Jinja2与Flask框架实战:如何打造轻量级Web应用
发布时间: 2024-10-05 08:21:40 阅读量: 23 订阅数: 42 

# 1. Jinja2模板引擎入门
## 1.1 Jinja2简介
Jinja2是一个现代的、设计简洁的模板引擎,广泛用于Python Web开发,它提供了强大的模板语言,允许开发者定义可重用的模板结构。Jinja2的语法设计清晰直观,易于上手,能够轻松地将数据和业务逻辑分离,提高开发效率。
## 1.2 模板的基本结构
Jinja2模板使用`.jinja`或`.html`作为文件扩展名。一个基本的Jinja2模板包含三部分:变量、控制结构(如循环、条件判断)以及模板标签。例如:
```jinja
<!DOCTYPE html>
<html lang="en">
<head>
<title>{{ title }}</title>
</head>
<body>
{% if items %}
<ul>
{% for item in items %}
<li>{{ item }}</li>
{% endfor %}
</ul>
{% endif %}
</body>
</html>
```
在上述模板中,`{{ title }}`是变量的使用,`{% if %}`和`{% for %}`是控制结构。
## 1.3 配置Jinja2环境
要在Python应用中使用Jinja2,首先需要安装库,可以通过pip安装:
```bash
pip install Jinja2
```
然后在应用中配置Jinja2环境,加载模板,并渲染输出。下面是一个简单的配置和渲染的例子:
```python
from jinja2 import Environment, FileSystemLoader
# 创建环境对象,指定模板加载路径
env = Environment(loader=FileSystemLoader('templates'))
# 加载模板文件
template = env.get_template('hello.html')
# 模板变量字典
data = {'title': 'My Web Page', 'items': ['One', 'Two', 'Three']}
# 渲染模板并打印结果
print(template.render(data))
```
以上就是Jinja2模板引擎的基础入门,对于新手来说,了解基本的模板语法和如何配置环境是开始的第一步。随着学习的深入,将会探索更多高级功能,如自定义过滤器、测试、宏和继承等。
# 2. Flask框架基础
## 2.1 Flask的安装和配置
### 2.1.1 安装Flask及其依赖
在Python的世界里,安装一个库或者框架通常是第一步。对于Flask来说,也不例外。使用Flask之前,您需要确保Python环境已经安装。推荐使用`pip`进行安装,因为它是最为通用的Python包安装工具。
打开终端或命令提示符,输入以下命令安装Flask:
```bash
pip install Flask
```
这个命令会安装Flask及其所有的依赖包。如果安装过程中遇到权限问题,可以使用`sudo`(在Unix-like系统上)或以管理员权限运行(在Windows系统上)。
为了确认Flask已经正确安装,你可以创建一个Python文件,例如`hello.py`,并输入以下内容:
```python
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello, Flask!'
if __name__ == '__main__':
app.run(debug=True)
```
运行该Python脚本:
```bash
python hello.py
```
如果一切正常,你将在终端看到类似于以下的输出:
```
* Running on ***
```
此时打开浏览器,访问`***`,应该能看到“Hello, Flask!”的消息显示出来。这表示Flask已成功安装并且可以运行。
### 2.1.2 创建Flask应用和基本配置
创建一个Flask应用需要定义一个应用实例和一个或多个路由。首先,让我们创建一个简单的应用,并为其添加一个基本配置。
在`hello.py`文件中,我们已经定义了一个Flask应用实例和一个路由。下面的步骤将帮助我们进一步了解如何进行应用配置。
```python
from flask import Flask
app = Flask(__name__)
app.config['DEBUG'] = True
app.config['SECRET_KEY'] = 'your_secret_key'
@app.route('/')
def index():
return 'Hello, World!'
if __name__ == '__main__':
app.run()
```
在这个例子中,我们通过`app.config`字典来设置两个配置项。`DEBUG`是一个重要的配置项,当其被设置为`True`时,应用在运行时会启用调试模式。这使得开发过程中遇到错误时,应用能够提供详细的错误信息,并且在代码变动后能够自动重载,非常方便。
`SECRET_KEY`是一个用于维护应用安全性的重要配置项,它用于保护会话数据,防止篡改。在生产环境中,您应该设置一个难以猜测的密钥。
代码解读:
- `Flask(__name__)`:这是创建Flask应用实例的标准方式。
- `app.config`:这是用来设置配置的字典。
- `app.run()`:这是用来启动Flask应用的函数。
对`app.config`所设置的每个配置项,都可以通过`app.config['CONFIG_ITEM']`的方式进行访问和修改。这是对Flask应用进行配置的基本方法,随着应用的复杂化,我们还可以通过其他方式添加配置,例如环境变量或继承`Config`类。
## 2.2 Flask路由和视图函数
### 2.2.1 路由的定义和分发
在Flask框架中,路由(Routing)是指对网络中资源的定位。在Web应用中,它主要是指确定一个URL地址和一个视图函数之间的映射关系。视图函数是负责处理对应的HTTP请求,并返回响应数据的函数。
在Flask里定义路由是非常简单的。只需使用`@app.route装饰器`装饰一个Python函数,就可以将这个函数注册为一个路由。当客户端访问该路由时,对应的函数就会被调用。
下面是一个定义路由的简单例子:
```python
@app.route('/')
def index():
return 'Index Page'
@app.route('/hello')
def hello():
return 'Hello Flask'
```
在这个例子中,`index()`函数响应的是网站的根路径`/`,而`hello()`函数则响应`/hello`路径。如果用户访问`***`,他们将看到“Index Page”,访问`***`则会看到“Hello Flask”。
### 2.2.2 视图函数的参数解析
路由不仅可以通过路径来匹配,还可以根据URL中提供的参数来进行匹配。Flask允许我们定义带有参数的路由,并在视图函数中获取这些参数的值。
例如,我们想要创建一个路由,它能够根据用户ID显示用户的页面:
```python
@app.route('/user/<int:user_id>')
def show_user_profile(user_id):
return f'User ID: {user_id}'
@app.route('/post/<string:post_id>')
def show_post(post_id):
return f'Post ID: {post_id}'
```
在这个例子中,我们定义了两个路由,它们都包含了一个参数:`user_id`和`post_id`。`<int:> `和`<string:> `是转换器,它们指示Flask期望这些参数是整型和字符串类型。这样,Flask就可以在视图函数中接收参数,并自动将其转换为相应的数据类型。
代码解读:
- `@app.route('/user/<int:user_id>')`:定义了一个带有参数的路由,参数名称为`user_id`,类型为整数。
- `def show_user_profile(user_id):`:定义了一个视图函数,它接收参数`user_id`。
- `return f'User ID: {user_id}'`:返回一个包含`user_id`的字符串。
## 2.3 Flask的请求和响应处理
### 2.3.1 处理请求数据
在Web开发中,处理客户端发送的请求数据是一个非常重要的环节。Flask通过`request`对象提供了一个丰富的接口,用于获取请求中的数据。
`request`对象是Flask内置的全局对象,可以用来访问请求中的各种信息,包括表单数据、请求参数、HTTP头等。下面是一个如何使用`request`对象来获取和处理请求数据的例子:
```python
from flask import request
@app.route('/login', methods=['GET', 'POST'])
def login():
if request.method == 'POST':
username = request.form['username']
password = request.form['password']
# 进行用户验证等操作...
return '登录成功'
else:
return '''
<form method="post">
<label>用户名: <input type="text" name="username"></label>
<label>密码: <input type="password" name="password"></label>
<input type="submit" value="登录">
</form>
'''
```
在这个例子中,我们首先引入了`request`模块。然后定义了一个名为`login`的视图函数,它响应`/login`路由。该路由使用了`methods`参数来限制只接受`GET`和`POST`请求。
在视图函数内部,我们首先检查请求的方法是否为`POST`。如果是,那么我们就可以从`request.form`中获取用户提交的用户名和密码。如果不是,则返回一个简单的登录表单。
代码解读:
- `request.form`:一个特殊的`werkzeug.datastructures.MultiDict`对象,包含了POST请求提交的所有表单数据。
- `request.method`:用来检查当前请求使用的HTTP方法。
Flask还提供了`request.args`、`request.values`、`request.files`等属性,用于获取查询字符串参数、请求参数以及上传的文件等数据。通过这些属性,我们可以在视图函数中处理各种类型的数据。
### 2.3.2 自定义响应对象
虽然返回简单的字符串或者响应对象是处理请求的快速方法,但Flask也支持创建更加复杂的响应对象,包括自定义状态码、响应头等。
通常情况下,一个视图函数返回的是字符串或者一个元组。但Flask允许你返回一个`Response`对象,你可以自定义响应的内容、状态码和响应头。
```python
from flask import make_response
@app.route('/')
def index():
response = make_response('<h1>This document carries a header</h1>')
response.headers['X-Something'] = 'A value'
response.set_cookie('name', 'value')
return response
```
在这个例子中,我们使用`make_response`函数创建了一个新的`Response`对象。这个对象可以接受一个简单的字符串作为响应的内容。我们还可以自定义响应头和设置cookie。
代码解读:
- `make_response('<h1>This document carries a header</h1>')`:创建一个新的`Response`对象,并传入了一个HTML字符串作为响应内容。
- `response.headers['X-Something'] = 'A value'`:向响应头中添加了一个名为`X-Something`的字段,并为其赋予了一个值。
- `response.set_cookie('name', 'value')`:在响应中设置了一个cookie。
通过上述方法,我们可以灵活地控制响应的每一个细节,以满足不同场景的需求。
# 3. Jinja2与Flask结合应用
## 3.1 模板渲染基础
### 3.1.1 Flask中的模板渲染过程
在Web开发中,模板渲染是将后端数据动态地嵌入HTML页面的过程。在Flask框架中,Jinja2作为内置的模板引擎,提供了灵活而强大的模板渲染能力。Flask应用通过`render_template`函数,将业务逻辑中的数据传递给Jinja2模板,完成从数据到页面的转换。
核心渲染流程如下:
1. 定义路由和视图函数,在视图函数中准备好传递给模板的数据。
2. 使用`render_template`函数指定模板文件路径和要传递给模板的数据。
3. Flask调用Jinja2模板引擎,模板引擎读取模板文件,并将数据按照模板中的指令渲染成最终的HTML内容。
4. 渲染后的HTML内容被返回给客户端,浏览器解析并展示最终页面。
### 代码示例:
```python
from flask import Flask, render_template
app = Flask(
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Jinja2 模板引擎,提供了一系列实用技巧和高级策略,帮助开发者从入门到精通。从优化渲染到高级特性,再到与 Django 的整合,专栏涵盖了 Jinja2 的方方面面。此外,还介绍了过滤器、测试、模板继承、宏、扩展和错误处理,为打造定制化、高效且可扩展的 Web 应用提供了全面的指南。通过掌握这些技巧,开发者可以提升开发水平,优化网站性能,并构建功能强大的多语言应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【RCS-2000 V3.1.3系统性能提升秘籍】:有效策略加速调度效率

# 摘要
RCS-2000 V3.1.3系统作为研究对象,本文首先概述了其系统架构与特性。接着,本文深入探讨了系统性能评估的理论基础,包括关键性能指标、性能瓶颈的诊断方法以及性能测试和基准比较的策略。在系统性能优化策略部分,文章详细介绍了系统配置、资源管理、负载均衡以及缓存与存储优化的方法。此外,本文还记录了
C#操作INI文件的20个常见问题解决与优化策略
# 摘要
本文详细探讨了在C#编程环境下操作INI文件的方法,涵盖了从基础概念到高级应用与优化,再到安全性和兼容性处理的全过程。文章首先介绍了INI文件的基本操作,包括文件的创建、初始化、读取、修改及更新,并提供了错误处理和异常管理的策略。随后,本文探讨了使用第三方库和多线程操作来实现性能优化的进阶技术,并针对安全性问题和跨平台兼容性问题提供了具体的解决方案。最后,结合实战案例,文章总结了最佳实践和代码规范,旨在为开发者提供C#操作INI文件的全面指导和参考。
# 关键字
C#编程;INI文件;文件操作;多线程;性能优化;安全性;兼容性
参考资源链接:[C#全方位详解:INI文件操作(写入
【Arima模型高级应用】:SPSS专家揭秘:精通时间序列分析

# 摘要
时间序列分析在理解和预测数据变化模式中扮演着关键角色,而ARIMA模型作为其重要工具,在众多领域得到广泛应用。本文首先介绍了时间序列分析的基础知识及ARIMA模型的基本概念。接着,详细探讨了ARIMA模型的理论基础,包括时间序列数据的特征分析、模型的数学原理、参数估计、以及模型的诊断和评估方法。第三章通过实例演示了ARIMA模型在SPSS软件中的操作流程,包括数据处理、模型构建和
【散热技术详解】:如何在Boost LED背光电路中应用散热技术,提高热管理效果

# 摘要
散热技术对于维护电子设备的性能和寿命至关重要。本文从散热技术的基础知识出发,详细探讨了Boost LED背光电路的热源产生及其传播机制,包括LED的工作原理和Boost电路中的热量来源。文章进一步分析了散热材料的选择标准和散热器设计原则,以及散热技术在LED背光电路中的实际应用。同
CTM安装必读:新手指南与系统兼容性全解析

# 摘要
CTM系统的安装与维护是确保其高效稳定运行的关键环节。本文全面介绍了CTM系统的安装流程,包括对系统兼容性、软件环境和用户权限的细致分析。文章深入探讨了CTM系统兼容性问题的诊断及解决策略,并提供了详细的安装前准备、安装步骤以及后续的配置与优化指导。此外,本文还强调了日常维护与系统升级的重要性,并提供了有效的故障恢复与备份措施,以保障CTM系统运行的连续性和安全性。
# 关键字
CTM系统;兼容性分析;安装流
【EC200A模组MQTT协议全解】:提升物联网通信效率的7大技巧
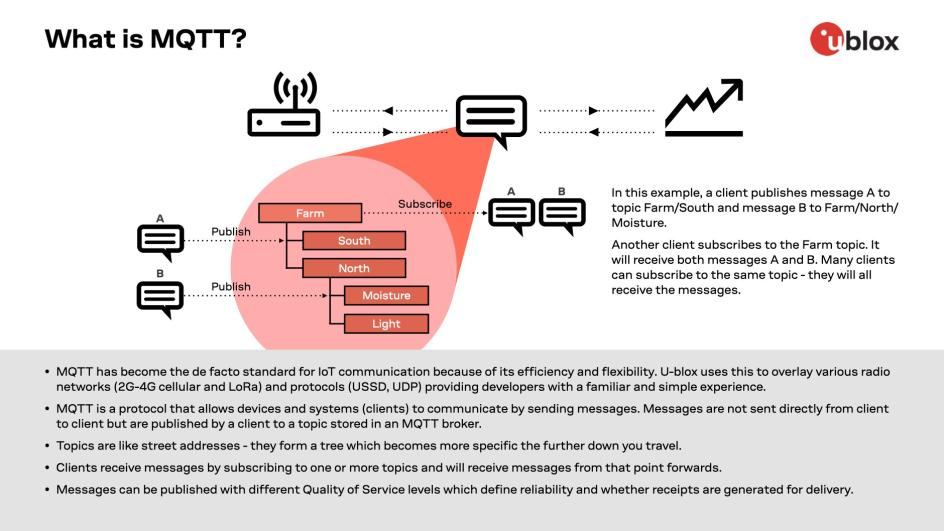
# 摘要
本文旨在探讨EC200A模组与MQTT协议在物联网通信中的应用。首先介绍了EC200A模组的基础和MQTT协议的理论架构,包括其起源、优势、消息模式、QoS等级及安全机制。随后,通过具体实例演示了EC200A模组的设置、MQTT通信的实现及性能优化。文章进一步提出了优化MQTT连接和消息处理的技巧,并强调了安全通信的重要性。最
SDH信号故障排查秘籍:帧结构问题快速定位与解决方案,让你的网络无懈可击!

# 摘要
SDH(同步数字体系)作为电信传输的重要技术,其帧结构的稳定性和可靠性对于数据通信至关重要。本文首先介绍了SDH信号及其帧结构的基础知识,详细阐述了帧结构的组成部分和数据传输机制。接着,通过理论分析,识别并解释了帧结构中常见的问题类型,例如同步信号丢失、帧偏移与错位,以及数据通道的缺陷。为了解决这些问题,本文探讨了利用专业工具进行故障检测和案例分析的策略,提出了快速解
【Android Studio与Gradle:终极版本管理指南】:2023年最新工具同步策略与性能优化
# 摘要
本文综合概述了Android Studio和Gradle在移动应用开发中的应用,深入探讨了版本控制理论与实践以及Gradle构建系统的高级特性。文章首先介绍了版本控制系统的重要性及其在Android项目中的应用,并讨论了代码分支管理策
2路组相联Cache性能提升:优化策略与案例分析
# 摘要
本文深入探讨了2路组相联Cache的基本概念、性能影响因素、优化策略以及实践案例。首先介绍了2路组相联Cache的结构特点及其基本操作原理,随后分析了影响Cache性能的关键因素,如访问时间、命中率和替换策略。基于这些理论基础,文中进一步探讨了多种优化策略,包括Cache结构的调整和管理效率的提升,以及硬件与软件的协同优化。通过具体的实践案例,展示了如何通过分析和诊断来实施优化措施,并通过性能测试来评估效果。最后,展望了Cache优化领域面临的新兴技术和未来研究方向,包括人工智能和多级Cache结构的应用前景。
# 关键字
2路组相联Cache;性能影响因素;优化策略;命中率;替换
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )