MyBatis缓存配置与优化策略:深入了解缓存配置
发布时间: 2023-12-15 19:16:34 阅读量: 61 订阅数: 27 
# 1. MyBatis缓存概述
## 1.1 缓存的基本概念
在软件开发中,缓存是一种将数据临时存储在内存中的技术,以加快数据访问速度的方法。通过缓存,可以减少对数据库或外部资源的频繁访问,从而提高系统的性能和响应速度。
## 1.2 MyBatis中的缓存机制简介
MyBatis是一个优秀的持久层框架,它提供了对数据库的操作接口,并且具有自身的缓存机制。MyBatis的缓存包括一级缓存(Local Cache)和二级缓存(Second Level Cache),可以在不同的作用域内共享SQL查询结果,从而提高系统性能。
## 1.3 为什么需要对MyBatis缓存进行配置与优化
尽管MyBatis提供了默认的缓存机制,但在实际项目中,需要根据应用场景和性能要求进行定制化的缓存配置和优化。合理配置和优化缓存不仅能够提升系统性能,还可以减轻数据库负担,降低系统成本。因此,深入了解MyBatis的缓存配置与优化策略是非常重要的。
# 2. MyBatis缓存配置详解
### 2.1 一级缓存(Local Cache)的工作原理与配置
一级缓存是指在SQLSession级别的缓存,也称为本地缓存。它默认是开启的,可以通过配置文件或代码进行相关配置。
在MyBatis中,一级缓存的工作原理如下:
1. 当执行一个查询操作时,查询的结果会被缓存到一级缓存中。
2. 下次执行相同的查询操作时,MyBatis会先查找一级缓存中是否存在该查询的结果,如果存在,则直接返回缓存的结果,不再访问数据库。
3. 当执行增删改操作(例如插入、更新、删除)时,会使一级缓存失效,以保证数据的一致性。
可以通过以下方式配置一级缓存:
1. 通过配置文件配置:
```xml
<settings>
<setting name="localCacheScope" value="STATEMENT" />
</settings>
```
2. 通过代码配置:
```java
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(configuration);
Configuration configuration = sqlSessionFactory.getConfiguration();
configuration.setLocalCacheScope(LocalCacheScope.STATEMENT);
```
通过以上配置,可以控制一级缓存的作用范围,可选值有STATEMENT(默认值)和SESSION,其中:
- STATEMENT表示一级缓存仅在当前SQLSession中有效;
- SESSION表示一级缓存在当前会话中的所有SQLSession中有效。
### 2.2 二级缓存(Second Level Cache)的工作原理与配置
二级缓存是指在Mapper级别的缓存,它可以被多个SQLSession共享。默认情况下,二级缓存是关闭的,需要手动进行配置。
二级缓存的工作原理如下:
1. 当执行一个查询操作时,查询的结果会被缓存到二级缓存中。
2. 下次执行相同的查询操作时,MyBatis会先查找二级缓存中是否存在该查询的结果,如果存在,则直接返回缓存的结果,不再访问数据库。
3. 当执行增删改操作时,会使二级缓存失效,以保证数据的一致性。
可以通过以下方式配置二级缓存:
1. 通过配置文件配置:
```xml
<settings>
<setting name="cacheEnabled" value="true" />
</settings>
```
2. 通过代码配置:
```java
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(configuration);
Configuration configuration = sqlSessionFactory.getConfiguration();
configuration.setCacheEnabled(true);
```
通过以上配置,可以启用或禁用二级缓存。
### 2.3 MyBatis缓存相关的全局配置
除了一级缓存和二级缓存的配置外,还可以进行一些全局配置,例如缓存的刷新间隔、缓存的大小限制等。
可以通过以下方式进行全局配置:
1. 通过配置文件配置:
```xml
<!-- 设置缓存刷新时间间隔,单位为毫秒,默认值为不刷新 -->
<setting name="flushInterval" value="60000" />
<!-- 设置最大缓存数量,默认值为空,表示不限制 -->
<setting name="localCacheSize" value="1024" />
```
2. 通过代码配置:
```java
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(configuration);
Configuration configuration = sqlSessionFactory.getConfiguration();
configuration.setFlushInterval(60000);
configuration.setLocalCacheSize(1024);
```
通过以上配置,可以对缓存进行更加精细的控制。需要注意的是,在高并发的情况下,过大的缓存会导致内存占用过高,从而影响系统的性能。因此,需要根据具体的业务场景进行合理配置。
# 3. 缓存失效策略
在实际项

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《MyBatis源码深入剖析》专栏深入剖析MyBatis框架的底层实现原理,通过一系列文章依次解析了MyBatis的核心模块。从SQL映射到数据库交互、底层实现原理、缓存机制、内部工作原理、执行器原理、事务管理、插件机制、与Spring整合原理、高级特性、缓存配置优化、多数据源管理方案、性能调优、异步执行与线程池原理、结果映射、架构设计模式、插件开发、代码生成器原理与实践、异常处理与日志追踪、扩展性等方面进行了深入探讨。本专栏旨在帮助读者深入理解MyBatis框架的内部机制,为开发人员提供深度学习与实践的指导,使其能更好地应用和定制MyBatis框架,提升自身在数据库交互领域的技术水平。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【数据同步秘籍】:跨平台EQSL通联卡片操作的最佳实践
# 摘要
本文全面探讨了跨平台EQSL通联卡片同步技术,详细阐述了同步的理论基础、实践操作方法以及面临的问题和解决策略。文章首先介绍了EQSL通联卡片同步的概念,分析了数据结构及其重要性,然后深入探讨了同步机制的理论模型和解决同步冲突的理论。此外,文章还探讨了跨平台数据一致性的保证方法,并通过案例分析详细说明了常见同步场景的解决方案、错误处理以及性能优化。最后,文章预测了未来同步技术的发展趋势,包括新技术的应用前景和同步技术面临的挑战。本文为实现高效、安全的
【DevOps快速指南】:提升软件交付速度的黄金策略
# 摘要
DevOps作为一种将软件开发(Dev)与信息技术运维(Ops)整合的实践方法论,源于对传统软件交付流程的优化需求。本文从DevOps的起源和核心理念出发,详细探讨了其实践基础,包括工具链概览、自动化流程、以及文化与协作的重要性。进一步深入讨论了持续集成(CI)和持续部署(CD)的实践细节,挑战及其解决对策,以及在DevOps实施过程中的高级策略,如安全性强化和云原生应用的容器化。
【行业标杆案例】:ISO_IEC 29147标准下的漏洞披露剖析
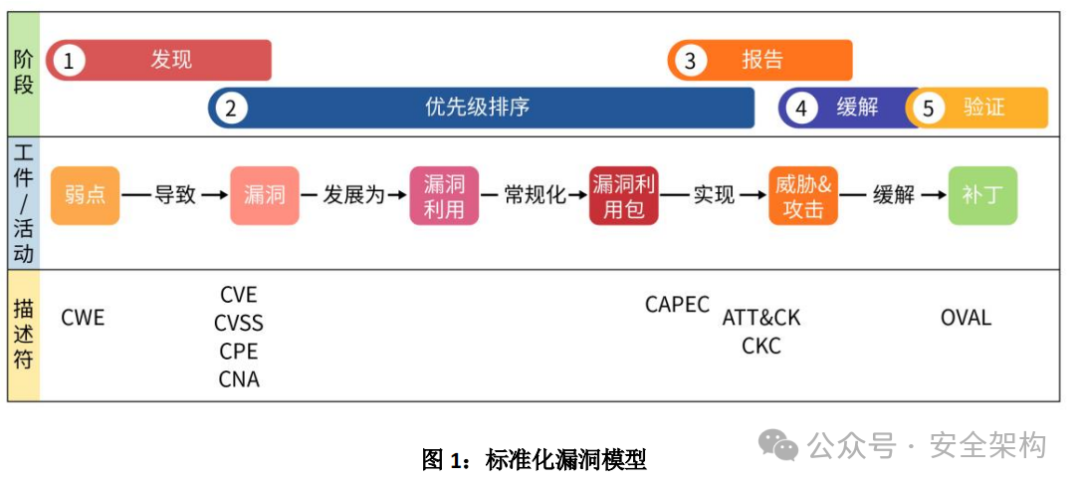
# 摘要
本文系统地探讨了ISO/IEC 29147标准在漏洞披露领域的应用及其理论基础,详细分析了漏洞的生命周期、分类分级、披露原则与流程,以及标准框架下的关键要求。通过案例分析,本文深入解析了标准在实际漏洞处理中的应用,并讨论了最佳实践,包括漏洞分析、验证技术、协调披露响应计划和文档编写指南。同时,本文也提出了在现有标准指导下的漏洞披露流程优化策略,以及行业标杆的
智能小车控制系统安全分析与防护:权威揭秘
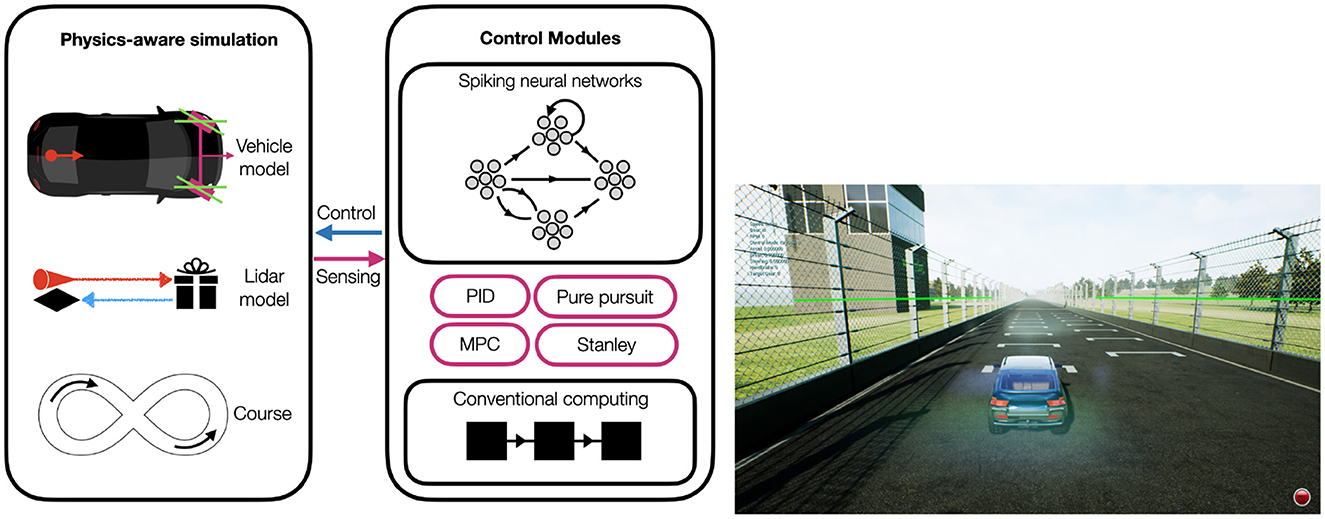
# 摘要
随着智能小车控制系统的广泛应用,其安全问题日益凸显。本文首先概述了智能小车控制系统的基本架构和功能特点,随后深入分析了该系统的安全隐患,包括硬件和软件的安全威胁、潜在的攻击手段及安全风险评估方法。针对这些风险,文章提出了一整套安全防护措施,涵盖了物理安全、网络安全与通信以及软件与固件的保护策略。此外,本文还讨论了安全测试与
【编程进阶】:探索matplotlib中文显示最佳实践

# 摘要
matplotlib作为一个流行的Python绘图库,其在中文显示方面存在一些挑战,本论文针对这些挑战进行了深入探讨。首先回顾了matplotlib的基础知识和中文显示的基本原理,接着详细分析了中文显示问题的根本原因,包括字体兼容性和字符编码映射。随后,提出了多种解决方案,涵盖了配置方法、第三方库的使用和针对不同操作系统的策略。论文进一步探讨了中
非线性控制算法破解:面对挑战的创新对策

# 摘要
非线性控制算法在现代控制系统中扮演着关键角色,它们的理论基础及其在复杂环境中的应用是当前研究的热点。本文首先探讨了非线性控制系统的理论基础,包括数学模型的复杂性和系统稳定性的判定方法。随后,分析了非线性控制系统面临的挑战,包括高维系统建模、系统不确定性和控制策略的局限性。在理论创新方面,本文提出新型建模方法和自适应控制策略,并通过实践案例分析了这些理论的实际应用。仿
Turbo Debugger与版本控制:6个最佳实践提升集成效率
# 摘要
本文旨在介绍Turbo Debugger及其在版本控制系统中的应用。首先概述了Turbo Debugger的基本功能及其在代码版本追踪中的角色。随后,详细探讨了版本控制的基础知识,包括不同类型的版本控制系统和日常操作。文章进一步深入分析了Turbo Debugger与版本控制集成的最佳实践,包括调试与
流量控制专家:Linux双网卡网关选择与网络优化技巧

# 摘要
本文对Linux双网卡网关的设计与实施进行了全面的探讨,从理论基础到实践操作,再到高级配置和故障排除,详细阐述了双网卡网关的设置过程和优化方法。首先介绍了双网卡网关的概述和理论知识,包括网络流量控制的基础知识和Linux网络栈的工作原理。随后,实践篇详细说明了如何设置和优化双网卡网关,以及在设置过程中应采用的网络优化技巧。深入篇则讨论了高级网络流量控制技术、安全策略和故障诊断与修复方法。最后,通
GrblGru控制器终极入门:数控新手必看的完整指南

# 摘要
GrblGru控制器作为先进的数控系统,在机床操作和自动化领域发挥着重要作用。本文概述了GrblGru控制器的基本理论、编程语言、配置设置、操作实践、故障排除方法以及进阶应用技术。通过对控制器硬件组成、软件功能框架和G代码编程语言的深入分析,文章详细介绍了控制器的操作流程、故障诊断以及维护技巧。此外,通过具体的项目案例分析,如木工作品和金属雕刻等,本文进一步展示了GrblGr
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )