搜索引擎广告中的地域定向优化策略
发布时间: 2024-02-22 15:38:49 阅读量: 65 订阅数: 37 

搜索引擎优化策略
# 1. 搜索引擎广告中的地域定向概述
## 1.1 什么是地域定向
地域定向是指在广告投放过程中,根据广告主的需求和目标受众的地理位置特征,将广告投放展现给特定地域的用户群体。地域定向可以通过用户的IP地址、地理位置信息、地域兴趣等数据进行精准匹配和定向投放。
## 1.2 地域定向在搜索引擎广告中的作用
在搜索引擎广告中,地域定向可以帮助广告主精准地将广告展示给特定地域的潜在客户,提高广告的曝光度和点击率。通过地域定向,广告主可以更有效地管理广告预算,避免无效流量的浪费,实现更精准的营销推广。
## 1.3 地域定向对广告效果的影响
地域定向可以显著影响广告的效果和转化率。通过合理的地域定向策略,可以提高广告的转化率,降低点击成本,提升广告投放的ROI。在市场营销中,地域定向也被广泛运用于促销活动、地方品牌推广、本地化服务推广等方面。
接下来的章节将深入探讨地域定向优化的重要性、地域定向优化策略、最佳实践与案例分享,以及地域定向优化工具与技术等内容。
# 2. 地域定向优化的重要性
在搜索引擎广告中,地域定向优化是至关重要的一环。通过合理的地域定向策略,广告主可以更精准地触达目标受众,提升广告投放效果。以下将详细讨论地域定向优化的重要性及其对广告投放的影响。
### 2.1 地域定向优化对广告投放成本的影响
地域定向优化可以帮助广告主有效控制广告投放成本。通过分析不同地区的用户点击、转化等数据,进行地域定向的精细化调整,可以避免资源浪费,将广告重点投放在最具潜力的地区,从而降低整体广告投放成本。
```python
# 代码示例:地域定向成本优化-数据分析
import pandas as pd
# 模拟不同地区用户点击成本
data = {
'地区': ['A', 'B', 'C', 'D'],
'点击成本': [0.5, 0.6, 0.4, 0.7]
}
df = pd.DataFrame(data)
print(df)
# 计算平均点击成本
avg_cost = df['点击成本'].mean()
print("平均点击成本为:", avg_cost)
```
**代码总结:** 通过数据分析不同地区的点击成本,可以找到平均成本并据此优化地域定向策略。
**结果说明:** 通过地域定向优化,广告主可以根据不同地区的点击成本调整广告投放策略,有效降低整体广告投放成本。
### 2.2 地域定向优化对广告点击率的影响
精准的地域定向可以提升广告的点击率。针对不同地区的用户特点和偏好,调整广告内容和投放时机,使广告更具吸引力,提高用户点击率和转化率。
```java
// 代码示例:地域定向点击率优化-内容调整
public class AdOptimization {
public static void main(String[] args) {
String location = "A";
String adContent;
if (location.equals("A")) {
adContent = "地区A用户专属优惠,限时抢购!";
} else {
adContent = "全国通用优惠券,立即领取!";
}
System.out.println("当前广告内容:" + adContent);
}
}
```
**代码总结:** 根据地域特点调整广告内容,提升地域定向广告的点击率。
**结果说明:** 通过地域定向优化,广告内容更贴近目标地区

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏探讨了SEM实战课程中关于搜索引擎广告优化的一系列重要内容。从搜索引擎广告的基本原理到具体的优化技巧,包括搜索引擎广告排名原理、关键词优化、目标页面创建、广告拓展选项应用、投放调整技巧、A/B测试优化、转化率提升、竞价策略、定位与定向策略等方面进行了深入讨论。此外,还涉及到搜索网络与展示网络应用、效果跟踪工具的使用、地域定向优化、设备定向以及优化技巧等内容。通过本专栏的学习,读者将能够全面了解搜索引擎广告的优化策略,掌握实战技巧,提升广告效果,为营销策略的制定提供有力支持。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
rrpack功能深度剖析:10个技巧让你效率翻倍
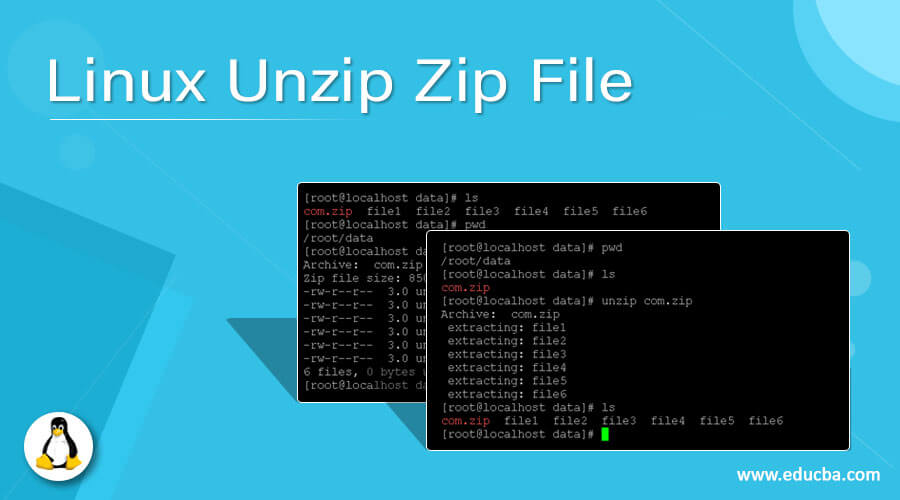
# 摘要
rrpack作为一种高效的工具,广泛应用于提升工作效率和自动化管理任务。本文首先对rrpack进行概述,并分析其在提高效率方面的作用。接着,详细介绍rrpack的核心功能,实用技巧以及与其他工具的协同工作,如版本控制和DevOps工具链。进一步探讨rrpack的高级用法和性能优化策略,包括脚本编写、并发处理、监控与日志管理。文章还提供了rrpack在金融、IT和
iSecure Center与物联网:构建智能安防系统的关键步骤
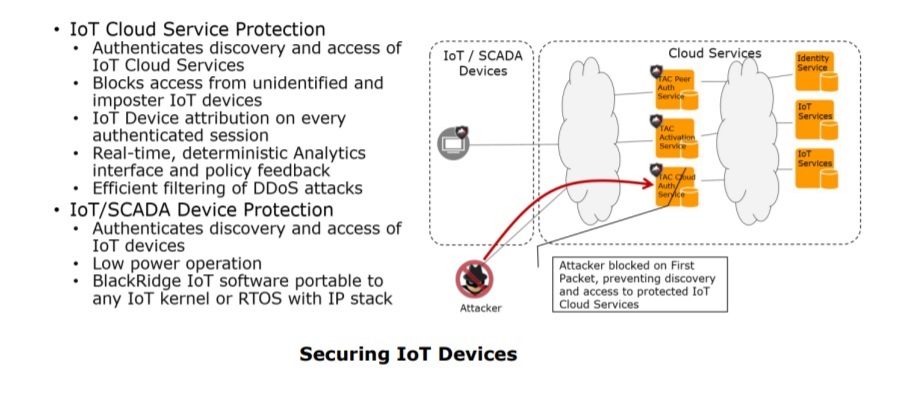
# 摘要
本文介绍iSecure Center及其在物联网基础中的应用,探讨构建物联网智能安防系统的核心组件,包括硬件组件、通信技术、软件平台以及数据管理和机器学习的应用。文章详细分析了iSecure Center的实践应用,包括系统部署、定制化开发、安全与维护。此外,本文还探讨了iSecure Center在智能安防中的高级应用,如智能识别技术、大数据分析和决策
【H3C-CAS-Converter环境搭建】:从零开始的完整攻略

# 摘要
本文全面介绍了H3C-CAS-Converter环境的搭建过程,涵盖了从硬件配置、操作系统安装、网络环境设置到必要的软件和工具安装。详细阐述了软件的下载、验证、安装步骤及其配置方法,并对安装后的环境进行了验证。为了提升系统的性能和安全性,本文还提供了性能调优、安
系统效率提升指南:Modbus_RTU CRC校验优化关键步骤
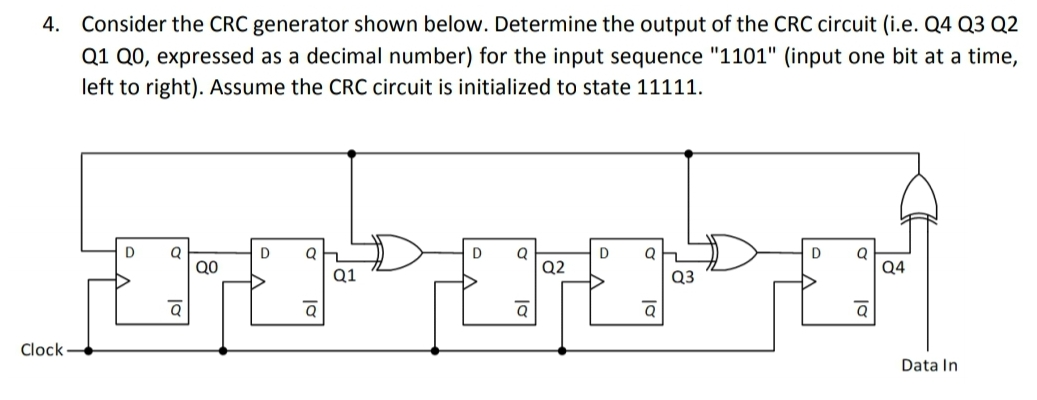
# 摘要
Modbus RTU作为工业通讯中广泛使用的一种协议模式,其数据传输的准确性与可靠性在很大程度上依赖于CRC校验。本文首先概述了Modbus协议和RTU模式,并深入探讨了CRC校验的基础理论、算法原理及其实现。文章详细分析了CRC校验的软件与硬件实现方法,并探讨了在保持能耗最低的同时优化性能的策略。通过实际案例分析,本文展示了CRC校验在
【XP系统AHCI模式全面解析】:从BIOS设置到性能提升,一步到位

# 摘要
本文系统地探讨了AHCI(高级主机控制器接口)模式的原理及其在存储技术中的重要性。文章首先介绍了AHCI的基本概念和在BIOS中的设置方法,随后深入分析了AHCI模式相较于传统IDE模式在性能上的优势,包括数据传输速度和系统响应时间的提升。紧接着,本文详述了从IDE模式迁移到AH
【C++课程管理系统开发全攻略】:新手入门到性能优化的终极指南

# 摘要
本文详细介绍了C++课程管理系统的设计与实现,涵盖从基础语法回顾到系统架构设计,再到高级功能开发及测试部署的全流程。首先,回顾了C++的基础语法和面向对象编程的概念,深入探讨了C++的核心特性。接着,本文阐述了系统架构设计中的模块划分、数据库交互以及功能模块的开发实践,包括用户登录、课程信息管理及成绩处理等。文章进一步探讨了高级功能,如网络通信、多线程编程和跨平台技
【TIPTOP GP升级宝典】:从旧版到新版的无缝转换技巧

# 摘要
本文全面概述了GP系统的升级过程,涵盖从准备工作、实施升级到后续优化调整的完整阶段。首先,文章强调了环境评估、数据备份和用户培训的重要性,以确保升级顺利进行。在升级过程中,详细阐述了新版系统的安装部署、数据迁移、功能验证等关键步骤。升级后,着重讨论了性能调优、问题诊断与修复,以及持续支持与更新的重要性。最后
串行通信核心揭秘:单片机串口函数与高级配置全解析

# 摘要
串行通信是电子设备间传递信息的基本方式,尤其在单片机领域占有重要地位。本文首先介绍了串行通信的基础概念和原理,然后深入探讨了单片机中串口的基础知识,包括串口的硬件结构及其在通信中的关键作用。接着,文章转向串口编程基础,涵盖初始化配置和通信函数的使用。进一步地,文章讨论了高级串口通信技术,包括多串口配置和实时数据处理策略。最后,通过实例分析了串口在实际项目中的应用及常见问题的解决方法。本文旨在为
【深入解析Excel公式】:身份证号码中年龄的自动计算方法
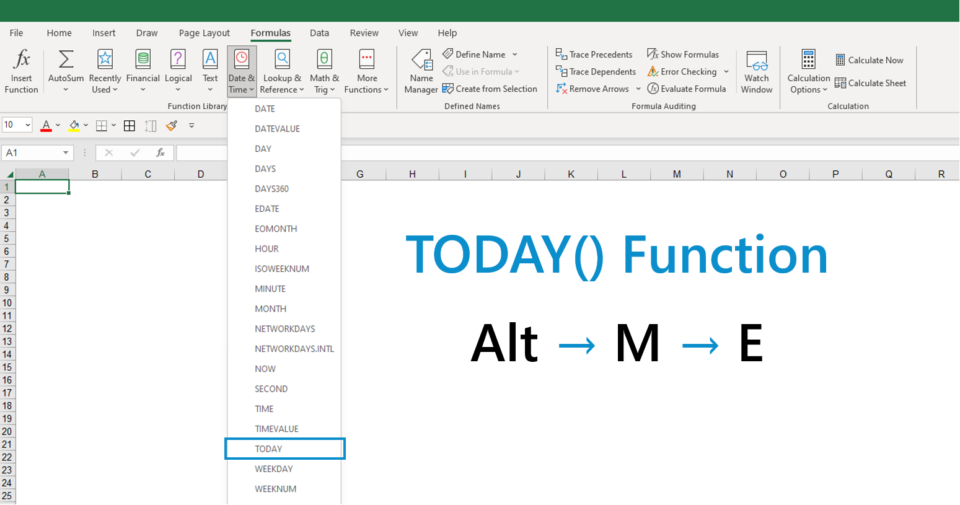
# 摘要
本文旨在提供一个详尽的指南,以在Excel环境中解析和计算身份证号码中的年龄信息。文章首先介绍了身份证号码的基本信息和结构,接着详细阐述了使用Excel公式进行身份证号码解析和年龄计算的基本方法和技巧。在此基础上,本文进一步讨论了年龄计算公式的高级应用和优化,包括如何处理跨年度更新、增强公式的通用性及错误处理。最后,文章展望了Excel公式在年
Chroma 8000测试命令秘籍

# 摘要
本文全面介绍了Chroma 8000测试系统的功能和操作,从基础的测试命令介绍到测试脚本的编写与实践,再到测试场景的具体应用,并通过案例分析分享了实际操作经验和最佳实践。文章首先概述了Chroma 8000测试系统的基本概念,然后详细阐述了测试命令的结构、语法和核心功能,以及测试参数的配置与管理。接下来,文章深入讨论了测试脚本的编写基础、高级应用技巧以及如何
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )