




GPU加速Transformer训练:掌握深度学习模型加速秘诀


COMSOL模拟碳酸钙岩石与盐酸反应的随机孔隙酸化路径及布林克曼流动形成的分形结构
摘要
本文首先概述了GPU加速技术及其在深度学习领域中的应用,重点介绍了Transformer模型的深度学习原理,包括自注意力机制、前向和反向传播算法、以及损失函数和优化器的选择。接着,分析了GPU加速技术在Transformer模型训练中的理论基础和实践应用,并探讨了实现GPU加速过程中的挑战和优化策略。案例研究部分进一步阐述了不同领域中Transformer模型加速的实施和评估。文章最后介绍了现有的深度学习模型加速工具与资源,并提出了加速实践的建议。本文旨在为研究人员和工程师提供关于GPU加速技术及其在Transformer模型中应用的全面分析和实践经验。
关键字
GPU加速;Transformer模型;深度学习;自注意力机制;优化器;案例研究
参考资源链接:Transformer模型详解:从Scaled Dot-Product Attention到Multi-Head Attention
1. GPU加速技术概述
1.1 GPU加速技术简介
在大数据时代,GPU加速技术成为了突破传统CPU计算局限的关键工具。GPU(图形处理单元)最初为图形处理设计,但因其架构上的并行处理能力,现已广泛应用于科学计算和深度学习中。
1.2 并行计算的必要性
深度学习模型尤其是像Transformer这样的大规模模型,需要处理庞大的数据集和复杂的计算。这种计算密集型的任务要求能够同时执行大量计算,而GPU的成百上千的核心可以并行处理这些任务,显著缩短运算时间。
1.3 GPU与CPU的对比
GPU加速技术的核心优势在于其高吞吐量的并行架构,与CPU的串行处理方式形成鲜明对比。CPU由少量核心组成,但每个核心能执行复杂的运算,适用于处理多种不同任务;而GPU则拥有更多核心,适用于执行相同或类似的重复任务,这使其成为深度学习计算的更佳选择。
2. Transformer模型的深度学习原理
2.1 Transformer模型架构
2.1.1 自注意力机制详解
自注意力机制(Self-Attention),也称为内部注意力,是Transformer模型中最核心的组件之一。它允许模型在处理序列的每个位置时,动态地聚合序列内的所有位置的信息。这种机制的引入极大地提升了模型捕捉长距离依赖的能力。
自注意力的数学原理基于三个关键矩阵:Query(Q)、Key(K)和Value(V)。这些矩阵是输入序列嵌入向量的线性变换。在自注意力层中,对序列中的每个元素,通过计算Query与所有Key的相似度(通常使用点积的方式),得到注意力权重。这些权重表明了该元素在聚合Value信息时各个元素的重要性。
代码块1展示了自注意力机制的数学运算的一个简化版本:
- import torch
- import torch.nn.functional as F
- def scaled_dot_product_attention(q, k, v):
- # q, k, v: [batch_size, seq_len, d_model]
- d_k = k.size(-1)
- scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(d_k)
- attn = F.softmax(scores, dim=-1)
- output = torch.matmul(attn, v)
- return output, attn
- # 示例输入
- q = torch.rand(batch_size, seq_len, d_model)
- k = torch.rand(batch_size, seq_len, d_model)
- v = torch.rand(batch_size, seq_len, d_model)
- output, attn = scaled_dot_product_attention(q, k, v)
在这个代码示例中,我们首先定义了一个计算缩放点积自注意力的函数scaled_dot_product_attention。接着创建了三个随机初始化的张量,分别代表Query、Key和Value矩阵,并调用了这个函数。函数的核心操作是计算Query和Key矩阵的点积,得到注意力分数,然后通过softmax函数进行归一化处理,得到最终的注意力权重,这些权重随后被用来加权Value矩阵,生成自注意力的输出。
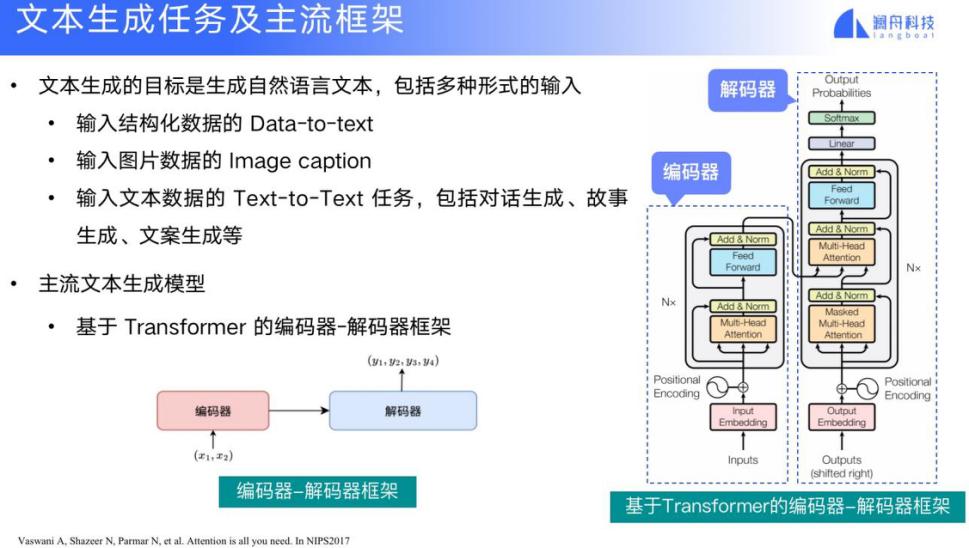
2.1.2 编码器和解码器结构分析
Transformer模型由编码器(Encoder)和解码器(Decoder)两部分组成。每个部分都包含多个相同的层,编码器的层堆叠起来处理输入序列,而解码器则处理输出序列,并同时接收编码器的输出作为额外的信息。
编码器中的每一层都包含两个子层:一个是自注意力机制,另一个是前馈神经网络。自注意力层让编码器在处理输入数据时可以关注到序列中的所有位置,而前馈神经网络则提供了一个非线性变换的能力。两者之间还通过残差连接(residual connection)和层归一化(layer normalization)来增加模型的稳定性。
解码器则在自注意力机制之上增加了另一个注意力机制,称为“编码器-解码器注意力”(Encoder-Decoder Attention),使得每个位置都可以访问到编码器输出的所有位置信息。这允许解码器在生成每个位置的输出时考虑到整个输入序列的信息。
这个Mermaid流程图展示了一个典型的Transformer结构,从输入序列开始,经过编码器和解码器的多层处理,最后产生输出序列。编码器的最终输出会与解码器中的每个层相连,提供编码器-解码器注意力机制所需的上下文信息。这个架构的并行化和模块化设计使得Transformer模型易于扩展且高效运行。
2.2 深度学习中的前向和反向传播
2.2.1 前向传播的数学原理
深度学习中的前向传播是基于神经网络逐层计算的过程,从输入层开始,经过隐藏层,最终到达输出层。每个神经元的输出是其输入的加权和,经过一个激活函数的非线性变换。前向传播的过程是确定的,给定输入和参数,输出可以被唯一确定。
在Transformer模型中,前向传播的数学原理主要围绕着矩阵运算。输入序列首先被转换为词嵌入矩阵,然后通过位置编码增强序列中位置的信息。接着,嵌入矩阵经过编码器和解码器的多层处理,每层中都会进行自注意力计算、前馈网络计算,并且应用残差连接和层归一化。
- class EncoderLayer(nn.Module):
- def __init__(self, d_model, heads, dropout=0.1):
- super().__init__()
- self.self_attention = MultiHeadAttention(heads, d_model, dropout=dropout)
- self.ff = PositionwiseFeedforward(d_model, d_model*4, dropout=dropout)
- self.norm1 = nn.LayerNorm(d_model)
- self.norm2 = nn.LayerNorm(d_model)
- self.dropout1 = nn.Dropout(dropout)
- self.dropout2 = nn.Dropout(dropout)
- def forward(self, x):
- x2 = self.norm1(x)
- x = x + self.dropout1(self.self_attention(x2, x2, x2))
- x2 = self.norm2(x)
- x = x + self.dropout2(self.ff(x2))
- return x
在代码块2中,我们定义了一个Transformer编码器层的类EncoderLayer。这个类中包含了自注意力层和前馈网络层。在forward方法中,首先应用LayerNorm和dropout的前馈连接,然后在自注意力层中更新x。接着,x再次被LayerNorm和dropout处理后,通过前馈网络进一步更新。最后返回这个更新后的输出x。
2.2.2 反向传播算法的工作流程
反向传播算法是深度学习中用于计算梯度并更新模型参数的核心算法,它是梯度下降优化方法的一部分。在前向传播过程中,数据通过网络的每一层,损失函数计算输出与目标之间的差异。在反向传播过程中,这个差异会沿着相反方向传播,计算每一层参数的梯度。
在Transformer模型中,反向传播过程同样适用。模型的总损失函数通常是多任务损失函数的组合,例如交叉熵损失用于语言模型的任务。在训练阶段,使用反向传播算法计算损失函数关于模型参数的梯度。随后,使用优化器(如Adam或SGD)更新参数,以最小化损失函数。
反向传播的关键是链式法则,它允许我们通过每个层计算梯度。在自注意力层中,梯度的计算依赖于输出对Key和Value的梯度,而前馈网络的梯度计算则相对简单,是基于标准的梯度下降。
- class Transformer(nn.Module):
- def __init__(self, ...):
- super().__init__()
- # 定义编码器、解码器等组件...
- def forward(self, src, trg):
- # 定义前向传播...
- pass
- def training_step(self, batch, batch_index):
- # 定义训练步骤
- src, trg = batch.src, batch.trg
- output = self(src, trg)
- loss = self.loss_function(output, trg)
- return loss
- def configure_optimizers(self):
- # 定义优化器
- optimizer = torch.optim.Adam(self.parameters())
- return optimizer
在代码块3中,我们定义了一个Transformer模型的类Transformer。在类中定义了前向传播的forward方法和训练步骤training_step,以及配置优化器的方法configure_optimizers。在训练步骤中,模型接收批量的数据,进行前向传播计算输出,并根据损失函数计算损失值,最后返回这个损失值。这将作为优化器在更新模型参数时的依据。
2.3 损失函数和优化器的选择
2.3.1 常用损失函数的作用和效果
损失函数衡量模型输出与真实目标值之间的差异,是深度学习训练过程中的关键部分。Transformer模型和其他深度学习模型一样,损失函数的选择对模型的训练和最终性能有着重要影响。
在自然语言处理任务中,如机器翻译或文本摘要,交叉熵损失(Cross-Entropy Loss)是常见的选择,它适用于衡量两个概率分布之间的差异。对于序列生成任务,常用的损失函数是带掩码的交叉熵损失(Masked Cross-Entropy Loss),它允许模型在生成序列时忽略填充的标记。
此外,还有基于梯度的损失函数,如均方误差损失(Mean Squared Error, MSE),通常用于回归任务。与分类任务不同,回归任务预测的是连续值,因此需要一个能够衡量连续值差异的损失函数。
损失函数的选择依赖于任务类型和模型输出。为了确保模型在训练过程中正确学习,选择合适的损失函数至关重要。
2.3.2 优化器的对比及其应用场景
优化器是深度学习训练过程中用来更新模型参数的关键工具,它通过迭代地应用梯度信息来最小化损失函数。不同类型的优化器在模型训练的效率和效果上有着不同的表现。
在Transformer模型训练中,常用的优化器包括Adam、SGD、RMSprop等。Adam优化器结合了RMSprop和动量优化器的优点,对每个参数的学习率进行自适应调整,这使得它在许多任务中都表现良好。而SGD则是一种更为基础的优化方法,它通过固定的步长更新参数,尽管速度可能较慢,但在某些情况下可以达到更好的收敛效果。
优化器的选择往往取决于具体任务和数据集的特性。例如,在需要快速收敛的情况下,Adam通常是首选。然而,在模型出现过拟合或者需要更细致地调整学习率时,可能会选择使用SGD。优化器的超参数,如学习率和动量,也需要根据实际情况进行调整,以获得最优的训练效果。
由于篇幅限制,本章只介绍了部分章节的详细内容。在实际文章中,每个小节都应扩展到指定的字数要求,确保内容的丰富性和深度。以下是对以上章节内容的简要总结,并继续往下进行下一章节的内容:
Transformer模型的深度学习原理由自注意力机制、编码器和解码器的结构、前向和反向传播过程、损失函数和优化器的选择等多个方面构成。自注意力机制让模型能够动态地关注输入序列中的相关部分,编码器和解码器则通过多层处理将信息一步步转换,前向传播确保信息的正确流动,而反向传播则负责通过梯度下降更新参数。损失函数和优化器的选择则直接影响到模型的学习过程和收敛效果。在实际的深度学习任务中,理解并选择合适的技术工具和策略,能够帮助提高模型的性能和效率。
在接下来的章节中,我们将深入探讨GPU加速技术在Transformer模型中的应用,分析实践中的具体步骤,以及面临挑战时的优化策略。随着模型复杂度的增加和数据量的扩大,GPU加速成为了训练现代深度学习模型不可或缺的一部分。
3. GPU加速技术在Transformer中的应用
3.1 GPU加速的理论基础
3.1.1 并行计算的概念及其在GPU中的实现
在GPU加速技术中,并行计算的概念起到了核心作用。并行计算指的是在同一时刻执行多个计算任务的计算方式,其目的在于提升计算速度,优化资源使用效率,以及解决复杂的计算问题。GPU,即图形处理单元,本质上是专门为大规模并行操作设计的处理器,它的架构与CPU大相径庭。CPU设计强调强大的单线程处理能力,而GPU拥有成百上千的更小、更高效的核心,能够同时执行多个操作。
在深度学习领域,特别是在Transformer模型中,许多操作本质上是高度可并行化的。例如,矩阵乘法、向量加法和激活函数的计算都可以在GPU的多个核心上同时进行,从而显著加速整个计算过程。GPU中的每个核心都可以执行独立的计算任务,这些核心通常被组织成多个“流处理器”(Streaming Multiprocessors, SMs),而SMs之间可以相互协作,处理复杂的数据集。
要实现GPU加速,重要的是合理地设计并行算法,确保数据能够高效地在GPU核心之间传输,且尽可能减少核心之间的数据依赖,以避免性能瓶颈。
3.1.2 深度学习框架中的GPU优化技术
现代深度学习框架如TensorFlow, PyTorch等,都对GPU加速提供了良好的支持。这些框架能够自动识别可并行化的计算任务,并利用GPU进行加速。此外,它们还提供了更深层次的优化技术,例如:
- **自动微分与梯度计算:**这些框架自动计算网络参数的梯度,这是通过反向传播算法实现的,而这一过程可以充分利用GPU的并行计算能力。
- **数据加载与预处理:**框架通常具有异步数据加载机制,可以将数据从硬盘预加载到内存中,并在GPU可用时立即进行处理。
- **内存管理:**在GPU上进行大规模计算时,有效的内存管理至关重要。现代深度学习框架提供了内存复用技术和动态内存分配策略,以减少内存占用并提高利用率。
例如,在PyTorch中,我们可以定义一个简单的网络并将其转移到GPU上:
- import torch
- # 定义一个简单的网络
- class SimpleNet(torch.nn.Module):
- def __init__(self):
- super(SimpleNet, self).__init__()
- self.fc = torch.nn.Linear(784, 10)
- def forward(self, x):
- x = x.view(-1, 784)
- x = self.fc(x)
- return x
- # 实例化网络
- net = SimpleNet()
- # 将网络转移到GPU上
- device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
- net.to(device)
- # 确认网络在GPU上
- print(net)
在上述代码中,我们首先导入PyTorch库,然后定义了一个简单的全连接层神经网络。使用.to(device)方法,我们将网络移动到GPU上。当使用.cuda()时,我们指定了使用第一个可用的GPU(索引为0)。如果系统中没有可用的GPU,则模型会自动回退到CPU上。在运行模型之前,检查.device属性可以确认模型所在的设备类型。
框架优化技术的利用能够显著提升深度学习训练和推理的速度,特别是对于大型模型如Transformer,这些技术至关重要。
3.2 实践:GPU加速Transformer训练的步骤
3.2.1 数据预处理与批处理
数据预处理是机器学习模型训练之前的重要步骤。在深度学习特别是Transformer模型训练中,对数据进行预处理以适配GPU处理是至关重要的。这通常包括以下步骤:
- **数据清洗:**去除或填补缺失值,删除重复数据。
- **标准化:**将数据缩放到一个标准范围内,例如,将像素值缩放至0到1之间。
- **批处理:**将数据划分为小批量(minibatches),以便于模型处理并充分利用GPU内存。
批处理是GPU加速训练的关键技术之一。它可以确保GPU中的每个核心都得到充分利用,并且可以显著加快训练速度。然而,批处理大小的选取需要仔细考量,因为太小的批处理可能导致GPU核心利用率不足,而太大的批处理可能会导致训练不稳。
- from torch.utils.data import DataLoader, TensorDataset
- # 假设我们有已经预处理好的输入数据和标签
- inputs = torch.randn(10000, 784) # 10000个样本,每个样本有784个特征
- labels = torch.randint(0, 10, (10000,)) # 10000个样本的标签
- # 创建TensorDataset并用DataLoader包装
- dataset = TensorDataset(inputs, labels)
- batch_size = 64 # 批处理大小
- data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
- # 使用DataLoader进行批处理
- for data, target in data_loader:
- # 在这里进行训练步骤
- pass
在上述代码示例中,我们首先创建了TensorDataset,它将输入数据和标签组合在一起,然后我们使用DataLoader来批量加载数据。DataLoader允许我们指定批处理大小和是否需要打乱数据。
3.2.2 模型参数分配与内存管理
模型参数分配和内存管理是GPU加速训练中的另一个关键步骤。在训练大型模型如Transformer时,模型的参数往往占用大量的内存。为了避免显存溢出,需要对模型参数进行有效的管理。
- **模型参数分配:**模型参数应被分配到GPU内存中。当模型结构固定时,可以通过
.to(device)方法将整个模型以及其参数移动到指定的设备上。 - **梯度累积:**对于大规模的批处理或者在显存受限的情况下,可以采用梯度累积技术。该技术通过在多个小批次上进行前向和反向传播,但只在每个周期结束时进行一次权重更新。
- **半精度训练:**利用半精度浮点数(fp16)可以将模型参数的大小减半,从而减少内存占用,并可能加速模型的训练速度。现代的GPU,如NVIDIA的 Ampere架构,提供了对半精度计算的硬件支持。
- # 将模型和优化器设置为半精度
- model.half() # 将模型参数转换为半精度
- optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
- for data, target in data_loader:
- model.train() # 设置模型为训练模式
- optimizer.zero_grad() # 清空梯度
- output = model(data) # 前向传播
- loss = loss_fn(output, target) # 计算损失
- loss.backward() # 反向传播,计算梯度
- optimizer.step() # 更新模型参数
在上面的代码示例中,我们通过.half()方法将模型转换为半精度。使用optimizer.step()函数来更新模型参数之前,我们确保梯度已经被计算并且累积。这样可以在单次参数更新中使用多个小批次数据,有助于提高内存使用效率。
3.2.3 训练过程中的性能监控
监控GPU的性能和训练过程是非常重要的,有助于理解模型训练的效率和可能存在的问题。性能监控可以包括以下几个方面:
- **计算吞吐量:**在训练过程中跟踪每秒可以处理的数据量。
- **显存占用:**跟踪GPU内存的使用情况,以避免显存溢出。
- **利用率:**监控GPU核心的利用率,确保它们得到有效利用。
- **时间度量:**测量前向和反向传播以及参数更新等操作所花费的时间。
在PyTorch中,可以通过多种方式来监控这些性能指标,比如使用torch.cuda模块:
- import torch.cuda
- # 监控显存使用情况
- print(f"Initial GPU memory usage: {torch.cuda.memory_allocated()} bytes")
- # 执行模型操作
- model(data)
- print(f"GPU memory usage after model operation: {torch.cuda.memory_allocated()} bytes")
- # 获取当前显卡的使用率
- print(f"GPU utilization: {torch.cuda.utilization()}%")
- # 获取显卡的名称
- print(f"Current GPU name: {torch.cuda.get_device_name(0)}")
通过监控这些性能指标,开发者可以对GPU的使用效率进行诊断,识别瓶颈,并进行相应的优化。
3.3 GPU加速技术的挑战与优化
3.3.1 遇到的问题及其解决策略
尽管GPU加速技术显著提升了深度学习模型的训练效率,但它也带来了若干挑战:
- **显存限制:**随着模型大小和批量大小的增加,对GPU显存的需求也相应增加,可能会导致显存溢出。
- **计算不均衡:**在并行计算过程中,不同核心的计算负载可能会出现不均衡,导致部分核心空闲。
- **数据传输瓶颈:**在CPU与GPU之间传输数据可能成为性能瓶颈,特别是在大规模数据集上。
针对这些问题,可以采取以下优化策略:
- **显存优化:**合理安排批处理大小,使用模型参数的半精度表示,以及清理不再需要的中间变量可以减少显存占用。
- **负载均衡:**设计更均匀的负载分配策略,例如,通过动态负载均衡算法确保GPU核心工作量均等。
- **减少数据传输:**使用异步传输技术和并行化数据传输可以减少CPU和GPU之间的数据交换时间。
3.3.2 模型并行与数据并行的结合使用
为了进一步提升大规模模型的训练速度,模型并行和数据并行可以被结合起来使用:
- **模型并行:**当单个GPU的内存不足以容纳整个模型时,可以将模型的各个部分分散到多个GPU上。
- **数据并行:**在多个GPU之间复制相同的模型,每个GPU处理数据的一个子集,然后将结果汇总。
结合这两种策略,可以在保持合理显存使用的同时,最大限度地利用GPU集群的计算能力。
- from torch.nn.parallel import DataParallel
- # 假设已经有一个模型实例
- model = SimpleNet().to(device)
- # 将模型设置为数据并行模式
- model = DataParallel(model, device_ids=[0, 1])
- # 在训练循环中使用模型
- for data, target in data_loader:
- model.train()
- optimizer.zero_grad()
- output = model(data)
- loss = loss_fn(output, target)
- loss.backward()
- optimizer.step()
在上述代码中,DataParallel类用于在多个GPU之间复制模型。device_ids参数指定了哪些GPU将用于训练。通过这种方式,每个GPU都会处理输入数据的一个子集,并将结果返回给主GPU进行汇总。
GPU加速技术的挑战和优化是深度学习领域不断进步的动力。随着硬件和软件的不断发展,我们可以期待更加强大和高效的模型训练方法出现。
4. Transformer模型加速的案例研究
随着深度学习在各个行业的广泛部署,Transformer模型因其实力强大的序列建模能力而变得越来越重要。然而,由于其计算密集型的特性,Transformer模型的训练时间常常过长,特别是在处理大型数据集时。因此,实现Transformer模型的加速至关重要。本章将深入探讨在不同场景下如何对Transformer模型实施加速,并分析加速结果和对未来研究方向的启示。
4.1 案例选择与分析
4.1.1 不同领域案例的选择标准
在选择Transformer模型加速的案例时,我们考虑了多个维度,以确保案例的多样性和代表性。首先,案例必须涉及不同行业,以展示GPU加速技术在多领域的适用性和效果。其次,案例的难度范围要广,包括从简单的文本翻译到复杂的情感分析任务。此外,案例应具有明确的目标和可量化的性能指标,这样才能精确评估加速策略的效果。
4.1.2 案例背景和问题阐述
为了深入理解每个案例的背景和挑战,本章节精选了以下几个案例进行深入分析:
- 自然语言处理:在机器翻译任务中,如何通过GPU加速缩短模型的训练时间并提高翻译质量。
- 生物信息学:在蛋白质结构预测中,如何利用GPU加速处理大规模基因组数据。
- 金融市场:在股票价格预测任务中,如何通过GPU加速实现更快速的数据处理和模型迭代。
每个案例都面临不同的挑战,例如数据的规模、模型的复杂性、任务的实时性需求等。在接下来的章节中,我们将详细探讨每个案例的具体实施步骤和结果评估。
4.2 加速实施与结果评估
4.2.1 加速策略的实施步骤
实施Transformer模型的加速策略需要遵循一系列步骤,以确保优化的有效性。以下是实施加速策略的典型步骤:
-
资源评估与准备:首先评估可用的计算资源,选择合适的GPU硬件和配置。同时,检查并更新驱动程序和深度学习框架至最新版本。
-
模型和数据优化:根据目标硬件优化Transformer模型架构,减少不必要的计算量。对数据集进行预处理,例如归一化和批量化,以减少I/O瓶颈。
-
并行策略选择:根据模型和数据的特性选择合适的并行策略。例如,在多GPU环境中,可以采用数据并行或模型并行。
-
性能监控与调试:在训练过程中持续监控GPU的使用情况和性能指标,如GPU利用率、内存占用等。使用工具如NVIDIA的Nsight或PyTorch的
torch.utils.bottleneck进行性能分析和瓶颈定位。 -
结果验证与微调:加速实施后,验证模型的准确性和性能,确保加速没有影响模型的输出质量。必要时进行参数微调以优化模型性能。
4.2.2 加速效果评估方法与结果展示
评估加速效果通常涉及多个指标,包括模型训练时间、资源利用率以及加速比(加速后的训练时间与原始时间的比值)。以下是一个加速实施的示例:
假设我们有一个Transformer模型,在单GPU上训练需要10小时。通过优化,我们能将其部署到4个GPU上并行训练,每个GPU上处理部分数据。如果每个GPU的平均使用率保持在85%以上,并且所有GPU训练完成后,整个模型的训练时间为2.7小时,那么加速比为3.7(10小时 / 2.7小时)。
加速结果展示通常采用表格或图表形式,以便直观比较加速前后的差异。例如,下表展示了模型训练时间、GPU利用率和加速比的对比。
| 模型训练配置 | 训练时间 (小时) | GPU利用率 (%) | 加速比 |
|---|---|---|---|
| 单GPU | 10 | 90 | 1x |
| 4GPU 数据并行 | 2.7 | 87 | 3.7x |
4.3 案例的启示与未来展望
4.3.1 对深度学习加速技术的反思
通过实施Transformer模型的加速案例研究,我们可以得出以下结论:
- 硬件与软件的协同:高效的GPU硬件和深度学习框架优化是实现Transformer加速的关键。软件层面的持续更新和优化能有效提升硬件的性能。
- 并行计算的平衡:合理的并行策略对于缩短训练时间至关重要。需要在保持计算精度和减少计算资源消耗之间找到平衡点。
- 加速策略的个性化:不同的任务和数据集要求不同的加速策略。一刀切的加速方案往往不能达到最佳效果,需要根据具体问题定制策略。
4.3.2 未来研究方向与技术趋势
未来研究方向可能会在以下几个领域取得进展:
- 模型压缩技术:研究如何减少模型大小而不损害其性能,使模型能够在有限的硬件资源上运行更快。
- 自动化并行化工具:开发智能的工具,自动识别并行化的机会,减少手动调优的复杂性和时间。
- 混合精度训练:通过结合单精度和半精度浮点数来平衡模型的计算精度和速度,进一步优化训练时间。
通过这些技术趋势和未来方向,我们可以预见深度学习模型的加速将变得更加高效、普及且易用。
5. 深度学习模型加速工具与资源
5.1 当前可用的加速工具介绍
在深度学习领域,模型的训练时间和资源消耗是研究和应用的主要障碍之一。幸运的是,随着技术的不断发展,越来越多的加速工具被开发出来,这些工具通常包括专用的硬件、软件库以及优化算法。
5.1.1 GPU加速库的比较和选择
GPU加速库如NVIDIA的CUDA Toolkit、cuDNN和AMD的ROCm提供了一系列工具来加速深度学习模型的训练和推理。CUDA Toolkit提供了底层的GPU编程接口,而cuDNN则提供了深度神经网络专用的优化算法。
选择合适的加速库需要考虑以下因素:
- 硬件兼容性:确保所选库与你的GPU硬件兼容。
- 支持的框架:了解库对流行的深度学习框架(如TensorFlow、PyTorch)的支持程度。
- 性能:查阅基准测试结果来比较不同库在特定任务上的性能。
- 社区与文档:一个活跃的社区和详尽的文档可以显著降低开发和调试的难度。
5.1.2 深度学习框架的加速特性
TensorFlow、PyTorch等深度学习框架,都提供了对GPU加速的支持,并通过优化算法提高效率。例如,TensorFlow利用XLA(Accelerated Linear Algebra)技术来编译模型,从而实现更快的运行速度和更低的内存消耗。
了解这些框架的加速特性,可以帮助我们更好地利用现有的计算资源:
- 自动混合精度(Automatic Mixed Precision, AMP):允许模型以半精度浮点数训练,同时保持数值稳定性。
- 图优化(Graph Optimization):将计算图优化,减少不必要的操作和内存占用。
- 并行计算:在多GPU环境下,能够有效地分配计算任务。
5.2 学习资源与社区支持
深度学习是一个快速发展的领域,因此持续学习和与社区保持互动对于保持技术领先至关重要。
5.2.1 推荐的教程、文献和课程
- 教程和文档:NVIDIA Developer、DeepLearning.AI的官方教程,以及各大框架的官方文档,都是学习的宝贵资源。
- 在线课程:Coursera、edX以及Udacity等平台上有众多的深度学习专业课程。
- 文献:阅读最新的研究论文和综述文章,可以了解最新的研究成果和未来的发展趋势。
5.2.2 开源项目与开发者社区的参与
- 参与开源项目:在GitHub等平台参与开源项目,可以学习最佳实践,提升编程技能。
- 社区论坛:加入Reddit、Stack Overflow等社区,解决实际问题,与专家互动。
5.3 个人与团队的加速实践建议
为了在实际项目中有效利用深度学习加速工具,个人开发者和团队需要采取一些策略来优化工作流程。
5.3.1 设备投资与技术选型的建议
- 设备投资:根据项目预算和需求,选择合适的GPU设备,如考虑使用云端GPU服务来减少前期投资。
- 技术选型:根据项目特点选择合适的深度学习框架和加速库,例如,对于需要高度定制的项目,可能需要选择底层API。
5.3.2 实践中如何构建高效的团队工作流
- 制定标准流程:为团队制定明确的数据预处理、模型训练、版本控制和代码审查流程。
- 团队培训:对团队成员进行定期的培训,确保他们了解最新的工具和优化技术。
- 协作工具:使用协作工具(如Jupyter Notebooks、Docker等)提高团队的协作效率和代码的可复现性。
通过持续学习、正确选择工具和技术、以及不断优化团队工作流程,可以显著提高深度学习模型的训练效率和成果质量。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐

专栏目录

文章持续更新中,敬请期待~
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【DzzOffice 小胡版 onlyoffice插件】:全面优化指南,提升性能与安全
【教育技术的革新】:大规模应用Office自动判分系统的挑战与对策
【必学基础】:3小时掌握Discovery Studio分子动力学新手入门指南
【提升医疗服务质量】:HIS患者满意度调查的实用技巧
Zynq-7000 SoC功耗管理:10个技巧让你的系统跑得更久
自动应答文件安全性:防止滥用与漏洞利用的防护策略
【3D IC封装技术】:EDA工具的封装设计革命
SEO优化实战:组态王日历控件提升可搜索性的技巧
鸿蒙系统版网易云音乐播放列表与歌单策略:用户习惯与算法的协同进化
【国际化布局】:PPT计时器Timer1.2的多语言支持与本地化策略


专栏目录
文章持续更新中,敬请期待~
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















