如何利用正则表达式从文本中提取特定模式的数据
发布时间: 2024-05-03 05:51:14 阅读量: 35 订阅数: 26 

# 1. 正则表达式简介
正则表达式(Regular Expression)是一种强大的文本模式匹配工具,它允许你通过指定一系列字符组合来查找、匹配和替换文本中的特定模式。正则表达式广泛应用于文本处理、数据验证、编程语言和各种系统管理任务中。
正则表达式由一系列元字符组成,这些元字符具有特定的含义,用于匹配文本中的特定模式。例如,`.`(点)元字符匹配任何单个字符,`*`(星号)元字符匹配前面字符的零次或多次出现。通过组合这些元字符,你可以创建复杂而强大的模式来匹配各种文本格式。
# 2. 正则表达式基础语法
### 2.1 正则表达式的组成和元字符
正则表达式由两部分组成:**模式**和**修饰符**。模式用于描述要匹配的文本,而修饰符用于控制匹配行为。
**元字符**是具有特殊含义的字符,用于匹配文本中的特定模式。常见的元字符包括:
- `.`:匹配任意单个字符
- `*`:匹配前面字符 0 次或多次
- `+`:匹配前面字符 1 次或多次
- `?`:匹配前面字符 0 次或 1 次
- `^`:匹配字符串的开头
- `$`:匹配字符串的结尾
- `[]`:匹配方括号内的任意一个字符
- `[^]`:匹配方括号内以外的任意一个字符
- `|`:匹配多个模式中的任何一个
**示例:**
```
模式 | 匹配的文本
---|---|
`ab*` | "a"、"ab"、"abb"、"abbb"、...
`[a-z]` | 任何小写字母
`[^0-9]` | 任何非数字字符
```
### 2.2 正则表达式的修饰符和量词
**修饰符**用于控制正则表达式的匹配行为。常见的修饰符包括:
- `i`:忽略大小写
- `m`:多行匹配
- `s`:点号匹配换行符
- `x`:允许在模式中使用空格和注释
**量词**用于指定字符或模式的匹配次数。常见的量词包括:
- `*`:匹配 0 次或多次
- `+`:匹配 1 次或多次
- `?`:匹配 0 次或 1 次
- `{n}`:匹配 n 次
- `{n,}`:匹配至少 n 次
- `{n,m}`:匹配 n 次到 m 次
**示例:**
```
修饰符 | 描述
---|---|
`i` | 忽略大小写,例如:`[a-z]` 匹配 "a" 和 "A"
`m` | 多行匹配,例如:`^.*$` 匹配多行文本的每一行
`s` | 点号匹配换行符,例如:`.+` 匹配包含换行符的文本
```
```
量词 | 描述
---|---|
`*` | 匹配 0 次或多次,例如:`ab*` 匹配 "a"、"ab"、"abb"、...
`+` | 匹配 1 次或多次,例如:`ab+` 匹配 "ab"、"abb"、...
`?` | 匹配 0 次或 1 次,例如:`ab?` 匹配 "a" 或 "ab"
```
**代码块:**
```python
import re
# 匹配以 "a" 开头的字符串
pattern = re.compile(r'^a.*$')
# 在文本中查找匹配项
text = "apple banana cherry"
match = pattern.search(text)
# 打印匹配项
print(match.group())
```
**代码逻辑分析:**
1. `re.compile(r'^a.*$')`:编译正则表达式,`^` 匹配字符串开头,`.*` 匹配任意数量的字符,`$` 匹配字符串结尾。
2. `pattern.search(text)`:在文本中查找与正则表达式匹配的第一个子串。
3. `print(match.group())`:打印匹配的子串。
**参数说明:**
- `re.compile(pattern)`:编译正则表达式,返回一个 `re.Pattern` 对象。
- `pattern.search(string)`:在字符串中查找与正则表达式匹配的第一个子串,返回一个 `re.Match` 对象,如果没有匹配项则返回 `None`。
- `match.group()`:返回匹配的子串。
# 3. 正则表达
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 VIP年卡限时特惠
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在提供正则表达式的实战技巧,涵盖广泛的应用场景。从基础语法到高级技巧,深入探讨正则表达式的强大功能。专栏内容包括:文本查找和替换、IP地址匹配、数据提取、算法优化、数据爬取、表单验证、计算器实现、邮件地址验证、日志分析、大规模文本搜索、XML数据解析、搜索引擎优化、分组捕获、词法分析、图像处理、多语言文本处理、精确数据匹配和日志过滤等。通过深入浅出的讲解和丰富的实战案例,本专栏将帮助读者掌握正则表达式的精髓,在实际应用中有效解决复杂问题。
专栏目录
最低0.47元/天 解锁专栏
VIP年卡限时特惠
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深入了解MATLAB开根号的最新研究和应用:获取开根号领域的最新动态

# 1. MATLAB开根号的理论基础
开根号运算在数学和科学计算中无处不在。在MATLAB中,开根号可以通过多种函数实现,包括`sqrt()`和`nthroot()`。`sqrt()`函数用于计算正实数的平方根,而`nt
MATLAB符号数组:解析符号表达式,探索数学计算新维度

# 1. MATLAB 符号数组简介**
MATLAB 符号数组是一种强大的工具,用于处理符号表达式和执行符号计算。符号数组中的元素可以是符
MATLAB求平均值在社会科学研究中的作用:理解平均值在社会科学数据分析中的意义

# 1. 平均值在社会科学中的作用
平均值是社会科学研究中广泛使用的一种统计指标,它可以提供数据集的中心趋势信息。在社会科学中,平均值通常用于描述人口特
MATLAB在图像处理中的应用:图像增强、目标检测和人脸识别
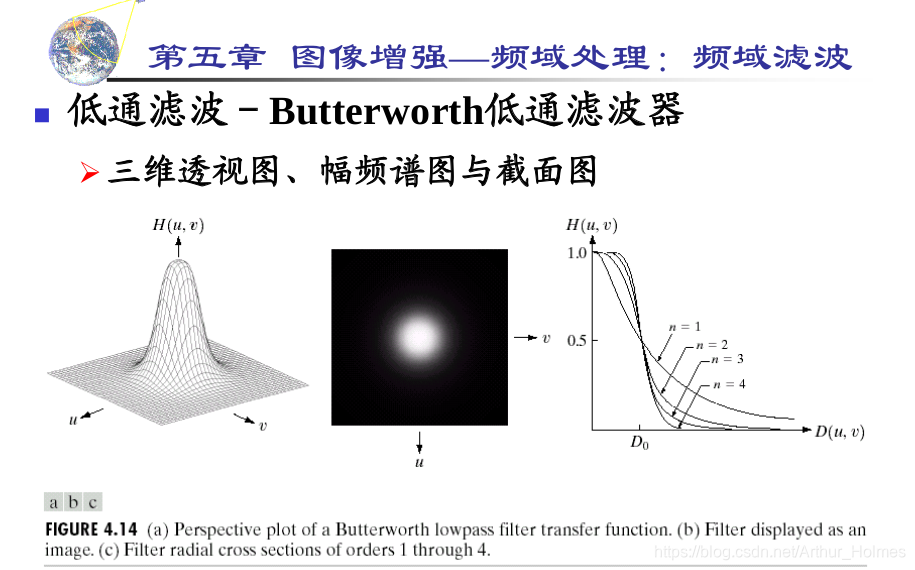
# 1. MATLAB图像处理概述
MATLAB是一个强大的技术计算平台,广泛应用于图像处理领域。它提供了一系列内置函数和工具箱,使工程师
MATLAB字符串拼接与财务建模:在财务建模中使用字符串拼接,提升分析效率

# 1. MATLAB 字符串拼接基础**
字符串拼接是 MATLAB 中一项基本操作,用于将多个字符串连接成一个字符串。它在财务建模中有着广泛的应用,例如财务数据的拼接、财务公式的表示以及财务建模的自动化。
MATLAB 中有几种字符串拼接方法,包括 `+` 运算符、`strcat` 函数和 `sprintf` 函数。`+` 运算符是最简单的拼接
MATLAB柱状图在信号处理中的应用:可视化信号特征和频谱分析

# 1. MATLAB柱状图概述**
MATLAB柱状图是一种图形化工具,用于可视化数据中不同类别或组的分布情况。它通过绘制垂直条形来表示每个类别或组中的数据值。柱状图在信号处理中广泛用于可视化信号特征和进行频谱分析。
柱状图的优点在于其简单易懂,能够直观地展示数据分布。在信号处理中,柱状图可以帮助工程师识别信号中的模式、趋势和异常情况,从而为信号分析和处理提供有价值的见解。
# 2. 柱状图在信号处理中的应用
柱状图在信号处理
图像处理中的求和妙用:探索MATLAB求和在图像处理中的应用

# 1. 图像处理简介**
图像处理是利用计算机对图像进行各种操作,以改善图像质量或提取有用信息的技术。图像处理在各个领域都有广泛的应用,例如医学成像、遥感、工业检测和计算机视觉。
图像由像素组成,每个像素都有一个值,表示该像素的颜色或亮度。图像处理操作通常涉及对这些像素值进行数学运算,以达到增强、分
NoSQL数据库实战:MongoDB、Redis、Cassandra深入剖析
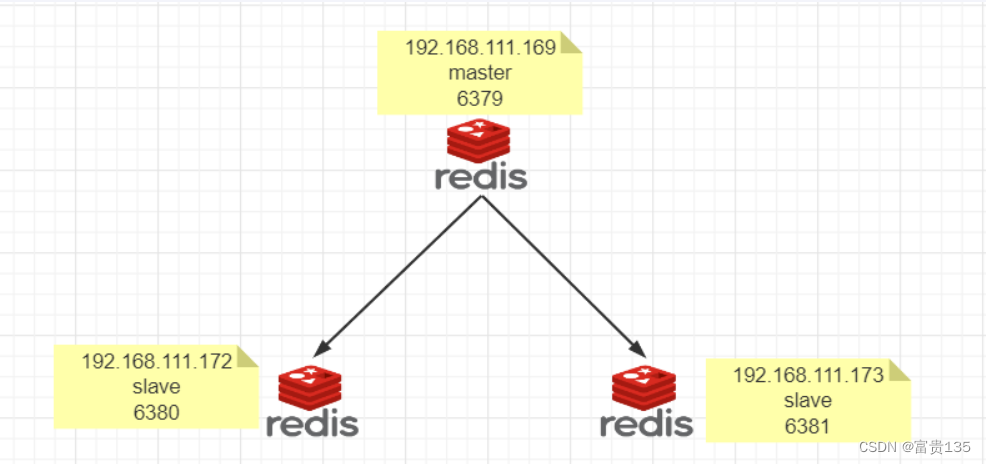
# 1. NoSQL数据库概述
**1.1 NoSQL数据库的定义**
NoSQL(Not Only SQL)数据库是一种非关系型数据库,它不遵循传统的SQL(结构化查询语言)范式。NoSQL数据库旨在处理大规模、非结构化或半结构化数据,并提供高可用性、可扩展性和灵活性。
**1.2 NoSQL数据库的类型**
NoSQL数据库根据其数据模型和存储方式分为以下
MATLAB散点图:使用散点图进行信号处理的5个步骤
# 1. MATLAB散点图简介
散点图是一种用于可视化两个变量之间关系的图表。它由一系列数据点组成,每个数据点代表一个数据对(x,y)。散点图可以揭示数据中的模式和趋势,并帮助研究人员和分析师理解变量之间的关系。
在MATLAB中,可以使用`scatter`函数绘制散点图。`scatter`函数接受两个向量作为输入:x向量和y向量。这些向量必须具有相同长度,并且每个元素对(x,y)表示一个数据点。例如,以下代码绘制
MATLAB平方根硬件加速探索:提升计算性能,拓展算法应用领域

# 1. MATLAB 平方根计算基础**
MATLAB 提供了 `sqrt()` 函数用于计算平方根。该函数接受一个实数或复数作为输入,并返回其平方根。`sqrt()` 函数在 MATLAB 中广泛用于各种科学和工程应用中,例如信号处理、图像处理和数值计算。
**代码块:**
```matlab
% 计算实数的平方根
x = 4;
sqrt_x = sqrt(x);
%
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
VIP年卡限时特惠
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )