使用flowable创建和管理工作流程实例
发布时间: 2023-12-25 10:27:55 阅读量: 94 订阅数: 30 
# 1. 简介
## 1.1 工作流程概述
在现代的商业和组织环境中,工作流程已成为组织和企业管理的关键要素之一。通过定义和自动化各种业务流程,工作流程可以提高效率、减少错误和延迟,并促进组织的协作和协调。
一个典型的工作流程由一系列有序的任务或活动组成,这些任务按照特定的规则和条件依次执行。每个任务都有一个责任人或参与者,他们负责根据任务定义的要求完成自己的工作。
工作流程可以应用于各种领域,如人力资源管理、采购流程、销售合同审批等。通过使用工作流程管理工具,如Flowable,可以轻松地设计、部署和管理各种工作流程,并提供灵活的配置选项和丰富的功能。
## 1.2 Flowable简介
Flowable是一个开源的工作流程引擎,它实现了BPMN 2.0规范,并提供了一套强大而灵活的工作流程管理功能。Flowable可以用于设计、执行和监控各种工作流程,支持流程定义、流程实例管理、任务分配和执行、流程变量管理等关键功能。
Flowable提供了丰富的API和工具,可以轻松地与现有系统集成,如Spring框架、Java EE、RESTful服务等。它还支持各种流程模型的创建和编辑,包括图形编辑器、XML定义和编程方式。
Flowable的特点包括:
- 高度可配置和可扩展性:可以根据需求进行灵活的配置和定制
- 松散耦合架构:可以与各种系统和技术进行集成
- 支持并行和串行流程:可以处理各种复杂的工作流程
- 简单而强大的API:可以简化开发和集成过程
- 可靠和可扩展的数据库支持:支持各种关系数据库和NoSQL数据库
下一节,我们将学习如何安装和配置Flowable框架。
# 2. 安装和配置Flowable
Flowable作为一个流程引擎,提供了便捷的安装和配置方式,本章将介绍如何进行Flowable的安装和配置。
### 2.1 安装Flowable框架
在开始安装之前,确保你的计算机上已经安装了Java环境。接下来,你可以按照以下步骤安装Flowable框架:
```shell
# 使用Maven安装
mvn archetype:generate \
-DarchetypeGroupId=org.flowable \
-DarchetypeArtifactId=flowable-archetype \
-DarchetypeVersion=6.5.0 \
-DgroupId=com.example \
-DartifactId=my-flowable-project \
-Dversion=1.0.0-SNAPSHOT
```
上述命令将利用Maven创建一个新的Flowable项目。你也可以使用其他构建工具或直接下载Flowable的JAR包进行安装。
### 2.2 配置数据库和启动Flowable服务
安装完成后,下一步是配置数据库和启动Flowable服务。Flowable支持多种数据库,包括MySQL、PostgreSQL、Oracle等。你可以根据自己的需求选择合适的数据库并进行相应的配置。
接着,通过以下步骤启动Flowable服务:
```java
import org.flowable.engine.ProcessEngine;
import org.flowable.engine.ProcessEngineConfiguration;
public class FlowableStarter {
public static void main(String[] args) {
ProcessEngineConfiguration cfg = ProcessEngineConfiguration.createStandaloneProcessEngineConfiguration()
.setJdbcUrl("jdbc:h2:mem:flowable;DB_CLOSE_DELAY=1000")
.setJdbcUsername("sa")
.setJdbcPassword("")
.setJdbcDriver("org.h2.Driver")
.setDatabaseSchemaUpdate(ProcessEngineConfiguration.DB_SCHEMA_UPDATE_TRUE);
ProcessEngine processEngine = cfg.buildProcessEngine();
}
}
```
以上代码演示了如何使用Java代码配置并启动一个基于H2数据库的Flowable引擎。你也可以根据实际情况进行配置,比如切换到其他数据库、添加数据源等。
安装和配置完成后,你就可以开始使用Flowable来创建、部署和运行工作流程了。在接下来的章节中,我们将深入探讨如何创建工作流程并进行部署。
# 3. 创建工作流程
在Flowable中创建工作流程的过程可以分为以下步骤:
### 3.1 流程定义和模型
流程定义是工作流程的模板,它描述了工作流程的结构、节点和执行规则。在Flowable中,可以使用BPMN 2.0标准来定义流程。
```java
BpmnModel model = new BpmnModel();
Process process = new Process();
model.addProcess(process);
StartEvent startEvent = new StartEvent();
process.addFlowElement(startEvent);
UserTask userTask = new UserTask();
userTask.setName("Handle Request");
userTask.setAssignee("${assignee}");
process.addFlowElement(userTask);
EndEvent endEvent = new EndEvent();
process.addFlowElement(endEvent);
SequenceFlow flow1 = new SequenceFlow();
flow1.setSourceRef(startEvent.getId());
flow1.setTargetRef(userTask.getId());
process.addFlowElement(flow1);
SequenceFlow flow2 = new SequenceFlow();
flow2.setSourceRef(userTask.getId());
flow2.setTargetRef(endEvent.getId());
process.addFlowElement(flow2);
Deployment deployment = repositoryService.createDeployment()
.addBpmnModel("myProcess.bpmn", model)
.deploy();
```
在上述代码中,我们首先创建一个`BpmnModel`对象,并添加一个`Process`对象用于描述流程。然后,我们创建了起始事件`StartEvent`和结束事件`EndEvent`,并使用`UserTask`表示一个任务节点。最后,我们使用`SequenceFlow`定义流程的执行路径,并将流程定义部署到Flowable引擎中。在实际应用中,可以根据具体需求来定义更复杂的流程模型。
### 3.2 设计任务和流程节点
在Flowable中,任务代表了工作流程中需要执行的具体操作。可以使用代码来创建任务并指定执行人。
```java
TaskService taskService = processEngine.getTaskService();
Task task = taskService.newTask();
task.setName("Handle Request");
task.setAssignee("user1");
taskService.saveTask(task);
```
在上述代码中,我们首先获取`TaskService`对象,然后创建一个新的任务对象`Task`。我们使用`setName()`方法设置任务的名称,使用`setAssignee()`方法指定任务的执行人,并使用`saveTask()`方法保存任务到Flowable引擎中。
在Flowable中,流程节点代表了工作流程中的每一个步骤或者决策点。可以使用代码来创建流程节点并定义节点的属性。
```java
FlowElementService flowElementService = processEngine.getRuntimeService().getFlowElementService();
FlowElement flowElement = flowElementService.newFlowElement();
flowElement.setName("Approve Request");
flowElement.setDescription("This node is used to approve the request");
flowElementService.saveFlowElement(flowElement);
```
在上述代码中,我们首先获取`FlowElementService`对象,然后创建一个新的流程节点对象`FlowElement`。我们使用`setName()`方法设置节点的名称,使用`setDescription()`方法设置节点的描述,并使用`saveFlowElement()`方法保存节点到Flowable引擎中。
### 3.3 定义流程变量和表单
在Flowable中,流程变量用于在工作流程中传递和存储数据。可以使用代码来定义流程变量并设置变量的值。
```java
VariableService variableService = processEngine.getRuntimeService().getVariableService();
variableService.setVariable(processInstanceId, "requestId", "12345");
variableService.setVariable(processInstanceId, "status", "pending");
```
在上述代码中,我们首先获取`VariableService`对象,然后使用`setVariable()`方法定义流程变量。我们使用`processInstanceId`表示流程实例的唯一标识,使用`"requestId"`和`"status"`表示变量的名称,使用`"12345"`和`"pending"`表示变量的值。
流程表单用于收集和展示用户输入的数据。可以使用代码来创建和配置流程表单。
```java
FormService formService = processEngine.getFormService();
FormData formData = formService.createFormData(formDefinitionId);
formData.setVariable("username", "user1");
formData.setVariable("password", "password123");
formService.saveFormData(formData);
```
在上述代码中,我们首先获取`FormService`对象,然后使用`createFormData()`方法创建一个新的表单数据对象`FormData`。我们使用`formDefinitionId`表示表单定义的唯一标识,使用`setVariable()`方法定义表单的字段和对应的值,最后使用`saveFormData()`方法保存表单数据到Flowable引擎中。
通过上述步骤,我们可以使用Flowable来创建工作流程,定义任务和流程节点,并定义流程变量和表单字段。在接下来的章节中,我们将介绍如何部署和运行工作流程。
# 4. 部署和运行工作流程
在前面已经完成了工作流程的设计和定义,接下来我们需要将工作流程部署到Flowable中并启动工作流实例。本章将介绍如何部署流程定义、启动流程实例以及执行和管理工作流任务。
### 4.1 部署流程定义
在Flowable中,部署流程定义是指将定义好的流程模型和相关资源上传至Flowable引擎以供使用。流程定义文件通常是一份XML格式的文件,其中包含了流程中的节点、连线、监听器以及相关的流程变量和表单等信息。
下面是一个简单的示例,展示了如何使用Flowable API来部署流程定义:
```java
// 创建一个流程引擎
ProcessEngine processEngine = ProcessEngineConfiguration.createStandaloneProcessEngineConfiguration().buildProcessEngine();
// 获取RepositoryService
RepositoryService repositoryService = processEngine.getRepositoryService();
// 部署流程定义
Deployment deployment = repositoryService.createDeployment()
.addClasspathResource("my-process.bpmn20.xml")
.deploy();
// 输出部署信息
System.out.println("流程定义ID:" + deployment.getId());
System.out.println("流程定义名称:" + deployment.getName());
```
上述示例代码中,我们首先创建了一个流程引擎实例,然后通过流程引擎的`getRepositoryService()`方法获取到`RepositoryService`实例。`RepositoryService`是Flowable用来管理流程定义和部署的服务对象。
接下来,我们使用`RepositoryService`对象的`createDeployment()`方法创建一个新的流程部署,并通过`addClasspathResource()`方法指定了流程定义文件。最后,调用`deploy()`方法将流程定义部署到Flowable引擎中。
部署成功后,我们可以通过`Deployment`对象获取到相关的部署信息,如部署ID和名称。
### 4.2 启动流程实例
一旦我们成功部署了流程定义,就可以使用Flowable来启动流程实例了。流程实例是定义好的流程模型的一次具体执行,每个流程实例都有一个唯一的ID。
下面的示例展示了如何使用Flowable API来启动一个流程实例:
```java
// 获取RuntimeService
RuntimeService runtimeService = processEngine.getRuntimeService();
// 启动流程实例
ProcessInstance processInstance = runtimeService.startProcessInstanceByKey("myProcess");
// 输出流程实例ID
System.out.println("流程实例ID:" + processInstance.getId());
```
在上述示例中,我们首先通过流程引擎获取到`RuntimeService`实例,`RuntimeService`用于操作和管理运行中的流程实例。
然后,我们使用`runtimeService`的`startProcessInstanceByKey()`方法启动了一个流程实例。这里的`"myProcess"`是我们之前部署的流程定义的Key值。
启动流程实例后,我们可以通过`ProcessInstance`对象获取到相关的流程实例信息,如流程实例ID。
### 4.3 执行和管理流程任务
当流程实例启动后,流程会按照定义好的节点顺序执行,并生成相应的任务。任务是流程中的一个环节,通常需要由特定的参与者完成。
下面的示例展示了如何使用Flowable API来执行和管理流程任务:
```java
// 获取TaskService
TaskService taskService = processEngine.getTaskService();
// 查询流程任务
List<Task> tasks = taskService.createTaskQuery().taskAssignee("user1").list();
// 完成任务
for (Task task : tasks) {
System.out.println("任务ID:" + task.getId());
// 根据业务需求完成任务
taskService.complete(task.getId());
}
```
在上述示例中,我们通过流程引擎获取到`TaskService`对象,`TaskService`用于操作和管理流程任务。
首先,我们使用`taskService`的`createTaskQuery()`方法查询分配给特定参与者("user1")的所有流程任务,并将结果保存在`List<Task>`中。
接下来,我们遍历任务列表,并通过`complete()`方法完成任务。在实际业务中,需要根据具体需求来完成任务的处理。
以上示例展示了如何使用Flowable来部署流程定义、启动流程实例以及执行和管理流程任务。通过这些步骤,我们能够有效地管理和跟踪工作流程的执行情况。
# 5. 监控和优化工作流程
在工作流程的运行过程中,监控和优化是非常重要的环节。Flowable提供了一些功能和工具,帮助我们监控和优化工作流程的性能和效率。
### 5.1 监控流程实例状态
通过Flowable提供的API,我们可以获取工作流程实例的状态信息,以便实时监控流程的执行情况和进度。以下是一个示例代码,展示如何获取流程实例的状态信息:
```java
ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();
RuntimeService runtimeService = processEngine.getRuntimeService();
List<ProcessInstance> processInstances = runtimeService.createProcessInstanceQuery()
.processDefinitionKey("myProcess")
.list();
for (ProcessInstance processInstance : processInstances) {
String processInstanceId = processInstance.getId();
String processDefinitionId = processInstance.getProcessDefinitionId();
String processInstanceName = processInstance.getName();
Date startTime = processInstance.getStartTime();
Date endTime = processInstance.getEndTime();
String processInstanceStatus = processInstance.isEnded() ? "已结束" : "进行中";
System.out.println("流程实例ID:" + processInstanceId);
System.out.println("流程定义ID:" + processDefinitionId);
System.out.println("流程实例名称:" + processInstanceName);
System.out.println("开始时间:" + startTime);
System.out.println("结束时间:" + endTime);
System.out.println("状态:" + processInstanceStatus);
System.out.println("-------------------");
}
```
上述代码中,我们使用了Flowable的RuntimeService来创建一个流程实例查询,通过指定流程定义的Key来获取该流程的所有实例。然后,我们遍历流程实例列表,获取每个实例的相关信息,比如流程实例ID、流程定义ID、流程实例名称、开始时间、结束时间以及状态。最后,我们将这些信息打印出来。
### 5.2 分析流程性能和效率
除了实时监控流程实例的状态,我们还可以通过Flowable提供的历史数据查询功能来进行流程性能和效率的分析。Flowable的HistoryService可以帮助我们获取流程的历史数据,如任务执行时间、任务耗时、任务完成情况等。
以下是一个示例代码,展示如何获取历史任务数据并计算任务平均耗时:
```java
ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();
HistoryService historyService = processEngine.getHistoryService();
List<HistoricTaskInstance> historicTasks = historyService.createHistoricTaskInstanceQuery()
.taskCompleted()
.orderByHistoricTaskInstanceStartTime()
.asc()
.list();
long totalDuration = 0;
int completedTasks = 0;
for (HistoricTaskInstance historicTask : historicTasks) {
long startTime = historicTask.getStartTime().getTime();
long endTime = historicTask.getEndTime().getTime();
long duration = endTime - startTime;
totalDuration += duration;
completedTasks++;
}
double averageDuration = totalDuration / completedTasks;
System.out.println("任务总耗时:" + totalDuration + " 毫秒");
System.out.println("完成任务数:" + completedTasks);
System.out.println("平均任务耗时:" + averageDuration + " 毫秒");
```
上述代码中,我们使用了Flowable的HistoryService创建一个历史任务实例查询,通过指定已完成的任务来获取历史任务数据。然后,我们遍历历史任务列表,计算每个任务的耗时,并累加到总耗时和完成任务数中。最后,我们计算平均任务耗时并打印出来。
### 5.3 优化工作流程设计
除了监控流程的状态和性能,我们还可以通过优化工作流程的设计来提高性能和效率。以下是一些优化工作流程设计的方法:
- 简化流程:根据实际业务需求,去除不必要的环节和冗余的操作,使流程更加简洁和高效。
- 并行处理:将互不依赖的任务设计为并行处理,以提高流程的并发度和处理能力。
- 优化资源分配:通过合理分配任务和资源,提高工作效率和资源利用率。
- 自动化流程:将重复性的操作和判断自动化,减少人工干预,提高流程的自动化水平。
通过以上优化方法,我们可以不断改进工作流程的设计,使其更加符合实际需求,提高工作效率和质量。
总结:
本章介绍了如何使用Flowable来监控和优化工作流程。我们学习了如何获取流程实例的状态信息,以及如何通过历史数据查询来分析流程的性能和效率。此外,我们还介绍了一些优化工作流程设计的方法,帮助我们改进流程的效率和质量。通过监控和优化工作流程,我们可以及时发现问题并采取措施,以达到更好的工作流程管理效果。
# 6. 其他功能和扩展
在本章中,我们将探讨Flowable的其他功能和扩展,以及如何与其他系统进行集成。
#### 6.1 定时任务和提醒
Flowable提供了定时任务和提醒的功能,可以让用户在流程中设置定时触发的任务或提醒。通过Flowable的定时任务和提醒功能,用户可以实现例如定时审批提醒、超时任务处理等功能。
示例代码(Java):
```java
// 创建定时任务
TimerJobEntity timerJob = ManagementService.createTimerJobQuery().processInstanceId(processInstanceId).singleResult();
if (timerJob != null) {
Date dueDate = timerJob.getDuedate();
// 设置定时提醒
ReminderService.createReminder().processInstanceId(processInstanceId).dueDate(dueDate).message("您有一个待办任务即将到期!").send();
}
```
#### 6.2 集成表单和数据驱动
Flowable可以集成表单和数据驱动,通过Flowable的表单功能,用户可以定义流程表单并且实现数据驱动的流程。这使得用户可以根据具体的业务需求,灵活地设计流程表单和实现数据驱动的流程操作。
示例代码(JavaScript):
```javascript
// 定义流程表单
var formDefinition = {
key: 'leaveRequestForm',
fields: [
{
type: 'textfield',
label: '请假原因',
key: 'reason',
placeholder: '请输入请假原因',
required: true
},
{
type: 'datepicker',
label: '开始日期',
key: 'startDate',
required: true
},
{
type: 'datepicker',
label: '结束日期',
key: 'endDate',
required: true
}
]
};
```
#### 6.3 与其他系统的集成
Flowable可以与其他系统进行集成,例如与企业内部的ERP、CRM系统进行集成,实现数据的互通和业务流程的协同。通过Flowable的集成功能,可以实现流程中的自动化操作,并且与其他系统之间实现数据的交换和共享。
示例代码(Python):
```python
# 与其他系统集成示例
import requests
def callExternalSystem(data):
url = 'http://external-system/api/trigger'
headers = {'Content-Type': 'application/json'}
response = requests.post(url, headers=headers, json=data)
return response.json()
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以"flowable"为主题,覆盖了流程引擎的各个方面,包括BPMN 2.0流程建模与定义、工作流程实例的创建和管理、任务管理与分配技巧、表单设计与集成、事件管理与监听器、流程执行与优化、流程版本控制与部署策略、权限管理与安全策略、微服务架构的集成与实践、任务调度与执行管理、数据处理与业务规则建模、跨部门协作中的应用与实践、性能优化与扩展技巧、事件驱动流程设计与实现、现有系统集成的最佳实践以及日志与监控管理。通过深入介绍flowable在企业中的应用与实践,旨在帮助读者全面了解流程引擎的各个方面,掌握flowable的使用技巧,提升工作效率,构建灵活的工作流程应用,并最大化流程引擎的价值。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【实战演练】综合案例:数据科学项目中的高等数学应用

# 1. 数据科学项目中的高等数学基础**
高等数学在数据科学中扮演着至关重要的角色,为数据分析、建模和优化提供了坚实的理论基础。本节将概述数据科学
【实战演练】通过强化学习优化能源管理系统实战
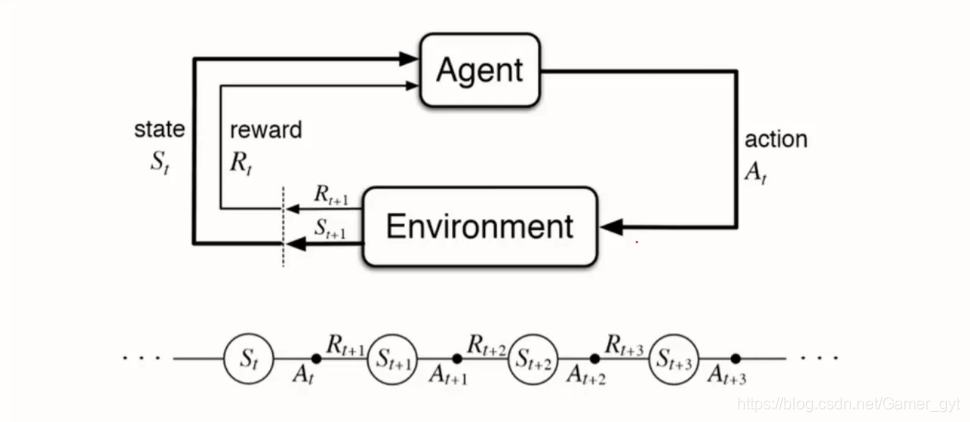
# 2.1 强化学习的基本原理
强化学习是一种机器学习方法,它允许智能体通过与环境的交互来学习最佳行为。在强化学习中,智能体通过执行动作与环境交互,并根据其行为的
【实战演练】python云数据库部署:从选择到实施
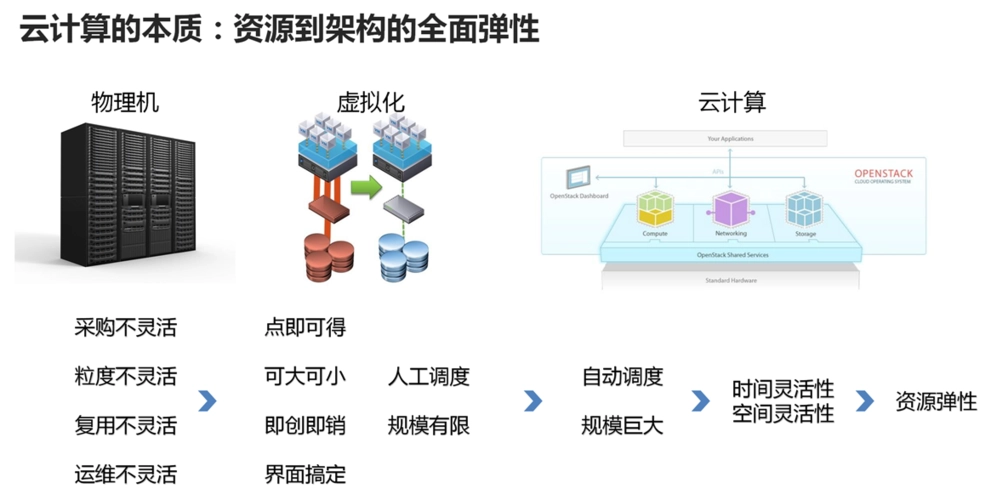
# 2.1 云数据库类型及优劣对比
**关系型数据库(RDBMS)**
* **优点:**
* 结构化数据存储,支持复杂查询和事务
* 广泛使用,成熟且稳定
* **缺点:**
* 扩展性受限,垂直扩展成本高
* 不适合处理非结构化或半结构化数据
**非关系型数据库(NoSQL)**
* **优点:**
* 可扩展性强,水平扩展成本低
【实战演练】深度学习在计算机视觉中的综合应用项目

# 1. 计算机视觉概述**
计算机视觉(CV)是人工智能(AI)的一个分支,它使计算机能够“看到”和理解图像和视频。CV 旨在赋予计算机人类视觉系统的能力,包括图像识别、对象检测、场景理解和视频分析。
CV 在广泛的应用中发挥着至关重要的作用,包括医疗诊断、自动驾驶、安防监控和工业自动化。它通过从视觉数据中提取有意义的信息,为计算机提供环境感知能力,从而实现这些应用。
# 2.1 卷积
【实战演练】时间序列预测项目:天气预测-数据预处理、LSTM构建、模型训练与评估

# 1. 时间序列预测概述**
时间序列预测是指根据历史数据预测未来值。它广泛应用于金融、天气、交通等领域,具有重要的实际意义。时间序列数据通常具有时序性、趋势性和季节性等特点,对其进行预测需要考虑这些特性。
# 2. 数据预处理
### 2.1 数据收集和清洗
#### 2.1.1 数据源介绍
时间序列预测模型的构建需要可靠且高质量的数据作为基础。数据源的选择至关重要,它将影响模型的准确性和可靠性。常见的时序数据源包括:
【实战演练】python远程工具包paramiko使用
# 1. Python远程工具包Paramiko简介**
Paramiko是一个用于Python的SSH2协议的库,它提供了对远程服务器的连接、命令执行和文件传输等功能。Paramiko可以广泛应用于自动化任务、系统管理和网络安全等领域。
# 2. Paramiko基础
### 2.1 Paramiko的安装和配置
**安装 Paramiko**
```python
pip install
【实战演练】使用Python和Tweepy开发Twitter自动化机器人

# 1. Twitter自动化机器人概述**
Twitter自动化机器人是一种软件程序,可自动执行在Twitter平台上的任务,例如发布推文、回复提及和关注用户。它们被广泛用于营销、客户服务和研究等各种目的。
自动化机器人可以帮助企业和个人节省时间和精力,同时提高其Twitter活动的效率。它们还可以用于执行复杂的任务,例如分析推文情绪或
【实战演练】虚拟宠物:开发一个虚拟宠物游戏,重点在于状态管理和交互设计。

# 2.1 虚拟宠物的状态模型
### 2.1.1 宠物的基本属性
虚拟宠物的状态由一系列基本属性决定,这些属性描述了宠物的当前状态,包括:
- **生命值 (HP)**:宠物的健康状况,当 HP 为 0 时,宠物死亡。
- **饥饿值 (Hunger)**:宠物的饥饿程度,当 Hunger 为 0 时,宠物会饿死。
- **口渴
【实战演练】前沿技术应用:AutoML实战与应用

# 1. AutoML概述与原理**
AutoML(Automated Machine Learning),即自动化机器学习,是一种通过自动化机器学习生命周期
【实战演练】使用Docker与Kubernetes进行容器化管理
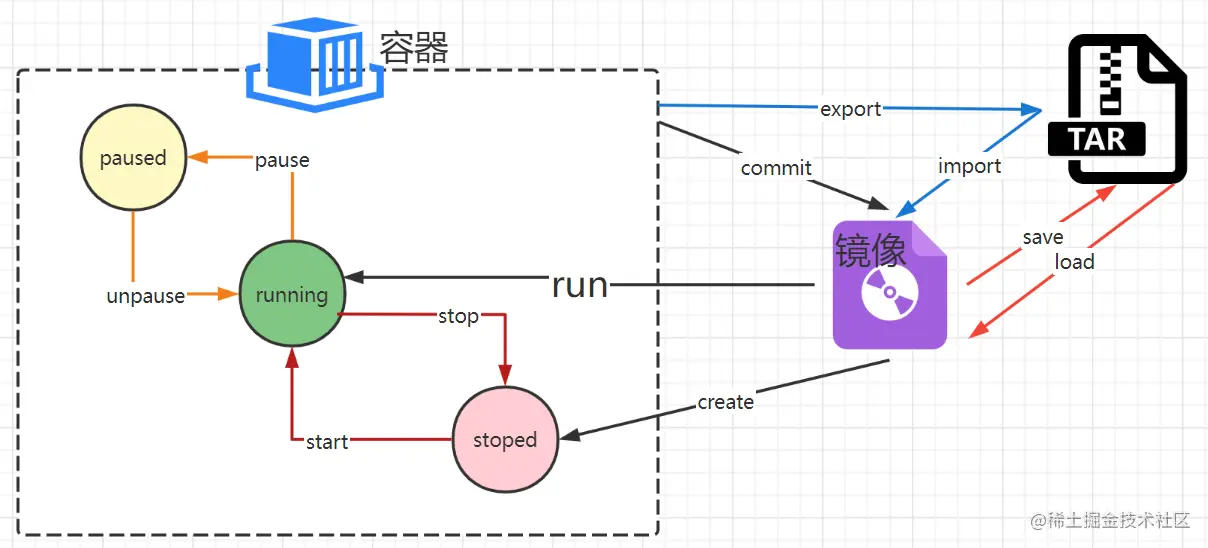
# 2.1 Docker容器的基本概念和架构
Docker容器是一种轻量级的虚拟化技术,它允许在隔离的环境中运行应用程序。与传统虚拟机不同,Docker容器共享主机内核,从而减少了资源开销并提高了性能。
Docker容器基于镜像构建。镜像是包含应用程序及
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )