深入解析云计算架构及其关键组件
发布时间: 2024-02-04 17:52:09 阅读量: 113 订阅数: 21 

云计算架构
# 1. 云计算基础概述
## 1.1 什么是云计算
云计算是一种通过互联网按需提供计算资源和服务的模式,用户无需了解、理解和控制云计算基础设施的具体技术细节。
## 1.2 云计算的发展历程
云计算概念最早可以追溯到20世纪60年代,随着互联网技术和虚拟化技术的发展,云计算逐渐成为一种强大的计算范式。
## 1.3 云计算的优势和应用场景
云计算的优势包括灵活的资源调配、高可用性、弹性扩展和成本效益等,广泛应用于企业 IT 系统、大数据分析、物联网等领域。
以上是云计算基础概述章节的初步内容草稿,接下来可以根据需要进行详细的代码编写和完善。
# 2. 云计算架构概述
云计算架构是指在云计算环境中,为实现云计算所需的各种功能和服务而构建的软件架构和硬件基础设施。云计算架构的设计需要考虑系统的可靠性、高性能、可扩展性和安全性等方面的要求,以满足用户在云环境中对计算、存储、网络等方面的需求。
#### 2.1 云计算架构的定义和特点
云计算架构的定义:云计算架构旨在构建一个高度自动化、可伸缩、灵活且安全的计算环境,以支持各种不同的应用和工作负载。其特点包括:
- **弹性可扩展**:云计算架构能够根据需求快速调整资源,实现弹性扩展和收缩,以满足不同规模和负载下的计算需求。
- **虚拟化技术**:云计算架构广泛使用虚拟化技术,通过将物理资源虚拟化为多个虚拟资源实现资源的灵活分配和利用。
- **服务治理**:云计算架构借助服务治理机制,对各种服务进行管理与监控,保障服务的稳定性和可靠性。
#### 2.2 云计算架构的主要组成部分
云计算架构通常包括以下主要组成部分:
- **硬件基础设施**:包括服务器、存储设备、网络设备等硬件资源,构成了云计算的基础设施。
- **虚拟化层**:虚拟化层是云计算架构的核心组成部分,通过虚拟化技术将物理资源虚拟化为虚拟资源,实现资源的灵活管理和分配。
- **管理与编排系统**:管理与编排系统负责对硬件和虚拟资源进行统一管理和调度,实现资源的动态分配和横向扩展。
#### 2.3 云计算架构的层次划分
根据功能和责任的不同,云计算架构通常可以划分为以下几个层次:
- **物理层**:包括物理硬件资源,如服务器、存储设备、网络设备等。
- **虚拟化层**:通过虚拟化技术将物理资源虚拟化为虚拟资源,为上层提供资源池。
- **管理与编排层**:负责管理和编排虚拟资源,实现资源的动态分配和任务调度。
- **应用层**:包括各种面向用户的应用和服务,如计算服务、存储服务、网络服务等。
以上是云计算架构概述的章节内容,后续章节将进一步介绍云计算架构的关键组成部分和技术细节。
# 3. 云计算基础设施
云计算的基础设施是实现云计算服务的重要组成部分。本章将介绍虚拟化技术及其在云计算中的应用、数据中心的构建与管理以及网络与存储技术在云计算中的作用。
#### 3.1 虚拟化技术及其在云计算中的应用
虚拟化技术是云计算基础设施的核心技术之一,它可以将物理资源抽象成虚拟的资源,为不同的用户提供独立的计算环境。常见的虚拟化技术包括虚拟机技术、容器化技术和轻量级虚拟化技术。
**3.1.1 虚拟机技术**
虚拟机技术通过软件模拟出一个完整的计算机系统,包括CPU、内存、存储和网络等硬件资源。每个虚拟机都可以独立运行不同的操作系统和应用程序,而云服务提供商可以根据用户的需求,灵活地调整虚拟机的配置和规模。
下面是使用Python语言创建虚拟机的示例代码:
```python
import libvirt
conn = libvirt.open('qemu:///system')
if conn is None:
print('Failed to open connection to the hypervisor')
exit(1)
# 创建虚拟机
xml_desc = """
<domain type='kvm'>
<name>myvm</name>
<memory unit='KiB'>1048576</memory>
<vcpu placement='static'>1</vcpu>
<os>
<type arch='x86_64' machine='pc-i440fx-2.9'>hvm</type>
<boot dev='hd'/>
</os>
<devices>
<disk type='file' device='disk'>
<driver name='qemu' type='qcow2'/>
<source file='/var/lib/libvirt/images/myvm.qcow2'/>
<target dev='vda' bus='virtio'/>
</disk>
</devices>
</domain>
conn.createXML(xml_desc, 0)
print('Virtual machine created successfully')
# 关闭连接
conn.close()
```
**代码解释:**
- 首先,使用`libvirt.open`函数打开与QEMU/KVM hypervisor的连接。
- 然后,使用XML描述语言创建虚拟机的配置信息。
- 最后,调用`createXML`函数创建虚拟机并指定配置信息。
**代码总结:**
以上代码演示了使用Python和libvirt库创建虚拟机的基本过程。
**结果说明:**
如果运行成功,将输出"Virtual machine created successfully"表示虚拟机创建成功。
**3.1.2 容器化技术**
容器化技术是一种轻量级的虚拟化技术,它通过共享操作系统内核,在隔离的环境中运行应用程序。与虚拟机相比,容器化技术更加轻量级和灵活,可以实现快速部署和扩展。
下面是使用Docker工具创建容器的示例代码:
```python
import docker
client = docker.from_env()
# 创建容器
container = client.containers.create('nginx:latest')
container.start()
print('Container created successfully')
# 关闭容器
container.stop()
print('Container stopped successfully')
```
**代码解释:**
- 首先,使用`docker.from_env`函数创建与Docker引擎的连接。
- 然后,调用`client.containers.create`函数创建一个基于"nginx:latest"镜像的容器。
- 最后,调用容器的`start`方法启动容器。
**代码总结:**
以上代码演示了使用Python和Docker SDK进行容器创建和启动的基本过程。
**结果说明:**
如果运行成功,将输出"Container created successfully"表示容器创建成功,并且"Container stopped successfully"表示容器停止成功。
#### 3.2 数据中心的构建与管理
数据中心是云计算基础设施的核心组成部分,它是用于存储、处理和管理大量数据的物理或虚拟环境。数据中心的构建需要考虑服务器硬件的选型和规划、数据的备份与恢复、冷热备份策略等。
**3.2.1 服务器硬件选型和规划**
数据中心的服务器硬件选型需要考虑性能、可靠性、扩展性和能耗等因素。通常会选择高性能的服务器,通过搭建集群的方式提高整体计算和存储能力。
此处省略代码示例。
**3.2.2 数据的备份与恢复**
数据中心的数据备份是保证数据安全性和可靠性的重要手段。常见的数据备份方式包括增量备份、全量备份和镜像备份。此外,还需要制定适当的数据恢复策略,以便在数据丢失或损坏时能够快速恢复。
此处省略代码示例。
**3.2.3 冷热备份策略**
数据中心的冷热备份策略是根据数据的访问频率和重要性,将数据分为热数据和冷数据,采取不同的备份策略和存储介质。热数据备份通常使用高性能的存储设备,而冷数据备份则可以使用较低成本的存储设备。
此处省略代码示例。
#### 3.3 网络与存储技术在云计算中的作用
网络和存储技术在云计算中起着至关重要的作用,它们为云服务的交互和数据存储提供支持。
**3.3.1 网络技术**
云计算中的网络技术包括网络拓扑设计、网络安全策略和网络带宽管理等方面。通过合理设计和管理网络,可以确保云服务的稳定性和安全性。
此处省略代码示例。
**3.3.2 存储技术**
云计算中的存储技术包括分布式存储、对象存储和块存储等。这些存储技术可以提供高性能、可靠性和可扩展性的数据存储解决方案。
此处省略代码示例。
以上是云计算基础设施的简要介绍,虚拟化技术、数据中心构建与管理以及网络与存储技术在云计算中扮演着重要角色。在实际应用中,需要根据具体场景和需求选择适当的技术和方案。
# 4. 云计算的关键组件之一——云服务模型
#### 4.1 基础设施即服务(IaaS)
云计算中的基础设施即服务(Infrastructure as a Service,IaaS)是一种云服务模型,提供虚拟化的计算资源、存储资源和网络资源。用户可以通过IaaS模型,按需自助地使用这些资源,而无需关注底层的物理设施和维护工作。
IaaS模型中,用户可以通过云平台提供的管理控制台或者API,轻松创建、配置和管理虚拟机、存储卷和网络。用户可以根据自身需求进行扩展或缩减虚拟资源的使用量,灵活性非常高。
IaaS模型的典型应用场景包括:灵活的服务器扩展和缩减、测试与开发环境、容灾备份、批处理计算等。
下面是一个使用Python代码示例,用于创建一个虚拟机实例:
```python
import boto3
# 创建EC2实例
def create_ec2_instance():
ec2 = boto3.resource('ec2')
# 定义实例的配置信息
instance_config = {
'ImageId': 'ami-12345678', # 镜像ID
'InstanceType': 't2.micro', # 实例类型
'KeyName': 'my_keypair', # 密钥对名称
'MinCount': 1,
'MaxCount': 1
}
# 创建EC2实例
response = ec2.create_instances(**instance_config)
# 获取创建的实例ID
instance_id = response[0].id
return instance_id
# 执行创建虚拟机实例的函数
instance_id = create_ec2_instance()
print(f"成功创建虚拟机实例,实例ID为:{instance_id}")
```
代码解析:
- 首先,我们通过Python的boto3库来操作云平台上的云资源。该库提供了丰富的API调用接口,方便我们与云平台进行交互。
- 然后,定义了一个创建EC2实例的函数create_ec2_instance(),函数中包含了实例的配置信息,比如镜像ID、实例类型、密钥对名称等。
- 接着,调用ec2.create_instances()方法创建EC2实例,并将配置信息传递给该方法。
- 最后,获取到创建的实例ID,并打印在控制台上。
运行以上代码,即可成功创建一个虚拟机实例,并返回实例的ID。
#### 4.2 平台即服务(PaaS)
平台即服务(Platform as a Service,PaaS)是一种云服务模型,在IaaS的基础上提供更高级别的服务。PaaS模型可以让开发者将精力集中在应用程序的开发上,而不需要关注底层的基础设施和运维工作。
在PaaS模型中,云服务提供商会提供应用程序所需的运行环境、开发框架和相关工具,开发者只需要使用这些平台提供的服务来开发、测试和部署应用程序。PaaS模型可以大大简化应用程序的开发和部署过程,并提供高度可扩展的运行环境。
PaaS模型的典型应用场景包括:Web应用程序开发、移动应用程序开发、大数据处理等。
下面是一个使用Java代码示例,使用Google Cloud Platform的App Engine服务部署一个简单的Web应用程序:
```java
import com.google.appengine.api.users.UserService;
import com.google.appengine.api.users.UserServiceFactory;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
public class HelloWorldServlet extends HttpServlet {
@Override
public void doGet(HttpServletRequest req, HttpServletResponse resp) throws IOException {
resp.setContentType("text/plain");
resp.getWriter().println("Hello, World");
UserService userService = UserServiceFactory.getUserService();
if (userService.isUserLoggedIn()) {
resp.getWriter().println("Welcome, " + userService.getCurrentUser().getNickname());
} else {
resp.getWriter().println("Please log in");
}
}
}
```
代码解析:
- 这是一个基于Java的简单的Web应用程序,使用Google App Engine提供的服务。
- 在doGet()方法中,我们设置HTTP响应的内容类型为"text/plain",并返回"Hello, World"的字符串。然后,通过UserService接口来检查用户是否已经登录,如果已登录,则返回"Welcome, 用户昵称",否则返回"Please log in"。
以上代码示例是一个简单的Web应用程序的示范,使用PaaS模型部署的Web应用程序可以扩展和自动化处理请求,开发者只需要关注业务逻辑的实现即可。
总结:
- IaaS模型提供基础设施的租用,用户可以通过模板或API自助创建配置虚拟资源。
- PaaS模型提供平台和工具来简化应用程序的开发和部署,开发者只需要关注业务逻辑的实现。
- 使用云服务模型可以大大简化管理和使用云计算平台的复杂性,并提供高度可扩展的环境。
# 5. 云计算的关键组件之二——虚拟化技术
虚拟化技术是云计算架构中的重要组成部分,它可以将物理资源(如服务器、存储设备)虚拟化为多个逻辑资源,并有效地利用这些资源。虚拟化技术可以提高资源利用率、灵活性和可扩展性,为云计算提供了基础。
### 5.1 虚拟机技术
虚拟机技术是一种通过软件模拟硬件的方法,将一台物理计算机分隔成多个虚拟计算机(虚拟机)。每个虚拟机都具有独立的操作系统和应用程序,可以独立地运行和管理。虚拟机技术可以提供隔离性、灵活性和可移植性,使得多个虚拟机可以在同一物理计算机上共享资源。
使用虚拟机技术,可以在云平台上创建和管理大量的虚拟机实例,根据实际需求动态调整虚拟机的数量和规模。例如,可以根据用户的请求,自动创建和销毁虚拟机实例,以适应不同的负载情况。
虚拟机技术常用的实现方式有两种:全虚拟化和半虚拟化。全虚拟化技术可以模拟完整的硬件环境,虚拟机内的操作系统不需要做任何修改即可运行。半虚拟化技术需要对虚拟机内的操作系统进行修改,以便与物理计算机上的虚拟化层进行通信。
下面是一个使用Python语言实现虚拟机管理的代码示例:
```python
import libvirt
# 连接到本地的虚拟化管理器
conn = libvirt.open()
# 创建虚拟机
def create_vm(name, memory, vcpus, image):
# 从模板克隆虚拟机
base_vm = conn.lookupByName('template')
clone_vm = base_vm.clone(name, flags=libvirt.VIR_CLONE_RECONNECT)
# 设置虚拟机的内存和CPU
clone_vm.setMemory(memory)
clone_vm.setVcpus(vcpus)
# 安装操作系统镜像
clone_vm.create()
# 关闭连接
conn.close()
# 销毁虚拟机
def destroy_vm(name):
vm = conn.lookupByName(name)
vm.destroy()
# 调用函数创建和销毁虚拟机
create_vm('vm1', 1024, 1, 'image1.qcow2')
destroy_vm('vm1')
```
以上代码使用`libvirt`库连接到本地的虚拟化管理器,可以通过调用相应的函数来创建和销毁虚拟机。其中,`create_vm`函数根据提供的参数创建一个虚拟机实例,并安装指定的操作系统镜像;`destroy_vm`函数可以根据虚拟机的名称销毁对应的虚拟机实例。
### 5.2 容器化技术
容器化技术是一种将应用程序及其所有依赖项打包成一个独立的容器的方法。容器可以在任何支持容器化技术的计算环境中运行,无需考虑底层的操作系统和硬件差异。容器化技术可以提供轻量级、快速部署和可移植的应用运行环境,适用于云计算领域。
容器化技术的核心是容器引擎,它负责创建和管理容器。目前最流行的容器引擎是Docker。Docker提供了一个简单而强大的命令行工具,可以通过镜像构建和管理容器。每个容器都是独立的,具有独立的文件系统、网络和进程空间。
使用Docker,可以在云平台上快速部署和扩展应用程序。通过使用Docker镜像,可以保证应用程序在不同环境中的一致性,并提供容器的隔离性和安全性。
下面是一个使用Docker命令行工具创建和运行容器的示例:
```bash
# 从Docker Hub下载镜像
docker pull nginx
# 创建并运行一个名为web的容器,将本地的8080端口映射到容器的80端口
docker run -d -p 8080:80 --name web nginx
# 停止并删除容器
docker stop web
docker rm web
```
以上命令通过`docker pull`从Docker Hub下载一个Nginx镜像,然后使用`docker run`创建一个名为web的容器,并将本地的8080端口映射到容器的80端口。最后,使用`docker stop`和`docker rm`命令停止并删除容器。
### 5.3 轻量级虚拟化技术
除了传统的虚拟机和容器化技术外,还有一种轻量级的虚拟化技术,即操作系统级虚拟化。操作系统级虚拟化通过在主机操作系统中创建多个隔离的用户空间实例(称为容器或虚拟环境)来实现虚拟化。每个容器都可以运行一个独立的应用程序,并且与其他容器隔离。
操作系统级虚拟化具有轻量级、高性能和资源利用率高等特点。常见的操作系统级虚拟化技术包括Linux的LXC(Linux Containers)和FreeBSD的Jails。
以下是一个使用LXC创建和运行容器的示例:
```bash
# 安装LXC
sudo apt-get install lxc
# 创建一个名为container的容器
sudo lxc-create -t ubuntu -n container
# 启动容器
sudo lxc-start -n container
# 进入容器
sudo lxc-attach -n container
# 在容器中安装应用程序
sudo apt-get install nginx
```
以上命令通过使用`lxc-create`创建一个名为container的LXC容器,并使用`lxc-start`启动容器。然后,使用`lxc-attach`进入容器,并在容器中安装Nginx应用程序。
总结:
虚拟化技术在云计算中起着至关重要的作用。虚拟机技术可以实现对物理计算机的虚拟化,提供资源隔离和灵活性。容器化技术可以将应用程序及其依赖项打包成独立的容器,实现快速部署和可移植性。操作系统级虚拟化则提供了一种轻量级的虚拟化解决方案,具有高性能和资源利用率的优势。在实际应用中,可以根据需求选择适合的虚拟化技术来构建云计算平台。
# 6. 云计算的关键组件之三——自动化管理与编排
在云计算环境中,自动化管理和编排是至关重要的组件,它们能够提高资源利用率、降低运维成本,并支持复杂的应用部署和管理。本章将深入探讨云计算中的自动化管理与编排技术,包括其重要性、技术实践和相关框架的应用。
#### 6.1 自动化管理的重要性
自动化管理在云计算中具有重要意义,它能够有效地解决以下问题:
- **资源利用率优化:** 自动化管理能够根据实际需求动态调整资源分配,提高资源利用率,降低成本。
- **快速部署与扩展:** 通过自动化管理,可以实现快速部署和扩展应用,缩短上线时间,提高灵活性。
- **故障处理与恢复:** 自动化管理可以实时监控系统状态,及时发现并处理故障,提高系统的稳定性和可靠性。
- **安全与合规性:** 自动化管理能够统一规范资源配置、更新和安全策略,确保系统满足合规性要求。
#### 6.2 云计算中的自动化管理技术
在云计算环境中,常用的自动化管理技术包括:
- **配置管理:** 使用工具如Ansible、Chef、Puppet等,实现对系统配置的自动化管理和统一化。
- **监控与告警:** 利用监控工具如Zabbix、Nagios、Prometheus等,实现对系统各项指标的实时监控和异常告警。
- **自动化运维:** 借助DevOps理念和工具,实现软件开发、测试、交付和运维的自动化流程。
#### 6.3 编排工具和框架的应用
在云计算环境中,为了更好地管理和调度应用容器、虚拟机等资源,常常会使用到编排工具和框架,例如:
- **Docker Swarm:** 用于Docker容器的编排和管理,实现跨主机的容器集群部署。
- **Kubernetes:** Google开源的容器编排引擎,支持自动化部署、扩展和管理容器化应用。
- **Apache Mesos:** 开源的集群管理系统,支持多种应用框架的调度与管理,包括Docker、Hadoop等。
通过以上自动化管理技术和编排工具的应用,可以更有效地构建和管理复杂的云计算环境,实现业务的高效部署和运行。
以上是自动化管理与编排在云计算中的重要性、技术实践和相关框架的应用的介绍,希望对您有所帮助。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《云计算技术及实例解析基础与应用》是一个以云计算为主题的专栏,通过多篇文章对云计算的不同方面进行深入解析。专栏涵盖了云计算的基础知识与应用案例,包括云计算的三种部署模式及其特点、公有云与私有云的选择、云计算架构及关键组件的解析、虚拟化技术在云计算中的作用和原理、云计算中的容器技术与虚拟化的比较等。此外,还探讨了云计算中的安全、容灾、自动化运维等关键问题,并介绍了云平台的应用场景和大数据、人工智能等技术在云计算中的实践。通过阅读本专栏,读者可以全面了解云计算的基础概念及其实际应用,掌握云计算技术的核心原理和关键技术,以及在实践中遇到的各种挑战和解决方案。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
EMMC5.0 vs SSD:性能对比分析与最佳选择指南

# 摘要
本文介绍了嵌入式多媒体卡(EMMC)与固态驱动器(SSD)的技术细节,包括它们的工作原理、架构以及性能特点。通过比较EMMC5.0与SSD的读写速度、耐久度、可靠性和成本效益,本文分析了两种存储技术在不同应用场景中的表现,如消费电子和企业级应用。基
【GRADE软件数据校验】:专家分享确保结果准确性的5大绝招

# 摘要
GRADE软件的数据校验对于保证数据质量与准确性至关重要。本文首先强调了GRADE软件数据校验的重要性,并详细解析了其校验机制,包括数据完整性的基础理论、校验的目的和必要性,以及校验功能的概览和校验算法的选择。接下来,文章探讨了GRADE软件数据校验的实践技巧,涵盖配置和优化校验参数、解决校验过程中的常见问题,以及校验自动化与集成。此外,高级应用
PN532 NFC标签读写技术全攻略:快速上手指南
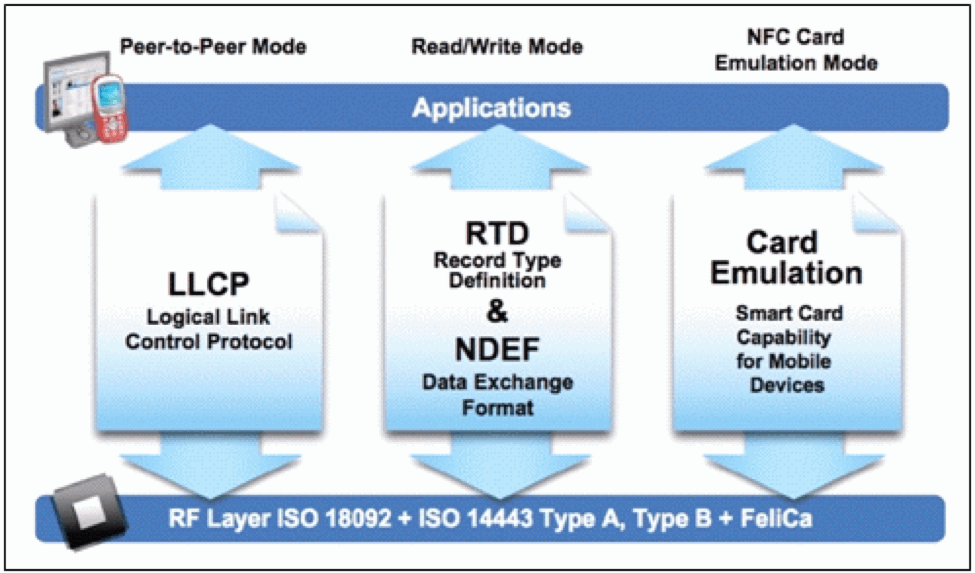
# 摘要
本文全面介绍了PN532 NFC标签读写技术,包括其基础理论、开发实践以及高级应用与技巧。首先概述了NFC技术的基本原理和PN532模块的技术特点,随后深入探讨了NFC标签读写的理论限制,如读写距离、功率要求、数据传输速率和安全性考量。在开发实践部分,本文详细说明了PN532模块与常见开发板的硬件连接、软件编程,以及在门禁控制系统和智能家居中的应用案例。此外,本文还探讨了NFC标签数据
Adblock Plus过滤规则深度剖析:提升网络安全的必备技巧

# 摘要
Adblock Plus作为一款流行的浏览器扩展程序,其强大的过滤规则功能是其核心特性之一。本文首先概述了Adblock Plus过滤规则的基本概念和语法,随后
WinPcap数据包过滤器深度解析:精确控制网络数据流

# 摘要
WinPcap作为网络数据包捕获库,广泛应用于网络分析和安全领域。本文介绍了WinPcap的基础知识,探讨了数据包过滤技术的理论基础及其过滤表达式语法,分析了过滤器的类型和配置策略。通过对WinPcap过滤器的深入配置和优化,以及探讨其在网络安全、网络性能分析和自定义协议分析中的应用,展
【整合JWT与OAuth2.0】:发挥两种协议的最大优势

# 摘要
本文对身份验证与授权领域的关键技术进行了全面探讨。首先介绍了JWT(JSON Web Tokens)的原理、结构及其在身份验证中的工作机制和安全性考量。随后,详细解析了OAuth2.0的授权流程、角色与令牌类型,并探讨了其在不同应用场景中的实际应用。进一步,文章深入探讨了JWT与OAuth2.0整合的动机、优势、实施方法以及实际案例。最后,针对整
【QCA Wi-Fi安全机制剖析】:源代码级别的数据加密与验证深入解析
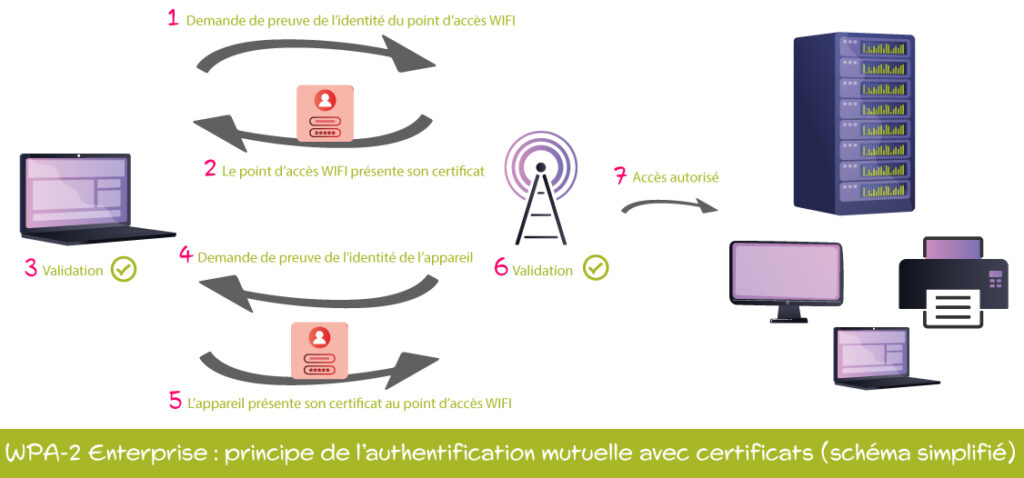
# 摘要
本文综述了QCA Wi-Fi安全机制的关键组成部分,包括数据加密、用户验证、授权协议以及网络安全监控技术。文中详细探讨了各种加密算法(如WEP, WPA, WPA2, WPA3)和密钥管理策略的工作原理及其在QCA平台上的实现。此外,分析了用户验证和授权协议(如EAP认证方法、MAC地址过滤、802.1X)如何保障Wi-Fi网络的安全性,
PNOZ继电器与其他安全设备的集成指南

# 摘要
本文对PNOZ继电器进行了全面的概述,详细介绍了其基础应用、与其他安全设备的集成实践以及高级应用。文章首先探讨了PNOZ继电器的原理、功能、安装和接线方法,进而分析了与传感器、PLC和HMI的集成方式。接着,本文深入讨论了PNOZ继电器在故障诊断处理、安全配置管理中的应用,以及在工业自动化和汽车制造等领域的实际案例。最后,文章展望了PN
Altium函数自定义指南:根据项目需求定制个性化功能

# 摘要
本文旨在全面介绍Altium函数自定义的技术细节及其应用。首先概述了Altium函数自定义的重要性及其理论基础,包括函数的概念及其与项目需求的关系。接着详细探讨了设计原则,强调了代码的可读性、性能优化和安全性。实践中,本文提供了自定义步骤和高级技巧,涵盖了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )