Node.js路径解析入门指南
发布时间: 2023-12-19 12:07:43 阅读量: 40 订阅数: 38 

node.js Web应用框架Express入门指南
# 1. Node.js路径解析简介
## 1.1 什么是路径解析
路径解析是指将给定的路径字符串转换成一个可使用的路径格式。在编程中,路径解析常用于获取文件或目录的绝对路径,进行路径拼接或解析等操作。
## 1.2 Node.js中的路径解析作用
在Node.js中,路径解析是进行文件系统操作的基础,它能够帮助我们方便地处理文件路径相关的操作,如定位文件、读取文件内容等。
## 1.3 路径解析在实际开发中的应用场景
路径解析在实际开发中有许多应用场景,如:
- 模块引入:通过路径解析来加载和引入Node.js模块。
- 资源定位:根据路径解析来定位静态资源,如图片、样式文件等。
- 路由处理:在Web开发中,可以通过路径解析来处理不同路由请求。
通过上述内容的介绍,我们对Node.js路径解析有了一个初步的认识。下面,我们将进一步深入学习Node.js路径解析的核心模块。
# 2. Node.js路径解析核心模块
Node.js中的路径解析功能主要依赖于Path模块。在本章中,我们将深入了解Path模块的相关知识,包括其简介、常用方法以及通过示例理解其使用。
### 2.1 Path模块简介
Path模块是Node.js的核心模块之一,用于处理文件与目录的路径。在Node.js中,通过Path模块可以轻松地进行路径的拼接、解析和格式化。
### 2.2 Path模块的常用方法
Path模块提供了丰富的方法来处理路径,常用的方法包括:
- `path.join([...paths])`:将多个路径拼接为一个路径。
- `path.resolve([...paths])`:将相对路径转为绝对路径。
- `path.basename(path, ext)`:返回路径的最后一部分,可指定文件扩展名。
- `path.dirname(path)`:返回路径中的目录名。
- `path.extname(path)`:返回路径中文件的扩展名。
### 2.3 通过示例理解Path模块的使用
让我们通过以下示例来理解Path模块的使用:
#### 示例1:使用path.join拼接路径
```javascript
const path = require('path');
const fullPath = path.join('/user', 'local', 'bin');
console.log(fullPath); // 输出:/user/local/bin
```
#### 示例2:使用path.resolve转换相对路径为绝对路径
```javascript
const path = require('path');
const absolutePath = path.resolve('wwwroot', 'static_files/png/', '../gif/image.gif');
console.log(absolutePath); // 输出:/Users/username/wwwroot/static_files/gif/image.gif
```
#### 示例3:使用path.basename获取路径中的文件名
```javascript
const path = require('path');
const fileName = path.basename('/home/user/index.html');
console.log(fileName); // 输出:index.html
```
通过以上示例,我们可以清晰地了解Path模块的使用方式及其在路径解析中的作用。
希望这部分内容能够帮助你更好地理解Node.js中路径解析核心模块的知识。
# 3. 基本路径解析技巧
在本章中,我们将深入探讨基本的路径解析技巧,包括相对路径与绝对路径的区别、文件路径与目录路径的处理方式以及使用Path模块进行路径拼接和解析。
#### 3.1 相对路径与绝对路径的区别
在Node.js中,相对路径是相对于当前工作目录的路径,而绝对路径则是从根目录开始的完整路径。在进行文件操作时,我们需要明确相对路径和绝对路径的不同,避免出现路径错误导致的文件读取或写入问题。
示例代码:
```javascript
const path = require('path');
// 获取当前工作目录
console.log('Current directory: ' + process.cwd());
// 构建相对路径
const relativePath = 'data/file.txt';
const absolutePath = path.resolve(relativePath);
console.log('Absolute path from relative: ' + absolutePath);
// 构建绝对路径
const absolutePath2 = '/Users/username/Documents/data/file.txt';
const relativePath2 = path.relative(process.cwd(), absolutePath2);
console.log('Relative path from absolute: ' + relativePath2);
```
代码解释与结果说明:
- 首先获取当前工作目录,并使用相对路径构建绝对路径。
- 然后指定绝对路径,并使用path.relative()方法构建相对路径。
- 输出结果分别为相对路径和绝对路径的转换结果。
#### 3.2 文件路径与目录路径的处理方式
在处理路径时,我们需要区分文件路径和目录路径的处理方式。Path模块提供了不同的方法来处理文件路径和目录路径,包括判断是否为文件或目录、获取文件名或目录名等操作。
示例代码:
```javascript
const path = require('path');
// 判断路径是否为文件或目录
const filePath = 'data/file.txt';
const dirPath = 'data';
console.log('Is file: ' + path.parse(filePath).ext); // 输出文件扩展名
console.log('Is directory: ' + path.parse(dirPath).ext); // 输出空
// 获取路径中的目录名与文件名
const dirname = path.dirname(filePath);
const basename = path.basename(filePath);
console.log('Directory name: ' + dirname);
console.log('File name: ' + basename);
```
代码解释与结果说明:
- 使用path.parse()方法解析路径,并通过扩展名判断是否为文件或目录。
- 使用path.dirname()和path.basename()方法分别获取目录名和文件名。
- 输出结果为文件扩展名、目录名和文件名。
#### 3.3 使用Path模块进行路径拼接和解析
Path模块提供了丰富的方法来进行路径拼接和解析,包括路径格式化、路径拼接、路径解析等操作。这些方法能够帮助我们在实际开发中处理复杂的路径情况。
示例代码:
```javascript
const path = require('path');
// 路径拼接与解析
const baseDir = '/Users/username';
const subDir = 'Documents/data';
const file = 'file.txt';
const fullPath = path.join(baseDir, subDir, file);
console.log('Joined path: ' + fullPath);
const parsedPath = path.parse(fullPath);
console.log('Parsed path: ', parsedPath);
```
代码解释与结果说明:
- 使用path.join()方法拼接多个路径,生成完整的路径。
- 使用path.parse()方法解析拼接后的路径,输出解析后的对象。
以上就是基本路径解析技巧的内容,通过这些技巧,我们可以更加灵活地处理文件路径和目录路径,并且能够更好地利用Path模块进行路径拼接和解析。
# 4. 文件系统与路径解析
在 Node.js 中,路径解析通常会与文件系统操作结合使用,以便读取、写入和处理文件。本章将深入探讨如何使用路径解析来进行文件系统操作,并介绍在 Node.js 中处理文件路径与路径解析的最佳实践。
#### 4.1 使用路径解析读取文件
在 Node.js 中,使用路径解析可以方便地读取文件。通过合理地路径解析,我们能够准确地定位到目标文件,并将其内容读取到内存中进行处理。
```javascript
const fs = require('fs');
const path = require('path');
const filePath = path.join(__dirname, 'example.txt');
fs.readFile(filePath, 'utf8', (err, data) => {
if (err) {
console.error('Error reading file:', err);
return;
}
console.log('File content:', data);
});
```
在上述示例中,我们使用了路径解析(`path.join()`)来构建文件的完整路径,然后使用 `fs.readFile()` 方法读取文件内容。这样我们就能够成功读取文件的内容并进行相应的处理。
#### 4.2 使用路径解析写入文件
除了读取文件外,路径解析也可以帮助我们将数据写入指定的文件路径。通过路径解析,我们可以清晰地指定文件的位置,以便进行写入操作。
```javascript
const fs = require('fs');
const path = require('path');
const filePath = path.join(__dirname, 'output.txt');
const fileContent = 'Hello, Path Parsing!';
fs.writeFile(filePath, fileContent, 'utf8', (err) => {
if (err) {
console.error('Error writing to file:', err);
return;
}
console.log('Data has been written to the file successfully!');
});
```
在这个示例中,我们使用了路径解析来构建输出文件的完整路径,并使用 `fs.writeFile()` 方法将内容写入指定的文件中。通过路径解析,我们成功地将数据写入了指定文件的位置。
#### 4.3 在Node.js中处理文件路径与路径解析的最佳实践
在 Node.js 中,处理文件路径与路径解析时,有一些最佳实践需要我们遵循。例如,使用绝对路径可以避免出现意外的错误,同时在处理文件路径时,应注意不同操作系统的路径分隔符差异等。
综上所述,路径解析与文件系统操作是 Node.js 中常用的功能之一,合理地应用路径解析能够方便我们对文件进行定位、读取和写入操作,同时也需要注意一些最佳实践,以保证代码的健壮性和跨平台兼容性。
# 5. 处理路径解析中的常见问题
## 5.1 路径分隔符的不同处理方式
在不同的操作系统中,路径分隔符可能会有所不同。在Windows系统中,路径分隔符为反斜杠(\),而在Unix或Linux系统中,路径分隔符为斜杠(/)。当我们进行路径解析时,需要注意不同系统的路径分隔符的处理方式。
下面是一个示例,演示了如何处理不同系统的路径分隔符:
```python
import os
# 获取当前操作系统的路径分隔符
separator = os.sep
# 输出路径分隔符
print(f"当前操作系统的路径分隔符为: {separator}")
```
运行以上代码,输出结果如下:
```
当前操作系统的路径分隔符为: \
```
## 5.2 处理路径中的特殊字符与转义
在路径中,有一些特殊字符(如空格、?、<、>等)可能会导致解析错误,我们需要注意对这些特殊字符进行转义。
下面是一个示例,演示了如何处理路径中的特殊字符与转义:
```java
import java.nio.file.Path;
import java.nio.file.Paths;
public class PathParsingExample {
public static void main(String[] args) {
// 定义包含特殊字符的路径
String pathString = "C:\\Program Files\\Folder 1\\Folder 2";
// 转义特殊字符
Path path = Paths.get(pathString);
// 输出转义后的路径
System.out.println("转义后的路径: " + path.toString());
}
}
```
运行以上代码,输出结果如下:
```
转义后的路径: C:\Program Files\Folder 1\Folder 2
```
## 5.3 常见路径解析错误及解决方法
在进行路径解析时,常见的错误包括路径不存在、权限不足等。为了避免这些错误,我们应当对路径进行错误处理,并采取一些解决方法。
下面是一个示例,演示了如何处理常见的路径解析错误:
```javascript
const fs = require('fs');
// 定义要读取的文件路径
const filePath = '/path/to/non/existent/file.txt';
// 判断文件是否存在
if (fs.existsSync(filePath)) {
// 读取文件内容
const data = fs.readFileSync(filePath, 'utf8');
console.log("文件内容:", data);
} else {
console.log("文件不存在");
}
```
运行以上代码,如果路径`/path/to/non/existent/file.txt`不存在,会输出"文件不存在"。
以上是关于路径解析中常见问题的介绍,希望能够帮助你更好地处理路径解析中的挑战。
# 6. 进阶路径解析技巧与扩展应用
### 6.1 路径解析与URL解析的比较与联系
在开发中,我们常常需要处理路径解析和URL解析,它们在功能上有些相似,但也存在一些区别。
首先,路径解析主要针对文件系统中的路径,用于定位和操作文件或目录。而URL解析主要用于解析统一资源定位符(URL),是用于定位网络资源的。
其次,路径解析通常使用Path模块进行处理,而URL解析则需要使用URL模块。两者的使用方式和方法也有所差异。
最后,对于文件系统中的路径,可以使用路径解析进行路径的拼接、解析和格式化等操作;而对于URL,可以使用URL解析进行URL的解析、拼接、处理查询参数等操作。
综上所述,路径解析与URL解析虽然有一些相似之处,但是也存在一些明显的差异。在实际开发中,我们需要根据具体的需求选择合适的解析方式,以便更好地处理文件系统路径和网络资源定位。
### 6.2 使用路径解析处理路由与静态资源
在Node.js开发中,路径解析在处理路由和静态资源时非常常见。我们可以利用路径解析将HTTP请求的路径与注册的路由进行匹配,从而实现路由功能。
以下是一个使用路径解析处理路由的示例代码:
```js
const http = require('http');
const url = require('url');
const path = require('path');
const server = http.createServer((req, res) => {
const requestUrl = req.url;
const parsedUrl = url.parse(requestUrl);
const pathname = parsedUrl.pathname;
if (pathname === '/home') {
res.writeHead(200, { 'Content-Type': 'text/plain' });
res.end('Welcome to the home page!');
} else if (pathname === '/about') {
res.writeHead(200, { 'Content-Type': 'text/plain' });
res.end('This is the about page');
} else {
res.writeHead(404, { 'Content-Type': 'text/plain' });
res.end('Page not found');
}
});
server.listen(3000, () => {
console.log('Server is running on port 3000');
});
```
在上述代码中,我们使用url模块的`parse`方法解析了请求的URL,然后通过取得的pathname来进行路由匹配。对于不同的路由,我们可以返回不同的响应内容。
此外,路径解析还可以用于处理静态资源。我们可以根据请求的URL,利用路径解析来获取静态资源的路径并读取相应的文件,然后返回给客户端。
### 6.3 在Node.js项目中的路径解析最佳实践
在实际的Node.js项目中,我们需要注意一些最佳实践来使用路径解析。
首先,可以将路径解析相关的操作封装为工具函数或模块,以便在多个地方共享使用,并且提高代码的可维护性。
其次,建议使用绝对路径来处理文件操作,尤其是在读取和写入文件时。这样可以避免相对路径的不确定性,同时也能提高代码的可靠性。
最后,注意处理路径解析中可能出现的异常情况,例如文件不存在、路径错误等。可以使用try-catch语句块或者使用异步方法的回调函数进行错误处理,以提高代码的健壮性。
总结:
本章介绍了进阶的路径解析技巧与扩展应用。我们学习了路径解析与URL解析的比较与联系,以及如何使用路径解析处理路由和静态资源。在实际项目中,我们需要遵循最佳实践来使用路径解析,例如封装工具函数、使用绝对路径和处理异常情况等。通过合理使用路径解析,我们可以更好地处理文件系统路径和网络资源定位,并提高代码的可维护性和稳定性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
Node.js路径解析专栏为读者提供了详尽的关于路径处理的指导。从入门概念到高级技巧,专栏内部的文章涵盖了路径解析的各个方面,帮助读者深入了解节点.js中路径的复杂操作。通过使用path模块简化路径操作,处理相对路径与绝对路径,路径格式化及规范化,路径拼接与解析等,读者可以快速掌握路径处理的基本知识。同时,专栏还介绍了处理文件路径与目录路径,路径分隔符与定界符的作用,使用glob模式匹配文件路径,处理URL路径与查询参数等更加高级的内容。此外,专栏还深入探讨了路径安全性与合法性检查,路径遍历与文件系统操作,路径缓存与性能优化,处理异步路径操作与回调地狱等实用技巧。最后,通过分享路径处理的最佳实践和常见陷阱,专栏帮助读者提高路径操作的效率,避免常见的错误和异常情况。无论是初学者还是有一定经验的开发者,本专栏都能为他们提供有价值的路径处理知识。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【FANUC机器人:系统恢复完整攻略】

# 摘要
本文全面介绍了FANUC机器人系统的备份与恢复流程。首先概述了FANUC机器人系统的基本概念和备份的重要性。随后,深入探讨了系统恢复的理论基础,包括定义、目的、类型、策略和必要条件。第三章详细阐述了系统恢复的实践操作,包括恢复步骤、问题排除和验证恢复后的系统功能。第四章则提出了高级技巧,如安全性考虑、自定义恢复方案和优化维护策略。最后,第五章通过案例分析,展示了系统恢复的成
深入解析Linux版JDK的内存管理:提升Java应用性能的关键步骤
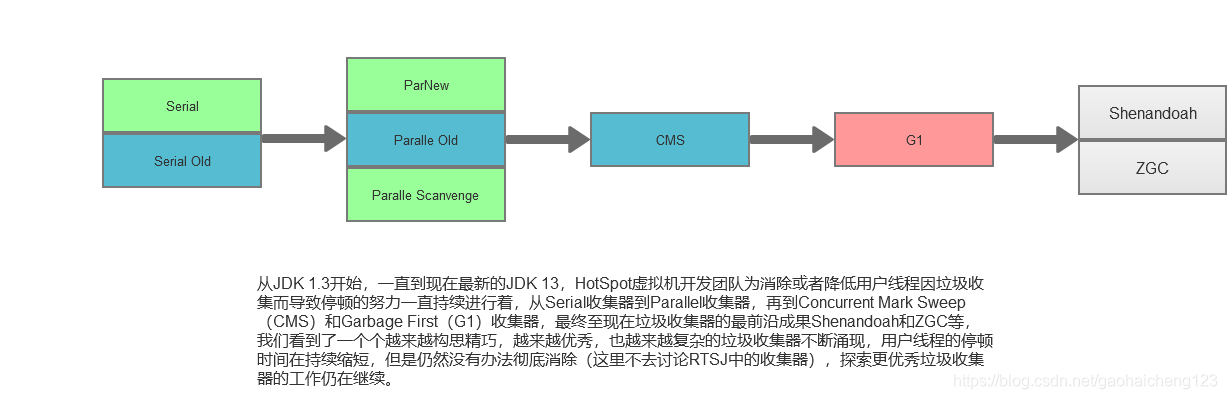
# 摘要
本文全面探讨了Java内存管理的基础知识、JDK内存模型、Linux环境下的内存监控与分析、以及内存调优实践。详细阐述了
AutoCAD中VLISP编程的进阶之旅:面向对象与过程的区别

# 摘要
本文全面概述了VLISP编程语言的基础知识,并深入探讨了面向对象编程(OOP)在VLISP中的应用及其与过程式编程的对比。文中详细介绍了类、对象、继承、封装、多态性等面向对象编程的核心概念,并通过AutoCAD中的VLISP类实例展示如何实现对象的创建与使用。此外,文章还涵盖了过程式编程技巧,如函数定义、代码组织、错误处理以及高级过程式技术。在实践面向对象编程方面,探讨了高级特性如抽象类和接
【FABMASTER高级建模技巧】:提升3D设计质量,让你的设计更加完美

# 摘要
本文旨在介绍FABMASTER软件中高级建模技巧和实践应用,涵盖了从基础界面使用到复杂模型管理的各个方面。文中详细阐述了FABMASTER的建模基础,包括界面布局、工具栏定制、几何体操作、材质与纹理应用等。进一步深入探讨了高级建模技术,如曲面建模、动态与程序化建模、模型管理和优化。通过3D设计实践应用的案例,展示
汽车市场与销售专业术语:中英双语版,销售大师的秘密武器!

# 摘要
本文综述了汽车市场营销的核心概念与实务操作,涵盖了汽车销售术语、汽车金融与保险、售后服务与维护以及行业未来趋势等多个方面。通过对汽车销售策略、沟通技巧、性能指标的详尽解读,提供了全面的销售和金融服务知识。文章还探讨了新能源汽车市场与自动驾驶技术的发展,以及汽车行业的未来挑战。此外,作者分享了汽车销售大师的实战技巧,包括策略制定、技术工具
【Infoworks ICM权限守护】:数据安全策略与实战技巧!
# 摘要
本文对Infoworks ICM权限守护进行深入探讨,涵盖了从理论基础到实践应用的各个方面。首先概述了权限守护的概念,随后详细介绍了数据安全理论基础,强调了数据保护的法律合规性和权限管理的基本原则。本文还深入分析了权限守护的实现机制,探讨了如何配置和管理权限、执行权限审核与监控,以及进行应急响应和合规性报告。文章的高级应用部分讨论了多租户权
多租户架构模式:大学生就业平台系统设计与实现的深入探讨

# 摘要
本文首先介绍了多租户架构模式的概念及其优势,随后深入探讨了其理论基础,包括定义、分类和数据隔离策略。接着,文章转向大学生就业平台系统的需求分析,明确了功能、性能、可用性和安全性等方面的需求。在此基础上,详细阐述了系统架构设计与实现过程中的关键技术和实现方法,以及系统测试与评估结果。最后,针对大学生就业平台
FreeRTOS死锁:预防与解决的艺术

# 摘要
FreeRTOS作为一款流行的实时操作系统,其死锁问题对于嵌入式系统的稳定性和可靠性至关重要。本文首先概述了死锁的概念、产生条件及其理论基础,并探讨了预防死锁的传统理论方法,如资源请求策略、资源分配图和银行家算法。接下来,本文深入研究了FreeRTOS资源管理机制,包括
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )