PLC通讯全攻略】:从入门到精通,打造高效通讯解决方案
# 摘要
本文详细探讨了C#语言与汇川PLC进行通信的全过程,包括基础连接、数据交互以及高级通讯功能的开发。文章首先介绍了C#在网络编程中的基本概念,包括TCP/IP和UDP协议以及Socket编程。随后,解析了汇川PLC通讯协议,并详细阐述了如何在C#中实现与汇川PLC的连接和数据交互,包括数据读取、写入、异常处理与日志记录。此外,文章还涵盖了高级数据处理技巧、多线程和异步通讯的实践应用,以及集成开发环境(IDE)的使用技巧。案例研究与最佳实践部分分析了典型应用,提出了构建高效通讯解决方案的策略,并对技术挑战和未来发展进行了展望。本研究旨在为工业自动化领域中C#与PLC通讯的开发者提供实用的
StarCCM+ FieldFunction函数全面指南:从基础到高级应用的5大秘诀

# 摘要
本文全面介绍了StarCCM+软件中的FieldFunction函数,详细阐述了该函数的基础知识、计算逻辑以及在模拟和高级主题中的应用。首先概述了FieldFunction函数的核心概念、定义及作用域,并提供了创建和编辑的步骤与技巧。其次,文章深入探讨了其计
Python并发编程:掌握多线程和多进程的6个高级技巧
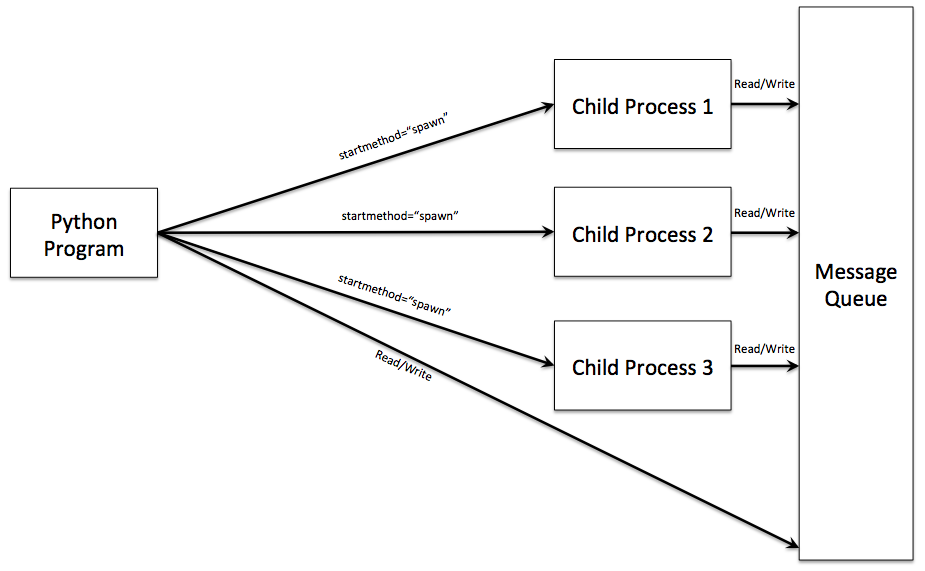
# 摘要
本文深入探讨了Python并发编程的核心概念与实践技巧,涉及多线程、多进程以及异步编程的技术细节和高级应用。首先,文章介绍了多线程的基础知识,包括线程模型和全局解释器锁(GIL),以及多线程编程的实践和高级应用。然后转向多进程编程,讲解了进程间通信和多进程的优势,及其在CPU密集型任务中的应用。接下来,文章讨论了同步工具的理论与实践,包括锁、信号量和条件变量,并展示了如何使用这些工具解决复杂的同步问题。在深入异步编程的章节
【数据分析实战技巧】:从清洗到条件排斥组的数据准备全攻略

# 摘要
数据分析作为数据科学的核心,涉及数据清洗、探索、处理以及高级应用等多个环节。本文首先介绍了数据分析的基础知识,随后深入探讨了数据清洗的技巧和工具,强调了对缺失数据的处理和实用工具如Excel和Pandas的应用。接着,本文阐述了数据探索的分析方法以及如何通过Matplotlib和Seaborn等工具进行有效的数据可视化。条件排斥与分组处
【高级应用揭秘】:如何在离散相模型中优化射流颗粒设置

# 摘要
离散相模型(Discrete Phase Model, DPM)在射流颗粒研究领域具有重要应用价值。本文首先介绍了离散相模型的基础理论及其在多个应用领域中的应用情况。第二章对射流颗粒设置的优化原理进行了详细分析,包括颗粒动力学方程、射流颗粒与流体的相互作用,以及射流速度和粒径分布、环境温度与压力等参数的影响。第三章探讨了数值模拟技术在优化射流颗粒过程中的应用,涵盖模拟软件的选择、参数设置、模拟步骤和案例分析。
物联网时代液位检测新范式:FDC2214的智能融合

# 摘要
本文深入探讨了物联网技术在液位检测领域的应用,特别聚焦于FDC2214芯片的原理和技术特点。章节涵盖FDC2214的电容式传感技术背景、工作原理、性能优势,以及基于该芯片构建的物联网液位检测系统的架构设计、实现和实践案例。重点分析了系统设计原理、传感器节点实现、通信协议选择和数据
【Matlab中的collect函数:高级技巧与案例分析】

# 摘要
本文全面介绍Matlab中的collect函数,首先概述了collect函数的基本概念及其在符号计算中的应用。接着,详细探讨了collect函数的基础使用技巧,包括参数的输入规则、返回值的类型和特点,以及在简化表达式、合并多项式等基础用例中的
PAS2050标准与可持续发展:实现环境与商业的和谐共存

# 摘要
PAS2050标准作为一种衡量产品碳足迹和生命周期环境影响的规范,旨在推动全球可持续发展目标的实现。本文首先概述了PAS2050标准的理论基础,包括可持续发展的定义、标准的制定背景和主要内容。随后,文章详细探讨了实施PAS2050标准的策略,如组织层面的准备、产品生命周期环境影响评估以及碳足迹的量化与报告。进一步地,通过商业实践案例分析,本文揭示了环境责任与企业竞争力的关系,以及企业在实施该标准过程中可能遇
【批量修改简化】:Word跨文档操作功能的深度解读
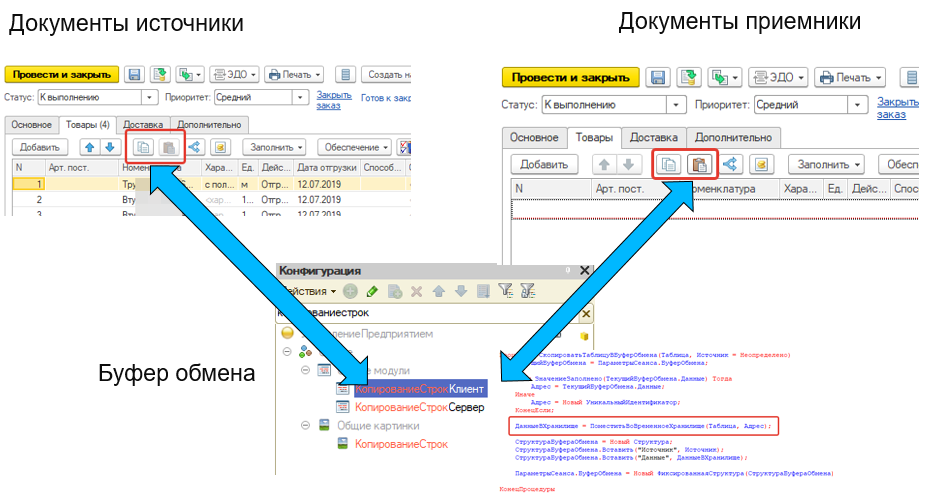
# 摘要
Word跨文档操作是提高文档处理效率和质量的关键技术,涵盖了从文档结构解析、技术原理、实践技巧到高级策略的全面探讨。本文首先介绍了Word文档的组织方式和标记语言XML分析,进而详细阐述了对象链接与嵌入(OLE)、文档对象模型(DOM)和VBA在实现跨文档操作中的核心作用。通过VBA脚本、宏和Word内置功能的实用技巧,本文为用户提供了批量处理和自动化操作的有效手段。此外,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )