Elasticsearch中的索引优化与性能调优技巧
发布时间: 2024-02-25 17:06:41 阅读量: 56 订阅数: 32 
# 1. I. 索引优化与性能调优概述
在这一章节中,我们将深入探讨Elasticsearch中索引优化和性能调优的重要性以及对系统性能的影响。首先,我们会讨论为什么理解和实施索引优化和性能调优对于Elasticsearch系统至关重要。接着,我们将探讨索引优化和性能调优在实际应用中所起到的作用,以及它们对系统整体性能的影响。
## A. 理解Elasticsearch索引优化和性能调优的重要性
在本节中,我们将介绍Elasticsearch中索引优化和性能调优的基本概念,以及为什么理解这些概念对于构建高效的Elasticsearch系统至关重要。我们将讨论索引优化和性能调优在提高搜索速度、减少资源消耗和优化数据存储方面的重要作用。
## B. 深入探讨索引优化和性能调优的影响
本节将深入探讨索引优化和性能调优对Elasticsearch系统性能的影响。我们将讨论这些优化措施如何影响搜索性能、写入性能、存储利用率以及整体系统的稳定性。通过深入了解这些影响,我们可以更好地制定索引优化和性能调优的策略,从而最大程度地发挥Elasticsearch的潜力。
# 2. II. 索引设计最佳实践
索引设计是影响Elasticsearch性能的关键因素之一。在进行索引设计时,需要考虑以下最佳实践:
### A. 确定合适的数据类型和映射
在创建索引时,需要仔细选择合适的数据类型和字段映射,包括文本、数字、日期、地理位置等。合理的数据类型选择有助于提高查询性能和减少存储空间的占用。
**示例代码:**
```json
PUT /my_index
{
"mappings": {
"properties": {
"title": {
"type": "text"
},
"price": {
"type": "float"
},
"timestamp": {
"type": "date"
},
"location": {
"type": "geo_point"
}
}
}
}
```
**代码说明:** 上述示例中展示了如何创建一个索引并指定不同类型的字段映射。
### B. 选择合适的分片和副本配置
合理的分片和副本配置可以提升Elasticsearch的性能和可用性。根据数据量和集群规模,选择合适的分片数量和副本数量。
**示例代码:**
```json
PUT /my_index
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
}
}
```
**代码说明:** 在创建索引时,通过设置`number_of_shards`和`number_of_replicas`来配置分片和副本的数量。
### C. 索引分割和管理
随着数据量的增长,需要考虑索引的分割和管理策略,以充分利用集群资源并保持良好的性能表现。
**示例代码:**
```json
POST /my_index/_split/my_new_index
{
"settings": {
"index.number_of_shards": 10
}
}
```
**代码说明:** 通过上述示例可以将一个索引拆分成两个新索引,以优化数据存储和提升查询性能。
通过以上的最佳实践,可以有效提升Elasticsearch的性能和稳定性,更好地满足不同场景下的需求。
# 3. III. 索引性能调优技巧
在Elasticsearch中,针对索引的性能调优是非常重要的。下面将详细介绍一些索引性能调优的技巧和最佳实践。
#### A. 使用合适的查询语法和过滤器
1. **布尔查询优化**
在构建布尔查询时,合理地使用`must`、`should`和`must_not`关键字是非常重要的。例如,使用`must`来表示必须匹配的查询条件,而使用`should`来表示可选匹配条件,可以有效提高查询性能。
```python
from elasticsearch import Elasticsearch
es = Elasticsearch()
query = {
"query": {
"bool": {
"must": [
{ "match": { "title": "Elasticsearch" } }
],
"should": [
{ "match": { "tags": "performance" } }
],
"must_not": [
{ "match": { "status": "inactive" } }
]
}
}
}
res = es.search(index="your_index", body=query)
```
2. **过滤器的使用**
当需要过滤某些文档而非匹配它们时,应该使用过滤器来代替查询。过滤器不会计算相关性分数,因此在某些情况下能够提高查询性能。
```python
from elasticsearch import Elasticsearch
es = Elasticsearch()
query = {
"query": {
"bool": {
"must": { "match": { "title": "Elasticsearch" } },
"filter": { "term": { "category": "technology" } }
}
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Elasticsearch搜索引擎》专栏深入探讨了Elasticsearch在数据索引与查询、聚合与分析、文本搜索与分析、以及索引优化与性能调优等方面的应用。文章包括了《Elasticsearch数据索引与查询详解》、《使用Elasticsearch进行数据聚合与分析》、《Elasticsearch中的文档更新及删除操作的实践》等多个主题,涵盖了Elasticsearch的基本操作到高级技术应用。此外,还深入探讨了Elasticsearch中的布尔查询与过滤查询、索引别名使用与原理、模糊搜索技术、地理位置数据的索引与查询等内容。无论您是初学者还是有经验的开发人员,本专栏都将为您提供丰富的实践经验和深入的技术知识,帮助您更好地理解和应用Elasticsearch搜索引擎。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【材料选择专家指南】:如何用最低成本升级漫步者R1000TC北美版音箱
# 摘要
本文旨在深入探讨漫步者R1000TC北美版音箱的升级理论与实践操作指南。首先分析了音箱升级的重要性、音质构成要素,以及如何评估升级对音质的影响。接着介绍了音箱组件工作原理,特别是扬声器单元和分频器的作用及其选择原则。第三章着重于实践操作,提供扬声器单元、分频器和线材的升级步骤与技巧。第四章讨论了升级效果的评估方法,包括使用音频测试软件和主观听感分析。最后,第五章探讨了进阶升级方案,如音频接口和蓝牙模块的扩展,以及个性化定制声音风格的策略。通过本文,读者可以全面了解音箱升级的理论基础、操作技巧以及如何实现个性化的声音定制。
# 关键字
音箱升级;音质提升;扬声器单元;分频器;调音技巧
【PyQt5控件进阶】:日期选择器、列表框和文本编辑器深入使用

# 摘要
PyQt5是一个功能强大的跨平台GUI框架,它提供了丰富的控件用于构建复杂的应用程序。本文从PyQt5的基础回顾和控件概述开始,逐步深入探讨了日期选择器、列表框和文本编辑器等控件的高级应用和技巧。通过对控件属性、方法和信号与槽机制的详细分析,结合具体的实践项目,本文展示了如何实现复杂日期逻辑、动态列表数据管理和高级文本编辑功能。此外,本文还探讨了控件的高级布局和样式设计
MAXHUB后台管理新手速成:界面概览至高级功能,全方位操作教程

# 摘要
MAXHUB后台管理平台作为企业级管理解决方案,为用户提供了一个集成的环境,涵盖了用户界面布局、操作概览、核心管理功能、数据分析与报告,以及高级功能的深度应用。本论文详细介绍了平台的登录、账号管理、系统界面布局和常用工具。进一步探讨了用户与权限管理、内容管理与发布、设备管理与监控的核心功能,以及如何通过数据分析和报告制作提供决策支持。最后,论述了平台的高
深入解析MapSource地图数据管理:存储与检索优化之法
# 摘要
本文对MapSource地图数据管理系统进行了全面的分析与探讨,涵盖了数据存储机制、高效检索技术、数据压缩与缓存策略,以及系统架构设计和安全性考量。通过对地图数据存储原理、格式解析、存储介质选择以及检索算法的比较和优化,本文揭示了提升地图数据管理效率和检索性能的关键技术。同时,文章深入探讨了地图数据压缩与缓存对系统性能的正面影响,以及系统架构在确保数据一致性
【结果与讨论的正确打开方式】:展示发现并分析意义

# 摘要
本文深入探讨了撰写研究论文时结果与讨论的重要性,分析了不同结果呈现技巧对于理解数据和传达研究发现的作用。通过对结果的可视化表达、比较分析以及逻辑结构的组织,本文强调了清晰呈现数据和结论的方法。在讨论部分,提出了如何有效地将讨论与结果相结合、如何拓宽讨论的深度与广度以及如何提炼创新点。文章还对分析方法的科学性、结果分析的深入挖掘以及案例分析的启示进行了评价和解读。最后
药店管理系统全攻略:UML设计到实现的秘籍(含15个实用案例分析)
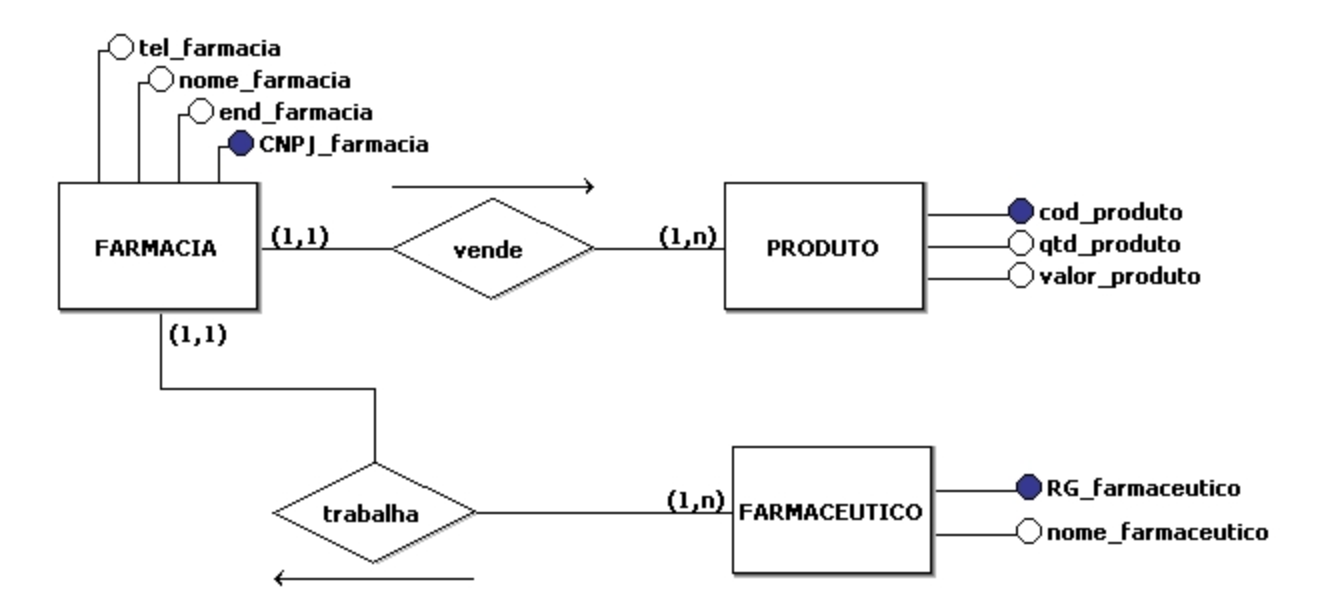
# 摘要
本论文首先概述了药店管理系统的基本结构和功能,接着介绍了UML理论在系统设计中的应用,详细阐述了用例图、类图的设计原则与实践。文章第三章转向系统的开发与实现,涉及开发环境选择、数据库设计、核心功能编码以及系统集成与测试。第四章通过实践案例深入探讨了UML在药店管理系统中的应用,包括序列图、活动图、状态图及组件图的绘制和案例分析。最后,论文对药店管理系统的优化与维护进行了讨论,提
【555定时器全解析】:掌握方波发生器搭建的五大秘籍与实战技巧
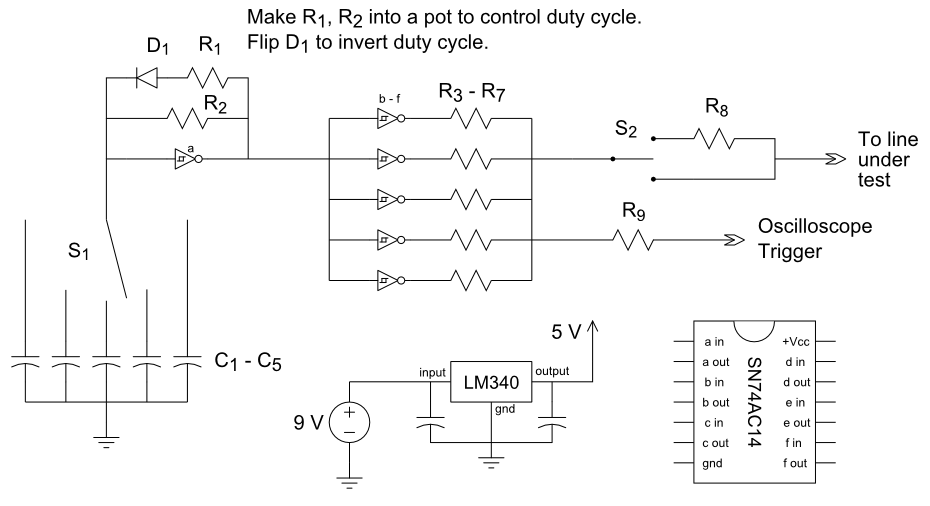
# 摘要
本文详细介绍了555定时器的工作原理、关键参数、电路搭建基础及其在方波发生器、实战应用案例以及高级应用中的具体运用。首先,概述了555定时器的基本功能和工作模式,然后深入探讨了其在方波发生器设计中的应用,包括频率和占空比的控制,以及实际实验技巧。接着,通过多个实战案例,如简易报警器和脉冲发生器的制作,展示了555定时器在日常项目中的多样化运用。最后,分析了555定时器的多用途扩展应用,探讨了其替代技术,
【Allegro Gerber导出深度优化技巧】:提升设计效率与质量的秘诀

# 摘要
本文全面介绍了Allegro Gerber导出技术,阐述了Gerber格式的基础理论,如其历史演化、
Profinet通讯优化:7大策略快速提升1500编码器响应速度
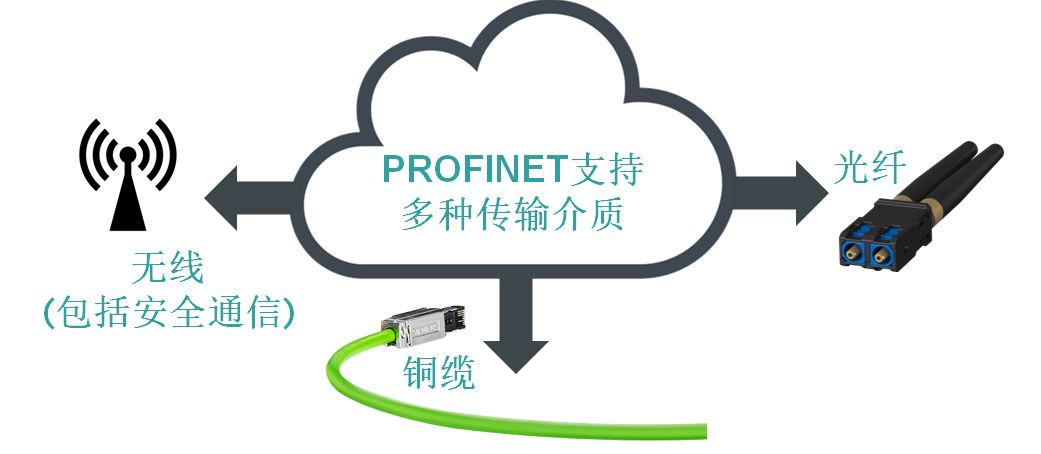
# 摘要
Profinet作为一种工业以太网通讯技术,其通讯性能和编码器的响应速度对工业自动化系统至关重要。本文首先概述了Profinet通讯与编码器响应速度的基础知识,随后深入分析了影响Profinet通讯性能的关键因素,包括网络结构、数据交换模式及编码器配置。通过优化网络和编码器配置,本文提出了一系列提升Profinet通讯性能的实践策略。进一步,本文探讨了利用实时性能监控、网络通讯协议优化以及预
【时间戳转换秘籍】:将S5Time转换为整数的高效算法与陷阱分析

# 摘要
时间戳转换在计算机科学与信息技术领域扮演着重要角色,它涉及到日志分析、系统监控以及跨系统时间同步等多个方面。本文首先介绍了时间戳转换的基本概念和重要性,随后深入探讨了S5Time与整数时间戳的理论基础,包括它们的格式解析、定义以及时间单位对转换算法的影响。本文重点分
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )