Java集合类库性能调优秘籍:掌握Google集合应用实践
发布时间: 2024-09-30 15:09:13 阅读量: 27 订阅数: 22 

ed-java:达拉斯欧洲Java
# 1. Java集合框架概述
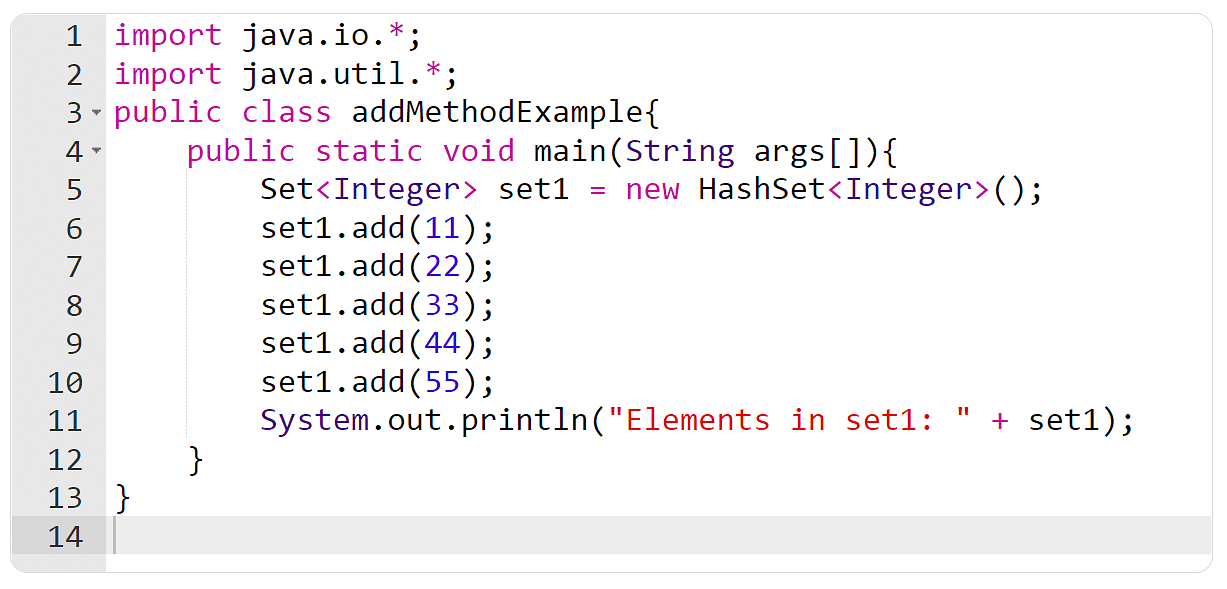
Java集合框架为对象提供了存储和操作的统一架构,是编写复杂应用程序的基础。在Java中,集合框架包含两个主要的接口:Collection和Map。Collection接口下又分为List、Set和Queue三个子接口,它们各自对应不同类型的集合,例如ArrayList、LinkedList和HashSet等。
集合框架允许用户以标准方式存储、检索、处理和操作集合中的数据。它的主要优点之一是减少了代码量和复杂性,由于其通用性,使得集合可以用于多种不同类型的对象。
在实际应用中,开发者必须根据具体需求选择合适的集合实现。例如,有序列表可以使用ArrayList或LinkedList实现,而快速查找则通常使用HashSet。理解每种集合的特点和性能差异对于开发高效的应用程序至关重要。接下来的章节将深入探讨核心集合类的性能、优化实践以及使用Google集合库等高级主题。
# 2. 核心集合类性能分析
## 2.1 List接口实现类的性能对比
### 2.1.1 ArrayList与LinkedList的性能差异
当我们讨论性能分析时,`ArrayList`与`LinkedList`是经常被比较的两个类。它们在`List`接口的实现中,各自有着独特的内部结构和操作特性。
- `ArrayList`基于动态数组数据结构,它提供了快速的随机访问能力,但由于数组结构,每次插入或删除操作都可能导致数组内容的迁移,从而在某些情况下其性能表现不如`LinkedList`。
- `LinkedList`则基于双向链表数据结构,对于频繁的插入和删除操作,尤其是在列表的前端或后端,它的性能非常出色。不过,`LinkedList`在访问元素时需要遍历链表,所以随机访问性能较差。
以下是`ArrayList`和`LinkedList`在不同操作下的性能对比:
- **随机访问:** `ArrayList`具有O(1)的时间复杂度,而`LinkedList`则为O(n)。
- **插入和删除操作:** 在列表的中间插入或删除元素,`LinkedList`有O(1)的性能,而`ArrayList`则需要O(n)的时间复杂度,因为需要移动后续所有元素。
- **内存占用:** `ArrayList`更节省空间,因为它不需要像`LinkedList`那样额外存储节点之间的指针。
### 2.1.2 Vector与Stack的遗留问题及替代方案
`Vector`和`Stack`是Java早期提供的集合类。`Vector`与`ArrayList`非常相似,但在每次添加元素时都会进行扩容检查和扩容操作,导致其性能比`ArrayList`要低。`Stack`本质上是一个后进先出(LIFO)的`Vector`,其使用场景已大幅减少。
随着Java的进化,**替代方案**如下:
- **对于`Vector`**,推荐使用`ArrayList`,因为它提供了相同的功能且性能更优。
- **对于`Stack`**,推荐使用`ArrayDeque`或`LinkedList`。这两个类都提供了栈的功能,并且在性能上更加优越。
下面是一个`ArrayList`和`LinkedList`插入性能对比的简单代码示例:
```java
public class ListPerformanceTest {
public static void main(String[] args) {
List<Integer> arrayList = new ArrayList<>();
List<Integer> linkedList = new LinkedList<>();
// 测试ArrayList和LinkedList插入性能
long startTime = System.nanoTime();
for (int i = 0; i < 100000; i++) {
arrayList.add(i);
}
long endTime = System.nanoTime();
System.out.println("ArrayList insert took: " + (endTime - startTime) + " ns");
startTime = System.nanoTime();
for (int i = 0; i < 100000; i++) {
linkedList.add(i);
}
endTime = System.nanoTime();
System.out.println("LinkedList insert took: " + (endTime - startTime) + " ns");
}
}
```
执行这段代码,我们可以看到在大量插入操作下,`LinkedList`往往比`ArrayList`表现得更好,因为它不需要迁移大量元素。
## 2.2 Set接口实现类的性能考量
### 2.2.1 HashSet与TreeSet的选择准则
`HashSet`和`TreeSet`是两种常见的`Set`集合实现。`HashSet`使用哈希表来存储集合中的元素,这使得它在执行添加、删除、查找操作时非常快速,平均时间复杂度为O(1)。
另一方面,`TreeSet`则基于红黑树数据结构,它在排序集上提供了有序性。`TreeSet`中的元素是排序的,这使得它可以确保元素的唯一性和顺序性。这在需要对元素进行排序的场景下非常有用。
选择`HashSet`还是`TreeSet`取决于具体需求:
- **数据规模**:如果数据量非常大,并且主要操作是查找元素,则`HashSet`是更优选择。
- **元素排序**:如果需要集合中的元素有序,则`TreeSet`是必须的。
### 2.2.2 LinkedHashSet的特性和使用场景
`LinkedHashSet`是一个特殊的`Set`实现,它在`HashSet`的基础上维护了一个双向链表,记录了插入顺序。这意味着`LinkedHashSet`不仅能够保证元素的唯一性,还能按照插入的顺序来迭代集合中的元素。
由于这种特性,`LinkedHashSet`在以下场景中特别有用:
- **有序的集合操作**:当需要保持插入顺序时,`LinkedHashSet`是一个很好的选择。
- **频繁遍历**:由于其内部结构特性,`LinkedHashSet`在遍历时比`HashSet`有微小的性能优势。
表格比较`HashSet`、`TreeSet`和`LinkedHashSet`的特性:
| 集合类型 | 平均时间复杂度 | 排序 | 插入顺序 |
|----------|----------------|------|----------|
| HashSet | O(1) | 否 | 否 |
| TreeSet | O(log n) | 是 | 否 |
| LinkedHashSet | O(1) | 否 | 是 |
**代码示例:**
```java
public class SetPerformanceTest {
public static void main(String[] args) {
Set<Integer> hashSet = new HashSet<>();
Set<Integer> treeSet = new TreeSet<>();
Set<Integer> linkedHashSet = new LinkedHashSet<>();
// 性能测试
long startTime, endTime;
// HashSet插入性能测试
startTime = System.nanoTime();
for (int i = 0; i < 100000; i++) {
hashSet.add(i);
}
endTime = System.nanoTime();
System.out.println("HashSet insert took: " + (endTime - startTime) + " ns");
// TreeSet插入性能测试
startTime = System.nanoTime();
for (int i = 0; i < 100000; i++) {
treeSet.add(i);
}
endTime = System.nanoTime();
System.out.println("TreeSet insert took: " + (endTime - startTime) + " ns");
// LinkedHashSet插入性能测试
startTime = System.nanoTime();
for (int i = 0; i < 100000; i++) {
linkedHashSet.add(i);
}
endTime = System.nanoTime();
System.out.println("LinkedHashSet insert took: " + (endTime - startTime) + " ns");
}
}
```
在这个示例代码中,我们比较了`HashSet`、`TreeSet`和`LinkedHashSet`在插入操作中的性能表现。通常,`HashSet`的性能最佳,但在需要有序性时,`LinkedHashSet`或`TreeSet`更为合适。
## 2.3 Map接口实现类的性能测试
### 2.3.1 HashMap与TreeMap的性能测试结果
`HashMap`和`TreeMap`是两种常见的`Map`实现。它们在性能和特性上有着显著的不同。
- `HashMap`使用哈希表来存储键值对,因此它提供了快速的插入、查找和删除操作,平均时间复杂度为O(1)。
- `TreeMap`使用红黑树数据结构来存储键值对,因此它能够保持键的排序。它的插入、查找和删除操作的时间复杂度为O(log n)。
下面是一个简单的性能测试代码:
```java
public class MapPerformanceTest {
public static void main(String[] args) {
Map<Integer, String> hashMap = new HashMap<>();
Map<Integer, String> treeMap = new TreeMap<>();
// 性能测试
long startTime, endTime;
// HashMap插入性能测试
startTime = System.nanoTime();
for (int i = 0; i < 100000; i++) {
hashMap.put(i, "value");
}
endTime = System.nanoTime();
System.out.println("HashMap insert took: " + (endTime - startTime) + " ns");
// TreeMap插入性能测试
startTime = System.nanoTime();
for (int i = 0; i < 100000; i++) {
treeMap.put(i, "value");
}
endTime = System.nanoTime();
System.out.println("TreeMap insert took: " + (endTime - startTime) + " ns");
}
}
```
这段代码比较了`HashMap`和`TreeMap`在插入操作中的性能表现。一般情况下,`HashMap`因为使用哈希表结构,会比使用红黑树的`TreeMap`快得多。
### 2.3.2 ConcurrentHashMap在多线程环境下的表现
随着多核处理器和并行计算的普及,多线程环境下对`Map`的性能表现和并发安全性要求日益增加。`ConcurrentHashMap`是Java提供的一个线程安全的`Map`实现,它通过分段锁的机制,提供了比`Hashtable`更优的并发性能。
- **分段锁策略**:`ConcurrentHashMap`将数据分割到若干个片段(或称为段,即Segment)上,每个段独立进行锁定,这样的设计可以减少并发时的锁竞争,从而提高性能。
- **弱一致性**:`ConcurrentHashMap`允许在迭代时对Map进行修改,但仍然保证操作的线程安全。
在下面的代码示例中,我们将看到如何利用`ConcurrentHashMap`在多线程环境下的优势:
```java
import java.util.concurrent.ConcurrentHashMap;
import java.util.Map;
import java.util.Random;
public class ConcurrentHashMapTest {
public static void main(String[] args) {
ConcurrentHashMap<Integer, String> map = new ConcurrentHashMap<>();
// 模拟多线程对ConcurrentHashMap的并发操作
Runnable task = () -> {
Random random = new Random();
for (int i = 0; i < 1000; i++) {
int key = random.nextInt(100);
map.put(key, "value" + key);
}
};
// 启动多个线程进行并发操作
long startTime = System.nanoTime();
Thread[] threads = new Thread[10];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(task);
threads[i].start();
}
// 等待所有线程完成
for (Thread t : threads) {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
long endTime = System.nanoTime();
System.out.println("ConcurrentHashMap concurrent operations took: " + (endTime - startTime) + " ns");
}
}
```
通过此示例,我们可以观察到在多线程环境下,`ConcurrentHashMap`能够保持很高的并发性能,这是因为在执行插入操作时,各个线程操作的`ConcurrentHashMap`中的不同段,避免了线程间的锁竞争。这使得`ConcurrentHashMap`成为多线程环境中处理大量数据的理想选择。
# 3. 集合类性能调优实践
在探讨Java集合框架时,优化性能不仅限于理解集合类的内部工作机制,还涉及到调优以适应特定的应用需求。本章将深入探讨如何通过初始化与扩容机制、数据结构选择和多线程策略等方面来提升集合类的性能。
## 3.1 集合类初始化与扩容机制优化
集合类在Java中扮演了重要的角色,而正确的初始化和扩容策略是保证集合操作性能的关键。
### 3.1.1 初始容量与扩容策略的平衡艺术
在初始化集合类如`ArrayList`时,提供合理的初始容量是避免频繁扩容导致性能下降的重要手段。以下是`ArrayList`的构造函数示例:
```java
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
```
在使用`ArrayList`时,如果提前知道将要存储的数据数量,可以通过参数指定初始容量。这样做可以减少数组复制的次数,因为每次扩容时,`ArrayList`都会创建一个更大的数组,并将旧数组的元素复制到新数组中。例如:
```java
List<String> list = new ArrayList<>(500);
```
在这个例子中,`ArrayList`的初始容量被设置为500。这使得在初期操作中不会触发扩容,提高了性能。然而,如果初始容量设置得过大,则会浪费内存资源。
### 3.1.2 预估集合容量的重要性
预估集合容量对于避免动态扩容是非常重要的。如果无法预估集合容量,可以采用动态扩容策略,或者使用`LinkedList`等不需要扩容的数据结构。但需要注意的是,`LinkedList`在访问元素时的时间复杂度为O(n),并不适合随机访问。
对于`HashMap`来说,合理的初始容量设置同样重要。初始容量过小会导致在插入元素时频繁的扩容操作和哈希碰撞,影响性能。以下是一个计算初始容量的例子:
```java
int initialCapacity = (int) Math.ceil((float) expectedSize / loadFactor);
Map<String, String> map = new HashMap<>(initialCapacity);
```
`expectedSize`是预计的元素数量,`loadFactor`是负载因子,默认值为0.75。通过这样的计算,可以减少`HashMap`扩容的次数,提高性能。
## 3.2 数据结构的选择与算法优化
在处理数据时,正确选择数据结构以及算法对于性能至关重要。
### 3.2.1 根据需求选择合适的数据结构
不同的数据结构有着不同的性能特点,正确选择可以带来显著的性能提升。例如,在需要快速检索时,使用`HashSet`或`HashMap`通常比使用`ArrayList`或`LinkedHashMap`要快。这是因为`HashSet`和`HashMap`的底层是通过哈希表实现的,它们的平均时间复杂度为O(1)。
以下是一个使用`HashSet`的简单例子:
```java
Set<String> set = new HashSet<>();
set.add("apple");
set.add("banana");
set.add("cherry");
```
### 3.2.2 算法优化对集合操作性能的影响
算法优化可以大幅提高集合操作的效率。例如,在使用`TreeSet`时,可以通过实现自定义的`Comparator`来优化排序性能。以下是一个简单的自定义比较器实现:
```java
class CustomComparator implements Comparator<String> {
@Override
public int compare(String s1, String s2) {
// 自定义比较逻辑
***pareToIgnoreCase(s2);
}
}
```
通过自定义比较器,可以提供一种更有效的方式来比较和排序字符串,从而在使用`TreeSet`或`TreeMap`时获得更好的性能。
## 3.3 多线程下的集合使用策略
在多线程环境下使用集合类时,必须考虑线程安全和性能的权衡。
### 3.3.1 线程安全与性能权衡
在多线程环境下,普通的集合类如`ArrayList`和`HashMap`并不是线程安全的。因此,可以使用`Vector`和`Hashtable`,它们是线程安全的版本,但性能较差。更好的选择是使用并发集合,如`ConcurrentHashMap`和`CopyOnWriteArrayList`,它们提供了更好的并发性能。
以下是`ConcurrentHashMap`的一个使用示例:
```java
ConcurrentMap<String, String> concurrentMap = new ConcurrentHashMap<>();
concurrentMap.put("key", "value");
```
### 3.3.2 并发集合类的选择与使用
`ConcurrentHashMap`的实现使用了分段锁技术,减少了锁的竞争,提高了并发性能。在实际应用中,选择合适并发集合类可以大幅提升多线程操作集合的性能。
表3.1列出了常用并发集合类及其使用场景:
| 集合类 | 使用场景 |
|---------------------|-------------------------------------------------------------|
| ConcurrentHashMap | 并发读写操作,高吞吐量环境 |
| CopyOnWriteArrayList | 读多写少的场景,需要快速遍历列表,如事件监听器列表 |
| ConcurrentSkipListMap | 并发环境下需要有序映射时使用 |
这些并发集合类在多线程环境下的使用,不仅提高了效率,也保证了数据的一致性和线程安全。
通过本章节的介绍,我们可以看到集合类性能调优并不是一件简单的事情,它需要深入了解集合类的内部工作机制和应用场景。正确地选择数据结构、算法以及并发策略,能够使集合操作的性能提升到新的高度。在下一章节中,我们将探讨使用Google集合库进行性能优化的方法和实践。
# 4. 使用Google集合库进行性能优化
## 4.1 Google集合框架概述
### 4.1.1 Guava库提供的集合工具类
Guava库是Google开发的一个开源的Java工具库,它提供了许多实用的工具类,极大地扩展了Java标准集合框架的功能。Guava的集合工具类包括了对集合操作的各种优化实现,例如:`Multimap`、`Multiset`、`LoadingCache`、`Splitter` 和 `Joiner` 等,这些类的设计宗旨是简化在真实世界中频繁遇到的复杂集合操作。
Guava 的集合类特别强调性能优化,例如,`Multimap` 可以存储键到多个值的映射关系,从而避免了编写额外的循环来添加或访问这些值。而 `Multiset` 允许一个元素出现多次,并且提供了方便的方法来操作计数,这在某些情况下比使用Map更加高效。在实际开发中,这些工具类能够帮助开发者以更少的代码量达到更好的性能。
### 4.1.2 Google集合框架与Java标准集合的比较
在深入探讨Guava库带来的性能优势之前,有必要先了解它与Java标准集合框架的主要区别。Java标准集合框架是Java基础的一部分,以其稳定性、高效性和广泛的应用性而闻名。然而,Guava并不是要取代Java标准集合框架,而是作为一个补充,提供了额外的功能和改进。
Guava集合类在几个方面对Java集合进行了增强:
- **额外的集合操作**:Guava提供了许多便捷的方法,如:`FluentIterable`、`Iterables` 和 `Iterators` 等,这些方法为集合的处理提供了更多的操作选择。
- **线程安全的集合**:Guava提供了`ImmutableList`、`ImmutableSet`、`ImmutableMap` 等不可变集合,它们在创建后不能被修改,保证线程安全且能够提供更好的性能。
- **更丰富的集合类型**:例如,`Multimap`、`Multiset` 和 `Table` 等都是Java标准集合中不存在的类型。
从性能角度来看,Guava集合类通常针对常见的操作进行了优化。例如,`LinkedHashMultimap` 使用 `LinkedHashMap` 和 `LinkedHashSet` 提供了稳定且快速的顺序访问,而 `EnumMap` 则针对枚举类型键的场景提供了一种紧凑且高效的实现。这些优化对于需要大量集合操作的程序来说,可能会带来性能上的提升。
## 4.2 Google集合类的高级用法
### 4.2.1 Multimap和Multiset的使用场景
`Multimap` 是一个接口,它允许一个键映射到多个值。这在许多场景下非常有用,比如,你需要将一组标签(Tag)应用到多个项目上时。在Java中,这通常需要额外的集合来手动管理键值对,而使用`Multimap`可以大大简化这一过程。
- **使用场景**:
- **多个值的映射**:当你需要为一个键存储多个值时,`Multimap` 是非常方便的,如映射用户到多个角色。
- **减少代码复杂性**:避免编写额外的代码来管理多个值与键之间的关系。
- **灵活的数据结构**:在需要将一个集合映射到另一个集合时,`Multimap` 提供了一种直接的实现方式。
```java
Multimap<String, String> multimap = ArrayListMultimap.create();
multimap.put("colors", "red");
multimap.put("colors", "blue");
// 多个值
Collection<String> colors = multimap.get("colors");
// [red, blue]
```
在上面的例子中,`multimap.get("colors")` 返回了一个值集合,包含 "red" 和 "blue"。`ArrayListMultimap` 是默认的实现,它保证了插入顺序。
### 4.2.2 使用Immutable集合保证线程安全
在多线程程序设计中,线程安全是一个重要的考虑因素。Java标准库中的 `Collections.unmodifiableList()` 和类似的不可变集合方法虽然可以防止集合被修改,但它们返回的是现有集合的一个不可修改视图。而Guava库中的 `ImmutableList`、`ImmutableSet` 和 `ImmutableMap` 等提供了真正的不可变集合,它们在创建时就保证了不可变性。
```java
List<String> originalList = new ArrayList<>();
originalList.add("one");
originalList.add("two");
// 创建不可变集合
ImmutableList<String> immutableList = ImmutableList.copyOf(originalList);
// 尝试修改不可变集合会导致UnsupportedOperationException异常
// immutableList.add("three"); // 抛出异常
```
不可变集合有几个显著优势:
- **线程安全**:由于不可变对象不能被修改,因此它们天生就是线程安全的。
- **性能**:不可变对象可以被自由地共享和缓存,而不需要考虑线程安全问题。
- **易于理解和使用**:不可变对象简化了并发编程,使得代码更容易理解和维护。
## 4.3 高性能数据处理实践
### 4.3.1 使用RangeSet和RangeMap进行范围操作
Guava集合框架中的 `RangeSet` 和 `RangeMap` 提供了处理一系列数据范围的集合类。它们分别用于存储不相交的范围集合和范围到值的映射。
- **使用场景**:
- **表示一系列的范围**:例如,处理时间段、IP地址范围、文件区域等。
- **执行范围查询和更新**:快速查询范围内的所有值或更新特定范围。
```java
RangeSet<Integer> rangeSet = TreeRangeSet.create();
rangeSet.add(Range.closed(1, 10)); // 添加范围 [1, 10]
rangeSet.add(Range.closedOpen(11, 15)); // 添加范围 [11, 15)
// 检查一个值是否属于某个范围
boolean contains = rangeSet.contains(12); // 返回 true
// 移除一个范围
rangeSet.remove(Range.closedOpen(5, 10)); // 移除范围 [5, 10)
// 处理范围映射
RangeMap<Integer, String> rangeMap = TreeRangeMap.create();
rangeMap.put(Range.closed(1, 10), "foo"); // 将 [1, 10] 映射到 "foo"
```
`RangeSet` 和 `RangeMap` 是对传统集合操作的扩展,它们提供了一种新的方式来处理范围数据,使得代码更加清晰和高效。
### 4.3.2 高效处理Map中的键集合和值集合
在Guava集合库中,`Multimap` 的一个特殊实现是 `Table`。它允许你将两个键映射到一个值上,这在需要处理交叉索引时非常有用。`Table` 是一个二维数据结构,可以视为一个映射的映射。
- **使用场景**:
- **交叉索引数据结构**:当你需要基于两个主键来存储和检索数据时,例如,一个班级课程的成绩表。
- **实现复杂的数据关系**:可以非常方便地通过两个键来添加或访问数据。
```java
Table<String, String, Integer> table = HashBasedTable.create();
table.put("John", "Math", 90);
table.put("John", "Literature", 95);
table.put("Jane", "Math", 85);
// 通过两个键值获取数据
Integer mathScore = table.get("John", "Math"); // 返回 90
```
在上面的例子中,`Table` 允许我们将学生的名字和课程作为键,成绩作为值。通过这种方式,我们可以轻松地访问任何学生的任何科目的成绩。
## 小结
Guava集合框架通过提供更丰富的集合类型和操作方法,极大地增强了Java标准集合框架的功能,特别是在处理复杂数据结构和提高性能方面。通过使用如`Multimap`、`Multiset`、`Table`等,开发者能够以更简洁、高效的方式来处理和管理数据集合。此外,`Immutable`集合和`RangeSet`、`RangeMap`等特别设计的集合类也进一步扩展了集合框架的边界,为构建高性能、线程安全和范围操作提供了强大工具。
# 5. 集合类性能测试与分析
在开发高性能应用程序时,性能测试和分析是不可或缺的环节。它不仅可以帮助我们发现程序中的潜在问题,还可以指导我们进行有效的优化。本章节将探讨如何建立性能测试基准、分析性能瓶颈以及持续性能优化的文化与实践。
## 5.1 建立性能测试基准
### 5.1.1 设计测试用例的要点
设计有效的性能测试用例需要明确性能指标和测试场景。首先,应该确定哪些性能指标最为关键,比如响应时间、吞吐量、CPU和内存使用率等。其次,基于应用的实际情况设计真实的测试场景,这包括模拟高并发、大数据量处理等。测试用例应覆盖不同的边界条件和异常情况,保证测试结果的全面性和准确性。
一个典型的设计测试用例的例子如下:
```java
import org.openjdk.jmh.annotations.*;
import java.util.ArrayList;
import java.util.List;
@BenchmarkMode(Mode.Throughput)
@Warmup(iterations = 5, time = 1)
@Measurement(iterations = 5, time = 1)
public class CollectionBenchmark {
@Benchmark
public List<String> testArrayListAdd() {
List<String> list = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
list.add("Element" + i);
}
return list;
}
}
```
这个例子中,我们使用了JMH(Java Microbenchmark Harness)来设计一个基准测试用例,目的是评估在添加1000个元素到ArrayList中时的吞吐量。
### 5.1.2 使用JMH进行基准性能测试
JMH是一个性能微基准测试框架,它能帮助开发者编写易于理解且可靠的性能测试代码。它通过注解的方式,支持多种性能测试模式,并提供易于使用的命令行工具来执行测试。
一个使用JMH的简单性能测试示例代码:
```java
@Benchmark
public List<String> testArrayListAdd() {
List<String> list = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
list.add("Element" + i);
}
return list;
}
```
在这个例子中,我们定义了一个性能测试方法,它会不断向ArrayList中添加元素,JMH将测量这个操作的吞吐量。
## 5.2 分析性能瓶颈与优化策略
### 5.2.1 识别性能瓶颈的工具和方法
识别性能瓶颈通常需要借助专业的分析工具,例如JProfiler、VisualVM和GC日志分析等。此外,代码分析、线程分析和内存分析也是常见的手段。
在识别性能瓶颈时,可以采取以下步骤:
1. 通过性能测试收集数据。
2. 使用分析工具定位热点代码(CPU消耗高的方法)。
3. 分析线程状态,找出死锁或阻塞情况。
4. 通过内存分析工具寻找内存泄漏。
### 5.2.2 实际案例分析:优化集合操作性能
假设在性能测试中,我们发现添加元素到`ArrayList`的过程中性能不足。通过JProfiler分析,我们发现主要性能瓶颈在于频繁的数组扩容。为了解决这个问题,我们可以预先分配一个足够大的容量给`ArrayList`,或者使用`LinkedList`作为替代方案,具体取决于集合操作的性质。
一个简单的优化示例:
```java
List<String> preallocatedList = new ArrayList<>(1000);
for (int i = 0; i < 1000; i++) {
preallocatedList.add("Element" + i);
}
```
在这个例子中,我们创建了一个预先分配了容量的`ArrayList`,这样在添加元素时就无需频繁扩容,从而减少了性能损耗。
## 5.3 持续性能优化的文化与实践
### 5.3.1 构建持续集成环境下的性能监控
持续集成(CI)是现代软件开发的重要实践之一,它要求开发团队频繁地将代码变更集成到主干。为了在CI过程中监控性能,我们可以集成性能测试作为构建流程的一部分。这样可以快速发现引入的性能问题,并在问题扩散前进行修复。
### 5.3.2 性能优化的企业实践案例分享
例如,Facebook采用了一套名为FPTI(Facebook Performance Testing Infrastructure)的性能测试基础设施,用于在代码提交时自动运行性能测试。这不仅保证了新代码的性能不会退化,还帮助他们不断优化现有代码的性能。
性能优化是一个持续的过程,需要团队的关注和投入。通过持续集成环境下的性能监控,企业可以及时发现并解决性能问题,确保应用的健康运行。
通过本章的学习,您应该了解了性能测试的重要性,并掌握了一些基本的性能测试与分析方法。在实际工作中,可以根据这些理论指导实践,持续改进和优化您的集合类操作性能。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨 Java Google 集合,提供高级使用技巧、性能调优秘籍、并发处理机制、专家指南、内存管理策略、扩展与定制方法、源码剖析、大数据场景应用、并发包、数据结构选择、设计模式、API 设计原则、测试与调试、监控与诊断、学习资源、扩展实践以及在 Android 开发中的应用。通过对 Google 集合的全面解析,本专栏旨在帮助开发者掌握 Google 集合的精髓,提升 Java 应用程序的性能、可扩展性、并发性和可维护性。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
微机接口技术深度解析:串并行通信原理与实战应用
# 摘要
微机接口技术是计算机系统中不可或缺的部分,涵盖了从基础通信理论到实际应用的广泛内容。本文旨在提供微机接口技术的全面概述,并着重分析串行和并行通信的基本原理与应用,包括它们的工作机制、标准协议及接口技术。通过实例介绍微机接口编程的基础知识、项目实践以及在实际应用中的问题解决方法。本文还探讨了接口技术的新兴趋势、安全性和兼容
【进位链技术大剖析】:16位加法器进位处理的全面解析
# 摘要
进位链技术是数字电路设计中的基础,尤其在加法器设计中具有重要的作用。本文从进位链技术的基础知识和重要性入手,深入探讨了二进制加法的基本规则以及16位数据表示和加法的实现。文章详细分析了16位加法器的工作原理,包括全加器和半加器的结构,进位链的设计及其对性能的影响,并介绍了进位链优化技术。通过实践案例,本文展示了进位链技术在故障诊断与维护中的应用,并探讨了其在多位加法器设计以及多处理器系统中的高级应用。最后,文章展望了进位链技术的未来,
【均匀线阵方向图秘籍】:20个参数调整最佳实践指南
# 摘要
均匀线阵方向图是无线通信和雷达系统中的核心技术之一,其设计和优化对系统的性能至关重要。本文系统性地介绍了均匀线阵方向图的基础知识,理论基础,实践技巧以及优化工具与方法。通过理论与实际案例的结合,分析了线阵的基本概念、方向图特性、理论参数及其影响因素,并提出了方向图参数调整的多种实践技巧。同时,本文探讨了仿真软件和实验测量在方向图优化中的应用,并介绍了最新的优化算法工具。最后,展望了均匀线阵方向图技术的发展趋势,包括新型材料和技术的应用、智能化自适应方向图的研究,以及面临的技术挑战与潜在解决方案。
# 关键字
均匀线阵;方向图特性;参数调整;仿真软件;优化算法;技术挑战
参考资源链
ISA88.01批量控制:制药行业的实施案例与成功经验

# 摘要
ISA88.01标准为批量控制系统提供了框架和指导原则,尤其是在制药行业中,其应用能够显著提升生产效率和产品质量控制。本文详细解析了ISA88.01标准的概念及其在制药工艺中的重要
实现MVC标准化:肌电信号处理的5大关键步骤与必备工具

# 摘要
本文探讨了MVC标准化在肌电信号处理中的关键作用,涵盖了从基础理论到实践应用的多个方面。首先,文章介绍了
【FPGA性能暴涨秘籍】:数据传输优化的实用技巧
# 摘要
本文全面介绍了FPGA在数据传输领域的应用和优化技巧。首先,对FPGA和数据传输的基本概念进行了介绍,然后深入探讨了FPGA内部数据流的理论基础,包
PCI Express 5.0性能深度揭秘:关键指标解读与实战数据分析

# 摘要
PCI Express(PCIe)技术作为计算机总线标准,不断演进以满足高速数据传输的需求。本文首先概述PCIe技术,随后深入探讨PCI Express 5.0的关键技术指标,如信号传输速度、编码机制、带宽和吞吐量的理论极限以及兼容性问题。通过实战数据分析,评估PCI Express
CMW100 WLAN指令手册深度解析:基础使用指南揭秘
# 摘要
CMW100 WLAN指令是业界广泛使用的无线网络测试和分析工具,为研究者和工程师提供了强大的网络诊断和性能评估能力。本文旨在详细介绍CMW100 WLAN指令的基础理论、操作指南以及在不同领域的应用实例。首先,文章从工作原理和系统架构两个层面探讨了CMW100 WLAN指令的基本理论,并解释了相关网络协议。随后,提供了详细的操作指南,包括配置、调试、优化及故障排除方法。接着,本文探讨了CMW100 WLAN指令在网络安全、网络优化和物联网等领域的实际应用。最后,对CMW100 WLAN指令的进阶应用和未来技术趋势进行了展望,探讨了自动化测试和大数据分析中的潜在应用。本文为读者提供了
三菱FX3U PLC与HMI交互:打造直觉操作界面的秘籍

# 摘要
本论文详细介绍了三菱FX3U PLC与HMI的基本概念、工作原理及高级功能,并深入探讨了HMI操作界面的设计原则和高级交互功能。通过对三菱FX3U PLC的编程基础与高级功能的分析,本文提供了一系列软件集成、硬件配置和系统测试的实践案例,以及相应的故障排除方法。此外,本文还分享了在不同行业应用中的案例研究,并对可能出现的常见问题提出了具体的解决策略。最后,展望了新兴技术对PLC和HMI
【透明度问题不再难】:揭秘Canvas转Base64时透明度保持的关键技术

# 摘要
本文旨在全面介绍Canvas转Base64编码技术,从基础概念到实际应用,再到优化策略和未来趋势。首先,我们探讨了Canvas的基本概念、应用场景及其重要性,紧接着解析了Base64编码原理,并重点讨论了透明度在Canvas转Base64过程中的关键作用。实践方法章节通过标准流程和技术细节的讲解,提供了透明度保持的有效编码技巧和案例分析。高级技术部分则着重于性能优化、浏览器兼容性问题以及Ca
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )