OpenCV答题卡识别系统:图像生成与合成的前沿技术
发布时间: 2024-08-07 11:19:35 阅读量: 31 订阅数: 42 

计算机视觉技术实现的OpenCV答题卡识别系统设计与实现
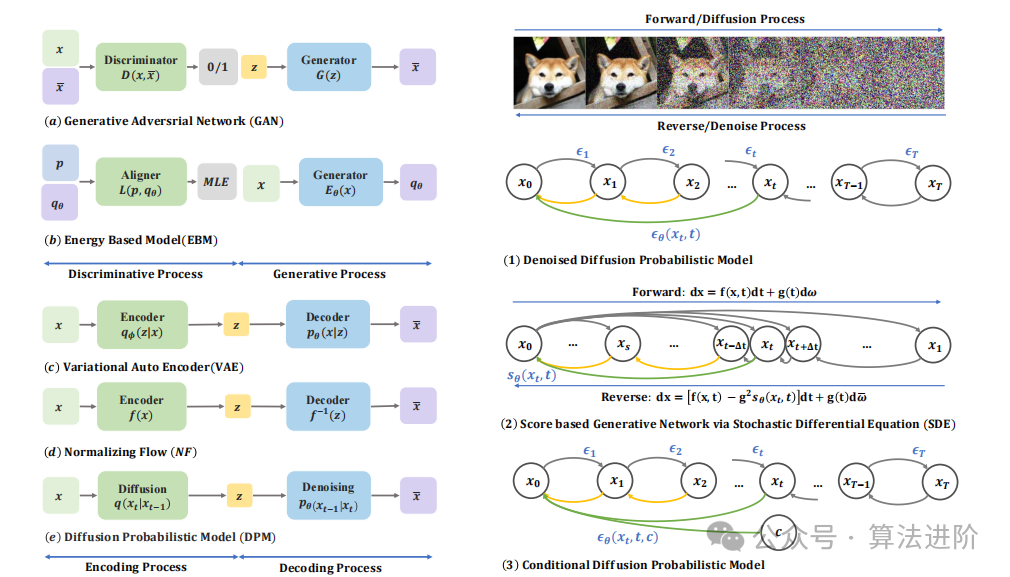
# 1. OpenCV图像处理基础**
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉库,广泛用于图像处理和计算机视觉应用中。它提供了一系列功能强大的算法和工具,可以帮助开发人员轻松处理和分析图像。
在图像处理中,OpenCV提供了图像预处理、特征提取、图像分割、目标检测和跟踪等基本功能。它支持多种图像格式,并具有跨平台兼容性,可以在Windows、Linux和macOS等操作系统上运行。
# 2. 答题卡识别算法
答题卡识别算法是答题卡识别系统中的核心技术,其主要任务是将答题卡图像中的答题信息提取出来,并进行分类和识别。答题卡识别算法主要分为三个步骤:图像预处理、特征提取和分类与识别。
### 2.1 图像预处理
图像预处理是答题卡识别算法的第一步,其目的是将原始答题卡图像转换为适合后续处理的格式。图像预处理主要包括图像灰度化和图像二值化两个步骤。
#### 2.1.1 图像灰度化
图像灰度化是指将彩色图像转换为灰度图像的过程。灰度图像只包含亮度信息,不包含色彩信息。图像灰度化可以去除图像中的颜色干扰,使后续处理更加容易。
```python
import cv2
# 读取原始图像
image = cv2.imread('answer_sheet.jpg')
# 转换为灰度图像
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
```
#### 2.1.2 图像二值化
图像二值化是指将灰度图像转换为二值图像的过程。二值图像只有两个像素值:0(黑色)和255(白色)。图像二值化可以将答题卡中的答题区域与背景区域分离出来。
```python
# 二值化阈值
threshold = 127
# 二值化处理
binary_image = cv2.threshold(gray_image, threshold, 255, cv2.THRESH_BINARY)[1]
```
### 2.2 特征提取
特征提取是答题卡识别算法的第二步,其目的是从预处理后的图像中提取出能够代表答题信息的特征。特征提取主要包括轮廓检测和霍夫变换两个步骤。
#### 2.2.1 轮廓检测
轮廓检测是指从二值图像中提取出物体边缘的过程。轮廓检测可以得到答题卡中答题区域的形状和位置信息。
```python
# 寻找轮廓
contours, _ = cv2.findContours(binary_image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
```
#### 2.2.2 霍夫变换
霍夫变换是一种用于检测图像中直线和圆等几何形状的算法。霍夫变换可以得到答题卡中答题框的直线方程和圆心坐标信息。
```python
# 霍夫变换检测直线
lines = cv2.HoughLinesP(binary_image, 1, np.pi / 180, 50, minLineLength=100, maxLineGap=10)
# 霍夫变换检测圆
circles = cv2.HoughCircles(binary_image, cv2.HOUGH_GRADIENT, 1, 20, param1=50, param2=30, minRadius=10, maxRadius=30)
```
### 2.3 分类与识别
分类与识别是答题卡识别算法的第三步,其目的是将提取出的特征分类和识别为特定的答题信息。分类与识别主要包括SVM分类和神经网络识别两个步骤。
#### 2.3.1 SVM分类
SVM分类是一种支持向量机分类算法,其可以将特征分为不同的类别。SVM分类可以用于识别答题卡中答题区域的类型,例如单选题、多选题和判断题。
```python
# 训练SVM分类器
clf = svm.SVC()
clf.fit(features, labels)
# 预测答题区域类型
predictions = clf.p
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《OpenCV答题卡识别系统:从入门到精通》专栏是一份全面的指南,涵盖了使用OpenCV库进行答题卡识别的各个方面。它从图像处理和特征提取的基础知识开始,逐步深入到图像分割、字符识别、人工智能、深度学习、图像增强、图像配准、边缘检测、形态学操作、图像分割、图像分类、图像生成和图像编辑等高级技术。该专栏提供了详细的教程、实战示例和常见问题解答,使读者能够从零开始构建一个功能齐全的答题卡识别系统。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【S型速度曲线终极指南】:20年经验技术大佬揭秘sin²x的算法奥秘
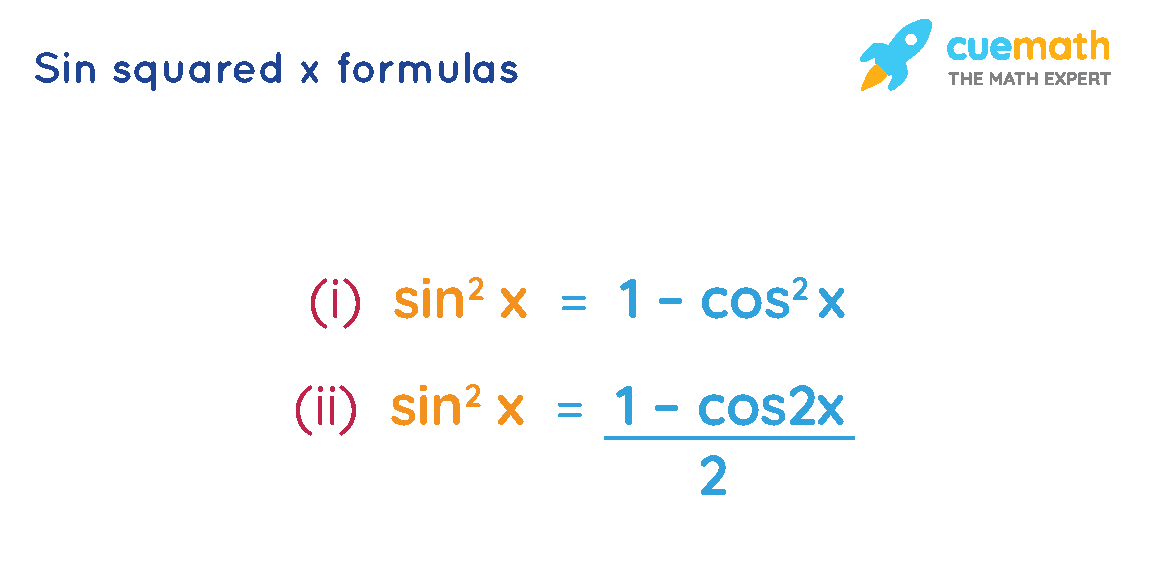
# 摘要
S型速度曲线作为一种重要的动力学建模工具,在多个领域中用于描述和控制速度变化。本文首先介绍了S型速度曲线的基本概念,随后深入探讨了sin²x算法的数学原理及其在速度控制中的应用。接着,本文详细分析了sin²x算法的编程实现,包括理论编程模型和具体编程实践,以及算法性能测试与优化。通过工业自动化和软件开发中
【CesiumLab切片原理深度剖析】:揭秘倾斜模型生成的科学

# 摘要
CesiumLab切片技术在三维可视化领域具有重要应用,本文详细概述了其核心概念、处理流程、实践应用以及高级特性。首先介绍倾斜模型数据的处理流程,包括倾斜摄影测量基础、切片技术的理论依据以及关键算法。其次,探讨CesiumLab切片技术的实践应用,重点阐述了切片生成的步骤、数据优化与
【超频不传之秘】:BIOS超频要点及最佳实践
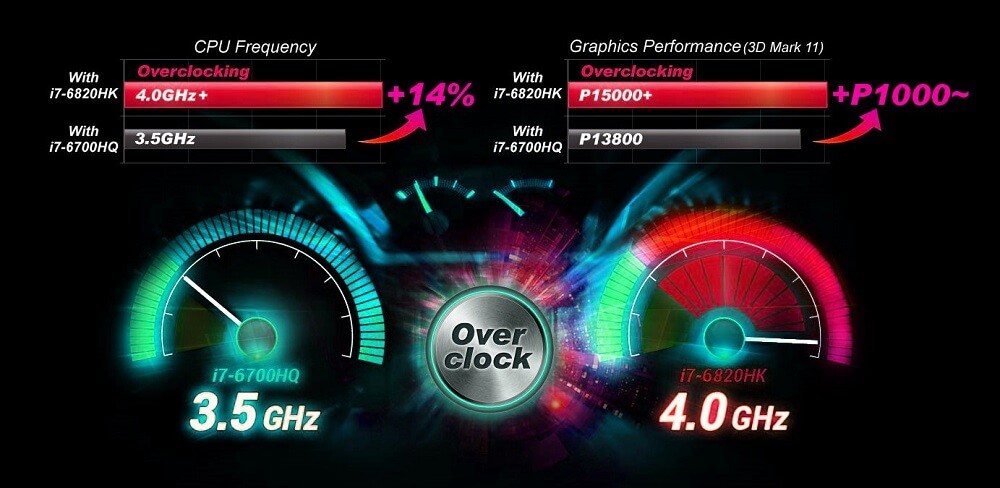
# 摘要
本文系统介绍了BIOS超频的基础知识和技术要点,详细解析了处理器、内存和图形卡超频的原理与实践。文章探讨了超频对硬件性能的影响,并提供了详细的实践操作指南,包括硬件兼容性检查、BIOS设置、系统监控与稳定性测试。通过对不同平台超频案例的分析,文章揭示了超频的最佳实践和潜在风险,并提供了应对策略。最后,文章展望了超频技术的未来发展趋势,以及超频社区在技术传播和文化传承中的作
DBeaver SQL格式化最佳实践:V1.4版本的终极应用指南
# 摘要
本文详细探讨了DBeaver SQL格式化功能的全面概述、理论基础、配置与优化,以及在实践中的应用。首先介绍了DBeaver SQL格式化的核心组件及其在提升SQL代码可读性和整洁性方面的重要性。随后深入分析了格式化的理论基础,包括美学标准和格式化规则的制定。文章接着讨论了格式化的配置、定制及优化方法,如何通过各种参数和模板提升格式化效率,并解决常见问题。此外,还探讨了格式化在数据库迁移、代码维护和团队协作中的关键作用。最后,本文展望了格式化技术的未来发展方向,包括高级技巧和人工智能的潜在应用。
# 关键字
DBeaver;SQL格式化;代码质量管理;配置优化;团队协作;人工智能应
Pilot Pioneer Expert V10.4数据备份与恢复:最佳实践与策略分析

# 摘要
本文全面介绍了Pilot Pioneer Expert V10.4的数据备份与恢复技术。首先概述了备份的基础知识和备份类型的选择,接着深入探讨了数据备份的策略和存储解决方案。在实践章节中,详述了如何配置和管理备份作业,并强调了恢复数据的测试与验证。理论与流程章节涉及了数据恢复的概念、策略、操作指南及验证审计
LTE连接稳定性专家:小区切换与重选的深刻剖析
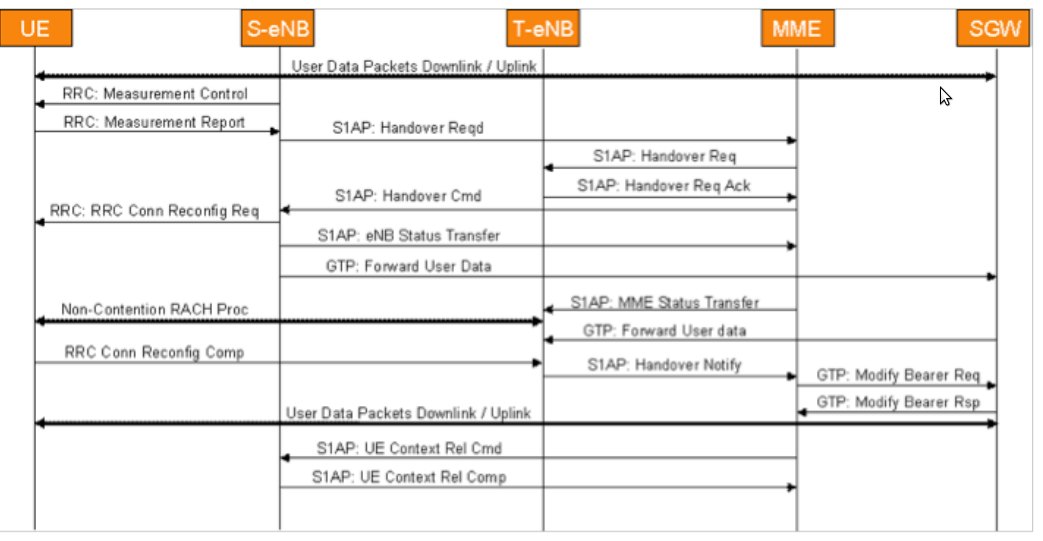
# 摘要
LTE技术作为当前移动通信领域的主流技术之一,其连接稳定性和小区切换性能对于保证用户体验至关重要。本文系统梳理了LTE网络小区切换的理论基础,包括LTE标准、关键技术如OFDMA和MIMO,以及小区切换与重选的基本概念和信号测量评估方法。通过对小区切换实践的分析,本文探讨了小区切换触发条件、决策过程以及重选算法,并分析了网络环境、用户
【提升FFT性能】:DIT与DIF计算效率优化技巧

# 摘要
快速傅里叶变换(FFT)是一种高效计算离散傅里叶变换(DFT)及其逆变换的算法,广泛应用于数字信号处理、图像处理、通信系统等领域。本文首先介绍了FFT的基本概念,并对离散傅里叶变换的定义和计算复杂度进行了分析。接着,深入探讨了基于分治策略的DIT(时域抽取)和DIF(频域抽取)FFT算法的理论基础、
Altium Designer与FPGA协同作战:提升设计效率的10大策略
# 摘要
本文探讨了Altium Designer与FPGA(现场可编程门阵列)在现代电子设计中的协同作战模式。首先介绍了FPGA的基本概念、优势及其设计原理,然后深入到Altium Designer平台的功能与FPGA设计协同策略,包括数据交换、接口设计、仿真与验证以及布局布
【CUDA开发效率】:在Visual Studio中优化代码编写与调试的技巧

# 摘要
本论文旨在系统地介绍CUDA开发环境的搭建、代码编写技巧以及调试策略。首先概述了CUDA开发的关键概念和优势。随后详细阐述了如何设置CUDA开发环境,包括Visual Studio的安装与配置,CUDA项目创建、管理和版本控制集成,以及环境变量和构建系统的配置。在第三章中,本文深入探讨了CUDA代
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )