Python for循环:从陷阱到高级应用的完整指南
发布时间: 2024-09-19 01:36:18 阅读量: 60 订阅数: 22 

Python编程中列表推导式的深度解析及实战应用详解
# 1. Python for循环基础
## 简介
Python中的for循环是编程的核心概念之一,它允许我们遍历序列中的每个元素,无论是字符串、列表、元组还是字典。在本章节中,我们将介绍Python for循环的基本用法,包括语法结构和最常见的应用场景。
## 基本语法
for循环的基本语法如下:
```python
for variable in sequence:
# 执行代码块
```
`variable`是每次迭代中序列`sequence`的当前元素值,`sequence`代表任何有序的序列对象。
## 示例代码
让我们通过一个简单的例子来理解for循环的用法。假设我们需要打印一个字符串列表中的每个名字:
```python
names = ['Alice', 'Bob', 'Charlie']
for name in names:
print(name)
```
这段代码会按顺序打印列表`names`中的每个名字。在接下来的章节中,我们将探讨for循环的高级用法,以及如何优化其性能和应用。
# 2. for循环的高级用法
## 2.1 迭代器和生成器的使用
### 2.1.1 迭代器的概念和特点
迭代器是支持迭代的对象,能够记住遍历的位置,可以使用`next()`函数和`for`循环进行访问。迭代器有以下几个显著特点:
- **状态保存**:迭代器能够记住遍历过程中的状态,即它们知道它们已经遍历到哪个位置了。
- **延迟计算**:迭代器只有在需要时才会计算下一个元素,这意味着它们可以用于潜在的无限序列。
- **内存效率**:由于迭代器不会一次性将所有值加载到内存中,因此它们在处理大数据集时非常高效。
迭代器是实现for循环的核心组件,通过迭代器,我们可以顺序访问容器中的每个元素,而无需了解容器的内部实现。
### 2.1.2 生成器的创建和优势
生成器是一种特殊的迭代器,通过使用关键字`yield`来定义函数,函数在每次调用时会返回一个值,而不是一次性返回一个列表。
生成器的优势包括:
- **按需产生值**:生成器一次产生一个值,只在需要时才计算,这使得它们对于大数据集非常有用。
- **节省内存**:与列表不同,生成器不会将所有值存储在内存中,因此可以使用较小的内存处理大型数据集。
- **简化代码**:生成器表达式是一种简洁的语法,用于创建生成器,使其在代码中使用更加方便。
下面是一个简单的生成器示例:
```python
def count_up_to(max_value):
count = 1
while count <= max_value:
yield count
count += 1
# 使用生成器
for number in count_up_to(5):
print(number)
```
这个生成器会逐个产生从1到5的数字。
### 2.1.3 使用生成器表达式简化代码
生成器表达式是列表推导的迭代器版本,具有类似`[x*x for x in range(10)]`的列表推导形式,但使用圆括号`()`而非方括号`[]`。
生成器表达式的优势在于它们可以提高内存效率,特别是当处理大量数据时。
例如:
```python
# 列表推导
squares = [x*x for x in range(10)]
# 生成器表达式
squares_gen = (x*x for x in range(10))
```
使用生成器表达式时,我们不需要一次性将所有平方数加载到内存中,我们可以按需逐个产生它们。
## 2.2 for循环中的异常处理
### 2.2.1 常见的迭代异常和避免策略
在使用for循环进行迭代时,常见的异常包括`StopIteration`和`IndexError`。`StopIteration`会在迭代器没有更多元素时抛出,而`IndexError`通常出现在访问不存在的索引时。
为了避免这些异常,我们可以采取以下策略:
- 使用`try-except`块来捕获并处理异常。
- 在迭代之前检查集合的长度或范围。
- 当使用索引迭代时,确保索引值在合法范围内。
下面是一个处理`StopIteration`异常的例子:
```python
iterator = iter([1, 2, 3])
try:
while True:
print(next(iterator))
except StopIteration:
print("迭代完成")
```
### 2.2.2 自定义异常处理机制
在特定场景下,我们可能需要创建自定义的异常处理机制。自定义异常处理有助于处理循环中出现的特定错误情况。
可以通过定义新的异常类来实现这一点,然后在适当的时机抛出这些异常。
```python
class MyCustomError(Exception):
"""自定义迭代错误类"""
def __init__(self, message):
super().__init__(message)
iterator = iter([1, 2, 3])
try:
while True:
value = next(iterator)
if value == 2:
raise MyCustomError("遇到不想要的值")
except MyCustomError as e:
print(f"捕获到自定义异常:{e}")
except StopIteration:
print("迭代完成")
```
在这个例子中,当迭代到值2时,程序会抛出自定义的`MyCustomError`异常。
### 2.2.3 异常与循环控制结构的结合使用
结合使用异常和循环控制结构(如`break`和`continue`)可以实现更复杂的控制逻辑。
例如,我们可以在出现特定异常时使用`break`跳出循环,或者使用`continue`跳过当前迭代中的剩余代码。
```python
for value in range(10):
if value == 5:
continue # 跳过值为5的情况
if value > 7:
break # 超过7时停止循环
print(value)
```
在这个例子中,循环会在打印出0到4的值后继续执行,但当值达到5时,`continue`会跳过打印,直接继续下一次迭代。一旦值超过7,`break`将终止循环。
## 2.3 多重循环和循环嵌套
### 2.3.1 多重循环的性能影响
多重循环(多重for循环)可以用于实现更复杂的迭代逻辑。然而,它们的性能影响不容忽视。随着循环层数的增加,总体执行时间和内存消耗也会随之增加。
一些减少性能影响的策略包括:
- 尽量减少循环层数。
- 使用更高效的数据结构。
- 优化算法逻辑,减少不必要的计算。
在多重循环中,应当特别注意循环的控制条件,避免逻辑错误导致无限循环的发生。
### 2.3.2 循环嵌套的艺术和最佳实践
循环嵌套要求程序员对循环之间的依赖和执行顺序有清晰的理解。嵌套循环的艺术在于:
- 理解每一层循环的作用。
- 确保循环的执行效率和逻辑正确性。
- 采用可读性和可维护性更高的结构。
最佳实践包括:
- 将循环逻辑拆分成独立的函数,以提高代码的复用性和可读性。
- 尽量避免过深的循环嵌套,这可能会降低代码的可读性。
### 2.3.3 降低复杂度的技术和技巧
在处理复杂循环时,降低复杂度是关键。降低循环复杂度的方法包括:
- **循环分解**:将复杂循环分解成多个简单循环。
- **使用内置函数和库**:利用Python的内置函数和标准库来替代复杂的自定义循环。
- **向量化**:在可能的情况下,使用向量化操作替代循环。
例如,列表推导式可以替代简单的循环,以更简洁的方式实现相同的功能:
```python
squares = [x*x for x in range(10)]
```
这种方式比手动编写循环更加高效和简洁。
# 3. for循环在数据处理中的应用
在现代编程实践中,数据处理是一个重要的环节。Python的for循环以其简洁性和表达力,在数据遍历、筛选、聚合等方面表现出色。本章将详细介绍for循环在这些方面的应用,并提供一些实用技巧和最佳实践。
## 3.1 遍历数据结构
Python中的数据结构包括列表、字典、集合等,for循环可以方便地遍历这些数据结构,以提取或操作数据。
### 3.1.1 列表、字典和集合的遍历技巧
列表是Python中最常见的数据结构,用于存储序列化数据。for循环遍历列表时,可以访问每一个元素。
```python
# 列表遍历示例
fruits = ['apple', 'banana', 'cherry']
for fruit in fruits:
print(fruit)
```
字典存储键值对,for循环可以遍历字典中的键或值。
```python
# 字典遍历示例
person = {'name': 'Alice', 'age': 25, 'city': 'New York'}
for key in person:
print(f"Key: {key}, Value: {person[key]}")
```
集合是一个无序的、不重复的元素集。for循环可以遍历集合。
```python
# 集合遍历示例
unique_numbers = {1, 2, 3, 4, 5}
for number in unique_numbers:
print(number)
```
### 3.1.2 使用zip和map函数优化遍历
`zip`函数可以将多个列表组合成一个迭代器,而`map`函数可以将指定函数应用于给定序列的每个项并返回一个迭代器。使用这些函数可以使遍历过程更加高效。
```python
# 使用zip结合for循环同时遍历多个列表
fruits = ['apple', 'banana', 'cherry']
prices = [1.5, 2.5, 3.0]
for fruit, price in zip(fruits, prices):
print(f"{fruit}: ${price}")
# 使用map函数处理数据
numbers = [1, 2, 3, 4, 5]
squared_numbers = map(lambda x: x ** 2, numbers)
for number in squared_numbers:
print(number)
```
## 3.2 数据筛选和过滤
数据筛选和过滤是数据处理的重要组成部分。for循环可以结合列表推导式或生成器来实现高效的数据筛选。
### 3.2.1 利用列表推导式进行数据筛选
列表推导式是Python中一种简洁的创建列表的方法。它们同样可以用于筛选符合特定条件的元素。
```python
# 使用列表推导式进行数据筛选
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
even_numbers = [num for num in numbers if num % 2 == 0]
print(even_numbers)
```
### 3.2.2 使用生成器进行高效数据处理
生成器提供了一种“惰性求值”的方式,即数据只有在需要时才被计算。这种方式非常适合处理大数据集。
```python
# 使用生成器表达式进行数据筛选
def gen_range(n):
for i in range(n):
yield i
# 使用生成器表达式进行数据筛选
even_numbers_gen = (x for x in gen_range(10) if x % 2 == 0)
for num in even_numbers_gen:
print(num)
```
## 3.3 数据聚合和统计
for循环在数据聚合和统计任务中也非常重要。无论是在数据统计、计数还是求和等聚合操作中,for循环都可以提供强大的支持。
### 3.3.1 for循环在数据统计中的应用
数据统计通常涉及计算某些值的总和、平均值、最大值和最小值等。
```python
# for循环用于数据统计
numbers = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
sum_numbers = 0
for num in numbers:
sum_numbers += num
print(f"The sum of the numbers is: {sum_numbers}")
```
### 3.3.2 高级数据聚合技术简介
对于更复杂的统计任务,可以结合使用for循环和Python的其他库,如NumPy和Pandas,来处理大规模数据集。
```python
import numpy as np
# 使用NumPy进行数据聚合
numbers_array = np.array(numbers)
print(f"Average of the numbers is: {np.mean(numbers_array)}")
```
通过本章节的介绍,我们了解了for循环在数据处理中的多种应用。下一章将继续探讨for循环的性能优化与调试技巧,以确保代码在处理大量数据时既高效又稳定。
# 4. for循环的性能优化与调试
## 4.1 代码优化策略
### 4.1.1 计算表达式的优化方法
Python的for循环在处理大量数据时,计算表达式的效率直接影响到程序的性能。在进行代码优化时,我们应该重视减少不必要的计算和优化计算表达式。
举一个简单的例子,在遍历列表的过程中,可能会用到列表的长度,一种常见的做法是每次循环都调用len()函数来获取长度。但是,如果列表长度不变,将其计算一次并存储到一个变量中,可以减少循环的开销。
```python
# 未优化的代码示例
for i in range(len(some_list)):
# 循环体内容
# 优化后的代码示例
length = len(some_list)
for i in range(length):
# 循环体内容
```
在这个优化例子中,我们避免了每次循环都进行一次len()调用,这在处理大列表时能显著减少不必要的计算。
### 4.1.2 优化循环的执行时间和内存使用
在Python中,循环的优化还包括减少内存消耗,尤其是当处理大量数据时。一个常见的优化是使用生成器表达式替代列表推导式。列表推导式会立即计算出完整的列表,而生成器表达式则在需要时才计算下一个值,从而节省内存。
```python
# 列表推导式
my_list = [x**2 for x in range(1000000)]
# 生成器表达式
my_generator = (x**2 for x in range(1000000))
```
以上例子中,列表推导式会立即创建一个有100万项的列表,这会消耗大量内存。而生成器表达式创建的是一个生成器对象,它仅在迭代时才计算每个x的平方,大大减少了内存占用。
### 4.1.3 总结
在编写for循环时,对计算表达式的优化以及循环执行时间和内存使用的优化,是提高程序性能的关键。理解Python的内部机制,知道何时以及如何使用生成器等优化手段,可以显著提升代码效率。这样的优化工作往往是逐步进行的,开发者需要通过分析代码逻辑,找到可能的性能瓶颈,然后采取合适的优化策略。
# 5. for循环的高级案例分析
在深入探讨了Python for循环的基础和高级用法后,我们将聚焦于将这些概念应用于解决实际问题。本章节将深入分析一些高级案例,将for循环与其他Python特性结合,并探讨for循环在复杂环境中的应用。这包括文件系统遍历、复杂数据结构处理以及与其他Python特性的结合,如上下文管理器和装饰器。
## 5.1 文件和目录遍历实战
在处理文件和目录时,能够高效地遍历文件系统是至关重要的。Python提供了一些内置库,如`os`和`pathlib`,可以用来实现文件系统遍历。本小节将展示如何使用for循环遍历文件系统,并介绍递归遍历目录的策略。
### 5.1.1 遍历文件系统的最佳实践
遍历文件系统时,一个最佳实践是尽量减少对文件系统的调用次数。对于简单的遍历任务,我们可以使用`os.walk`或`pathlib.Path.rglob`方法。下面是一个使用`os.walk`遍历指定目录下所有文件和子目录的例子:
```python
import os
def traverse_directory(directory):
for root, dirs, files in os.walk(directory):
for name in files:
print(os.path.join(root, name))
```
在上述代码中,`os.walk`生成一个3元组(root, dirs, files),其中root是当前目录的路径,dirs是其子目录列表,files是其文件列表。通过遍历这三个列表,我们可以访问文件系统中的每一个文件和目录。
### 5.1.2 实现递归目录遍历的策略
对于更复杂的目录结构,可能需要使用递归函数来遍历。递归允许我们在每个子目录中重复执行相同的遍历任务。下面是一个递归遍历目录的函数实现:
```python
import os
def recursive_traverse(directory):
for entry in os.listdir(directory):
path = os.path.join(directory, entry)
if os.path.isdir(path):
recursive_traverse(path) # 递归遍历子目录
else:
print(path) # 打印文件路径
# 调用函数
recursive_traverse('/path/to/directory')
```
递归函数需要一个终止条件来避免无限递归,通常这个条件是检查子路径是否为目录。如果当前路径是一个目录,则函数调用自身,对子目录执行同样的操作。
### 表格展示遍历方法对比
| 方法 | 使用场景 | 优势 | 劣势 |
| --- | --- | --- | --- |
| os.walk | 简单遍历 | 编写简单,跨平台兼容 | 频繁调用系统API,效率较低 |
| pathlib.Path.rglob | 使用新式API遍历 | 避免频繁系统调用,支持通配符 | 对Python版本有要求,需3.5以上 |
| 递归遍历 | 复杂目录结构 | 灵活处理多层目录 | 需手动管理递归深度,防止栈溢出 |
递归遍历方法虽然灵活,但是如果没有正确的终止条件,可能会导致栈溢出错误,特别是当目录层级非常深的时候。因此,当编写递归遍历函数时,应当特别注意递归深度的限制。
## 5.2 复杂数据结构处理
Python程序员经常会遇到复杂的数据结构,比如嵌套字典、列表中的列表等。处理这些结构往往需要使用到嵌套循环和条件判断。我们将探索如何高效地迭代嵌套数据结构,以及如何处理多维数据。
### 5.2.1 处理嵌套结构数据的技巧
嵌套的数据结构要求我们能够递归地遍历子结构。对于列表中的列表,我们可以使用嵌套的for循环:
```python
nested_list = [[1, 2, 3], [4, 5], [6, 7, 8]]
for sublist in nested_list:
for item in sublist:
print(item)
```
而对于字典中的嵌套字典,情况变得稍微复杂一些,但我们依旧可以使用嵌套循环:
```python
nested_dict = {
'a': {'x': 1, 'y': 2},
'b': {'z': 3}
}
for key, value in nested_dict.items():
for k, v in value.items():
print(f'{key}-{k}: {v}')
```
### 5.2.2 多维数据的迭代和处理方法
多维数据结构的迭代通常需要保持一个引用,记录当前的位置。我们可以使用堆栈(stack)或队列(queue)来存储当前的迭代状态,这样可以避免使用递归,减少栈溢出的风险。
使用列表的列表来模拟堆栈,下面是一个处理多维数据的通用方法:
```python
from collections import deque
def multi_dim_traverse(data):
stack = deque([data]) # 将数据压入栈中
while stack:
current = stack.pop()
if isinstance(current, list):
stack.extend(current) # 如果当前项是列表,则扩展栈
else:
print(current) # 处理基本数据类型
# 示例数据
matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
multi_dim_traverse(matrix)
```
在上述代码中,我们使用了一个双端队列(deque)来模拟堆栈的行为。每当我们遇到列表时,我们将其元素以相反的顺序压入堆栈中。这样可以保证我们总是按照正确的顺序处理数据。
## 5.3 for循环与其他Python特性的结合
Python提供了许多强大的特性,使得代码更加简洁和高效。本小节将探索for循环与其他Python特性的结合,比如使用上下文管理器简化文件操作和利用装饰器优化循环逻辑。
### 5.3.1 结合上下文管理器简化文件操作
上下文管理器允许我们控制资源的获取和释放,最常见的是文件操作。使用`with`语句可以确保文件在使用完毕后正确关闭,即使在文件操作过程中发生异常也是如此。下面是一个使用上下文管理器进行文件读写的例子:
```python
with open('example.txt', 'w') as ***
*** ["line 1\n", "line 2\n", "line 3\n"]:
file.write(line)
```
在上述代码中,`with`语句创建了一个上下文环境,`open`函数在这个环境中打开文件,并在代码块执行完毕后自动关闭文件。这使得文件操作更加安全和简洁。
### 5.3.2 利用装饰器和闭包优化循环逻辑
装饰器是Python中一个强大的特性,它允许我们修改或增强函数的行为而不需要修改函数本身。闭包是函数式编程中的一个概念,它允许函数记住并访问其定义时的作用域。下面是一个使用装饰器来记录函数执行时间和次数的例子:
```python
import functools
def timer(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
print(f'Function {func.__name__} took {end_time - start_time}s to execute')
return result
return wrapper
@timer
def count_loop(max_count):
for i in range(max_count):
pass
count_loop(1000000)
```
在上述代码中,`timer`函数是一个装饰器,它在被装饰的函数执行前后记录时间,并打印出执行时间。这个例子展示了如何使用装饰器来增强函数的功能,而不是改变函数的实际代码。
通过结合使用for循环和其他Python特性,我们可以创建出更为强大和灵活的代码。这不仅提高了代码的效率,也增强了其可读性和可维护性。
在本章节中,我们深入探讨了for循环的高级应用案例,从文件和目录遍历、处理复杂数据结构到与其他Python特性的结合使用。这些高级案例展示了for循环的强大功能和灵活性,能够帮助解决实际工作中的各种复杂问题。在下一章节中,我们将探究for循环的性能优化和调试技巧,进一步提升Python编程的效率和质量。
# 6. 探索for循环的未来趋势
在快速发展的IT行业中,编程语言及其特性也不断地在演进。Python作为一种广泛使用的编程语言,其for循环作为基础语言特性之一,也随着新版本的发布而不断优化和改进。同时,随着不同领域技术的发展,Python for循环的应用场景也在不断拓展。
## 6.1 Python新版本中的新特性
Python语言的每次更新都会带给我们新的特性,这些特性在提升代码效率、可读性的同时,也为for循环带来了新的可能性。
### 6.1.1 Python 3.x中for循环的改进
Python 3.x版本对for循环的改进主要体现在更加直观和安全的语法上。例如,Python 3.6引入了有序字典(`collections.OrderedDict`),使得在遍历字典时可以保持元素的插入顺序。这种改进对于数据处理中需要保持顺序的操作非常有用。
```python
from collections import OrderedDict
# Python 3.x 可以保持插入顺序
ordered_dict = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
for key in ordered_dict:
print(key, ordered_dict[key])
```
### 6.1.2 未来版本中可能的迭代器和循环改进
随着技术的发展,Python未来的版本可能会引入更多改进,例如,异步迭代器(async iterables)和异步生成器(async generators)可能会被加入到语言中,这将使得异步编程更加容易,尤其在处理I/O密集型任务时,异步循环能够带来显著的性能提升。
## 6.2 for循环与其他语言的比较
在编程的世界里,不同的语言有不同的循环结构。for循环作为最常见的结构之一,其在不同语言中的实现方式也各有特色。
### 6.2.1 不同编程语言中循环结构的对比
以Python、JavaScript和C++为例,我们可以看到不同语言中for循环的使用差异。在JavaScript中,for循环可以用来遍历对象的属性,而在C++中,我们可以使用范围for循环(基于范围的for循环)来遍历数组或其他容器。
```javascript
// JavaScript 中的对象遍历
let obj = {a: 1, b: 2, c: 3};
for (let key in obj) {
console.log(key, obj[key]);
}
```
```cpp
// C++ 中的范围for循环
std::vector<int> vec = {1, 2, 3};
for (int val : vec) {
std::cout << val << std::endl;
}
```
### 6.2.2 Python for循环的跨语言优势分析
Python for循环的优势在于其简洁和灵活性。Python的for循环可以很容易地与列表推导式、生成器表达式结合使用,实现数据的高效处理。同时,Python语言的可读性高,使得即使复杂的循环逻辑也容易被他人理解。
## 6.3 for循环在新兴领域的应用
技术的发展推动了编程语言的新应用场景。Python for循环因为其简洁和强大的数据处理能力,在新兴领域得到了广泛的应用。
### 6.3.1 在大数据和AI领域的应用前景
在大数据和AI领域,Python已经成为主流语言之一。for循环可以用于处理数据集,或者在机器学习模型训练过程中,对数据进行迭代。例如,在使用Pandas进行数据分析时,for循环可以帮助我们遍历DataFrame的每一行或列进行操作。
```python
import pandas as pd
# 使用Pandas读取CSV数据
df = pd.read_csv('data.csv')
# for循环遍历DataFrame的列
for col in df.columns:
print(col, df[col].sum())
```
### 6.3.2 Python for循环的教育和学习资源
教育和学习资源的丰富性也是Python for循环的一大优势。许多在线编程课程和书籍都将Python作为首选语言进行教授,其中for循环作为入门级知识点,受到了广泛关注。这些资源不仅包括基础语法,也覆盖了高级用法和最佳实践,使得学习者可以快速掌握for循环的使用。
```python
# 学习资源的一个例子
def learn_forex():
print("开始学习for循环...")
# 示例循环,用于教学目的
for i in range(5):
print(f"这是第{i+1}次迭代")
learn_forex()
```
通过本章的内容,我们可以预见for循环在Python编程中的未来趋势,以及它在不同领域中的潜在应用。随着技术的发展和更多编程语言特性的出现,for循环将继续演化,为程序员提供更加丰富和高效的编码选项。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到我们的专栏“for loop python”,在这里,我们将深入探讨 Python 中 for 循环的方方面面。从优化技巧到高级应用,再到并行处理、数据处理和内存管理,我们将为您提供全面的指南。您还将了解循环调试技巧、最佳实践、自定义迭代器、算法优化和封装复杂逻辑的方法。此外,我们还将探讨 Python 中变量作用域、数据结构和算法的实现策略,以及递归和迭代决策指南。通过本专栏,您将掌握使用 for 循环编写清晰、高效且可维护的 Python 代码所需的知识和技能。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
WinRAR CVE-2023-38831漏洞快速修复解决方案

# 摘要
本文详细阐述了WinRAR CVE-2023-38831漏洞的技术细节、影响范围及利用原理,并探讨了系统安全防护理论,包括安全防护层次结构和防御策略。重点介绍了漏洞快速检测与响应方法,包括使用扫描工具、风险评估、优先级划分和建立应急响应流程。文章进一步提供了WinRAR漏洞快速修复的实践
【QWS数据集实战案例】:深入分析数据集在实际项目中的应用
# 摘要
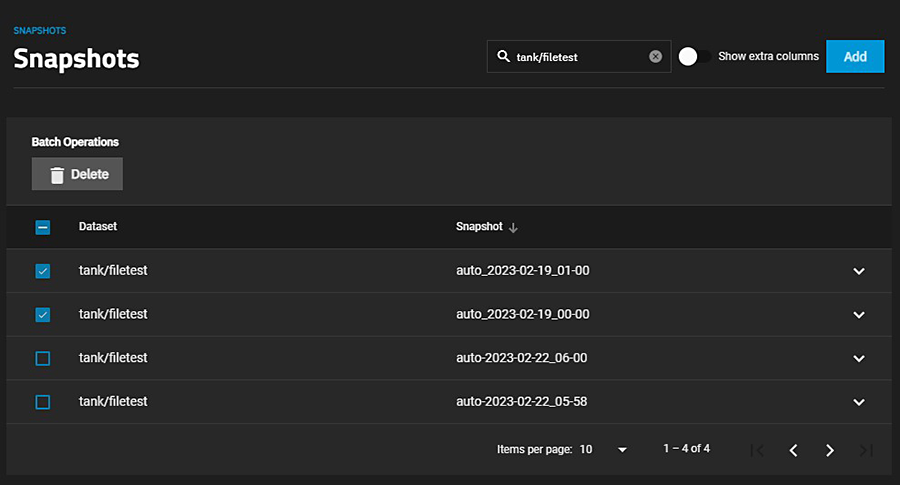
数据集是数据科学项目的基石,它在项目中的基础角色和重要性不可小觑。本文首先讨论了数据集的选择标准和预处理技术,包括数据清洗、标准化、特征工程等,为数据分析打下坚实基础。通过对QWS数据集进行探索性数据分析,文章深入探讨了统计分析、模式挖掘和时间序列分析,揭示了数据集内在的统计特性、关联规则以及时间依赖性。随后,本文分析了QWS数据集在金融、医疗健康和网络安全等特定领域的应用案例,展现了其在现实世界问题中
【跨平台远程管理解决方案】:源码视角下的挑战与应对
# 摘要
随着信息技术的发展,跨平台远程管理成为企业维护系统、提升效率的重要手段。本文首先介绍了跨平台远程管理的基础概念,随后探讨了在实施过程中面临的技术挑战,包括网络协议的兼容性、安全性问题及跨平台兼容性。通过实际案例分析,文章阐述了部署远程管理的前期准备、最佳实践以及性能优化和故障排查的重要性。进阶技术章节涵盖自动化运维、集群管理与基于云服务的远程管理。最后
边缘检测技术大揭秘:成像轮廓识别的科学与艺术

# 摘要
边缘检测技术是图像处理和计算机视觉领域的重要分支,对于识别图像中的物体边界、特征点以及进行场景解析至关重要。本文旨在概述边缘检测技术的理论基础,包括其数学模型和图像处理相关概念,并对各种边缘检测方法进行分类与对比。通过对Sobel算法和Canny边缘检测器等经典技术的实战技巧进行分析,探讨在实际应用中如何选择合适的边缘检测算法。同时,本文还将关注边缘检测技术的
Odroid XU4性能基准测试

# 摘要
Odroid XU4作为一款性能强大且成本效益高的单板计算机,其性能基准测试成为开发者和用户关注的焦点。本文首先对Odroid XU4硬件规格和测试环境进行详细介绍,随后深入探讨了性能基准测试的方法论和工具。通过实践测试,本文对CPU、内存与存储性能进行了全面分析,并解读了测试
TriCore工具使用手册:链接器基本概念及应用的权威指南

# 摘要
本文深入探讨了TriCore工具与链接器的原理和应用。首先介绍了链接器的基本概念、作用以及其与编译器的区别,然后详细解析了链接器的输入输出、链接脚本的基础知识,以及链接过程中的符号解析和内存布局控制。接着,本文着重于TriCore链接器的配置、优化、高级链
【硬件性能革命】:揭秘液态金属冷却技术对硬件性能的提升

# 摘要
液态金属冷却技术作为一种高效的热管理方案,近年来受到了广泛关注。本文首先介绍了液态金属冷却的基本概念及其理论基础,包括热传导和热交换原理,并分析了其与传统冷却技术相比的优势。接着,探讨了硬件性能与冷却技术之间的关系,以及液态金属冷却技术在实践应用中的设计、实现、挑战和对策。最后,本文展望了液态金属冷却技术的未来,包括新型材料的研究和技术创新的
【企业级测试解决方案】:C# Selenium自动化框架的搭建与最佳实践
# 摘要
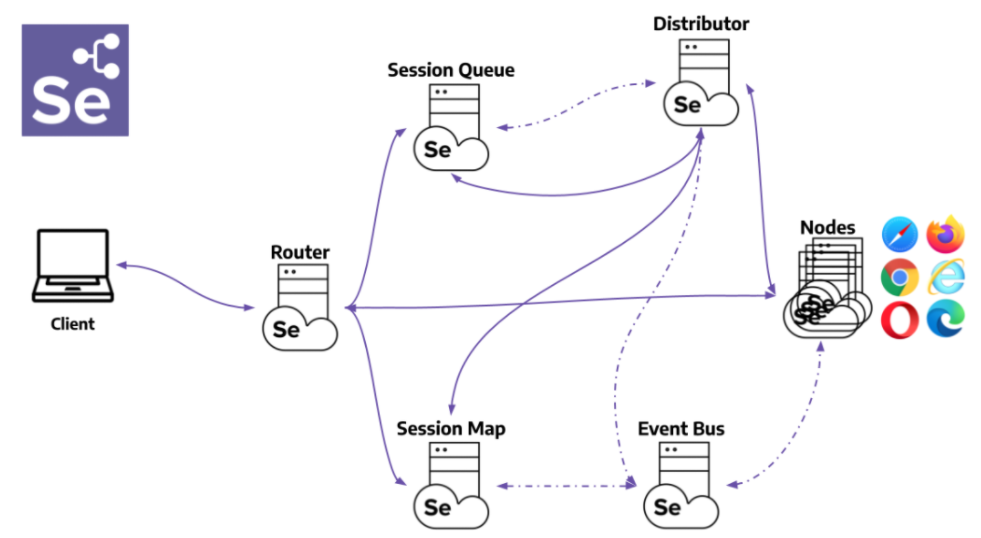
随着软件开发与测试需求的不断增长,企业级测试解决方案的需求也在逐步提升。本文首先概述了企业级测试解决方案的基本概念,随后深入介绍了C#与Selenium自动化测试框架的基础知识及搭建方法。第三章详细探讨了Selenium自动化测试框架的实践应用,包括测试用例设计、跨浏览器测试的实现以及测试数据的管理和参数化测试。第四章则聚焦于测试框架的进阶技术与优化,包括高级操作技巧、测试结果的分析与报告生成以及性能和负
三菱PLC-FX3U-4LC高级模块应用:详解与技巧

# 摘要
本论文全面介绍了三菱PLC-FX3U-4LC模块的技术细节与应用实践。首先概述了模块的基本组成和功能特点,接着详细解析了其硬件结构、接线技巧以及编程基础,包括端口功能、
【CAN总线通信协议】:构建高效能系统的5大关键要素

# 摘要
CAN总线作为一种高可靠性、抗干扰能力强的通信协议,在汽车、工业自动化、医疗设备等领域得到广泛应用。本文首先对CAN总线通信协议进行了概述,随后深入分析了CAN协议的理论基础,包括数据链路层与物理层的功能、CAN消息的传输机制及错误检测与处理机制。在实践应用方面,讨论了CAN网络的搭建、消息过滤策略及系统集成和实时性优化。同时,本文还探讨了CAN协议在不同行业的具体应用案例,及其在安全性和故障诊断方面的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )