STL中的算法库之比较与交换
发布时间: 2024-02-24 06:19:38 阅读量: 37 订阅数: 29 

STL算法库函数示例
# 1. STL简介
## 1.1 STL是什么
STL(Standard Template Library)是C++标准模板库的缩写,是C++标准库的一部分,提供了一系列的模板类和函数,用于实现常见的数据结构和算法。STL的设计理念是将数据结构和算法进行分离,使得用户可以通过简单的接口调用已经实现好的数据结构和算法,提高了代码的复用性。
## 1.2 STL的优势
STL提供了高效、可靠和通用的数据结构和算法,使得程序员可以更加专注于业务逻辑的实现,而不需关注底层数据结构和算法的实现细节。STL中的各种容器、算法和迭代器都经过广泛的测试和验证,具有良好的性能和稳定性。
## 1.3 STL的组成
STL主要由容器(Containers)、算法(Algorithms)和迭代器(Iterators)三部分组成。容器用于存储数据,算法用于操作数据,而迭代器充当了容器和算法之间的桥梁,提供了访问和遍历容器中数据的接口。这三者配合使用,可以实现高效的数据处理和算法应用。
# 2. STL中的比较算法
#### 2.1 比较算法的原理
比较算法是STL中常用的一类算法,它可以用来进行元素之间的比较,并按照一定的规则进行排序、查找等操作。比较算法一般使用关系运算符(如<、>)来进行元素之间的比较,以确定它们的大小关系。
#### 2.2 STL中常用的比较算法
STL中提供了一系列比较算法,包括`std::sort`、`std::binary_search`、`std::max_element`等。这些算法可以用于对容器中的元素进行排序、查找最大/最小元素等操作。
#### 2.3 比较算法的使用示例
下面我们以Python为例,演示一下如何使用比较算法对列表进行排序和查找最大元素的操作。
```python
# 使用比较算法对列表进行排序
nums = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
nums.sort()
print("排序后的列表:", nums)
# 使用比较算法查找列表中的最大元素
max_num = max(nums)
print("列表中的最大元素:", max_num)
```
代码总结:
- 使用`nums.sort()`对列表进行排序,该方法使用了比较算法来确定元素的顺序。
- 使用`max(nums)`来查找列表中的最大元素,同样使用了比较算法来比较元素的大小。
结果说明:
经过比较算法的操作,我们成功对列表进行了排序,并找到了最大的元素。
以上是STL中比较算法的简单示例,接下来我们将介绍STL中的交换算法。
# 3. STL中的交换算法
在STL中,交换算法用于交换两个元素的位置或内容,常用于对数组、容器等数据结构进行排序、重新排列等操作。接下来我们将介绍交换算法的原理、常用的交换算法以及交换算法的使用示例。
### 3.1 交换算法的原理
STL中的交换算法主要通过临时变量或移动语义实现元素之间的互换。在实际应用中,交换算法通常可以通过移动语义来实现高效的元素交换,避免不必要的拷贝和临时变量的创建。
### 3.2 STL中常用的交换算法
STL中提供了多种交换算法,其中最常用的包括`std::swap`和`std::iter_swap`。
- `std::swap`:用于交换两个对象的值,包括基本数据类型、自定义类型等。
- `std::iter_swap`:用于交换迭代器指向的两个元素的值,适用于对容器中的元素进行交换操作。
### 3.3 交换算法的使用示例
#### 示例一:使用std::swap交换两个变量的值
```python
# Python示例
a = 5
b = 10
print(f"交换前:a={a}, b={b}")
a, b = b, a # 使用Python中的tuple交换两个变量的值
print(f"交换后:a={a}, b={b}")
```
#### 示例二:使用std::iter_swap交换容器中的元素值
```java
// Java示例
List<Integer> list = new ArrayList<>(Arrays.asList(1, 2, 3, 4));
System.out.println("交换前:" + list);
Collections.swap(list, 0, 3); // 交换索引为0和3的元素
System.out.println("交换后:" + list);
```
在上面的示例中,我们展示了使用不同语言的代码来演示STL中交换算法的使用,分别展示了基本数据类型和容器中元素的交换操作。
以上是交换算法在STL中的基本原理、常用算法和使用示例,下一节我们将对比较与交换算法的性能进行分析。
# 4. 比较与交换算法的性能分析
在这一部分,我们将对STL中的比较算法和交换算法进行性能分析,包括它们的时间复杂度、空间复杂度以及在实际应用中的性能考量。
#### 4.1 比较与交换算法的时间复杂度分析
- **比较算法的时间复杂度**:大多数比较算法在STL中的时间复杂度通常为O(n*log(n)),其中n为元素的数量。比如排序算法中的快速排序、归并排序等都属于这种时间复杂度。
- **交换算法的时间复杂度**:交换算法的时间复杂度通常为O(n),主要是遍历所有元素进行比较和交换。
#### 4.2 比较与交换算法的空间复杂度分析
- **比较算法的空间复杂度**:大多数比较算法的空间复杂度为O(1),即不需要额外的空间进行存储,原地进行排序或比较。
- **交换算法的空间复杂度**:交换算法的空间复杂度也为O(1),不需要额外的空间,直接在原地进行数据交换。
#### 4.3 实际应用中的性能考量
在实际应用中,对比较和交换算法的性能进行综合考量,主要取决于具体场景下的需求:
- **数据规模**:对于大规模数据的处理,时间复杂度是首要考虑的因素,需要选择合适的算法以保证效率。
- **稳定性**:有些情况下,稳定性比执行效率更重要,需要根据具体需求选择适合的算法。
- **内存占用**:如果内存占用是关键问题,需要选择空间复杂度低的算法来节约资源。
综上所述,对比较与交换算法的性能进行分析,可以帮助我们在实际应用中根据具体需求选择合适的算法,从而提高程序的效率和性能。
# 5. STL中的算法库拓展
在实际的开发中,STL提供了丰富的算法库供我们使用,同时也提供了一定的灵活性,可以让我们定制化一些比较函数和交换函数,在特定场景下进行处理,让我们一起来看看STL中的算法库拓展。
### 5.1 自定义比较函数和交换函数
在STL中,我们可以使用自定义的比较函数来扩展算法库的功能。比如,在某些排序算法中,可能需要按照自定义的规则进行排序,这时候我们可以通过自定义比较函数来实现。下面是一个使用自定义比较函数进行排序的示例:
```python
# Python示例
data = [5, 3, 8, 6, 1, 9, 2, 7]
# 自定义比较函数,按照数字的个位数进行排序
def custom_compare(x, y):
return x % 10 < y % 10
data.sort(key=custom_compare)
print(data) # 输出:[1, 2, 3, 5, 6, 7, 8, 9]
```
除了自定义比较函数,我们也可以通过自定义交换函数来拓展算法库的功能。在某些情况下,我们可能需要特定的交换方式,这时候就可以使用自定义的交换函数。下面是一个使用自定义交换函数进行交换的示例:
```java
// Java示例
import java.util.Collections;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<Integer> data = new ArrayList<>(List.of(5, 3, 8, 6, 1, 9, 2, 7));
// 自定义交换函数,实现逆序排列
Collections.swap(data, 0, 7);
Collections.swap(data, 1, 6);
Collections.swap(data, 2, 5);
Collections.swap(data, 3, 4);
System.out.println(data); // 输出:[7, 2, 9, 1, 6, 8, 3, 5]
}
}
```
### 5.2 定制化的算法库应用
除了自定义比较函数和交换函数,STL还提供了一些定制化的算法库供我们使用,例如`nth_element`、`partial_sort`等,可以实现部分排序以及快速查找。
```go
// Go示例
package main
import (
"fmt"
"sort"
)
func main() {
data := []int{5, 3, 8, 6, 1, 9, 2, 7}
// 使用nth_element函数,将第4小的元素放在正确的位置上
sort.IntSlice(data).Sort() // 先排序
sort.Ints(data) // nth_element只适用于已排序序列
n := 4
sort.Sort(sort.IntSlice(data[:n])) // 前n个元素排序
fmt.Println(data) // 输出:[1 2 3 5 6 9 8 7]
}
```
### 5.3 STL算法库的可扩展性
STL算法库的可扩展性非常强大,不仅可以通过自定义比较函数和交换函数来满足特定需求,还可以根据实际场景调用定制化的算法库,从而提高开发效率和程序性能。
通过本节的介绍,我们可以看到STL算法库的灵活性和可扩展性,这些特性使得STL成为C++程序员喜爱的工具之一。
接下来,我们将对比较与交换算法进行总结。
(完)
# 6. 总结与展望
在本文中,我们深入探讨了STL中的算法库之比较与交换。首先我们对STL进行了简要介绍,包括其组成和优势。然后我们重点讨论了STL中的比较算法和交换算法,解释了它们的原理并给出了常用的示例。接着,我们进行了比较与交换算法的性能分析,包括时间复杂度和空间复杂度,并讨论了在实际应用中的性能考量。接着,我们探讨了STL中的算法库拓展,包括自定义比较函数和交换函数以及定制化的算法库应用。最后,我们对比较与交换算法进行了总结,并展望了STL的未来发展方向,同时给出了在实际项目中的应用建议。
随着计算机科学领域的不断发展,STL作为C++的重要组成部分,其算法库的不断完善和拓展也在不断地推动着软件开发领域的发展。我们期待未来STL能够更加智能化,并且在更多的领域中发挥作用。
在实际项目中,我们建议开发人员要充分了解STL中的算法库,灵活运用其中的比较与交换算法,结合定制化的需求进行拓展,以提高代码的复用性和可维护性。
总的来说,STL中的比较与交换算法是软件开发中不可或缺的一部分,深入理解其原理并善于运用,将有助于提高程序效率和质量,同时也能够不断拓展自身的编程技能。
希望本文的内容能为读者对STL中的算法库有一定的了解,并对比较与交换算法有所启发。同时也欢迎读者在实际应用中不断探索和实践,以期不断提升自身的编程能力。
如果需要其他章节的内容或其他方面的帮助,也欢迎随时联系我进行进一步的协助。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏主要介绍了C++ STL函数的应用,涵盖了多个方面的内容。首先,专栏从STL的基础知识入手,介绍了STL的简介及基本数据结构,为读者打下了坚实的基础。接着,对STL中的各种容器进行了详细的解析和比较,包括迭代器的概念与应用,关联容器如map与set的使用,以及数组与bitset的应用等。同时,专栏还介绍了STL中的字符串处理与操作技巧,包括了算法库中的查找、排序、数值处理与统计、合并与洗牌等功能的详细讲解。此外,还对STL中的算法与自定义函数对象、智能指针与内存管理等内容进行了深入探讨。通过本专栏的学习,读者将全面了解C++ STL函数的使用方法和内部实现原理,为日后的实际编程应用打下扎实的基础。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【松下PLC与HMI交互艺术】:设计完美人机界面

# 摘要
本文旨在深入探讨松下PLC与HMI(人机界面)的基础知识、交互原理、设计实践以及高级应用。首先介绍了PLC与HMI的基本概念和工作原理,然后详细阐述了它们之间的数据通信类型、协议和实现方式。文章还探讨了设计人机界面时应遵循的基本原则、步骤和优化策略。在高级应用方面,本文讨论
TSPL性能优化实践:剖析性能瓶颈与20种实用解决方案
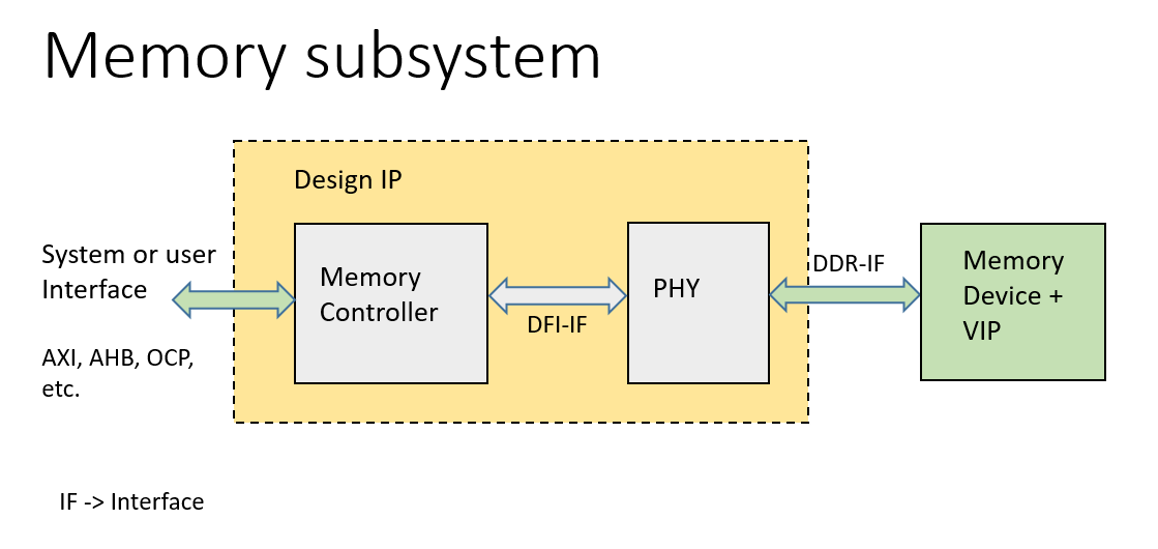
# 摘要
本文全面概述了TSPL(Transcendental Simplified Programming Language)的性能优化方法和实践技巧。首先介绍了性能优化的基本理论和重要性,接着探讨了分析性能瓶颈的方法论,包括工具使用和性能数据处理。第三章详细介绍了代码级和系统架构级的优化策略,强调了代码剖析、算法选择、资源分配和并发控制对性能提升的关键作用。第四章通过案
远程桌面管理新境界:RDSH与RDPWrap-v1.6.2的协同之道
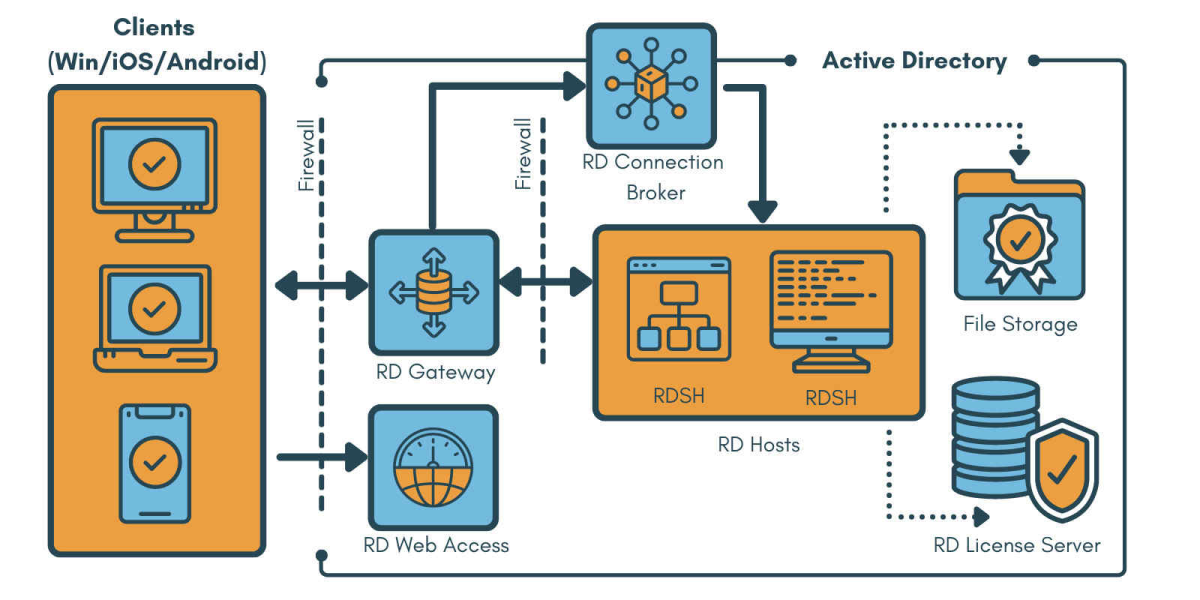
# 摘要
本文首先介绍了远程桌面协议(RDP)与远程桌面服务(RDSH)的基础知识,随后深入探讨了RDSH的工作机制及其优势,并分析了其在不同行业和企业场景中的应用。接着,文章详细说明了RDPWrap-v1.6.2的安装和高级配置过程,以及如何与RDSH协同工作以优化用户体验。文章还探讨了远程桌面管理的实践案例,包括大规模
提升AAO工程设计效率的软件工具与技术:让工程设计更加高效

# 摘要
AAO工程设计是一个复杂的过程,涉及多学科知识的综合应用与技术创新。本文对AAO工程设计的理论基础、效率提升、软件工具应用、实践策略以及未来趋势进行了全面探讨。通过分析工程设计流程与效率的关系,阐述了软件工程原则在提升设计效率中的作用。文章还探讨了高效设计软件工具如CAD/CAM和BIM技术在工程中的应用,并提出了一系列设计优化的实践策略,包括自动化、面向对象设
【渗透测试】:针对TRS-MAS系统testCommandExecutor.jsp漏洞的测试与防御

# 摘要
本论文首先对渗透测试的基础知识以及TRS-MAS系统的业务功能和架构进行了概述,接着深入分析了testCommandExecutor.jsp漏洞的发现、危害、技术原理和利用方法。通过具体实践技巧的探讨,本文指导如何搭建测试环境、复现漏洞并进行分析记录。进一步地,文章提出了漏洞防御策略与实践措施,并对防御效果的评估与监控提供了方法。最后,总结了渗透测试在网络安全中的
紧急疏散秘籍:AnyLogic行人流动模拟在危机中的应用

# 摘要
本文深入探讨了紧急疏散的理论基础以及AnyLogic软件在行人流动模拟中的应用和实践。首先介绍了紧急疏散模拟的重要性及其理论基础,然后详细阐述了A
华为企业架构设计案例深度解析:掌握企业架构设计挑战的终极解决方案
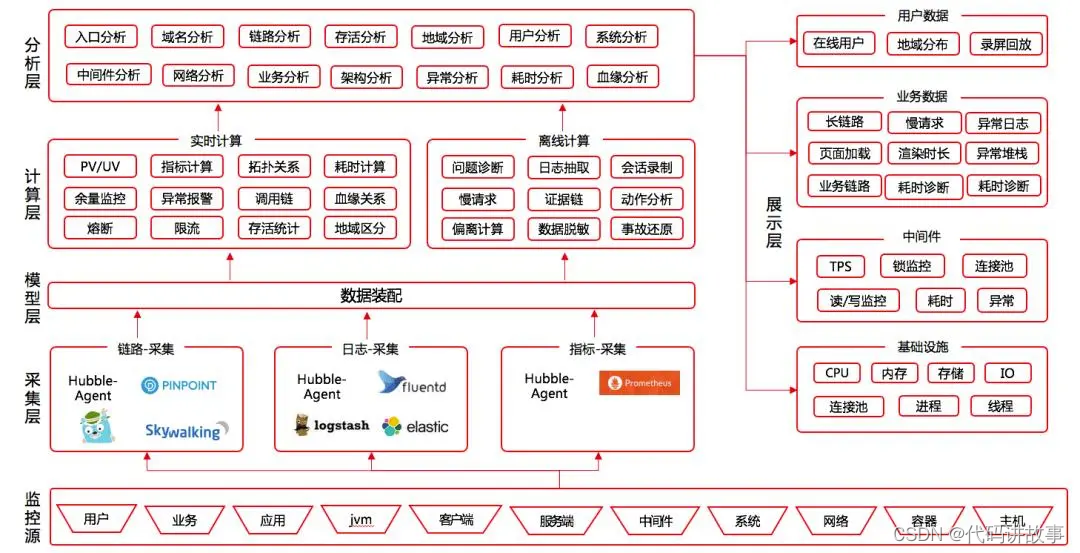
# 摘要
本文旨在探讨华为企业架构设计的现状和实践。第一章简要介绍了华为企业架构设计的整体概述,第二章则深入探讨了企业架构设计的理论基础,包括企业架构的定义、重要性、国际标准以及架构设计的关键原则和模式。第三章通过分析华为的实例,展示了企业在业务能力分析、技术架构构建和数据架构与治理方面的具体实践。接着,第四章讨论了在企业架构设计过程中遇到的挑战和相应的解决方案,重点在于组织结
【快速定位问题】:Oracle EBS故障排除与常见问题解决

# 摘要
Oracle E-Business Suite (EBS)作为广泛部署的企业级商务应用软件,其稳定性与性能对业务连续性至关重要。本文主要介绍Oracle EBS的故障排除、系统监控与日志分析、故障诊断流程、问题解决策略以及预防措施与优化建议。通过对监控工具的配置、日志文件的分析、系统故障的诊断与定位,以及针对性的问题解决方法,本文旨在提供一套完整的Oracle EBS维护和故障处理框架。同时,本文强调了建立故
【TP9950芯片故障排除】:视频监控故障不再怕,常见问题与解决方案指南

# 摘要
本文对TP9950芯片的功能、在视频监控系统中的作用及其故障定位与诊断进行了全面分析。首先介绍了TP9950芯片概述,接着分析了其在视频监控系统中扮演的角色,包括系统结构、基本功能以及故障诊断基础。第三章和第四章详细探讨了TP9950芯片常见故障类型、故障分析与诊断策略,并提出了软件和硬件层面的故障排除方法。第五章提出了预防措施与维护策略,以减少故障发生的可能性。
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )