MySQL数据库表结构设计:从新手到专家的进阶之路
发布时间: 2024-07-26 02:05:25 阅读量: 51 订阅数: 21 

Origin教程009所需练习数据
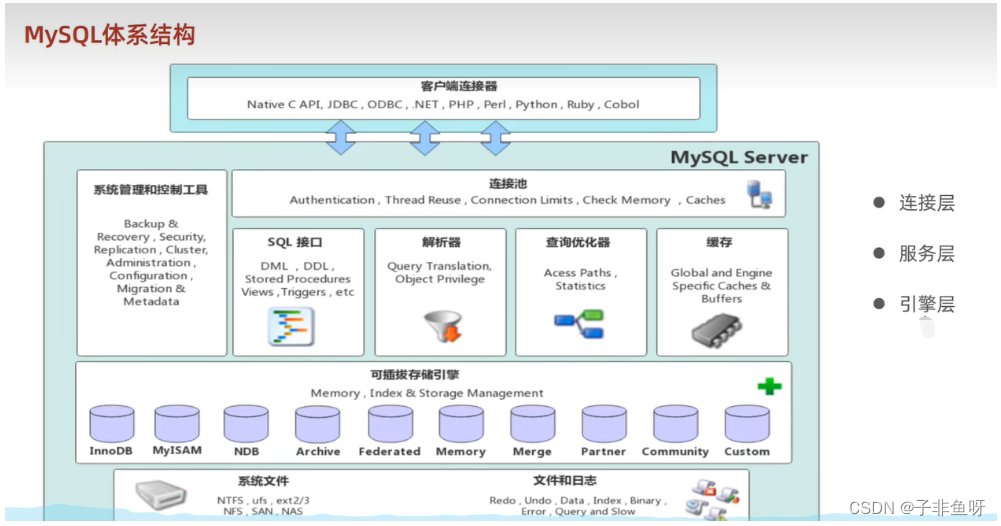
# 1. MySQL数据库基础
MySQL是一种流行的关系型数据库管理系统(RDBMS),它以其高性能、可扩展性和可靠性而闻名。本章将介绍MySQL数据库的基础知识,包括其架构、数据类型和基本操作。
### 1.1 MySQL架构
MySQL数据库由以下组件组成:
- **服务器**:管理数据库连接和处理查询的中央进程。
- **数据库**:一个包含相关表和数据的逻辑容器。
- **表**:一个存储特定类型数据的结构化集合。
- **行**:表中的一条记录,表示一个实体。
- **列**:表中的一列数据,表示实体的一个属性。
# 2. 表结构设计原则
### 2.1 规范化原则
规范化是数据库设计中的一组规则,旨在确保数据的一致性和完整性。它通过将数据分解成多个表来实现,每个表都包含特定类型的相关数据。规范化原则有三个级别:
**2.1.1 第一范式(1NF)**
1NF 要求表中的每一行都代表一个唯一的实体,并且每一列都包含该实体的一个属性。换句话说,表中不应有重复的数据组。
**2.1.2 第二范式(2NF)**
2NF 要求表中的每一列都与主键完全依赖。这意味着表中的每一列都应该直接与主键相关,而不是间接通过其他列相关。
**2.1.3 第三范式(3NF)**
3NF 要求表中的每一列都与主键直接依赖。这意味着表中的每一列都应该直接与主键相关,而不是通过其他非主键列间接相关。
### 2.2 数据类型选择
选择合适的数据类型对于优化数据库性能和数据完整性至关重要。MySQL 提供了多种数据类型,包括:
**2.2.1 数值类型**
* **INT**:用于存储整数
* **FLOAT**:用于存储浮点数
* **DECIMAL**:用于存储精确的十进制数
**2.2.2 字符串类型**
* **VARCHAR**:用于存储可变长度的字符串
* **CHAR**:用于存储固定长度的字符串
* **TEXT**:用于存储长文本
**2.2.3 日期和时间类型**
* **DATE**:用于存储日期
* **TIME**:用于存储时间
* **DATETIME**:用于存储日期和时间
### 2.3 索引设计
索引是数据库中用于快速查找数据的特殊结构。它们通过在表中的特定列上创建指向数据行的指针来工作。索引可以显着提高查询性能,尤其是当表中包含大量数据时。
**2.3.1 索引类型**
MySQL 提供了多种索引类型,包括:
* **B-Tree 索引**:最常用的索引类型,用于快速查找和范围查询。
* **哈希索引**:用于快速查找相等性查询。
* **全文索引**:用于对文本数据进行全文搜索。
**2.3.2 索引选择**
选择合适的索引对于优化查询性能至关重要。以下是一些选择索引的准则:
* 经常用于查询的列
* 具有高基数的列(即具有许多不同值的列)
* 用于连接的列
* 用于排序的列
```sql
-- 创建 B-Tree 索引
CREATE INDEX idx_name ON table_name (column_name);
-- 创建哈希索引
CREATE INDEX idx_name USING HASH ON table_name (column_name);
-- 创建全文索引
CREATE FULLTEXT INDEX idx_name ON table_name (column_name);
```
# 3.1 创建表结构
#### 3.1.1 使用CREATE TABLE语句
```sql
CREATE TABLE table_name (
field1 data_type [NOT NULL] [DEFAULT default_value],
field2 data_type [NOT NULL] [DEFAULT default_value],
...
PRIMARY KEY (field1, field2)
);
```
**参数说明:**
- `table_name`: 表名
- `field1`, `field2`, ...: 字段名
- `data_type`: 字段的数据类型(如INT、VARCHAR、DATE等)
- `NOT NULL`: 指定字段不能为NULL
- `DEFAULT default_value`: 指定字段的默认值
- `PRIMARY KEY (field1, field2)`: 指定主键,可以指定多个字段作为联合主键
**代码逻辑分析:**
1. `CREATE TABLE` 语句创建一张新表。
2. 表名后面括号内的字段列表定义

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到我们的 MySQL 数据库创建数据库专栏,这里为您提供打造数据库的终极秘籍。从数据库创建指南到表结构设计原则,再到索引原理详解和锁机制分析,我们为您提供全面的指导,帮助您轻松上手 MySQL 数据库。通过深入探讨常见问题和案例分析,您将掌握创建、设计和优化 MySQL 数据库的精髓。无论您是新手还是专家,我们的专栏都将帮助您提升技能,打造高效、可扩展且稳定的数据库系统。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Unreal Engine 4.pak文件压缩优化】:实现资源打包效率和性能的双重提升(性能提升关键)

# 摘要
Unreal Engine 4的.pak文件压缩是游戏开发和大型项目资源管理中的关键技术。本文首先概述了pak文件压缩的概念,并对其理论基础进行了深入分析,包括文件格式解析、压缩技术的作用、常见压缩算法的选择和优化的理论限制。随后,文中探讨了压缩实践技巧,重点介绍Unreal Engine内建压缩工具的应用和自定义压缩流程的开发。为了进一步提升性能,
Surfer 11实战演练:数据转换应用实例与技巧分享
# 摘要
Surfer 11作为一款功能强大的绘图和数据处理软件,广泛应用于地理信息系统、环境科学和工程等领域。本文首先为读者提供了一个Surf
【MV-L101097-00-88E1512故障排查】:从手册中找到快速解决系统问题的线索

# 摘要
本文详细论述了MV-L101097-00-88E1512故障排查的全面流程,涵盖故障的基本理论基础、手册应用实践、高级诊断技巧以及预防性维护和系统优化策略。首先介绍了系统问题的分类识别、排查原则和故障诊断工具的使用。随后,强调了阅读和应用技术手册进行故障排查的实践操作,并分享了利用手册快速解决问题的方法。进阶章节探讨了高级诊断技术,如性能监控、专业软件诊断和恢复备
无线传感器网络优化手册:应对设计挑战,揭秘高效解决方案

# 摘要
无线传感器网络(WSN)是现代化智能监控和数据采集的关键技术,具有广泛的应用前景。本文首先概述了无线传感器网络优化的基本概念和理论基础,深入探讨了网络的设计、节点部署、能量效率、网络协议和路由优化策略。接着,针对数据采集与处理的优化,本文详细论述了数据融合、压缩存储以及安全和隐私保护的技术和方法。此外,本文通过模拟实验、性能测试和现场部署,评估了网络性
【MDB接口协议问题解决宝典】:分析常见问题与应对策略

# 摘要
本文对MDB接口协议进行全面概述,涵盖了其理论基础、常见问题、实践诊断、高级应用以及未来趋势。通过分析MDB接口协议的工作原理、层次结构和错误检测与纠正机制,揭示了其在数据通信中的核心作用。文章深入探讨了连接、兼容性、安全性和性能问题,提供了实用的故障排除和性能优化技巧。同时,通过案例研究展示了MDB接口协议在不同行业中的应用实践,并讨论了新兴技术的融合潜力。最后,文章预测了新一代MDB接口协议
【Cadence 17.2 SIP系统级封装速成课程】:揭秘10个关键知识点,让你从新手到专家
# 摘要
Cadence SIP系统级封装是集成电子系统设计的关键技术之一,本文详细介绍了Cadence SIP的系统级封装概述、设计工具、设计流程以及封装设计实践和高级功能应用。通过探讨Cadence SIP工具和设计流程,包括工具界面、设计步骤、设计环境搭建、库和组件管理等,本文深入分析了封装设计实践,如从原理图到封装布局、信
飞行控制算法实战】:自定义飞行任务的DJI SDK解决方案
# 摘要
本论文综述了飞行控制算法的关键技术和DJI SDK的使用方法,以实现自定义飞行任务的规划和执行。首先,对飞行控制算法进行概述,然后介绍了DJI SDK的基础架构和通信协议。接着,详细探讨了自定义飞行任务的设计,包括任务规划、地图与航线规划、以及任务执行与异常处理。第四章专注于飞行控制算法的实现,涉及算法开发工具、核心代码及其测试与优化。最后,通过高级飞行控制应用案例,如精确着陆、自主返航、人工智能集成自动避障及多机协同,展示了如何将
MicroPython项目全解析:案例分析带你从零到项目部署成功

# 摘要
MicroPython作为一种针对微控制器和嵌入式系统的Python实现,因其简洁性、易用性受到开发者青睐。本文旨在全面介绍MicroPython项目,从基础语法到高级应用,并通过实战案例分析,揭示其在项目开发中的实际应用和性能优化策略。文中详细探讨了如何搭建开发环境,掌握编程技巧,以及部署、维
立即掌握:DevExpress饼状图数据绑定与性能提升秘籍
/i.s3.glbimg.com/v1/AUTH_08fbf48bc0524877943fe86e43087e7a/internal_photos/bs/2021/f/c/GVBAiNRfietAiJ2TACoQ/2016-01-18-excel-02.jpg)
# 摘要
本论文深入探讨了DevExpress饼状图的设计与应
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )