C#高级查询必备:LINQ to SQL复杂数据处理技巧全解析
发布时间: 2024-10-19 23:33:15 阅读量: 31 订阅数: 34 

C#讲座-讲座10:LINQ简介,LINQ to 0bjects第1部分
# 1. LINQ to SQL概述和核心概念
LINQ to SQL 是一个面向对象的中间层,用于访问 SQL Server 数据库。它支持开发者使用 .NET 语言的特性和优势,实现数据的查询、更新、删除和插入操作。本章将介绍 LINQ to SQL 的基础概念,并探讨其在 .NET 应用中的作用。
## LINQ to SQL 的起源和设计目的
LINQ to SQL 诞生于 2007 年,旨在简化数据库访问逻辑,提高开发效率和代码可维护性。其核心目标是将数据库中的数据映射为 .NET 世界中的对象,从而实现强类型的查询能力,让开发者可以使用熟悉的 .NET 语言特性来编写数据库逻辑。
## LINQ to SQL 的核心组件
LINQ to SQL 由几个关键组件构成,包括 `DataContext` 类、实体类(Entity classes)、映射(Mappings)和查询表达式(Query expressions):
- **DataContext 类** 是 LINQ to SQL 的核心,负责管理与数据库的连接和通信。开发者可以通过 `DataContext` 对象访问数据库,并执行各种数据操作。
- **实体类** 代表数据库中的表,每个实体类的实例对应表中的一行数据。这些实体类通常由 LINQ to SQL 的设计器自动生成,也可以手动定义。
- **映射** 定义了实体类与数据库表之间的关系。通过映射,开发者可以控制数据如何从数据库传输到 .NET 对象,反之亦然。
- **查询表达式** 允许开发者使用 C# 或其他 .NET 语言编写强类型、声明式的查询代码。LINQ to SQL 将这些查询表达式转换成相应的 SQL 语句,并在数据库上执行。
## LINQ to SQL 的优势与应用场景
使用 LINQ to SQL 的优势包括:
- **类型安全**:查询和操作都是针对强类型对象进行,减少了运行时错误。
- **代码简化**:开发者可以用更少的代码完成复杂的数据库操作。
- **集成开发环境(IDE)支持**:Visual Studio 的集成支持使得 LINQ to SQL 的设计和查询编写更加直观。
LINQ to SQL 适用于中到大型的应用程序,特别是那些需要紧密集成数据库操作和业务逻辑的场景。尽管在.NET生态系统中已出现了更多的数据访问技术(如Entity Framework),LINQ to SQL 仍因其简单和高效而被许多开发者所青睐。
```csharp
// 示例:使用 LINQ to SQL 查询数据库中的数据
using (var context = new NorthwindDataContext())
{
var query = from customer in context.Customers
where customer.City == "London"
select customer;
foreach(var customer in query)
{
Console.WriteLine($"{***panyName} is located in {customer.City}");
}
}
```
以上代码展示了如何使用 LINQ to SQL 查询伦敦的客户,并输出公司名和城市。这个例子说明了 LINQ to SQL 如何让查询变得简单和直观。在接下来的章节中,我们将深入探讨如何编写更复杂的查询,如何与数据库进行高级交互,以及如何优化 LINQ to SQL 的性能等主题。
# 2. LINQ to SQL基础查询技巧
## 2.1 LINQ to SQL的数据源连接和查询基础
### 2.1.1 连接数据库和建立数据源
连接数据库是使用LINQ to SQL进行数据操作的第一步。在.NET中,我们使用System.Data.Linq命名空间下的DataContext类来实现这一过程。DataContext类是LINQ to SQL的核心,它负责表示与数据库的连接和会话,并作为查询的入口点。
要连接数据库,首先需要配置数据库连接字符串,并使用它来实例化一个DataContext对象。下面是一个连接SQL Server数据库的示例代码:
```csharp
using System;
using System.Data.Linq;
class Program
{
static void Main()
{
// 数据库连接字符串
string connectionString = @"Data Source=.\SQLEXPRESS;AttachDbFilename=C:\path\to\yourdatabase.mdf;Integrated Security=True;Connect Timeout=30;User Instance=True";
// 使用连接字符串创建DataContext对象
DataContext db = new DataContext(connectionString);
// 这里可以进行数据库操作,例如查询、插入、更新、删除等
}
}
```
在上述代码中,`DataContext`对象`db`代表了一个特定的数据库会话。它使用`connectionString`参数来定义连接属性,例如数据源位置、数据库文件路径、身份验证方式和连接超时时间。创建`DataContext`对象之后,您就可以通过该对象访问数据库中的表和其他对象了。
### 2.1.2 编写基础查询和数据投影
一旦建立了数据库连接,接下来就可以编写LINQ to SQL查询了。基础查询通常涉及到从数据库表中选择、过滤、排序和分组数据。
假设有一个名为`Customer`的表,我们想查询名字为"John Doe"的客户信息,可以使用以下LINQ查询:
```csharp
var customerQuery = from customer in db.Customers
where customer.Name == "John Doe"
select customer;
```
在这个查询中,`Customers`是通过`DataContext`对象`db`访问的表。这个查询遍历`Customers`表中的每一行,检查`Name`字段是否等于"John Doe",如果是,则将该行包含在查询结果集中。
**数据投影**是指从数据源中选择出需要的列的过程,而不返回完整的数据行。在LINQ to SQL中,数据投影可以使用`select`语句来实现:
```csharp
var customerDetailsQuery = from customer in db.Customers
where customer.Name == "John Doe"
select new { customer.Name, customer.Email };
```
在这个例子中,我们没有选择整个`Customer`对象,而是创建了一个匿名类型(使用`new { ... }`),其中只包含`Name`和`Email`两个字段。这样,返回的查询结果将只包含这两个字段的数据。
### 2.2 LINQ to SQL的高级查询功能
#### 2.2.1 使用Where子句进行数据筛选
数据筛选是使用LINQ to SQL进行数据操作时非常常见的一种需求。`Where`子句是实现数据筛选的重要工具,它允许我们在查询中添加筛选条件,以便只获取满足特定条件的数据行。
下面是一个带有`Where`子句的查询示例,它将返回所有名字中包含字母"e"的客户信息:
```csharp
var customersWithEQuery = from customer in db.Customers
where customer.Name.Contains("e")
select customer;
```
在这个查询中,`Where`子句中的`Contains("e")`方法用来检查`Name`字段是否包含字母"e"。只有满足条件的客户数据才会被包含在最终的结果集中。
#### 2.2.2 使用OrderBy和GroupBy进行数据排序和分组
当我们需要对查询结果进行排序或分组时,可以使用`OrderBy`和`GroupBy`子句。排序是根据某个特定的属性将数据重新组织,分组则是根据某个属性的值将数据组织成几个独立的组。
假设我们需要按照`Customer`表中的`BirthDate`字段对客户数据进行升序排序,可以使用以下代码:
```csharp
var sortedCustomersQuery = from customer in db.Customers
orderby customer.BirthDate
select customer;
```
而`GroupBy`子句可以按照某个特定的字段将数据进行分组。例如,按照`Country`字段对客户数据进行分组:
```csharp
var groupedCustomersQuery = from customer in db.Customers
group customer by customer.Country into grouped
select grouped;
```
在这个例子中,`group by`语句将`Customers`表中的客户数据按照`Country`字段进行了分组。每个分组可以单独处理或遍历,使得数据的组织和处理更加灵活高效。
## 2.3 LINQ to SQL的数据聚合和联接操作
### 2.3.1 聚合函数和数据集的聚合
聚合函数如`Count`, `Sum`, `Average`, `Min`, `Max`等是查询数据集并得到单一值的常用方法。在LINQ to SQL中,可以使用这些函数对数据集合进行聚合操作。
例如,如果我们想知道`Customers`表中有多少客户,可以使用`Count()`方法:
```csharp
var totalCustomers = db.Customers.Count();
```
对于有特定条件的数据集进行聚合,可以在`Count()`方法中嵌入`Where`子句:
```csharp
var customersInUSA = (from customer in db.Customers
where customer.Country == "USA"
select customer).Count();
```
### 2.3.2 内联接、左外联接和右外联接的使用技巧
数据库表之间的关系通常是通过键值关联的。在LINQ to SQL中,可以使用内联接(Inner Join)、左外联接(Left Outer Join)、和右外联接(Right Outer Join)来联合来自不同数据源的数据。
内联接是最常用的联接类型,它返回两个表中匹配的行:
```csharp
var innerJoinQuery = from customer in db.Customers
join order in db.Orders
on customer.ID equals order.CustomerID
select new { customer.Name, order.OrderID };
```
左外联接会返回左表(`Customers`)的所有行,即使右表(`Orders`)中没有匹配的行也会返回,不匹配的行中的右表字段将为null:
```csharp
var leftOuterJoinQuery = from customer in db.Customers
join order in db.Orders
on customer.ID equals order.CustomerID into customerOrders
from co in customerOrders.DefaultIfEmpty()
select new { CustomerName = customer.Name, OrderID = (co != null ? (int?)co.OrderID : null) };
```
右外联接与左外联接类似,只不过这次返回的是右表(`Orders`)的所有行:
```csharp
var rightOuterJoinQuery = from customer in db.Customers
join order in db.Orders
on customer.ID equals order.CustomerID into customerOrders
from co in customerOrders.DefaultIfEmpty()
select new { CustomerName = (co != null
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
该专栏深入探讨了 C# 中的 LINQ to SQL,为 C# 开发者提供了 20 个高效技巧和策略。它涵盖了从选择最佳 ORM 工具到查询性能优化、复杂数据处理、并发问题解决方案、数据检索、大数据处理、异常处理、查询功能增强、多层架构数据访问和数据库负载减轻等各个方面。通过深入浅出的讲解和丰富的示例,该专栏旨在帮助开发者充分利用 LINQ to SQL 的强大功能,提高代码效率和应用程序性能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
高效DSP编程揭秘:VisualDSP++代码优化的五大策略

# 摘要
本文全面介绍了VisualDSP++开发环境,包括其简介、基础编程知识、性能优化实践以及高级应用案例分析。首先,文中概述了VisualDSP++的环境搭建、基本语法结构以及调试工具的使用,为开发者提供了一个扎实的编程基础。接着,深入探讨了在代码、算法及系统三个层面的性能优化策略,旨在帮助开发者提升程序的运行效率。通过高级应用和案例分析,本文展示了VisualD
BRIGMANUAL高级应用技巧:10个实战方法,效率倍增

# 摘要
BRIGMANUAL是一种先进的数据处理和管理工具,旨在提供高效的数据流处理与优化,以满足不同环境下的需求。本文首先介绍BRIGMANUAL的基本概念和核心功能,随后深入探讨了其理论基础,包括架构解析、配置优化及安全机制。接着,本文通过实战技巧章节,展示了如何通过该工具优化数据处理和设计自动化工作流。文章还具体分析了BRIGMANUAL在大数据环境、云服务平台以及物联网应用中的实践案例。最后,文
QNX Hypervisor调试进阶:专家级调试技巧与实战分享

# 摘要
QNX Hypervisor作为一种先进的实时操作系统虚拟化技术,对于确保嵌入式系统的安全性和稳定性具有重要意义。本文首先介绍了QNX Hypervisor的基本概念,随后详细探讨了调试工具和环境的搭建,包括内置与第三方调试工具的应用、调试环境的配置及调试日志的分析方法。在故障诊断方面,本文深入分析了内存泄漏、性能瓶颈以及多虚拟机协同调试的策略,并讨论了网络和设备故障的排查技术。此外,文中还介绍了QNX Hypervis
协议层深度解析:高速串行接口数据包格式与传输协议
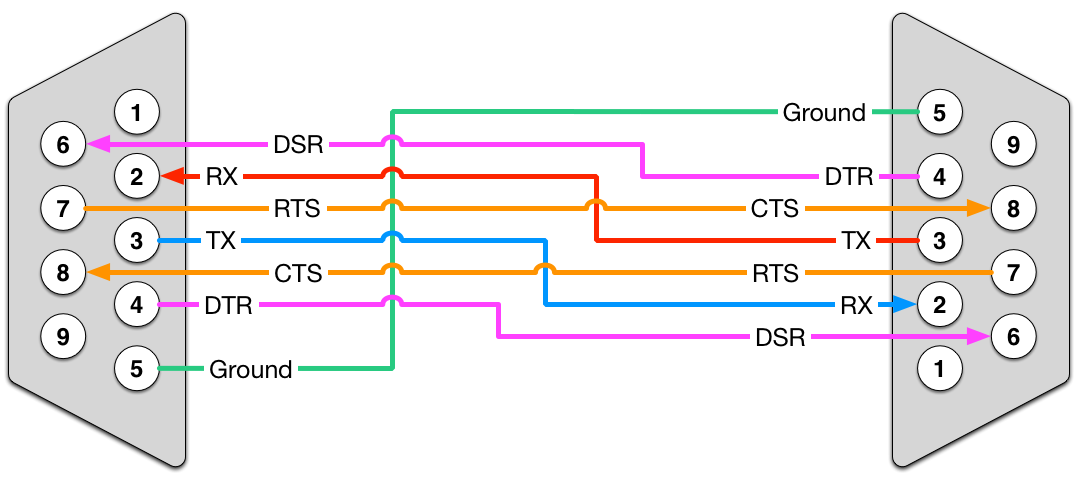
# 摘要
高速串行接口技术是现代数据通信的关键部分,本文对高速串行接口的数据包概念、结构和传输机制进行了系统性的介绍。首先,文中阐述了数据包的基本概念和理论框架,包括数据包格式的构成要素及传输机制,详细分析了数据封装、差错检测、流量控制等方面的内容。接着,通过对比不同高速串行接口标准,如USB 3.0和PCI Express,进一步探讨了数据包格式的实践案例分析,以及数据包的生成和注入技术。第四章深入分析了传输协议的特性、优化策略以及安全
SC-LDPC码性能评估大公开:理论基础与实现步骤详解
# 摘要
低密度奇偶校验(LDPC)码,特别是短周期LDPC(SC-LDPC)码,因其在错误校正能力方面的优势而受到广泛关注。本文对SC-LDPC码的理论基础、性能评估关键指标和优化策略进行了全面综述。首先介绍了信道编码和迭代解码原理,随后探讨了LDPC码的构造方法及其稀疏矩阵特性,以及SC-LDPC码的提出和发展背景。性能评估方面,本文着重分析了误码率(BER)、信噪比(SNR)、吞吐量和复杂度等关键指标,并讨论了它们在SC-LDPC码性能分析中的作用。在实现步骤部分,本文详细阐述了系统模型搭建、仿真实验设计、性能数据收集和数据分析的流程。最后,本文提出了SC-LDPC码的优化策略,并展望了
CU240BE2调试速成课:5分钟掌握必备调试技巧

# 摘要
本文详细介绍了CU240BE2变频器的应用与调试过程。从基础操作开始,包括硬件连接、软件配置,到基本参数设定和初步调试流程,以及进阶调试技巧,例如高级参数调整、故障诊断处理及调试工具应用。文章通过具体案例分析,如电动机无法启动
【Dos与大数据】:应对大数据挑战的磁盘管理与维护策略

# 摘要
随着大数据时代的到来,磁盘管理成为保证数据存储与处理效率的重要议题。本文首先概述了大数据时代磁盘管理的重要性,并从理论基础、实践技巧及应对大数据挑战的策略三个维度进行了系统分析。通过深入探讨磁盘的硬件结构、文件系统、性能评估、备份恢复、分区格式化、监控维护,以及面向大数据的存储解决方案和优化技术,本文提出了适合大数据环境的磁盘管理策略。案例分析部分则具体介绍
【电脑自动关机问题全解析】:故障排除与系统维护的黄金法则

# 摘要
电脑自动关机问题是一个影响用户体验和数据安全的技术难题,本文旨在全面概述其触发机制、可能原因及诊断流程。通过探讨系统命令、硬件设置、操作系统任务等触发机制,以及软件冲突、硬件故障、病毒感染和系统配置错误等可能原因,本文提供了一套系统的诊断流程,包括系统日志分析、硬件测试检查和软件冲突
MK9019故障排除宝典:常见问题的诊断与高效解决方案
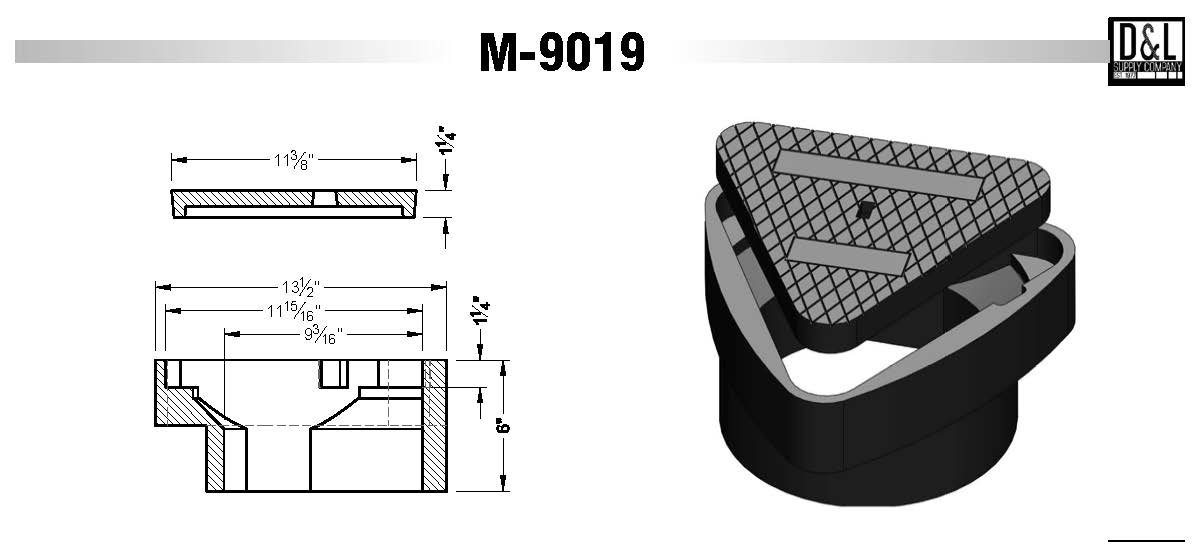
# 摘要
MK9019作为一种复杂设备,在运行过程中可能会遇到各种故障问题,从而影响设备的稳定性和可靠性。本文系统地梳理了MK9019故障排除的方法和步骤,从故障诊断基础到常见故障案例分析,再到高级故障处理技术,最后提供维护与预防性维护指南。重点介绍了设备硬件架构、软件系统运行机制,以及故障现象确认、日志收集和环境评估等准备工作。案例分析部分详细探讨了硬件问题、系统崩溃、性能问题及其解决方案。同时,本文还涉及
LTE-A技术新挑战:切换重选策略的进化与实施

# 摘要
本文首先介绍了LTE-A技术的概况,随后深入探讨了切换重选策略的理论基础、实现技术和优化实践。在切换重选策略的理论基础部分,重点分析了LTE-A中切换重选的定义、与传统LTE的区别以及演进过程,同时指出了切换重选过程中可能遇到的关键问题。实现技术章节讨论了自适应切换、多连接切换以及基于负载均衡的切换策略,包括其原理和应用场景。优化与实践章节则着重于切换重选参数的优化、实时监测与自适应调整机制以及切换重选策略的测试与评估方法。最
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )