boto.s3.key权限管理:如何在Python中控制S3访问权限
发布时间: 2024-10-15 04:19:17 阅读量: 77 订阅数: 35 

`人工智能_人脸识别_活体检测_身份认证`.zip

# 1. 理解boto3库与S3权限管理基础
在本章中,我们将探索使用Python进行AWS S3权限管理的基础知识。我们会首先介绍`boto3`库,这是一个Python的AWS SDK,它提供了易于使用的接口来与AWS服务进行交互,其中就包括S3。接着,我们将讨论S3的基本概念,包括其资源模型和权限模型,以及如何通过`boto3`与这些概念进行交互。
## 1.1 boto3库概述
`boto3`库是AWS官方提供的Python库,允许开发者通过编写Python代码来管理AWS服务。它提供了一种高效、简洁的方式来与S3进行数据上传、下载、权限设置等操作。
## 1.2 S3资源与权限模型基础
S3是Amazon Simple Storage Service的简称,它为开发者提供了非常可靠、可扩展的对象存储解决方案。在S3中,主要资源包括Bucket和Key。Bucket类似于文件系统的目录,用于存储多个对象(Key),这些对象相当于文件系统中的文件。
### 权限模型
S3的权限模型基于IAM(Identity and Access Management)角色和策略(Policy)。IAM允许定义具有特定权限的用户和角色,而策略则是定义了对S3资源操作权限的一系列规则。
### 示例代码
以下是一个简单的`boto3`代码示例,用于列出所有的S3 Bucket:
```python
import boto3
# 创建一个S3客户端
s3_client = boto3.client('s3')
# 列出所有的Bucket
for bucket in s3_client.list_buckets()['Buckets']:
print(bucket['Name'])
```
此代码首先导入`boto3`库并创建一个S3客户端,然后调用`list_buckets`方法列出所有Bucket,并打印出它们的名称。
在接下来的章节中,我们将深入了解如何使用`boto3`配置AWS账户,以及如何管理S3 Bucket和Key的权限。我们将讨论如何使用访问控制列表(ACL)和策略(Policy)来控制访问权限,并通过实践案例来分析公共读写权限和私有读写权限的管理。
# 2. 配置boto3与AWS账户
### 2.1 安装并导入boto3库
#### 2.1.1 安装boto3库的方法
在本章节中,我们将探讨如何安装并导入boto3库,这是AWS官方提供的Python SDK,它允许我们通过编程方式管理AWS资源,包括Amazon S3。boto3库为Python开发人员提供了对AWS服务的访问,使得创建、配置和管理AWS资源变得简单和直观。
安装boto3库可以通过Python的包管理工具pip来完成。打开终端或命令提示符,执行以下命令:
```bash
pip install boto3
```
这个命令会安装boto3库及其所有依赖项。如果你使用的是Python 2.7,则可能需要使用pip3来安装针对Python 3版本的boto3:
```bash
pip3 install boto3
```
安装完成后,我们可以在Python脚本中导入boto3库,如下所示:
```python
import boto3
```
这段代码是我们的起点,它允许我们访问boto3库中的所有功能,为后续与AWS服务的交互奠定了基础。
#### 2.1.2 创建AWS账户并配置访问密钥
在本章节中,我们将介绍如何创建AWS账户并配置访问密钥。访问密钥是用于通过AWS API与AWS服务进行交互的凭证。AWS提供了多种认证方式,其中最常用的是IAM用户访问密钥和AWS访问密钥。
首先,你需要有一个AWS账户。如果你还没有账户,可以访问[Amazon AWS官网](***,点击“创建AWS账户”并按照提示完成注册过程。
注册完成后,登录到AWS管理控制台,找到IAM(Identity and Access Management)服务。IAM是AWS的身份和访问管理服务,允许你创建用户和角色,并为它们分配访问权限。
接下来,创建一个新的IAM用户,并为该用户生成访问密钥。这将提供用于API调用的“access_key_id”和“secret_access_key”。
1. 登录到AWS管理控制台。
2. 导航到IAM服务。
3. 在左侧菜单中选择“用户”,然后点击“添加用户”。
4. 输入用户名称,选择“编程访问”作为访问类型。
5. 点击“创建用户”以生成访问密钥。
创建用户后,你将得到一对访问密钥。请确保保存这对密钥,因为它们不会再次显示。
现在,我们可以在Python脚本中使用这些密钥来配置boto3会话。以下是代码示例:
```python
import boto3
# 配置AWS访问密钥
session = boto3.Session(
aws_access_key_id='你的access_key_id',
aws_secret_access_key='你的secret_access_key',
region_name='us-west-2'
)
# 创建S3资源对象
s3 = session.resource('s3')
```
在这个代码块中,我们首先导入了boto3库。然后,我们创建了一个boto3会话,指定AWS访问密钥ID、秘密访问密钥以及默认区域。最后,我们使用这个会话创建了一个S3资源对象,这将用于后续的S3资源操作。
### 2.2 探索S3资源与权限模型
#### 2.2.1 S3的基本概念与结构
在本章节中,我们将探索Amazon S3的基本概念与结构。Amazon S3(Simple Storage Service)是一种高度可扩展的对象存储服务,广泛用于存储和检索任何数量的数据。
S3的基本概念包括:
- **Bucket**:存储对象的容器。每个Bucket都有一个全局唯一的名称,且所有的Bucket都位于某个AWS区域中。
- **Object**:存储在S3中的数据。每个Object由一个键(key)、值(value)、版本ID、元数据和一组属性组成。
- **Key**:对象的唯一标识符。Key是用户定义的字符串,它标识了存储在S3中的对象。
S3的结构简单直观,但其功能却非常强大。它支持高可用性、数据一致性和强大的数据管理功能。
### 2.2.2 权限模型与IAM角色
在本章节中,我们将讨论S3的权限模型以及IAM角色在S3中的作用。S3使用基于策略的访问控制模型,允许你定义细粒度的访问控制策略。
S3的权限模型主要基于以下几种策略:
- **Bucket策略**:定义哪些用户可以对Bucket执行哪些操作。
- **对象策略**:定义哪些用户可以对特定对象执行哪些操作。
- **IAM策略**:定义IAM角色可以对S3资源执行哪些操作。
IAM(Identity and Access Management)是AWS的身份和访问管理服务,它允许你创建用户和角色,并为它们分配访问权限。IAM角色是IAM中的一个核心概念,它允许你定义一组策略,并将这些策略应用于信任该角色的AWS服务或用户。
当IAM角色与S3结合使用时,你可以创建一个角色,并授予它对特定S3资源的访问权限。然后,其他AWS服务或用户可以通过承担这个角色来获得对S3资源的访问权限。
### 2.3 设置boto3会话与默认参数
#### 2.3.1 创建boto3会话
在本章节中,我们将介绍如何创建boto3会话以及如何使用它来配置AWS服务的默认参数。boto3会话允许你创建一个连接到AWS服务的上下文环境,你可以在该上下文环境中执行各种操作。
要创建一个boto3会话,你可以使用`boto3.Session()`方法。这个方法允许你指定多个参数,例如访问密钥、区域、会话令牌等。创建会话后,你可以使用该会话来创建S3资源对象、获取服务客户端等。
以下是一个创建boto3会话的代码示例:
```python
import boto3
# 创建一个boto3会话
session = boto3.Session(
aws_access_key_id='你的access_key_id',
aws_secret_access_key='你的secret_access_key',
region_name='us-west-2'
)
```
在这个代码示例中,我们首先导入了boto3库。然后,我们创建了一个boto3会话,并指定了访问密钥ID、秘密访问密钥和默认区域。最后,我们使用这个会话创建了一个S3资源对象,这将用于后续的S3资源操作。
#### 2.3.2 配置默认区域与输出格式
在本章节中,我们将学习如何配置boto3会话的默认区域和输出格式。boto3会话允许你设置多个默认参数,以便在连接到AWS服务时简化操作。其中,最常用的两个参数是默认区域和输出格式。
默认区域参数`region_name`用于指定你想要连接的AWS区域。AWS服务在不同的地理区域提供多个数据中心,你可以根据需要选择最近的区域。
输出格式参数`output`允许你指定API调用返回结果的格式。boto3支持多种输出格式,包括`json`、`yaml`和`text`。默认情况下,boto3使用`json`格式返回API调用的结果。
以下是如何设置默认区域和输出格式的代码示例:
```python
import boto3
# 创建一个boto3会话并配置默认参数
session = boto3.Session(
aws_access_key_id='你的access_key_id',
aws_secret_access_key='你的secret_access_key',
region_name='us-west-2',
output='json' # 设置输出格式为JSON
)
# 使用会话创建S3资源对象
s3 = session.resource('s3')
```
在这个代码示例中,我们首先导入了boto3库。然后,我们创建了一个boto3会话,并指定了访问密钥ID、秘密访问密钥、默认区域和输出格式。最后,我们使用这个会话创建了一个S3资源对象,这将用于后续的S3资源操作。
默认区域和输出格式是boto3会话中非常重要的配置项,它们将影响你使用boto3进行AWS服务操作的方式。正确配置这些参数可以帮助你更加高效地与AWS服务进行交互。
# 3. 使用boto3管理S3 Key权限
## 3.1 创建与管理S3 Bucket
### 3.1.1 创建Bucket
在本章节中,我们将深入探讨如何使用boto3库创建和管理S3 Bucket,这是存储对象的基础容器。我们将介绍创建Bucket的基本步骤,并讨论一些关键的配置选项,这些选项对于确保数据的可用性和安全性至关重要。
首先,使用boto3创建S3 Bucket的基本代码如下:
```python
import boto3
# 创建一个S3客户端
s3_client = boto3.client('s3')
# 创建Bucket
s3_client.create_bucket(Bucket='example-bucket-name')
```
在这段代码中,我们首先导入了`boto3`库,并创建了一个S3客户端实例。然后,我们调用了`create_bucket`方法来创建一个新的Bucket。这里需要注意的是,`Bucket`参数需要是全局唯一的,否则会抛出异常。
### 3.1.2 设置Bucket属性
创建Bucket之后,我们可能需要对其进行配置以满足特定的业务需求。例如,我们可以设置Bucket的区域位置、访问权限和其他高级属性。
```python
# 设置Bucket的区域位置
s3_client.put_bucket_location(Bucket='example-bucket-name', LocationConstraint='us-west-1')
# 设置Bucket的访问权限为私有
policy = {
"Version": "2012-10-17",
"Statement": [
{
"Sid": "DenyPublicRead",
"Effect": "Deny",
"Principal": "*",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::example-bucket-name/*"
}
]
}
s3_client.put_bucket_policy(Bucket='example-bucket-name', Policy=json.dumps(policy))
```
在这段代码中,我们首先通过`put_bucket_location`方法设置了Bucket的区域位置。然后,我们创建了一个包含权限策略的字典,并将其转换为JSON字符串。最后,我们通过`put_bucket_policy`方法应用了这个策略,确保Bucket中的对象不能被公开读取。
### 3.1.3 设置Bucket权限
除了使用策略控制访问权限外,我们还可以使用ACL(Access Control List)来设置Bucket的权限。ACL允许我们定义一些基本的访问控制规则。
```python
# 设置Bucket的ACL为私有
s3_client.put_bucket_acl(Bucket='example-bucket-name', ACL='private')
```
在这段代码中,我们通过`put_bucket_acl`方法将Bucket的ACL设置为`private`,这意味着除了Bucket的所有者外,其他用户默认没有访问权限。
### 3.1.4 创建Bucket的逻辑分析
在执行上述代码时,我们需要理解每一步操作的逻辑。首先,创建Bucket是一个简单的操作,但需要确保Bucket名称的全局唯一性。其次,设置Bucket的属性和权限是确保数据安全和合规性的关键步骤。
### 3.1.5 参数说明
- `Bucket`: 指定Bucket的名称。
- `LocationConstraint`: 指定Bucket的物理位置。
- `Policy`: 使用JSON格式的字符串定义Bucket的访问控制策略。
- `ACL`:

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 库 boto.s3.key,它提供了与 Amazon S3 对象交互的强大功能。通过一系列文章,您将掌握 boto.s3.key 的基本概念、高级功能和最佳实践。您将了解如何高效管理 S3 对象、实施安全措施、自动化云数据备份,以及在大型项目中优化性能。此外,您还将了解 boto.s3.key 在微服务架构、数据迁移和复杂数据处理中的应用。无论您是 Python 开发人员、AWS S3 用户还是云存储专家,本专栏都将为您提供宝贵的见解,帮助您充分利用 boto.s3.key,提升您的 S3 操作效率和安全性。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
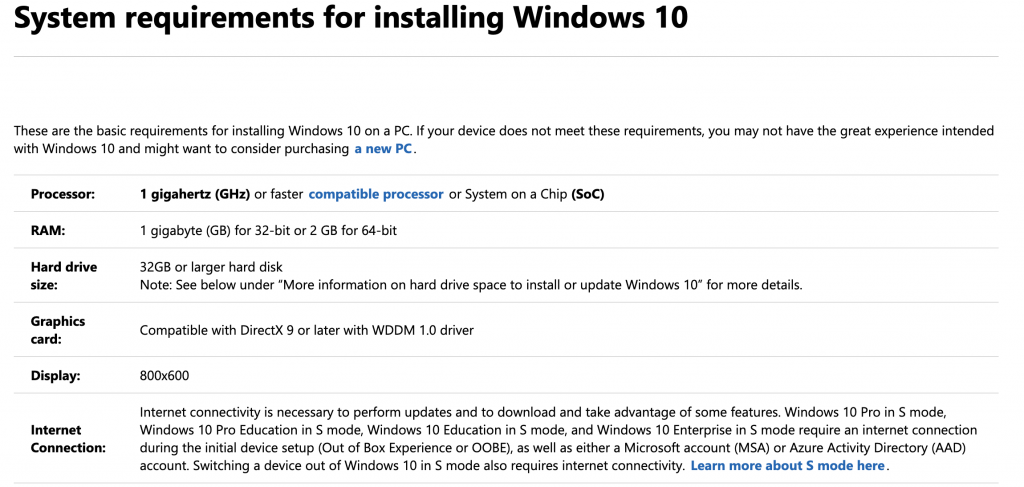
【系统兼容性深度揭秘】:Win10 x64上的TensorFlow与CUDA完美匹配指南
# 摘要
本文详细探讨了在深度学习框架中系统兼容性的重要性,并深入介绍了CUDA的安装、配置以及TensorFlow环境的搭建过程。文章分析了不同版本CUDA与GPU硬件及NVIDIA驱动程序的兼容性需求,并提供了详细的安装步骤和故障排除方法。针对TensorFlow的安装与环境搭建,文章阐述了版本选择、依赖
先农熵数学模型:计算方法深度解析

# 摘要
先农熵模型作为一门新兴的数学分支,在理论和实际应用中显示出其独特的重要性。本文首先介绍了先农熵模型的概述和理论基础,阐述了熵的起源、定义及其在信息论中的应用,并详细解释了先农熵的定义和数学角色。接着,文章深入探讨了先农熵模型的计算方法,包括统计学和数值算法,并分析了软件实现的考量。文中还通过多个应用场景和案例,展示了先农熵模型在金融分析、生物信息学和跨学科研究中的实际应用。最后,本文提出了
【24小时精通电磁场矩量法】:从零基础到专业应用的完整指南

# 摘要
本文系统地介绍了电磁场理论与矩量法的基本概念和应用。首先概述了电磁场与矩量法的基本理论,包括麦克斯韦方程组和电磁波的基础知识,随后深入探讨了矩量法的理论基础,特别是基函数与权函数选择、阻抗矩阵和导纳矩阵的构建。接着,文章详述了矩量法的计算步骤,涵盖了实施流程、编程实现以及结果分析与验证。此外,本文还探讨了矩量法在天线分析、微波工程以及雷达散射截面计算等不同场景的应用,并介绍了高频近似技术、加速技术和
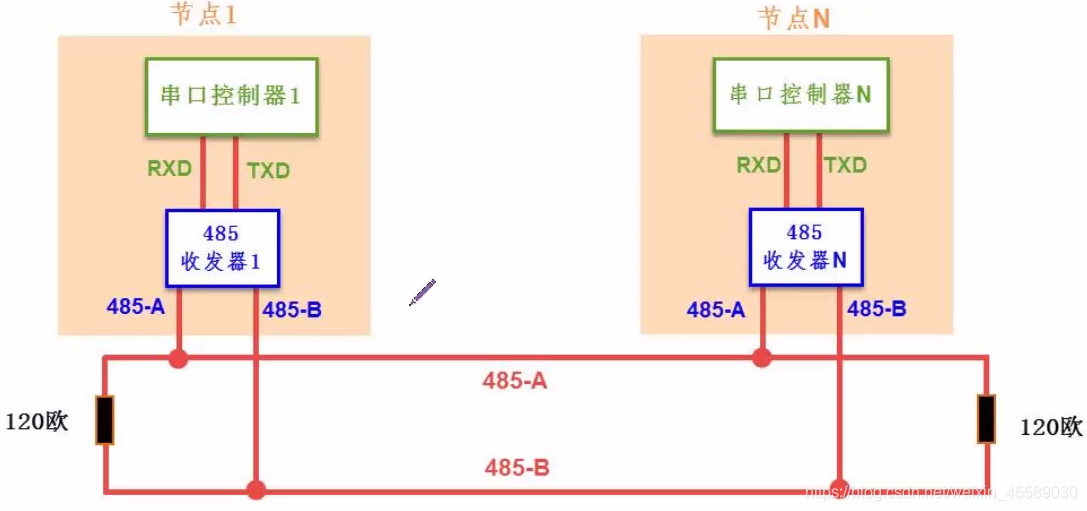
RS485通信原理与实践:揭秘偏置电阻最佳值的计算方法
# 摘要
RS485通信作为一种广泛应用的串行通信技术,因其较高的抗干扰能力和远距离传输特性,在工业控制系统和智能设备领域具有重要地位。
【SOEM多线程编程秘籍】:线程同步与资源竞争的管理艺术

# 摘要
本文针对SOEM多线程编程提供了一个系统性的学习框架,涵盖多线程编程基础、同步机制、资源竞争处理、实践案例分析以及进阶技巧,并展望了未来发展趋势。首先,介绍了多线程编程的基本概念和线程同步机制,包括同步的必要性、锁的机制、同步工具的使用等。接着,深入探讨了资源竞争的识别、预防策略和调试技巧。随后
SRIO Gen2在嵌入式系统中的实现:设计要点与十大挑战分析

# 摘要
本文对SRIO Gen2技术在嵌入式系统中的应用进行了全面概述,探讨了设计要点、面临的挑战、实践应用以及未来发展趋势。首先,文章介绍了SRIO Gen2的基本概念及其在嵌入式系统中的系统架构和硬件设计考虑。随后,文章深入分析了SRIO Gen2在嵌入式系统中遇到的十大挑战,包括兼容性、性能瓶颈和实时性能要求。在实践应用方面,本文讨论了硬件设计、软件集成优化以及跨平台部署与维护的策略。最后,文章展望了SRI
【客户满意度提升神器】:EFQM模型在IT服务质量改进中的效果

# 摘要
本论文旨在深入分析EFQM模型在提升IT服务质量方面的作用和重要性。通过对EFQM模型基本原理、框架以及评估准则的阐述,本文揭示了其核心理念及实践策略,并探讨了如何有效实施该模型以改进服务流程和建立质量管理体系。案例研究部分强调了EFQM模型在实际IT服务中的成功应用,以及它如何促进服务创新和持续改进。最后,本论文讨论了应用EFQM模型时可能遇到的挑战,以及未来的发展趋势,包括
QZXing进阶技巧:如何优化二维码扫描速度与准确性?

# 摘要
随着移动设备和电子商务的迅速发展,QZXing作为一种广泛应用的二维码扫描技术,其性能直接影响用户体验。本文首先介绍了QZXing的基础知识及其应用场景,然后深入探讨了QZXing的理论架构,包括二维码编码机制、扫描流程解析,以及影响扫描速度与准确性的关键因素。为了优化扫描速度,文章提出了一系列实践策略,如调整解码算法、图像预处理技术,以及线程和并发优化。此外,本文还探讨了提升扫描准
【架构设计的挑战与机遇】:保险基础数据模型架构设计的思考

# 摘要
保险业务的高效运行离不开科学合理的架构设计,而基础数据模型作为架构的核心,对保险业务的数据化和管理至关重要。本文首先阐述了架构设计在保险业务中的重要性,随后介绍了保险基础数据模型的理论基础,包括定义、分类及其在保险领域的应用。在数据模型设计实践中,本文详细讨论了设计步骤、面向对象技术及数据库选择与部署
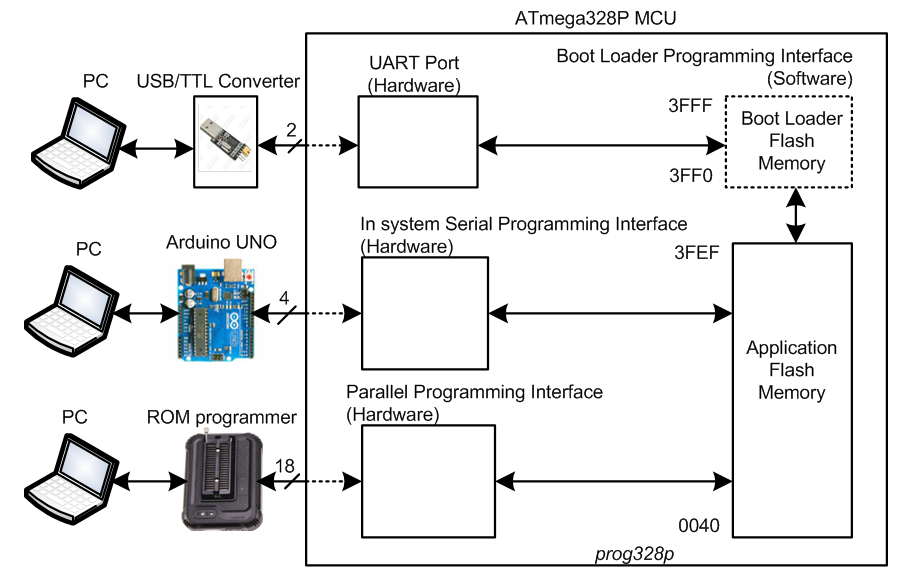
【AVR编程效率提升宝典】:遵循avrdude 6.3手册,实现开发流程优化
# 摘要
本文深入探讨了AVR编程和开发流程,重点分析了avrdude工具的使用与手册解读,从而为开发者提供了一个全面的指南。文章首先概述了avrdude工具的功能和架构,并进一步详细介绍了其安装、配置和在AVR开发中的应用。在开发流程优化方面,本文探讨了如何使用avrdude简化编译、烧录、验证和调
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )