【MySQL主从复制的秘密】:揭开主从复制的神秘面纱
发布时间: 2024-07-06 17:18:31 阅读量: 51 订阅数: 24 
# 1. MySQL主从复制概述
MySQL主从复制是一种数据库复制技术,它允许将一个数据库(主库)的数据复制到一个或多个其他数据库(从库)。主从复制提供了以下好处:
- **数据冗余和高可用性:**从库包含主库数据的副本,因此如果主库发生故障,从库可以接管并继续提供服务。
- **负载均衡:**从库可以处理读请求,从而减轻主库的负载,提高整体性能。
- **数据备份和恢复:**从库可以作为主库数据的备份,在主库数据丢失或损坏时可以用于恢复。
# 2. MySQL主从复制原理
### 2.1 主从复制的架构和组件
MySQL主从复制是一种数据复制技术,它允许将一个数据库(称为主库)的数据复制到一个或多个其他数据库(称为从库)。主从复制的架构如下图所示:
```mermaid
graph LR
subgraph 主库
A[主库实例]
end
subgraph 从库
B[从库实例1]
C[从库实例2]
end
A --> B
A --> C
```
主从复制涉及以下组件:
- **主库:**存储原始数据的数据库实例。
- **从库:**从主库复制数据的数据库实例。
- **二进制日志(binlog):**主库上记录所有数据更改的日志文件。
- **中继日志(relay log):**从库上存储从主库接收的二进制日志事件的日志文件。
- **I/O 线程:**从库上的线程,负责从主库读取二进制日志事件。
- **SQL 线程:**从库上的线程,负责将二进制日志事件应用到从库数据库。
### 2.2 主从复制的数据传输机制
主从复制的数据传输机制如下:
1. **主库上的更改:**当主库上的数据发生更改时,这些更改将被记录到二进制日志中。
2. **I/O 线程:**从库上的 I/O 线程连接到主库并从二进制日志中读取事件。
3. **中继日志:**I/O 线程将读取的二进制日志事件存储在从库的中继日志中。
4. **SQL 线程:**从库上的 SQL 线程从头开始读取中继日志中的事件。
5. **数据应用:**SQL 线程将事件应用到从库数据库中,从而使从库的数据与主库保持一致。
### 2.3 主从复制的同步机制
主从复制的同步机制确保从库上的数据与主库保持一致。有两种主要的同步机制:
- **异步复制:**从库上的 SQL 线程以异步方式应用二进制日志事件。这意味着从库的数据可能落后于主库,但它提供了更高的性能。
- **半同步复制:**从库上的 SQL 线程在将二进制日志事件应用到从库数据库之前,会等待主库确认已收到该事件。这提供了更高的数据一致性,但性能较低。
# 3.1 主库的配置
**修改 MySQL 配置文件**
在主库的 MySQL 配置文件中(通常为 `/etc/my.cnf`),添加以下配置项:
```
# 启用二进制日志
log-bin=mysql-bin
# 设置服务器 ID
server-id=1
# 设置复制 IO 线程和 SQL 线程的并行复制
binlog-do-db=test_db
binlog-ignore-db=information_schema
```
**参数说明:**
* `log-bin`:启用二进制日志,记录所有对数据库进行的更改。
* `server-id`:设置服务器 ID,用于标识主库。
* `binlog-do-db`:指定要复制的数据库。
* `binlog-ignore-db`:指定要忽略复制的数据库。
**创建复制用户**
在主库上创建用于从库连接和复制的复制用户:
```
CREATE USER 'repl'@'%' IDENTIFIED BY 'password';
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%';
```
**参数说明:**
* `repl`:复制用户的用户名。
* `password`:复制用户的密码。
* `REPLICATION SLAVE`:授予复制用户复制权限。
### 3.2 从库的配置
**修改 MySQL 配置文件**
在从库的 MySQL 配置文件中,添加以下配置项:
```
# 指定主库信息
server-id=2
replicate-do-db=test_db
replicate-ignore-db=information_schema
master-host=192.168.1.100
master-user=repl
master-password=password
master-port=3306
```
**参数说明:**
* `server-id`:设置从库的服务器 ID,必须与主库不同。
* `replicate-do-db`:指定要复制的数据库。
* `replicate-ignore-db`:指定要忽略复制的数据库。
* `master-host`:主库的 IP 地址或主机名。
* `master-user`:复制用户的用户名。
* `master-password`:复制用户的密码。
* `master-port`:主库的端口号。
**启动从库复制**
在从库上启动复制:
```
CHANGE MASTER TO
MASTER_HOST='192.168.1.100',
MASTER_USER='repl',
MASTER_PASSWORD='password',
MASTER_PORT=3306;
START SLAVE;
```
**参数说明:**
* `CHANGE MASTER TO`:指定主库信息。
* `START SLAVE`:启动从库复制。
### 3.3 主从复制的启动和监控
**启动主从复制**
在主库上执行以下命令:
```
mysql> FLUSH TABLES WITH READ LOCK;
mysql> START SLAVE;
```
**参数说明:**
* `FLUSH TABLES WITH READ LOCK`:锁定所有表,防止在启动复制期间进行更改。
* `START SLAVE`:启动主从复制。
**监控主从复制**
使用以下命令监控主从复制状态:
```
mysql> SHOW SLAVE STATUS\G
```
**参数说明:**
* `SHOW SLAVE STATUS`:显示从库的复制状态。
**输出示例:**
```
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Last_IO_Error:
Last_SQL_Error:
```
* `Slave_IO_Running`:表示 IO 线程正在运行。
* `Slave_SQL_Running`:表示 SQL 线程正在运行。
* `Last_IO_Error`:显示 IO 线程的最后一个错误。
* `Last_SQL_Error`:显示 SQL 线程的最后一个错误。
# 4. MySQL主从复制故障排查
### 4.1 主从复制常见故障现象
主从复制故障现象多种多样,常见的有:
- 从库无法连接主库
- 从库IO线程或SQL线程停止
- 从库数据与主库不一致
- 主从复制延迟过大
### 4.2 主从复制故障排查步骤
主从复制故障排查是一个系统性的过程,一般遵循以下步骤:
1. **检查主从库状态**:使用`show slave status`命令查看主从库状态,确认主从库是否正常运行。
2. **查看错误日志**:检查主从库的错误日志,查找故障原因。
3. **检查网络连接**:确认主从库之间的网络连接是否正常。
4. **检查IO线程和SQL线程状态**:使用`show processlist`命令查看IO线程和SQL线程的状态,确认是否停止。
5. **检查主从库配置**:确认主从库的配置是否正确,包括主库的`binlog_format`和`server_id`,从库的`relay_log_info_repository`和`relay_log_recovery`等。
6. **检查数据一致性**:使用`checksum table`命令检查主从库数据是否一致。
7. **检查主从复制延迟**:使用`show slave status`命令查看主从复制延迟,确认是否过大。
### 4.3 主从复制故障解决方法
根据故障现象和排查步骤,可以采取以下方法解决故障:
- **从库无法连接主库**:检查网络连接,确认主库的IP和端口是否正确。
- **从库IO线程或SQL线程停止**:检查IO线程或SQL线程的错误日志,解决错误。
- **从库数据与主库不一致**:检查主从库的配置,确认`binlog_format`和`relay_log_info_repository`是否一致。
- **主从复制延迟过大**:检查主库的负载,优化主库性能。检查从库的硬件配置,升级硬件。优化主从复制配置,如增加`relay_log_buffer_size`。
# 5. MySQL主从复制性能优化
### 5.1 主从复制性能瓶颈分析
MySQL主从复制性能瓶颈主要集中在以下几个方面:
- **网络延迟:**主从服务器之间的网络延迟会影响数据传输速度,导致主从复制延迟。
- **IO瓶颈:**主库和从库的IO性能不足,会导致数据传输和写入数据库的速度变慢。
- **CPU瓶颈:**主库和从库的CPU资源不足,会导致主从复制线程的执行效率降低。
- **内存瓶颈:**主库和从库的内存资源不足,会导致主从复制缓冲区不足,影响数据传输和写入数据库的速度。
- **锁争用:**主库和从库上的锁争用会导致主从复制线程阻塞,影响数据传输和写入数据库的速度。
### 5.2 主从复制性能优化策略
针对主从复制性能瓶颈,可以采取以下优化策略:
#### 5.2.1 优化网络环境
- 优化网络拓扑结构,减少网络延迟。
- 使用高带宽、低延迟的网络连接。
- 使用网络优化工具,如TCP优化工具,提高网络传输效率。
#### 5.2.2 优化IO性能
- 使用SSD或NVMe等高性能存储设备。
- 优化文件系统,如使用XFS或ext4文件系统。
- 使用RAID技术,提高IO性能。
#### 5.2.3 优化CPU性能
- 升级CPU硬件,提高CPU性能。
- 优化MySQL配置,如增加innodb_buffer_pool_size参数,提高MySQL的缓存能力。
- 使用CPU优化工具,如CPU调优器,提高CPU利用率。
#### 5.2.4 优化内存性能
- 增加MySQL服务器的内存容量。
- 优化MySQL配置,如增加innodb_buffer_pool_size参数,提高MySQL的缓存能力。
- 使用内存优化工具,如内存优化器,提高内存利用率。
#### 5.2.5 减少锁争用
- 优化数据库结构,减少表和索引上的锁争用。
- 使用乐观锁或无锁技术,减少锁争用。
- 使用锁优化工具,如锁优化器,优化锁的使用策略。
#### 5.2.6 其他优化措施
- 使用并行复制,提高数据传输速度。
- 使用半同步复制,降低主从复制延迟。
- 使用延迟复制,缓解主库的压力。
- 使用监控工具,监控主从复制性能,及时发现和解决问题。
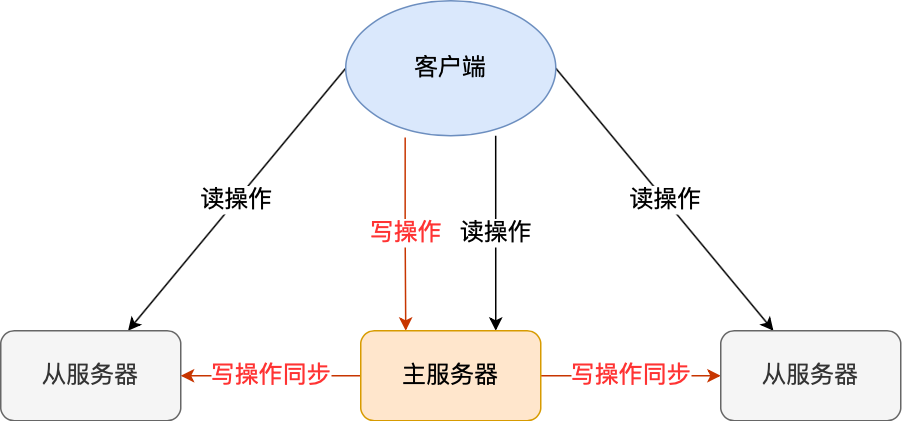
# 6.1 MySQL主从复制的读写分离
### 读写分离原理
读写分离是利用MySQL主从复制技术,将数据库的读写操作分离到不同的服务器上。主库负责处理所有写操作,而从库负责处理所有读操作。这样可以有效地减轻主库的负载,提高数据库的并发处理能力。
### 读写分离架构
读写分离的架构通常如下:
```mermaid
graph LR
subgraph 主库
A[主库]
end
subgraph 从库
B[从库1]
C[从库2]
end
A --> B
A --> C
```
### 读写分离配置
#### 主库配置
在主库上,需要开启binlog日志功能,并设置从库的复制权限。
```sql
# 开启binlog日志
SET GLOBAL binlog_format=ROW;
SET GLOBAL binlog_row_image=FULL;
# 授权从库的复制权限
GRANT REPLICATION SLAVE ON *.* TO 'slave_user'@'%' IDENTIFIED BY 'slave_password';
```
#### 从库配置
在从库上,需要配置主库的连接信息,并开启IO线程和SQL线程。
```sql
# 设置主库的连接信息
CHANGE MASTER TO
MASTER_HOST='master_host',
MASTER_USER='slave_user',
MASTER_PASSWORD='slave_password',
MASTER_PORT=3306,
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=4;
# 开启IO线程和SQL线程
START SLAVE;
```
### 读写分离应用
#### 应用层配置
在应用层,需要配置读写分离的策略。可以根据业务需求,将读操作和写操作路由到不同的数据库服务器上。
#### 数据库连接池配置
在数据库连接池中,需要配置读写分离的策略。可以根据连接类型,将读连接和写连接路由到不同的数据库服务器上。
### 读写分离的优点
* 提高数据库的并发处理能力
* 减轻主库的负载
* 增强数据库的可用性
* 降低数据库的成本

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《MySQL技术秘籍》专栏深入探索MySQL数据库的各个方面,为读者揭开其神秘面纱。从主从复制到索引优化,从锁机制到备份与恢复,该专栏提供了全面的技术指南。此外,它还涵盖了高可用架构设计、监控与告警、性能调优、运维最佳实践、数据迁移、分库分表、高并发场景优化、死锁问题解决以及查询优化等关键主题。通过深入的分析、实际案例和实用的解决方案,该专栏旨在帮助读者掌握MySQL数据库的精髓,优化其性能并确保其稳定可靠的运行。
专栏目录
最低0.47元/天 解锁专栏
买1年送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【R语言数据包用户反馈机制构建】:打造高效反馈循环与改进流程

# 1. R语言数据包用户反馈的重要性与基本流程
## 1.1 用户反馈的重要性
在R语言数据包的生命周期中,用户反馈是不可或缺的一部分。它不仅提供了用户的真实使用体验,而且是发现问题、持续改进产品、增强用户体验和促进技术创新的重要依据。及时收集和妥善处理用户反馈,可以缩短产品迭代周期,提升数据包的稳定性和功能性。
## 1.2 反馈收集的基本流程
用户反馈收集的基本流程通常包括以下几个步骤:
- 设计用户反馈表
【R语言数据库连接大全】:连接MySQL、PostgreSQL等数据库

# 1. R语言与数据库的基本连接
在数据分析和统计领域,R语言凭借其强大的统计分析能力得到了广泛应用。然而,为了从各种数据源获取数据,R语言与数据库的连接成为一项基本技能。数据库的使用不仅可以保证数据的结构化管理,还能通过高效的查询和数据操作来优化数据分析的流程。
## 1.1 数据库连接的目的和意义
数据库连接允许R语言与各类数据库进行交互,
【R语言新手必看】:5分钟掌握constrOptim函数的基础用法

# 1. R语言和constrOptim函数简介
R语言作为统计学和数据分析领域广泛使用的编程语言,提供了多种函数用于处理各类优化问题。其中,`
R语言prop.test应用全解析:从数据处理到统计推断的终极指南

# 1. R语言与统计推断简介
统计推断作为数据分析的核心部分,是帮助我们从数据样本中提取信息,并对总体进行合理假设与结论的数学过程。R语言,作为一个专门用于统计分析、图形表示以及报告生成的编程语言,已经成为了数据科学家的常用工具之一。本章将为读者们简要介绍统计推断的基本概念,并概述其在R语言中的应用。我们将探索如何利用R语言强大的统计功能库进行实验设计、数据分析和推断验证。通过对数据的
【数据清洗艺术】:R语言density函数在数据清洗中的神奇功效

# 1. 数据清洗的必要性与R语言概述
## 数据清洗的必要性
在数据分析和挖掘的过程中,数据清洗是一个不可或缺的环节。原始数据往往包含错误、重复、缺失值等问题,这些问题如果不加以处理,将严重影响分析结果的准确性和可靠性。数据清洗正是为了纠正这些问题,提高数据质量,从而为后续的数据分析和模型构建打下坚实的基础。
## R语言概述
R语言是一种用于统计分析
【R语言高性能计算】:并行计算框架与应用的前沿探索

# 1. R语言简介及其计算能力
## 简介
R语言是一种用于统计分析、图形表示和报告的编程语言和软件环境。自1993年问世以来,它已经成为数据科学领域内最流行的工具之一,尤其是受到统计学家和研究人员的青睐。
## 计算能力
R语言拥有强大的计算能力,特别是在处理大量数据集和进行复杂统计分析
R语言lme包深度教学:嵌套数据的混合效应模型分析(深入浅出)

# 1. 混合效应模型的基本概念与应用场景
混合效应模型,也被称为多层模型或多水平模型,在统计学和数据分析领域有着重要的应用价值。它们特别适用于处理层级数据或非独立观测数据集,这些数据集中的观测值往往存在一定的层次结构或群组效应。简单来说,混合效应模型允许模型参数在不同的群组或时间点上发生变化,从而能够更准确地描述数据的内在复杂性。
## 1.1 混合效应模型的
R语言数据包个性化定制:满足复杂数据分析需求的秘诀

# 1. R语言简介及其在数据分析中的作用
## 1.1 R语言的历史和特点
R语言诞生于1993年,由新西兰奥克兰大学的Ross Ihaka和Robert Gentleman开发,其灵感来自S语言,是一种用于统计分析、图形表示和报告的编程语言和软件环境。R语言的特点是开源、功能强大、灵活多变,它支持各种类型的数据结
【R语言t.test实战演练】:从数据导入到结果解读,全步骤解析

# 1. R语言t.test基础介绍
统计学是数据分析的核心部分,而t检验是其重要组成部分,广泛应用于科学研究和工业质量控制中。在R语言中,t检验不仅易用而且功能强大,可以帮助我们判断两组数据是否存在显著差异,或者某组数据是否显著不同于预设值。本章将为你介绍R语言中t.test函数的基本概念和用法,以便你能快速上手并理解其在实际工作中的应用价值。
## 1.1 R语言t.test函数概述
R语言t.test函数是一个
【R语言高级应用】:princomp包的局限性与突破策略

# 1. R语言与主成分分析(PCA)
在数据科学的广阔天地中,R语言凭借其灵活多变的数据处理能力和丰富的统计分析包,成为了众多数据科学家的首选工具之一。特别是主成分分析(PCA)作为降维的经典方法,在R语言中得到了广泛的应用。PCA的目的是通过正交变换将一组可
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )