【Trino性能调优秘籍】:从入门到精通,掌握最佳实践和核心技巧
发布时间: 2025-01-04 20:19:37 阅读量: 40 订阅数: 15 

# 摘要
本文对Trino性能调优进行了系统性的概述和分析。首先介绍了Trino的基本架构和工作原理,重点解析了其架构组件和查询处理流程以及性能指标。随后深入探讨了资源和硬件优化、查询优化技巧以及连接器与数据源优化等实践方法。文中还论述了高级性能调优技巧,如缓存与内存管理、并行处理与并发控制,以及JVM调优在提升Trino性能方面的作用。最后,通过案例分析,本文展示了在典型性能问题诊断、大数据环境下的性能优化和持续性能优化的实用策略。通过这些内容,本文旨在为读者提供全面的Trino性能调优知识框架,并分享实际操作中的最佳实践和经验教训。
# 关键字
Trino架构;性能调优;资源优化;查询优化;并发控制;JVM配置
参考资源链接:[Trino查询优化实战:提升数据分析效率](https://wenku.csdn.net/doc/1rkc01a87a?spm=1055.2635.3001.10343)
# 1. Trino性能调优概述
在面对日益增长的数据分析需求时,Trino(前身为Presto SQL查询引擎)作为一种强大的分布式SQL查询引擎,因其出色的速度和扩展性成为了业界的首选。但即便如此,随着数据量的不断增长和查询复杂度的提高,Trino性能问题仍然不可避免。因此,掌握Trino性能调优技巧,对于任何数据工程师和架构师来说都是至关重要的。
在本章,我们将概述Trino性能调优的必要性,介绍调优过程中可能关注的关键领域,并概述接下来的章节内容。我们将了解性能调优不仅是一门科学,更是一门艺术,它涉及到理解Trino的架构、工作原理,以及对关键性能指标的监控和分析。
理解调优的目标并结合实际业务场景,是从海量数据中提取价值的前提。本章旨在为读者提供一个Trino性能调优的高屋建瓴式概览,为深入讨论具体的调优策略打下坚实的基础。接下来的章节将逐一解析,从架构组件到实际操作,再到案例分析,逐步深入Trino性能调优的核心。
# 2. 理解Trino的基本架构和工作原理
## 2.1 Trino架构组件解析
### 2.1.1 Trino架构概览
Trino(原名Presto SQL)是一个分布式查询引擎,专为快速、大规模地执行只读查询而设计。它支持多种数据源,包括关系型数据库、分布式文件系统、NoSQL数据库以及云存储服务。Trino架构被设计为模块化和易于扩展,允许开发者在其上执行复杂的数据分析,从简单的数据探索到复杂的分析。
Trino的架构分为多个组件,主要包括以下几个:
- **Coordinator Node(协调节点)**:协调节点负责接收客户端的查询请求,生成查询计划,并进行优化。它还负责任务调度,将任务分配给工作节点。
- **Worker Node(工作节点)**:工作节点负责执行实际的数据处理工作。它们从数据源中获取数据,执行过滤、连接、聚合等操作,并返回结果给协调节点。
- **Catalog Service(目录服务)**:目录服务提供了关于数据源的信息。它允许Trino查询位于不同数据源中的数据,而无需关心底层数据存储的具体细节。
- **Connector(连接器)**:连接器定义了如何从特定数据源读取数据的逻辑。Trino支持多种连接器,例如JDBC、Hive、Cassandra等。
### 2.1.2 关键组件的角色与功能
- **Coordinator节点的角色和功能**:
- 接收用户查询。
- 分析和生成查询计划。
- 对查询计划进行优化。
- 负责执行查询的工作节点的任务调度。
- 维护元数据信息和执行查询计划的执行状态。
- **Worker节点的角色和功能**:
- 根据协调节点的指令执行查询任务。
- 从不同的数据源读取数据。
- 执行数据过滤、聚合、连接等操作。
- 处理和传递中间结果。
- **Catalog Service的角色和功能**:
- 提供一个抽象层,使得查询可以跨不同的数据源执行。
- 管理和存储有关数据源的元数据信息。
- **Connector的角色和功能**:
- 定义了与特定数据源交互的接口。
- 实现了读取和写入数据的具体逻辑。
- 支持数据的扫描、过滤、聚合、连接等操作。
## 2.2 Trino的查询处理流程
### 2.2.1 查询解析与规划
当用户提交一个查询到Trino后,首先由Coordinator进行处理。查询解析过程涉及几个步骤:
1. **词法分析(Lexical Analysis)**:解析查询文本,将其分解为一系列的标记(tokens)。
2. **语法分析(Syntax Analysis)**:将标记转换成抽象语法树(AST),这代表了查询的语法结构。
3. **语义分析(Semantic Analysis)**:检查AST中的每个操作是否有意义,比如检查列名和表名是否存在于元数据中。
查询规划阶段,Trino使用一个称为`Cost-based Optimizer (CBO)`的优化器,它根据数据的统计信息和查询的复杂性估算出不同执行计划的成本,并选择成本最低的计划来执行查询。
### 2.2.2 查询执行与优化
查询执行阶段,Trino使用一个分布式执行模型,其中协调节点分配任务到工作节点,并监控任务的执行状态。查询优化在这个阶段是动态进行的,Trino支持动态计划调整,这意味着查询执行时可以重新优化,以适应数据的分布和实际的运行时状态。
工作节点执行计划中的每个算子(operator),如`join`、`group by`、`order by`等,并通过网络在节点之间交换数据。Trino使用了向量化执行和列式存储等技术以提高执行效率。
## 2.3 Trino的性能指标
### 2.3.1 常见性能指标介绍
Trino的性能指标主要包括:
- **查询执行时间**:完成一个查询所需的总时间。
- **CPU使用率**:协调节点和工作节点的CPU使用情况。
- **内存使用率**:节点可用内存与实际使用的内存比率。
- **网络I/O**:节点间数据传输的速率和总量。
- **磁盘I/O**:如果查询涉及磁盘存储,如排序或临时文件的写入。
### 2.3.2 性能监控与指标解读
性能监控能够帮助我们理解Trino集群在执行查询时的行为。使用如`jmx exporter`可以收集和监控这些性能指标。监控数据可以用于识别性能瓶颈,并且能够指导我们对集群进行进一步的调优。
解读性能指标时,需要关注整个查询生命周期中的各种资源使用情况。例如:
- 如果查询执行时间较长,可能需要检查是否是由于网络I/O或磁盘I/O造成的瓶颈。
- 如果CPU使用率很高但查询执行慢,可能表明查询没有很好地并行化,或者是因为资源争用。
- 高内存使用率可能表明有内存溢出的风险,或者需要更多的内存资源来提高查询效率。
为了全面理解性能状况,需要在不同层面上收集数据,并根据实际使用情况做出调整。下面的例子展示了如何收集和分析Trino的性能指标。
```shell
# 使用jmx exporter导出指标
curl -s http://<coordinator-node>:<port>/jmx | jq '.'
```
在上述命令中,我们通过JMX端口获取了Trino协调节点上的指标,并使用`jq`工具对输出进行格式化,使其更易于阅读。通过监控工具可以实时查看这些指标,并及时调整配置以优化性能。
```mermaid
graph LR
A[开始查询] --> B[查询解析与规划]
B --> C[查询执行与优化]
C --> D[查询结果返回]
```
上述流程图展示了Trino查询处理的基本步骤。从开始查询到解析规划、执行优化,最后返回结果,每一步都涉及到不同的组件和操作。通过理解这个流程,开发者和系统管理员可以针对性地调整和优化查询性能。
# 3. Trino性能调优实践
### 3.1 资源和硬件优化
Trino的资源和硬件优化是提高查询效率和系统稳定性的关键。优化可以从多个角度入手,包括资源分配策略和硬件配置。
#### 3.1.1 资源分配策略
资源分配策略直接关联到Trino集群的响应速度和查询吞吐量。在Trino中,资源主要通过内存、CPU和网络带宽来体现。
- **内存分配**:Trino的内存分配对查询性能影响巨大,正确设置内存大小和分配策略可以减少内存溢出和查询失败的风险。内存分配策略可以通过调整`query.max-memory-per-node`和`query.max-total-memory-per-node`等参数来实现。
- **CPU分配**:合理分配CPU资源对并行处理性能至关重要。Trino允许通过`query.max-parallelism`和`query.min-cpu-per-gather`等参数设置并发执行的最大小时和最小CPU需求。
- **网络带宽**:Trino查询过程中数据传输依赖网络带宽,高带宽可以加快数据的传输速度,提高查询效率。
#### 3.1.2 硬件配置对性能的影响
硬件配置是性能调优的基础。在服务器硬件配置方面,内存大小、CPU核心数量、存储类型和网络速率都对Trino性能产生重大影响。
- **内存大小**:内存是影响查询速度的关键因素,足够的内存可以存储更多的数据页,减少磁盘I/O操作。
- **CPU核心**:更多的CPU核心意味着更强的并行处理能力,能够同时执行更多的任务。
- **存储类型**:SSD相比于HDD有更快的读写速度,对提高查询性能特别有效。
- **网络速率**:高网络速率能够加速节点间的通信,减少数据传输时间。
**代码块示例与逻辑分析**:
```yaml
query:
max-memory-per-node: 10GB
max-total-memory-per-node: 80GB
max-parallelism: 256
min-cpu-per-gather: 4
```
这个YAML配置示例设置了Trino查询的内存和CPU限制。其中`max-memory-per-node`限制了每个节点可用的最大内存,防止单个查询独占过多资源。`max-total-memory-per-node`限制了整个查询可使用的最大内存总量,防止系统内存溢出。`max-parallelism`定义了查询时允许的最大并行度,而`min-cpu-per-gather`保证了足够的CPU资源用于执行数据收集操作。
### 3.2 查询优化技巧
在Trino中,SQL语句的编写和数据分布情况直接影响查询效率。
#### 3.2.1 SQL语句改写
SQL语句改写的目标是减少查询所需的数据量和处理时间。改写可以从以下几个方面进行:
- **避免全表扫描**:尽量使用索引进行查询。
- **使用子查询代替连接**:在可能的情况下,使用子查询替代join操作,尤其是在数据量较小的时候。
- **减少计算复杂度**:如避免使用`ORDER BY`或`LIMIT`子句时不必要的计算。
- **避免复杂的列操作**:在不影响查询结果的前提下,简化对列的操作,例如减少函数的使用。
**示例代码**:
```sql
-- 优化前
SELECT * FROM table WHERE YEAR(column) = 2021;
-- 优化后,直接使用字段索引
SELECT * FROM table WHERE column >= '2021-01-01' AND column < '2022-01-01';
```
优化前的查询中,使用了`YEAR()`函数,这可能导致全表扫描。优化后的查询直接对日期字段进行范围查询,可以利用索引提高查询效率。
#### 3.2.2 数据分布与分区策略
Trino的数据分布和分区策略关系到数据加载和处理的速度,影响查询性能。
- **数据本地化**:通过合理分区,将数据分布在不同的节点上,减少数据在网络中的传输。
- **分区键选择**:选择合适的分区键,使得相关数据聚集在一起,提高数据查询的效率。
- **倾斜数据处理**:避免数据倾斜,即数据在某个分区上过于集中,导致查询负载不均衡。
**Mermaid流程图**展示数据分布优化流程:
```mermaid
graph TD
A[开始] --> B[分析查询模式]
B --> C[确定数据分区策略]
C --> D[优化数据分布]
D --> E[应用分区键]
E --> F[监控性能]
F --> G[循环优化]
```
通过上述流程图,我们可以看到从分析查询模式开始,逐步确定分区策略,并通过实际应用监控效果,根据性能反馈来循环优化数据分布策略。
### 3.3 连接器与数据源优化
Trino通过连接器与不同的数据源进行交互,连接器的选择和优化对整体性能影响显著。
#### 3.3.1 连接器性能分析
性能分析包括:
- **连接器性能评估**:不同的连接器有不同的性能表现,评估并选择最合适的连接器。
- **资源消耗**:监控连接器在资源使用方面的表现,及时调整资源分配策略。
#### 3.3.2 数据源优化策略
数据源优化包括:
- **索引优化**:为数据源创建适当的索引,提高查询效率。
- **表分区策略**:为数据源制定合理的分区策略,与Trino集群的分区策略保持一致,以提高数据查询的效率。
**表格**对比不同连接器的性能指标:
| 连接器 | 兼容性 | 性能 | 资源消耗 |
| ------ | ------ | ---- | -------- |
| Postgres | 高 | 中等 | 低 |
| MySQL | 高 | 较低 | 低 |
| Cassandra | 低 | 高 | 高 |
在表格中,我们列出了三个连接器的兼容性、性能和资源消耗情况,以此帮助用户根据实际需求进行选择。
通过对资源和硬件的优化、查询技巧的提升,以及连接器和数据源的优化,可以显著提高Trino的性能表现。在下一章节中,我们将深入探讨Trino的高级性能调优技巧。
# 4. Trino高级性能调优技巧
在深入分析Trino的架构和基本工作原理后,接下来将探讨一些更高级的性能调优技巧。这些技巧涉及缓存与内存管理、并行处理与并发控制,以及针对Java虚拟机(JVM)的优化,这些高级技巧将帮助Trino实现更高的性能和效率。
## 4.1 缓存与内存管理
### 4.1.1 缓存机制与策略
Trino作为一个分布式查询引擎,为了提高查询效率,采用了多种缓存机制。缓存的使用减少了对数据源的访问次数,加快了响应速度,但也需要合理配置以避免内存溢出。
#### 缓存策略
- **结果集缓存(Result Set Caching)**:Trino可以将查询结果保存在缓存中,对于后续相同查询可直接返回缓存结果,避免重复计算。
- **查询计划缓存(Query Plan Caching)**:查询计划被保存在缓存中,相同的查询可以直接使用缓存的查询计划执行,加速查询。
- **元数据缓存(Metadata Caching)**:Trino通过缓存表和列的元数据来提高查询的响应速度。
#### 实施缓存策略
1. **配置缓存大小**:需要根据实际应用场景调整缓存大小,保证热点数据可以被有效缓存,同时防止缓存过大影响内存使用。
2. **缓存失效策略**:合理配置缓存失效时间,以及当缓存达到限制时,决定是优先淘汰旧数据还是新数据。
```yaml
trino:
cache:
result_set:
enabled: true
max_entries: 10000
query_plan:
enabled: true
max_entries: 500
```
通过上述配置示例,我们开启了结果集和查询计划缓存,并设置了缓存最大条目数。
### 4.1.2 内存使用优化
内存管理是性能调优中非常关键的部分,合理地分配和管理内存资源可以显著提升Trino的执行效率。
#### 内存分配
- **工作内存(Working Memory)**:用于执行查询操作的内存资源。
- **查询内存(Query Memory)**:每个查询能够使用的最大内存。
#### 优化建议
1. **合理设置内存限制**:根据集群大小和查询负载合理分配内存。
2. **避免内存溢出**:监控内存使用情况,避免单一查询占用过多内存导致的系统不稳定性。
```sql
-- 查询内存分配示例
SHOW SESSION;
```
执行上述SQL可以查看当前会话的内存分配情况。
## 4.2 并行处理与并发控制
### 4.2.1 并行查询优化
并行处理是Trino处理查询的基石,Trino通过并行处理可以将任务分散到多个节点上执行,以此提高查询效率。
#### 提升并行度
- **节点数量**:增加集群中的节点数量,提供更多的并行处理能力。
- **任务划分**:合理划分查询任务,确保每个任务都能有效利用资源,避免资源浪费。
#### 具体实施
1. **调整查询任务大小**:通过调整参数来控制并行查询任务的大小,太大或太小都可能导致资源利用不当。
2. **数据分区**:优化数据的分区策略,确保数据均匀分布,避免数据倾斜。
```properties
-- 配置并行度
query.max-parallelism=100
```
上述配置示例将查询的最大并行度设置为100。
### 4.2.2 并发参数调整
合理配置并发参数可以更精细地控制Trino的资源使用,提高集群的并发处理能力。
#### 并发参数
- **并发任务数**:集群能够同时执行的最大查询任务数量。
- **节点并发数**:每个节点上能够同时运行的查询任务数量。
#### 调整策略
1. **资源隔离**:合理配置资源隔离,避免某些查询过度占用资源。
2. **动态调整**:在执行大量并行查询时,可能需要动态调整并发参数,以适应不同的负载情况。
```sql
-- 查看当前并发参数
SHOW SESSION;
```
通过上述SQL可以查看并调整当前会话的并发参数。
## 4.3 JVM调优
### 4.3.1 Java虚拟机性能调优基础
JVM调优是高级性能优化的一个关键部分,Trino作为一个Java应用,其性能很大程度上依赖于JVM的调优。
#### 垃圾收集器选择
- **G1收集器**:适用于大内存环境,注重垃圾收集与应用暂停时间之间的平衡。
- **ZGC收集器**:适用于需要低停顿时间的场景,适用于高并发和大内存的应用。
#### 调优建议
1. **根据应用特点选择合适的垃圾收集器**:例如,如果应用对停顿时间要求不高,G1收集器是一个不错的选择。
2. **监控和调优JVM参数**:监控JVM的运行情况,根据实际情况调整堆内存大小、垃圾收集器参数等。
```shell
java -Xmx4G -XX:+UseG1GC -jar trino-server.jar
```
以上示例为启动Trino时指定JVM参数,其中`-Xmx4G`表示最大堆内存为4GB,`-XX:+UseG1GC`启用G1垃圾收集器。
### 4.3.2 Trino中JVM的配置与优化
Trino在运行时依赖JVM,因此JVM的配置直接影响着Trino的性能。
#### 核心配置
- **堆内存大小**:根据查询负载和数据集大小合理设置堆内存。
- **线程数**:调整JVM线程数以适应集群规模和查询类型。
#### 调优实例
1. **堆内存设置**:需要根据实际情况来调整,例如,如果遇到频繁的Full GC,可能需要增加堆内存。
2. **线程数调整**:集群规模较大时,应增加线程数以提高并发执行能力。
```yaml
jvm:
heap-size: 4G
threads: 256
```
上述配置展示了如何在Trino的配置文件中设置JVM参数。
至此,我们已经探讨了缓存与内存管理、并行处理与并发控制,以及JVM调优的高级技巧,为Trino性能调优提供了更深入的了解。在接下来的章节中,我们将通过案例分析来深入了解这些技巧的应用。
# 5. Trino性能调优案例分析
## 5.1 典型性能问题诊断
### 5.1.1 性能瓶颈的识别方法
在进行Trino性能调优时,首要任务是识别和定位性能瓶颈。这通常涉及到以下几个步骤:
- **资源监控**: 使用如JMX、Prometheus等工具监控CPU、内存、磁盘I/O等资源使用情况。
- **日志分析**: 分析Trino的日志文件,特别是错误日志和查询日志,以发现异常行为或查询模式。
- **查询分析**: 通过Trino的Web界面或使用命令行工具检查慢查询。
- **性能指标**: 关注执行时间、读取数据量、处理数据量等指标。
### 5.1.2 常见问题案例与解决方案
**案例一:查询响应时间慢**
- **分析**: 这可能是由于不合理的查询计划,或硬件资源不足导致。
- **解决**:
1. 优化查询语句,添加必要的索引。
2. 调整Trino服务器的资源配置,如增加内存、CPU核心。
**案例二:数据倾斜导致查询不均衡**
- **分析**: 数据分布在不同的节点上可能导致部分节点负载过高。
- **解决**:
1. 优化数据分区,尽可能均匀分配。
2. 调整查询策略,使用数据局部性原理。
## 5.2 大数据环境下的性能优化
### 5.2.1 大数据场景的特点
大数据场景通常意味着数据量大、查询复杂、计算密集。在这种环境下,Trino可能会面临以下挑战:
- 处理大量数据的高吞吐需求。
- 复杂查询带来的计算和存储压力。
- 需要支持高并发的数据访问。
### 5.2.2 针对大数据场景的优化策略
**优化策略一:数据存储与索引优化**
- 使用HDFS、S3等分布式存储系统,保证数据的高可用性和水平扩展能力。
- 在数据存储上合理建立索引,提高查询效率。
**优化策略二:分布式计算优化**
- 利用Trino的分布式计算能力,通过增加工作节点来提高并发处理能力。
- 调整并行度参数,使得查询任务可以更细粒度地分布到各个节点。
## 5.3 持续性能优化与最佳实践
### 5.3.1 持续性能监控的重要性
持续监控是性能优化的重要环节,可以确保系统性能维持在最佳状态。主要监控内容包括:
- 实时监控:CPU、内存、磁盘I/O、网络带宽的使用情况。
- 历史数据监控:长期跟踪资源使用趋势,进行容量规划。
- 查询性能监控:监控慢查询和执行计划的变化。
### 5.3.2 从经验中学习:最佳实践分享
**最佳实践一:性能基准测试**
- 定期进行基准测试,量化Trino的性能指标,作为调优的基线参考。
**最佳实践二:文档化与知识共享**
- 将性能调优的过程和结果记录下来,形成文档。
- 定期举行分享会,让团队成员了解最佳实践。
通过这些章节内容的深入探讨,可以更有效地对Trino进行性能调优,优化整体查询性能,并且能够更好地应对大数据环境下的挑战。Trino的性能优化不仅仅是一项技术活动,更是一个持续学习和不断进步的过程。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Trino优化宝典》是一本全面的指南,旨在帮助用户优化Trino性能。该专栏深入探讨了Trino的各种优化技术,涵盖从查询执行计划分析到内存管理和缓存策略。它提供了详细的指导和最佳实践,帮助用户掌握Trino的并发控制机制、连接器性能提升、资源调度智能化和多租户架构部署。此外,该专栏还提供了有关Trino监控和报警、事务处理强化、数据处理流程优化、与Spark集成和执行引擎调优的深入见解。通过遵循本指南中的策略和技巧,用户可以显著提高Trino性能,释放其数据处理潜力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
三菱NZ81GP21-SX型接口板安装与配置:CC-Link IE技术基础完全攻略

# 摘要
CC-Link IE技术作为一种工业以太网解决方案,已被广泛应用于自动化控制领域。本文首先概述了CC-Link IE技术的基本概念及其重要性。随后,重点介绍了三菱NZ81GP21-SX型接口板的硬件结构及功能,并详细阐述了其安装步骤,包括物理安装和固件更新。接着,本文深入探讨了CC-Link I
【Pinpoint性能监控深度解析】:架构原理、数据存储及故障诊断全攻略
# 摘要
Pinpoint性能监控系统作为一款分布式服务追踪工具,通过其独特的架构设计与数据流处理机制,在性能监控领域展现出了卓越的性能。本文首先概述了Pinpoint的基本概念及其性能监控的应用场景。随后深入探讨了Pinpoint的架构原理,包括各组件的工作机制、数据收集与传输流程以及分布式追踪系统的内部原理。第三章分析了Pinpoint在数据存储与管理方面的技术选型、存储模型优化及数据保留策略。在第四章中,本文详细描述了Pinpoint的故障诊断技术,包括故障分类、实时故障检测及诊断实例。第五章探讨了Pinpoint的高级应用与优化策略,以及其未来发展趋势。最后一章通过多个实践案例,分享了
软件工程中的FMEA实战:从理论到实践的完整攻略
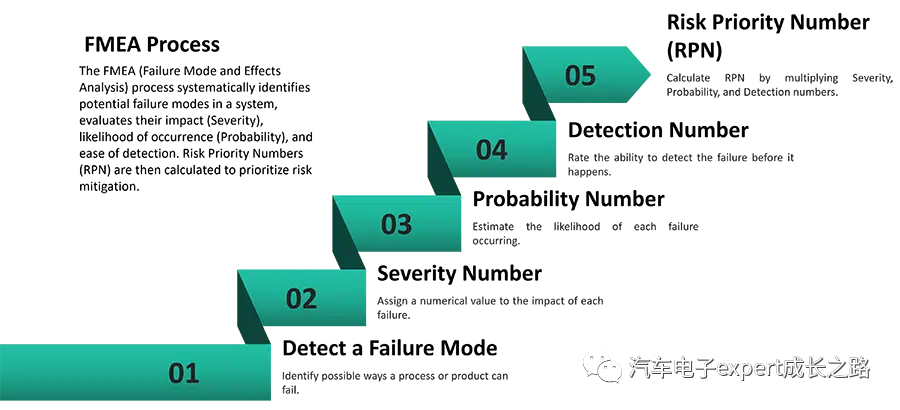
# 摘要
FMEA(故障模式与影响分析)是软件工程中用于提高产品可靠性和安全性的重要质量工具。本文详细解析了FMEA的基本概念、理论基础和方法论,并探讨了其在软件工程中的分类与应用。文章进一步阐述了FMEA实践应用的流程,包括准备工作、执行分析和报告编写等关键步骤。同时,本文还提供了FMEA在敏捷开发环境中的应用技巧,并通过案例研究分享了成功的行
CITICs_KC接口数据处理:从JSON到XML的高效转换策略
![CITICs_KC股票交易接口[1]](https://bytwork.com/sites/default/files/styles/webp_dummy/public/2021-07/%D0%A7%D1%82%D0%BE%20%D1%82%D0%B0%D0%BA%D0%BE%D0%B5%20%D0%9B%D0%B8%D0%BC%D0%B8%D1%82%D0%BD%D1%8B%D0%B9%20%D0%BE%D1%80%D0%B4%D0%B5%D1%80.jpg?itok=nu0IUp1C)
# 摘要
随着信息技术的发展,CITICs_KC接口在数据处理中的重要性日益凸显。本文首先概述了C
光学信号处理揭秘:Goodman版理论与实践,光学成像系统深入探讨

# 摘要
本文系统地介绍了光学信号处理的基础理论、Goodman理论及其深入解析,并探讨了光学成像系统的实践应用。从光学信号处理的基本概念到成像系统设计原理,再到光学信号处理技术的最新进展和未来方向,本文对光学技术领域的核心内容进行了全面的梳理和分析。特别是对Goodman理论在光学成像中的应用、数字信号处理技术、光学计算成像技术进行了深入探讨。同时,本文展望了量子光学信号处理、人工智能在光
队列的C语言实现:从基础到循环队列的进阶应用
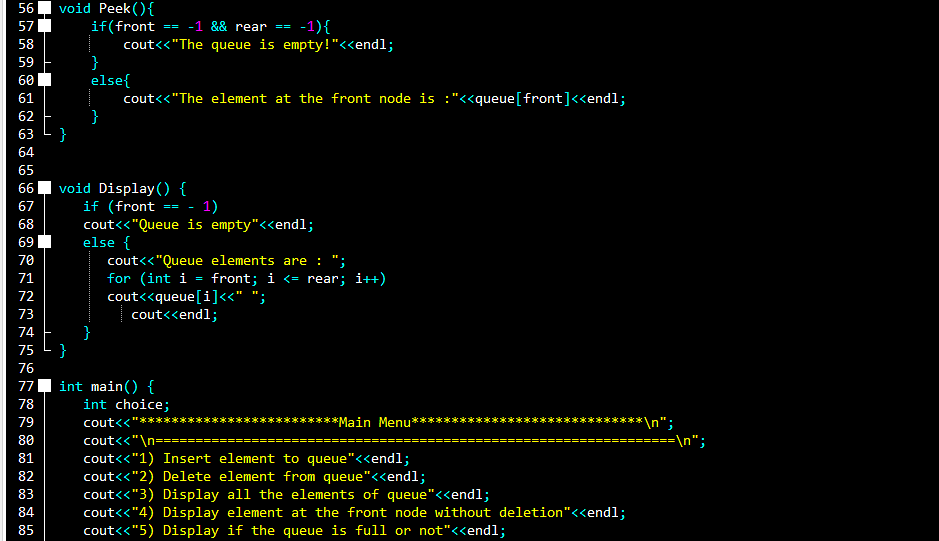
# 摘要
本论文旨在系统地介绍队列这一基础数据结构,并通过C语言具体实现线性队列和循环队列。首先,本文详细解释了队列的概念、特点及其在数据结构中的地位。随后,深入探讨了线性队列和循环队列的实现细节,包括顺序存储结构设计、入队与出队操作,以及针对常见问题的解决方案。进一步,本文探讨了队列在
【CAXA图层管理:设计组织的艺术】:图层管理的10大技巧让你的设计井井有条
# 摘要
图层管理是确保设计组织中信息清晰、高效协同的关键技术。本文首先介绍了图层管理的基本概念及其在设计组织中的重要性,随后详细探讨了图层的创建、命名、属性设置以及管理的理论基础。文章进一步深入到实践技巧,包括图层结构的组织、视觉管理和修改优化,以及CAXA环境中图层与视图的交互和自动化管理。此外,还分析了图层管理中常见的疑难问题及其解决策略,并对图层管理技术的未来发展趋势进行了展望,提出了一系列面向未来的管理策略。
# 关键字
图层管理;CAXA;属性设置;实践技巧;自动化;协同工作;未来趋势
参考资源链接:[CAXA电子图板2009教程:绘制箭头详解](https://wenku.c
NET.VB_TCPIP协议栈深度解析:从入门到精通的10大必学技巧

# 摘要
本文全面探讨了TCP/IP协议栈的基础理论、实战技巧以及高级应用,旨在为网络工程师和技术人员提供深入理解和高效应用TCP/IP协议的指南。文章首先介绍了TCP/IP协议栈的基本概念和网络通信的基础理论,包括数据包的封装与解封装、传输层协议TCP和UDP的原理,以及网络层和网络接口层的关键功能。接着,通过实战技巧章节,探讨了在特定编程环境下如VB进行
MCP41010数字电位计初始化与配置:从零到英雄
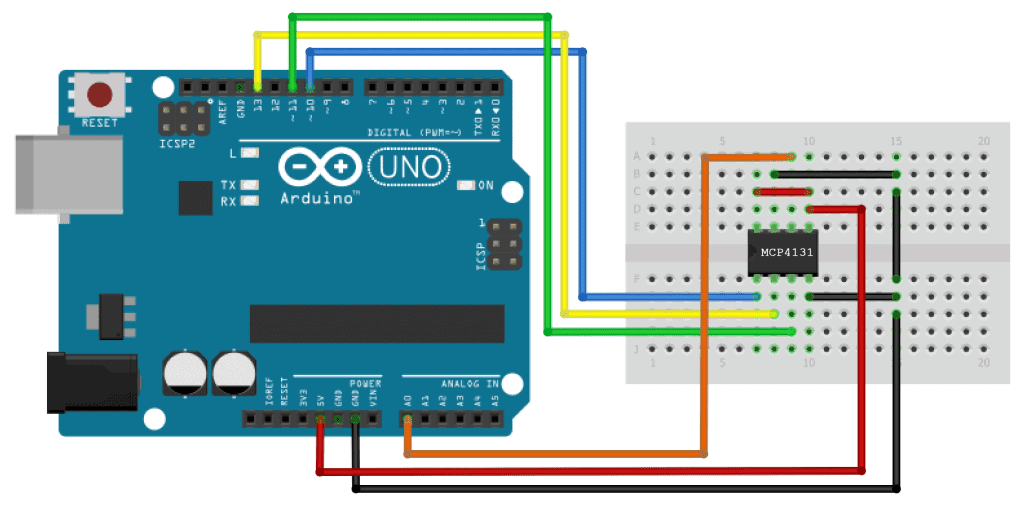
# 摘要
本文全面介绍MCP41010数字电位计的功能、初始化、配置以及高级编程技巧。通过深入探讨其工作原理、硬件接口、性能优化以及故障诊断方法,本文为读者提供了一个实用的技术指导。案例研究详细分析了MCP41010在电路调节、用户交互和系统控制中的应用,以
【Intouch界面初探】:5分钟掌握Intouch建模模块入门精髓

# 摘要
本文系统性地介绍了Intouch界面的基本操作、建模模块的核心概念、实践应用,以及高级建模技术。首先,文章概述了Intouch界面的简介与基础设置,为读者提供了界面操作的起点。随后,深入分析了建模模块的关键组成,包括数据驱动、对象管理、界面布局和图形对象操作。在实践应用部分,文章详细讨论了数据
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )