Jinja2.lexer库与异构系统集成:跨平台模板兼容性的秘密武器
发布时间: 2024-10-16 08:08:08 阅读量: 19 订阅数: 15 

# 1. Jinja2.lexer库概述
## 1.1 Jinja2.lexer库的起源与发展
Jinja2.lexer库是Python语言中Jinja2模板引擎的一个重要组成部分,它起源于对模板引擎中词法分析的需求。随着Web开发的快速发展,Jinja2模板引擎因其灵活性和安全性而受到开发者的青睐。Jinja2.lexer库在Jinja2模板引擎的基础上进一步发展,为模板的解析提供了强大的支持。
## 1.2 Jinja2.lexer库的核心功能与作用
Jinja2.lexer库的核心功能是将模板文本转换为一系列的词法单元(tokens),这些词法单元是模板解析的基础。它将文本中的各种语法元素如变量、表达式、注释等识别出来,并生成对应的词法单元,为后续的语法分析阶段做准备。通过这种方式,Jinja2.lexer库在模板引擎中起到了关键的作用,确保了模板的正确解析和执行。
## 1.3 Jinja2.lexer库在模板引擎中的定位
在模板引擎的整个工作流程中,Jinja2.lexer库位于词法分析阶段,是模板解析的第一步。它为后续的语法分析、模板编译和渲染提供了必要的输入。通过对模板文本的词法分析,Jinja2.lexer库不仅提高了模板解析的效率,还增强了模板引擎的健壮性和扩展性。
# 2. Jinja2.lexer库的工作原理
## 2.1 解析模板语言的流程
Jinja2.lexer库的核心功能是将模板语言解析成可执行的代码块。这个过程主要分为两个阶段:词法分析阶段和语法分析阶段。在本章节中,我们将详细介绍这两个阶段的工作原理。
### 2.1.1 词法分析阶段
词法分析阶段是Jinja2.lexer库解析模板语言的第一步。在这个阶段,库会将模板文本中的每个字符分解成一个个的词法单元(Token)。例如,模板中的变量、标签、注释等都会被识别为不同的词法单元。
```python
from jinja2 import lexer
template = "{{ user.name }} is {{ user.age }} years old."
tokens = list(lexer.tokenize(template))
print(tokens)
```
代码逻辑的逐行解读分析:
- 首先,我们导入了`lexer`模块。
- 然后,我们定义了一个模板字符串。
- 使用`lexer.tokenize`方法将模板字符串分解成词法单元列表。
- 最后,打印出这些词法单元。
参数说明:
- `template`: 定义的模板字符串。
- `lexer.tokenize`: 将模板字符串分解成词法单元的方法。
在这个例子中,`tokens`列表包含了模板中所有的词法单元。例如,`{{ user.name }}`会被分解成`Token('variable_begin')`, `Token('name', 'user')`, `Token('variable_end')`等。
### 2.1.2 语法分析阶段
语法分析阶段是Jinja2.lexer库解析模板语言的第二步。在这个阶段,库会根据词法单元和模板的语法规则构建出一个语法树(AST)。语法树是一个表示模板结构的树状数据结构。
```python
from jinja2 import parser, nodes
ast = parser.parse(tokens)
print(ast)
```
代码逻辑的逐行解读分析:
- 首先,我们导入了`parser`模块。
- 然后,我们使用`parser.parse`方法将词法单元列表转换成语法树。
- 最后,打印出语法树。
参数说明:
- `tokens`: 词法单元列表。
- `parser.parse`: 将词法单元列表转换成语法树的方法。
在这个例子中,`ast`是模板的语法树。语法树的每个节点代表模板中的一个元素,例如变量、标签等。
mermaid格式流程图展示词法分析和语法分析的过程:
```mermaid
graph LR
A[开始解析] --> B[词法分析]
B --> C[生成词法单元列表]
C --> D[语法分析]
D --> E[构建语法树]
E --> F[结束解析]
```
## 2.2 Jinja2.lexer库的内部机制
### 2.2.1 词法单元的生成
Jinja2.lexer库通过词法分析器生成词法单元。词法分析器是一个状态机,它根据当前的输入字符和状态生成词法单元。
```python
import re
import collections
class Lexer:
Token = collections.namedtuple('Token', ['type', 'value'])
tokens_spec = [
('NUMBER', r'\d+(\.\d*)?'), # Integer or decimal number
('SKIP', r'[ \t]+'), # Skip over spaces and tabs
('MISMATCH', r'.'), # Any other character
]
tok_regex = '|'.join('(?P<%s>%s)' % pair for pair in tokens_spec)
line_re = ***pile('.*\n')
line = 1
pos = 0
def __init__(self, text):
self.text = text
self.match = re.match(self.tok_regex, text)
def token(self, match, text):
token_spec = self.tokens_spec[match.lastindex - 1]
value = text[match.start():match.end()]
token = self.Token(token_spec[0], value)
if token.type == 'NUMBER':
return token._replace(value=float(value))
return token
def tokens(self):
while self.pos < len(self.text):
line = self.line_re.match(self.text, self.pos)
if line:
self.line += 1
self.pos = line.end()
else:
self.pos += 1
if self.pos > len(self.text):
break
yield self.token(self.match, self.text[self.pos - 1])
self.match = None
lexer = Lexer("3 + 4")
for token in lexer.tokens():
print(token)
```
代码逻辑的逐行解读分析:
- 定义了一个`Lexer`类,它包含了词法单元的生成逻辑。
- `tokens_spec`定义了各种词法单元的正则表达式。
- `tok_regex`是所有正则表达式的组合。
- `token`方法根据匹配结果生成词法单元。
- `tokens`方法生成所有词法单元直到文本结束。
参数说明:
- `text`: 输入的模板文本。
- `Lexer(text)`: 生成词法分析器的实例。
mermaid格式流程图展示词法分析的过程:
```mermaid
graph LR
A[开始词法分析] --> B[匹配正则表达式]
B --> C[生成词法单元]
C --> D[检查是否到达文本末尾]
D --> |是| E[结束词法分析]
D --> |否| B
```
### 2.2.2 语法树的构建
语法树的构建是Jinja2.lexer库解析模板语言的核心部分。语法树是一个表示模板结构的树状数据结构。
```python
from collections import deque
class Node:
def __init__(self, type, children=None):
self.type = type
self.children = children if children is not None else []
class Parser:
def __init__(self, tokens):
self.tokens = deque(tokens)
self.current_token = self.tokens.popleft()
def parse(self):
return self.expression()
def expression(self):
node = Node('expression')
node.children.append(self.term())
while self.current_token.type == '+':
self.eat('+')
node.children.append(self.term())
return node
def term(self):
node = Node('term')
node.children.append(self.factor())
while self.current_token.type == '*':
self.eat('*')
node.children.append(self.factor())
return node
def factor(self):
if self.current_token.type == 'NUMBER':
value = self.current_token.value
self.eat('NUMBER')
return Node('number', [Node('value', [str(value)])])
elif self.current_token.type == '(':
self.eat('(')
node = self.expression()
self.eat(')')
return node
else:
raise Exception('Unexpected token')
def eat(self, token_type):
if self.current_token.type == token_type:
self.current_token = self.tokens.popleft()
else:
raise Exception('Unexpected token')
parser = Parser(list(lexer.tokens()))
ast = parser.parse()
print(ast)
```
代码逻辑的逐行解读分析:
- 定义了一个`Node`类,它表示语法树的节点。
- 定义了一个`Parser`类,它包含了语法分析的逻辑。
- `parse`方法开始语法分析并返回语法树的根节点。
- `expression`方法解析表达式。
- `term`方法解析项。
- `factor`方法解析因子。
- `eat`方法检查当前词法单元并移动到下一个词法单元。
参数说明:
- `tokens`: 词法单元列表。
- `Parser(tokens)`: 生成语法分析器的实例。
mermaid格式流程图展示语法分析的过程:
```mermaid
graph LR
A[开始语法分析] --> B[解析表达式]
B --> C[解析项]
C --> D[解析因子]
D --> E[返回语法树]
E --> F[结束语法分析]
```
## 2.3 Jinja2.lexer库的扩展性与定制性
### 2.3.1 自定义语法和词法单元
Jinja2.lexer库提供了强大的扩展性,允许开发者自定义语法和词法单元。这使得库可以适用于不同的模板语言和需求。
```python
class CustomLexer(Lexer):
tokens_spec = [
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python 库文件学习系列的 Jinja2.lexer 专栏!本专栏将带你踏上掌握 Python 模板引擎 Jinja2.lexer 的旅程。从入门指南到高级技巧,再到源码分析和安全最佳实践,我们将深入探讨 Jinja2.lexer 的方方面面。通过实践案例和误区分析,你将获得打造高效模板解析流程所需的知识。此外,我们还将探索 Jinja2.lexer 与异构系统集成、调试技巧、自定义扩展和 Web 框架融合的奥秘。最后,我们将了解模板继承、宏和循环控制的机制,以及注释和测试功能的使用。加入我们,成为 Jinja2.lexer 的专家,提升你的 Python 模板引擎技能!
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
故障恢复计划:机械运动的最佳实践制定与执行

# 1. 故障恢复计划概述
故障恢复计划是确保企业或组织在面临系统故障、灾难或其他意外事件时能够迅速恢复业务运作的重要组成部分。本章将介绍故障恢复计划的基本概念、目标以及其在现代IT管理中的重要性。我们将讨论如何通过合理的风险评估与管理,选择合适的恢复策略,并形成文档化的流程以达到标准化。
## 1.1 故障恢复计划的目的
故障恢复计划的主要目的是最小化突发事件对业务的
Python算法实现捷径:源代码中的经典算法实践

# 1. Python算法实现捷径概述
在信息技术飞速发展的今天,算法作为编程的核心之一,成为每一位软件开发者的必修课。Python以其简洁明了、可读性强的特点,被广泛应用于算法实现和教学中。本章将介绍如何利用Python的特性和丰富的库,为算法实现铺平道路,提供快速入门的捷径
【NLP新范式】:CBAM在自然语言处理中的应用实例与前景展望

# 1. NLP与深度学习的融合
在当今的IT行业,自然语言处理(NLP)和深度学习技术的融合已经产生了巨大影响,它们共同推动了智能语音助手、自动翻译、情感分析等应用的发展。NLP指的是利用计算机技术理解和处理人类语言的方式,而深度学习作为机器学习的一个子集,通过多层神经网络模型来模拟人脑处理数据和创建模式
MATLAB时域分析:动态系统建模与分析,从基础到高级的完全指南
# 1. MATLAB时域分析概述
MATLAB作为一种强大的数值计算与仿真软件,在工程和科学领域得到了广泛的应用。特别是对于时域分析,MATLAB提供的丰富工具和函数库极大地简化了动态系统的建模、分析和优化过程。在开始深入探索MATLAB在时域分析中的应用之前,本章将为读者提供一个基础概述,包括时域分析的定义、重要性以及MATLAB在其中扮演的角色。
时域
MATLAB遗传算法与模拟退火策略:如何互补寻找全局最优解

# 1. 遗传算法与模拟退火策略的理论基础
遗传算法(Genetic Algorithms, GA)和模拟退火(Simulated Annealing, SA)是两种启发式搜索算法,它们在解决优化问题上具有强大的能力和独特的适用性。遗传算法通过模拟生物
全球高可用部署:MySQL PXC集群的多数据中心策略

# 1. 高可用部署与MySQL PXC集群基础
在IT行业,特别是在数据库管理系统领域,高可用部署是确保业务连续性和数据一致性的关键。通过本章,我们将了解高可用部署的基础以及如何利用MySQL Percona XtraDB Cluster (PXC) 集群来实现这一目标。
## MySQL PXC集群的简介
MySQL PXC集群是一个可扩展的同步多主节点集群解决方案,它能够提供连续可用性和数据一致
【JavaScript人脸识别的用户体验设计】:界面与交互的优化

# 1. JavaScript人脸识别技术概述
## 1.1 人脸识别技术简介
人脸识别技术是一种通过计算机图像处理和识别技术,让机器能够识别人类面部特征的技术。近年来,随着人工智能技术的发展和硬件计算能力的提升,JavaScript人脸识别技术得到了迅速的发展和应用。
## 1.2 JavaScript在人脸识别中的应用
JavaScript作为一种强
Android二维码框架选择:如何集成与优化用户界面与交互

# 1. Android二维码框架概述
在移动应用开发领域,二维码技术已经成为不可或缺的一部分。Android作为应用广泛的移动操作系统,其平台上的二维码框架种类繁多,开发者在选择适合的框架时需要综合考虑多种因素。本章将为读者概述二维码框架的基本知识、功
拷贝构造函数的陷阱:防止错误的浅拷贝
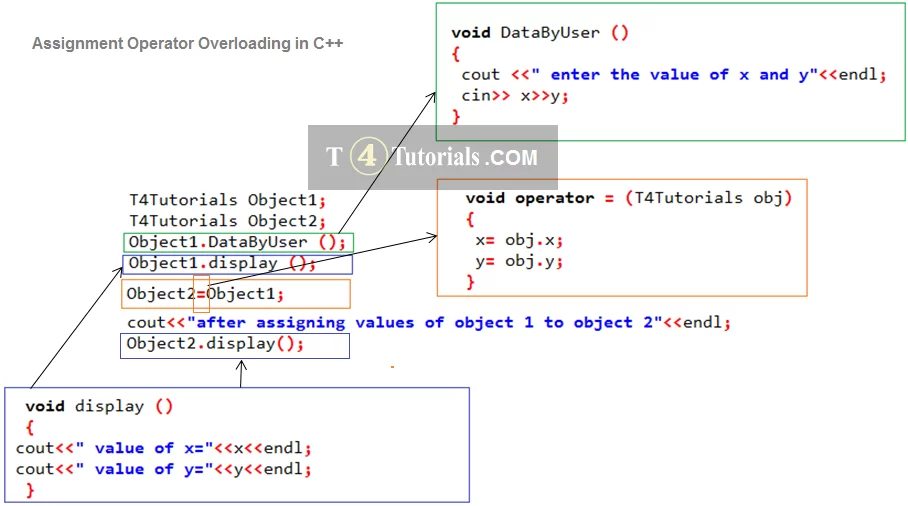
# 1. 拷贝构造函数概念解析
在C++编程中,拷贝构造函数是一种特殊的构造函数,用于创建一个新对象作为现有对象的副本。它以相同类类型的单一引用参数为参数,通常用于函数参数传递和返回值场景。拷贝构造函数的基本定义形式如下:
```cpp
class ClassName {
public:
ClassName(const ClassName& other); // 拷贝构造函数
【深度学习在卫星数据对比中的应用】:HY-2与Jason-2数据处理的未来展望

# 1. 深度学习与卫星数据对比概述
## 深度学习技术的兴起
随着人工智能领域的快速发展,深度学习技术以其强大的特征学习能力,在各个领域中展现出了革命性的应用前景。在卫星数据处理领域,深度学习不仅可以自动
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )