求解器在数据科学中的作用:挖掘数据宝藏,释放无限潜力
发布时间: 2024-07-09 04:31:00 阅读量: 39 订阅数: 27 
# 1. 求解器在数据科学中的概述**
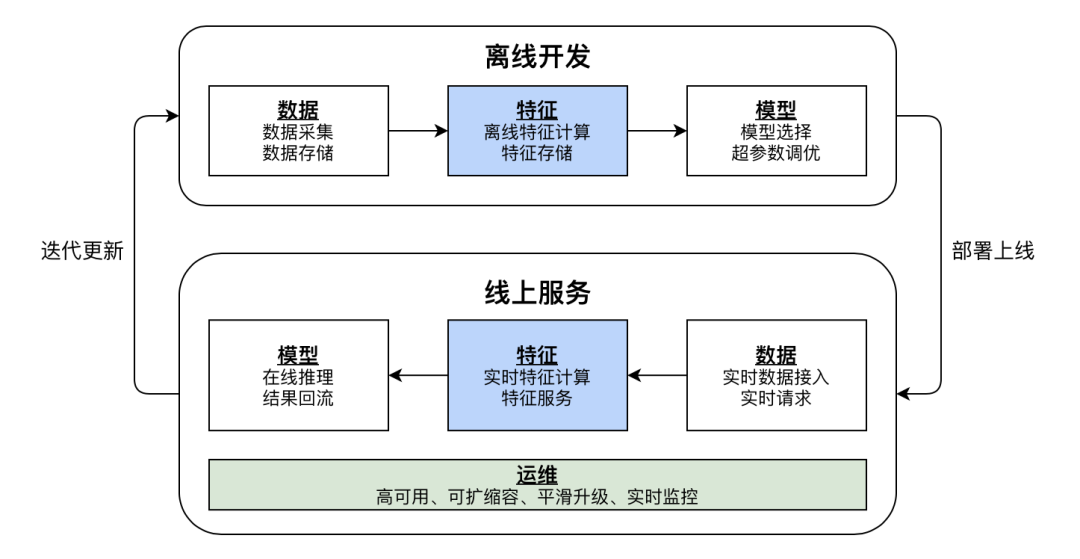
求解器是数据科学中不可或缺的工具,它们用于求解复杂数学问题,这些问题通常涉及优化或拟合数据。求解器通过迭代算法,逐步逼近最优解或最佳拟合,使数据科学家能够从数据中提取有意义的见解。
求解器在数据科学中扮演着至关重要的角色,它们被广泛用于各种任务,包括:
- **模型训练:** 求解器用于训练机器学习模型,如回归模型和分类器,通过最小化损失函数来调整模型参数。
- **超参数优化:** 求解器可以帮助优化模型的超参数,如学习率和正则化参数,以提高模型性能。
- **数据分析:** 求解器可用于执行复杂的数据分析任务,如主成分分析和聚类,以识别数据中的模式和结构。
# 2. 回归和分类
### 线性求解器的类型
线性求解器是一种用于求解线性方程组的算法。它们在数据科学中广泛应用于回归和分类任务。常见的线性求解器类型包括:
- **最小二乘法 (OLS)**:用于求解线性回归模型的参数,最小化预测值与真实值之间的平方误差。
- **岭回归 (Ridge Regression)**:OLS 的正则化版本,通过添加 L2 正则化项来防止过拟合。
- **套索回归 (Lasso Regression)**:OLS 的另一个正则化版本,通过添加 L1 正则化项来促进稀疏解。
- **逻辑回归 (Logistic Regression)**:用于求解二分类问题的线性模型,通过对数几率函数建模预测概率。
### 线性求解器在回归中的应用
回归是一种预测连续目标变量的技术。线性求解器可用于构建线性回归模型,该模型通过一组自变量预测目标变量。
**代码块 1:使用 Scikit-Learn 构建线性回归模型**
```python
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
# 加载数据
data = pd.read_csv('data.csv')
# 提取自变量和目标变量
X = data[['age', 'gender']]
y = data['salary']
# 创建线性回归模型
model = LinearRegression()
# 拟合模型
model.fit(X, y)
# 预测
predictions = model.predict(X)
```
**逻辑分析:**
- `LinearRegression` 类创建一个线性回归模型。
- `fit()` 方法使用最小二乘法拟合模型。
- `predict()` 方法使用拟合模型预测目标变量。
### 线性求解器在分类中的应用
分类是一种预测离散目标变量的技术。线性求解器可用于构建线性分类模型,该模型通过一组自变量预测目标变量的类别。
**代码块 2:使用 Scikit-Learn 构建逻辑回归模型**
```python
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
# 加载数据
data = pd.read_csv('data.csv')
# 提取自变量和目标变量
X = data[['age', 'gender']]
y = data['class']
# 创建逻辑回归模型
model = LogisticRegression()
# 拟合模型
model.fit(X, y)
# 预测
predictions = model.predict(X)
```
**逻辑分析:**
- `LogisticRegression` 类创建一个逻辑回归模型。
- `fit()` 方法使用最大似然估计拟合模型。
- `predict()` 方法使用拟合模型预测目标

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
“求解器”专栏深入探讨了求解器在各个领域的广泛应用,揭秘其神秘面纱,助力读者轻松入门。专栏文章涵盖求解器优化技巧、算法详解、机器学习、数据科学、金融、工程设计、供应链管理、生物信息学、图像处理、自然语言处理、推荐系统、优化问题、运筹学、计算机视觉、人工智能、医疗保健、教育、游戏开发和机器人技术等领域。通过深入浅出的讲解和实用秘诀,专栏旨在赋能读者掌握求解精髓,优化效率,挖掘数据宝藏,优化决策,提升设计效率,增强视觉感知,提升文本理解,打造个性化体验,解决复杂难题,优化资源配置,赋能图像分析,推动机器智能,提升医疗水平,助力知识传播,创造身临其境的体验,推动机器人智能化。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Django意大利本地化应用】:选举代码与社会安全号码的django.contrib.localflavor.it.util模块应用

# 1. Django框架与本地化的重要性
## 1.1 Django框架的全球影响力
Django是一个高级的Python Web框架,它鼓励快速开发和干净、实用的设计。自2005年问世以来,它已经成为全球开发者社区的重要组成部分,支持着数以千计的网站和应用程序。
## 1.2 本地化在Django中的角色
本地化是软件国际化的一部分,它允许软件适应不同地区
【Python库文件学习之odict】:数据可视化中的odict应用:最佳实践

# 1. odict基础介绍
## 1.1 odict是什么
`odict`,或有序字典,是一种在Python中实现的有序键值对存储结构。与普通的字典(`dict`)不同,`odict`保持了元素的插入顺序,这对于数据处理和分析尤为重要。当你需要记录数据的序列信息时,`odict`提供了一种既方便又高效的解决方案。
## 1.2 为什么使用odict
在数据处理中,我们经常需要保
Twisted.web.http自定义服务器:构建定制化网络服务的3大步骤
# 1. Twisted.web.http自定义服务器概述
## 1.1 Twisted.web.http简介
Twisted是一个事件驱动的网络框架,它允许开发者以非阻塞的方式处理网络事件,从而构建高性能的网络应用。Twisted.web.http是Twisted框架中处理HTTP协议的一个子模块,它提供了一套完整的API来构建HTTP服务器。通过使用Twisted.web.http,开发者可以轻松地创
【WebOb安全提升】:防御常见Web攻击的7大策略

# 1. WebOb与Web安全基础
## 1.1 WebOb的介绍
WebOb是一个Python库,它提供了一种用于访问和操作HTTP请求和响应对象的方式。它是WSGI标准的实现,允许开发人员编写独立于底层服务器的Web应用程序。WebOb的主要目的是简化HTTP请求和响应的处理,提供一个一致的接口来操作HTTP消息。
```python
from webob import Request
de
Distutils Spawn与Python打包最佳实践:构建跨平台Python包的10大技巧
# 1. Distutils Spawn概述
在Python编程领域,打包是将代码组织成模块、包,并提供给其他开发者或系统使用的重要步骤。Distutils是Python标准库中的一个模块,它提供了简单而强大的打包和分发工具,使得开发者可以轻松地创建、安装和分发Python包。
Distutils Spawn是Distutils的一个扩展,它
docutils.nodes节点转换与处理流程详解:掌握数据到文档的桥梁构建

# 1. docutils.nodes概述
在本章中,我们将深入探讨`docutils.nodes`模块,这是Python的一个文档处理库Docutils的核心组件。Docutils广泛用于文档编写、转换和发布,而`nodes`模块则
【Piston.Handler与数据库交互】:ORM和数据库操作的集成攻略
# 1. Piston.Handler与数据库交互概述
## 概述
在软件开发中,应用程序与数据库的交互是必不可少的一部分。Piston.Handler作为一种在Web开发中广泛使用的库,其数据库交互功能尤为重要。本文将深入探讨Piston.Handler与数据库的交互,包括ORM基础、数据库操作、实践应
Django 自定义模型字段:通过 django.db.models.sql.where 扩展字段类型

# 1. Django自定义模型字段概述
在Django框架中,模型字段是构成数据模型的基本组件,它们定义了数据库表中的列以及这些列的行为。在大多数情况下,Django提供的标准字段类型足以满足开发需求。然而,随着项目的复杂性和特定需求的增长,开发者可能需要自定义模型字段以扩展Django的功能或实现特
Cairo图形阴影技术:添加真实感阴影效果的终极技巧

# 1. Cairo图形阴影技术简介
## 1.1 Cairo图形库概述
Cairo图形库是一个开源的2D矢量图形库,它提供了一套丰富的API来绘制图形和渲染文本。其设计目标是提供跨平台的能力,并且能够输出到不同的目标设备,如屏幕、打印机、PDF文件等。
### 1.1.1 Cairo图形库的特点
Cairo的API设计简洁而强大,它支持多种图形操作,包括但不限于路径绘制、文
【Django Admin验证与异步处理】:设计和实现异步验证机制的4大步骤

# 1. Django Admin验证与异步处理概述
Django Admin作为Django框架内置的后台管理系统,为开发者提供了便捷的数据管理接口。然而,在实际应用中,我们常常需要对数据的输入进行验证,确保数据的正确性和完整性。第一章将概述Django Admin的验证机制和异步处理的基本概念,为后续章节的深入探讨奠定基础。
## 2.1 Django Admi
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )