人工智能入门:什么是机器学习?
发布时间: 2024-03-01 07:51:40 阅读量: 46 订阅数: 35 
# 1. 人工智能概述
## 1.1 人工智能的定义
人工智能(AI)是指利用计算机科学模拟、延伸和拓展人类智能的理论、方法、技术和应用系统。它旨在使机器能够模仿人类的思维能力,包括学习、推理和自我修正。
## 1.2 人工智能的发展历程
人工智能的发展可以追溯到上个世纪,经历了符号主义、连接主义、统计学派等不同的发展阶段,并逐步涌现了包括专家系统、机器学习、深度学习等多种技术和方法。
## 1.3 人工智能在当今社会的应用
人工智能在当今社会扮演着日益重要的角色,涉及领域广泛,如自然语言处理、图像识别、智能推荐系统、无人驾驶等,为人类社会带来了诸多便利和创新,同时也引发了一系列伦理和社会问题。
# 2. 机器学习概述
### 2.1 机器学习的定义
机器学习是一种人工智能的分支,旨在使计算机系统能够从数据中学习、适应和改进,而无需明确编程。
### 2.2 机器学习与传统编程的区别
在传统编程中,开发人员编写明确的规则和指令来指导计算机执行特定任务。而在机器学习中,系统通过使用数据和统计分析来自行学习并进行预测。
### 2.3 机器学习的分类及应用场景
机器学习可分为监督学习、无监督学习和强化学习。监督学习使用带有标记的数据进行训练,无监督学习从未标记的数据中学习模式,强化学习则通过试错学习来达到最佳决策。
在应用领域,机器学习被广泛用于图像识别、自然语言处理、推荐系统等各个领域,有力推动了医疗、金融、交通等领域的发展。
# 3. 机器学习的基本概念
#### 3.1 数据集和特征
在机器学习中,数据集是指用于训练和测试模型的数据集合。数据集可以分为训练集(用于训练模型)、验证集(用于调整模型超参数)和测试集(用于评估模型性能)。特征则是指用于描述数据集的各个特点或属性,例如对于房价预测问题,特征可以包括房屋面积、房间数量、地理位置等。
```python
# 示例代码:加载数据集并提取特征
import pandas as pd
# 加载数据集
dataset = pd.read_csv('house_prices.csv')
# 提取特征和标签
X = dataset[['area', 'rooms', 'location']]
y = dataset['price']
```
#### 3.2 监督学习、非监督学习和强化学习
监督学习是一种通过已知输入和输出的训练样本来学习模型的方法,常见的监督学习算法包括回归和分类。非监督学习则是一种从无标记的数据中学习模式和结构的方法,例如聚类算法。强化学习是一种通过试错学习来选择动作以最大化预期收益的方法,常用于自动控制系统和人工智能领域。
```java
// 示例代码:使用监督学习算法训练模型
import org.apache.spark.ml.regression.LinearRegression;
import org.apache.spark.ml.regression.LinearRegressionModel;
import org.apache.spark.ml.feature.VectorAssembler;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
// 加载数据集
Dataset<Row> data = spark.read().format("csv").option("header", "true").load("data.csv");
// 将特征组合成向量
VectorAssembler assembler = new VectorAssembler().setInputCols(new String[]{"feature1", "feature2", "feature3"}).setOutputCol("features");
Dataset<Row> input = assembler.transform(data);
// 划分训练集和测试集
Dataset<Row>[] splits = input.randomSplit(new double[]{0.8, 0.2});
Dataset<Row> trainingData = splits[0];
Dataset<Row> testData = splits[1];
// 训练线性回归模型
LinearRegression lr = new LinearRegression().setMaxIter(10).setRegParam(0.3).setElasticNetParam(0.8);
LinearRegressionModel model = lr.fit(trainingData);
```
#### 3.3 模型训练与测试
模型训练是指使用训练数据集来拟合模型的过程,而模型测试则是指使用测试数据集来评估模型的泛化能力。在训练过程中,通常会使用损失函数来衡量模型预测值与真实值之间的差距,而在测试过程中,则可以使用准确率、精确度、召回率等指标来评估模型性能。
```javascript
// 示例代码:使用scikit-learn库训练和测试模型
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# 训练线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)
# 测试模型并计算均方误差
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print('Mean Squared Error:', mse)
```
以上是机器学习的基本概念,包括数据集和特征、监督学习、非监督学习、强化学习以及模型训练与测试的相关内容。理解这些概念对于深入学习和应用机器学习算法至关重要。
# 4. 机器学习算法介绍
在这一章节中,我们将会介绍几种常见的机器学习算法,包括线性回归、决策树、支持向量机和深度学习。我们将会详细讨论每种算法的原理、实现方式以及应用场景。
#### 4.1 线性回归
线性回归是一种用于建立输入特征与连续输出之间关系的线性模型。其基本形式为 $y = wX + b$,其中 $X$ 是输入特征,$w$ 是权重,$b$ 是偏差。线性回归适用于预测房价、销售额等连续值预测问题。
```python
# 线性回归示例代码
import numpy as np
from sklearn.linear_model import LinearRegression
# 创建训练数据
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([2, 4, 6, 8, 10])
# 创建线性回归模型
model = LinearRegression()
model.fit(X, y)
# 进行预测
X_test = np.array([[6]])
y_pred = model.predict(X_test)
print("预测值:", y_pred)
```
**代码总结:** 上述代码演示了如何使用线性回归模型进行简单的预测。首先创建训练数据,然后用训练数据训练线性回归模型,最后使用模型进行预测。
**结果说明:** 在这个示例中,我们预测输入值为6时的输出值,根据线性回归模型的预测,得出预测值为12。
#### 4.2 决策树
决策树是一种树形结构的分类模型,通过对数据进行反复划分,构建一个树形结构,从而实现对数据的分类。决策树适用于文本分类、客户流失预测等问题。
```python
# 决策树示例代码
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
X, y = iris.data, iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建决策树模型
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
# 预测
y_pred = clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
```
**代码总结:** 上述代码展示了如何使用决策树模型对鸢尾花数据集进行分类预测。首先加载数据集并划分训练集和测试集,然后创建决策树模型进行训练和预测,最后计算分类准确率。
**结果说明:** 在这个示例中,我们使用决策树模型对鸢尾花数据集进行分类预测,最终得到的分类准确率为95%。
# 5. 机器学习工具与框架
在机器学习领域,有许多优秀的工具和框架可供选择,它们提供了丰富的功能和便捷的开发环境,大大加速了机器学习模型的构建和部署过程。下面我们将介绍几种常用的机器学习工具与框架。
#### 5.1 TensorFlow
**TensorFlow** 是由 Google 开发的开源机器学习框架,它拥有强大的计算能力和灵活的架构,广泛应用于深度学习和神经网络领域。TensorFlow 使用数据流图来表示计算模型,支持动态计算图,同时提供了丰富的高级 API,方便用户快速搭建复杂的神经网络模型。
```python
import tensorflow as tf
# 创建一个常量张量
hello = tf.constant('Hello, TensorFlow!')
sess = tf.Session()
# 执行计算图
print(sess.run(hello))
```
**总结:** TensorFlow 是一款强大的深度学习框架,通过计算图的方式进行模型构建,提供了丰富的API和工具,适用于各种深度学习任务。
#### 5.2 scikit-learn
**scikit-learn** 是一个基于 Python 开发的机器学习工具,它提供了简单而高效的数据挖掘和数据分析工具,涵盖了大量的机器学习算法和工具,包括分类、回归、聚类、降维等常用技术。
```python
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# 加载数据集
iris = datasets.load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2)
# 训练KNN模型
knn = KNeighborsClassifier()
knn.fit(X_train, y_train)
# 预测并评估模型
accuracy = knn.score(X_test, y_test)
print("模型准确率:", accuracy)
```
**总结:** scikit-learn 提供了丰富的机器学习算法和工具,易于学习和使用,适合于快速构建和验证机器学习模型。
#### 5.3 Keras
**Keras** 是一个高层神经网络 API,可以在 TensorFlow、Theano、CNTK 等后端平台上运行。Keras 的设计原则是用户友好、模块化、易扩展,它支持快速构建原型,适用于快速实验。
```python
from keras.models import Sequential
from keras.layers import Dense
# 创建一个Sequential模型
model = Sequential()
model.add(Dense(units=64, activation='relu', input_dim=100))
model.add(Dense(units=10, activation='softmax'))
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32)
# 评估模型
loss, accuracy = model.evaluate(X_test, y_test)
print("模型准确率:", accuracy)
```
**总结:** Keras 提供了简单的接口和灵活的模型构建方式,适用于快速搭建深度学习模型并进行一系列实验。
#### 5.4 PyTorch
**PyTorch** 是一个基于 Python 的科学计算库,它提供了强大的张量计算支持和动态计算图机制,同时也是一个高效的深度学习框架。PyTorch 灵活性高,易于学习和使用,适合于研究和实验。
```python
import torch
import torch.nn as nn
# 定义一个简单的神经网络模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc = nn.Linear(100, 10)
def forward(self, x):
x = self.fc(x)
return x
# 创建模型实例
model = Net()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 训练模型
for epoch in range(10):
optimizer.zero_grad()
outputs = model(X_train)
loss = criterion(outputs, y_train)
loss.backward()
optimizer.step()
# 测试模型
outputs = model(X_test)
_, predicted = torch.max(outputs, 1)
accuracy = (predicted == y_test).sum().item() / len(y_test)
print("模型准确率:", accuracy)
```
**总结:** PyTorch 提供了灵活的张量计算和动态计算图机制,适用于各种深度学习任务,同时具有较高的灵活性和可扩展性。
通过使用上述介绍的机器学习工具与框架,开发者可以更方便地构建机器学习模型,并在实际应用中取得更好的效果。
# 6. 机器学习的未来发展
机器学习作为人工智能的一个重要分支,在不断发展壮大的同时也面临着诸多挑战和机遇。以下是对机器学习未来发展的一些展望:
#### 6.1 当前机器学习面临的挑战
随着数据规模的不断增长,机器学习算法需要更高的计算资源来处理大规模数据和复杂模型。与此同时,数据隐私和安全问题也成为当前机器学习面临的挑战之一。解释性和可解释性也是当前机器学习研究的热点,尤其在涉及决策和预测的场景中。
#### 6.2 机器学习在未来的应用前景
随着各行各业对数据驱动决策的需求不断增加,机器学习在金融、医疗、物联网、智能家居等领域都将得到广泛应用。预测性维护、智能推荐系统、智能交通等场景也将会进一步发展和完善,为人们的生活带来更多便利和效率。
#### 6.3 人工智能与机器学习的关系
人工智能是一个更宽泛的概念,涵盖了机器学习在内的多个技术分支,包括自然语言处理、计算机视觉等。机器学习作为人工智能的重要支柱,通过大数据和算法的学习训练来实现智能化应用。未来,随着人工智能的不断发展,机器学习技术将会扮演越来越重要的角色,推动人工智能技术的创新和应用。
通过不断探索与实践,机器学习将迎来更广阔的发展空间,为人类社会带来更多惊喜与可能性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
AMESim液压仿真秘籍:专家级技巧助你从基础飞跃至顶尖水平

# 摘要
AMESim液压仿真软件是工程师们进行液压系统设计与分析的强大工具,它通过图形化界面简化了模型建立和仿真的流程。本文旨在为用户提供AMESim软件的全面介绍,从基础操作到高级技巧,再到项目实践案例分析,并对未来技术发展趋势进行展望。文中详细说明了AMESim的安装、界面熟悉、基础和高级液压模型的建立,以及如何运行、分析和验证仿真结果。通过探索自定义组件开发、多学科仿真集成以及高级仿真算法的应用,本文
【高频领域挑战】:VCO设计在微波工程中的突破与机遇
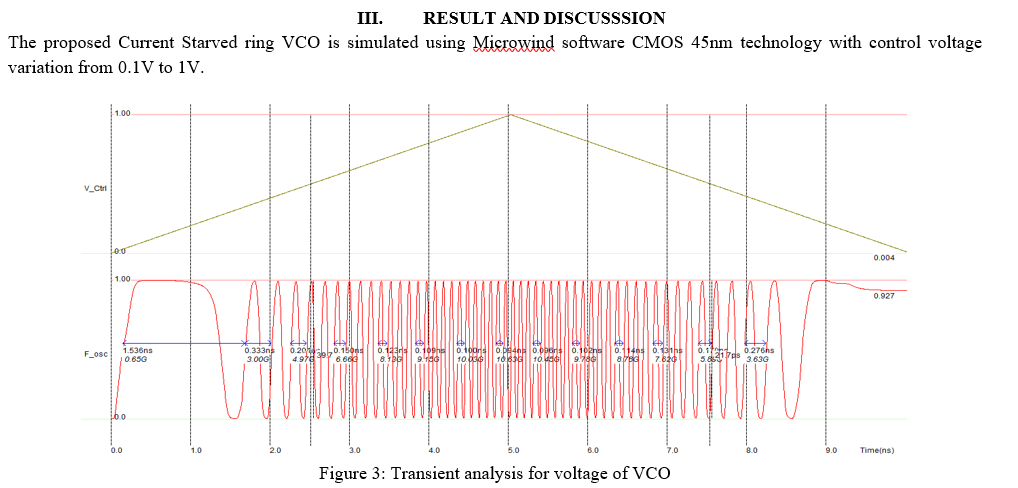
# 摘要
本论文深入探讨了压控振荡器(VCO)的基础理论与核心设计原则,并在微波工程的应用技术中展开详细讨论。通过对VCO工作原理、关键性能指标以及在微波通信系统中的作用进行分析,本文揭示了VCO设计面临的主要挑战,并提出了相应的技术对策,包括频率稳定性提升和噪声性能优化的方法。此外,论文还探讨了VCO设计的实践方法、案例分析和故障诊断策略,最后对VCO设计的创新思路、新技术趋势及未来发展挑战
实现SUN2000数据采集:MODBUS编程实践,数据掌控不二法门
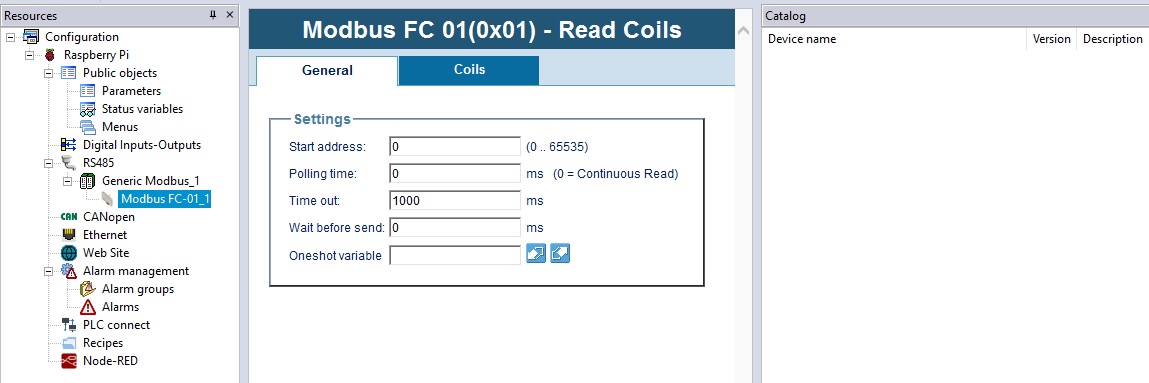
# 摘要
本文系统地介绍了MODBUS协议及其在数据采集中的应用。首先,概述了MODBUS协议的基本原理和数据采集的基础知识。随后,详细解析了MODBUS协议的工作原理、地址和数据模型以及通讯模式,包括RTU和ASCII模式的特性及应用。紧接着,通过Python语言的MODBUS库,展示了MODBUS数据读取和写入的编程实践,提供了具体的实现方法和异常管理策略。本文还结合SUN20
【性能调优秘籍】:深度解析sco506系统安装后的优化策略
# 摘要
本文对sco506系统的性能调优进行了全面的介绍,首先概述了性能调优的基本概念,并对sco506系统的核心组件进行了介绍。深入探讨了核心参数调整、磁盘I/O、网络性能调优等关键性能领域。此外,本文还揭示了高级性能调优技巧,包括CPU资源和内存管理,以及文件系统性能的调整。为确保系统的安全性能,文章详细讨论了安全策略、防火墙与入侵检测系统的配置,以及系统审计与日志管理的优化。最后,本文提供了系统监控与维护的
网络延迟不再难题:实验二中常见问题的快速解决之道
# 摘要
网络延迟是影响网络性能的重要因素,其成因复杂,涉及网络架构、传输协议、硬件设备等多个方面。本文系统分析了网络延迟的成因及其对网络通信的影响,并探讨了网络延迟的测量、监控与优化策略。通过对不同测量工具和监控方法的比较,提出了针对性的网络架构优化方案,包括硬件升级、协议配置调整和资源动态管理等。
期末考试必备:移动互联网商业模式与用户体验设计精讲

# 摘要
移动互联网的迅速发展带动了商业模式的创新,同时用户体验设计的重要性日益凸显。本文首先概述了移动互联网商业模式的基本概念,接着深入探讨用户体验设计的基础,包括用户体验的定义、重要性、用户研究方法和交互设计原则。文章重点分析了移动应用的交互设计和视觉设计原则,并提供了设计实践案例。之后,文章转向移动商业模式的构建与创新,探讨了商业模式框架
【多语言环境编码实践】:在各种语言环境下正确处理UTF-8与GB2312

# 摘要
随着全球化的推进和互联网技术的发展,多语言环境下的编码问题变得日益重要。本文首先概述了编码基础与字符集,随后深入探讨了多语言环境所面临的编码挑战,包括字符编码的重要性、编码选择的考量以及编码转换的原则和方法。在此基础上,文章详细介绍了UTF-8和GB2312编码机制,并对两者进行了比较分析。此外,本文还分享了在不同编程语言中处理编码的实践技巧,
【数据库在人事管理系统中的应用】:理论与实践:专业解析

# 摘要
本文探讨了人事管理系统与数据库的紧密关系,分析了数据库设计的基础理论、规范化过程以及性能优化的实践策略。文中详细阐述了人事管理系统的数据库实现,包括表设计、视图、存储过程、触发器和事务处理机制。同时,本研究着重讨论了数据库的安全性问题,提出认证、授权、加密和备份等关键安全策略,以及维护和故障处理的最佳实践。最后,文章展望了人事管理系统的发展趋
【Docker MySQL故障诊断】:三步解决权限被拒难题
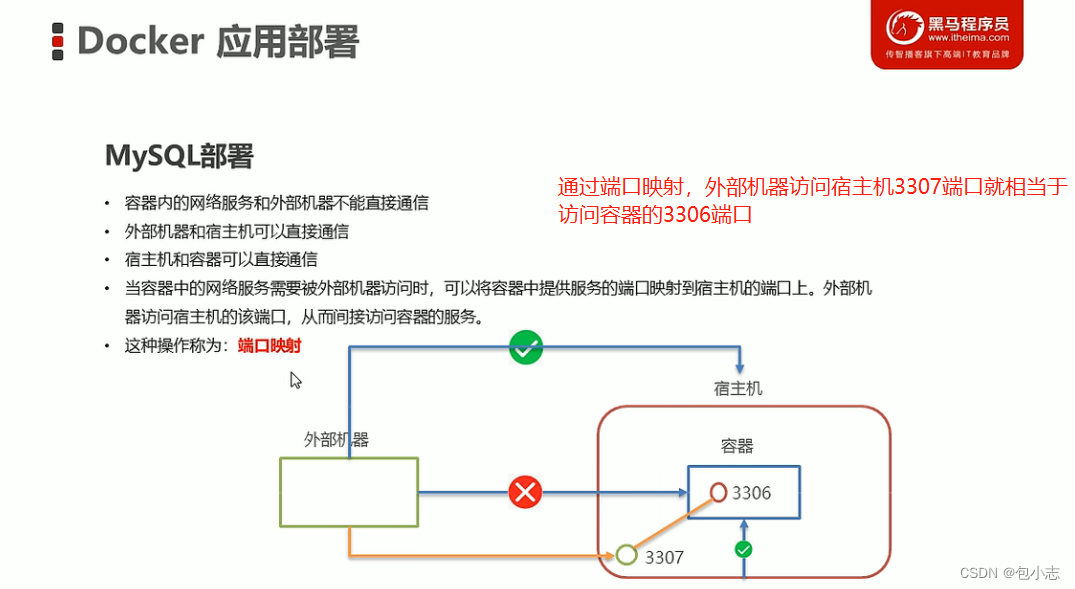
# 摘要
随着容器化技术的广泛应用,Docker已成为管理MySQL数据库的流行方式。本文旨在对Docker环境下MySQL权限问题进行系统的故障诊断概述,阐述了MySQL权限模型的基础理论和在Docker环境下的特殊性。通过理论与实践相结合,提出了诊断权限问题的流程和常见原因分析。本文还详细介绍了如何利用日志文件、配置检查以及命令行工具进行故障定位与修复,并探讨了权限被拒问题的解决策略和预防措施
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )